Hadoop-3.1.0+Hive-3.1.0+Spark-2.4.6单机集群部署
一、环境准备
| 主机 | IP | 软件 | 发行商 | 进程 |
| node01 | 192.168.10.101 |
hadoop-3.1.0 hive-3.1.0 spark-2.4.6 |
Apache社区 |
NameNode SecondaryNameNode DataNode ResourceManager NodeManager JobHistoryServer HistoryServer RunJar(Hive Metastore) RunJar(Hive HS2) |
1.1、初始化目录
// 初始化Java的安装路径 mkdir -p /usr/java // 存放软件包的目录 mkdir -p /usr/bdp/software // 存放软件安装包的目录 mkdir -p /usr/bdp/service
// 初始化Hadoop所需的路径
mkdir -p /usr/bdp/data/hadoop/logs /usr/bdp/data/hadoop/dfs/name /usr/bdp/data/hadoop/dfs/data /usr/bdp/data/hadoop/yarn/nm-local-dir mkdir -p /usr/bdp/data/hive/logs
1.2、下载相关软件
包含:jdk-8u271-linux-x64.tar.gz、hadoop-3.1.0.tar.gz、apache-hive-3.1.0-bin.tar.gz、spark-2.4.6-bin-hadoop2.7.tgz
链接:https://pan.baidu.com/s/1EtZDJqW4TPGP1Ne-jE-HkQ 提取码:3i6q

1.3、解压所有的软件包
// 1、解压JDK tar -zxf /usr/bdp/software/jdk-8u271-linux-x64.tar.gz -C /usr/java/ // 2、解压Hadoop tar -zxf /usr/bdp/software/hadoop-3.1.0.tar.gz -C /usr/bdp/service/ // 3、解压Hive tar -zxf /usr/bdp/software/apache-hive-3.1.0-bin.tar.gz -C /usr/bdp/service/ // 4、解压Spark tar -zxf /usr/bdp/software/spark-2.4.6-bin-hadoop2.7.tgz -C /usr/bdp/service/
1.4、创建软件安装包的软连接
// 1、创建Jdk的软连接 ln -s /usr/java/jdk1.8.0_271 /usr/java/jdk // 2、创建Hadoop的软连接 ln -s /usr/bdp/service/hadoop-3.1.0 /usr/bdp/service/hadoop // 3、创建Hive的软连接 ln -s /usr/bdp/service/apache-hive-3.1.0-bin /usr/bdp/service/hive // 4、创建Spark的软连接 ln -s /usr/bdp/service/spark-2.4.6-bin-hadoop2.7 /usr/bdp/service/spark
1.5、统一配置环境变量
// 编辑系统全局配置文件 vim /etc/profile // 新增如下内容 export JAVA_HOME=/usr/java/jdk PATH=.:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH export HADOOP_HOME=/usr/bdp/service/hadoop PATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HIVE_HOME=/usr/bdp/service/hive PATH=.:$HIVE_HOME/bin:$PATH export SPARK_HOME=/usr/bdp/service/spark PATH=.:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH export PATH=$PATH // 刷新配置在当前会话终端里生效 source /etc/profile
二、安装各个软件
2.1、安装Hadoop-3.1.0
2.1.1、hadoop-env.sh
// 编辑hadoop-env.sh
vim /usr/bdp/service/hadoop/etc/hadoop/hadoop-env.sh
// 修改第37行:设置Hadoop的JDK依赖 export JAVA_HOME=/usr/java/jdk
// 修改第200行:设置Hadoop的日志输出目录
export HADOOP_LOG_DIR=/usr/bdp/data/hadoop/logs
2.1.2、core-site.xml
// 编辑core-site.xml
vim /usr/bdp/service/hadoop/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 文件系统名称 --> <property> <name>fs.defaultFS</name> <value>hdfs://node01:9820</value> </property> <!-- 其他临时目录都会建立此目录下 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/bdp/data/hadoop</value> </property> <!-- 允许root用户代理所有主机上的任意用户 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <!-- 允许root用户代理所有主机上的任意用户组 --> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <!-- 允许hive用户代理所有主机上的任意用户 --> <property> <name>hadoop.proxyuser.hive.groups</name> <value>*</value> </property> <!-- 允许hive用户代理所有主机上的任意用户组 --> <property> <name>hadoop.proxyuser.hive.hosts</name> <value>*</value> </property> </configuration>
2.1.3、hdfs-site.xml
// 编辑hdfs-site.xml
vim /usr/bdp/service/hadoop/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 关闭HDFS的权限检查 --> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> </configuration>
2.1.4、yarn-site.xml
// 编辑yarn-site.xml
vim /usr/bdp/service/hadoop/etc/hadoop/yarn-site.xml
<?xml version="1.0"?> <configuration> <!-- 设置RM的地址为node01节点 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node01</value> </property> <!-- 启用YARN的WebUI-V2 --> <property> <name>yarn.webapp.ui2.enable</name> <value>true</value> </property> <!-- 设置AUX服务 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle,spark_shuffle</value> </property> <!-- 设置MapReduce的Shuffle实现 --> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <!-- 设置Spark的Shuffle实现 --> <property> <name>yarn.nodemanager.aux-services.spark_shuffle.class</name> <value>org.apache.spark.network.yarn.YarnShuffleService</value> </property> <!-- 为每个容器请求分配的最小内存限制为(512M) --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <!-- 为每个容器请求分配的最大内存限制为1GB --> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> </property> <!-- 虚拟内存比例,默认为2.1,此处设置为4倍 --> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> </property> <!-- 用于存放Application的cache数据 --> <property> <name>yarn.nodemanager.local-dirs</name> <value>${hadoop.tmp.dir}/yarn/nm-local-dir</value> </property> <!-- 开启日志聚合 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 将日志聚合HDFS的哪个目录下 --> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/apps/yarn/logs</value> </property> <!-- 日志保存时间10天,单位秒 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>864000</value> </property> <!-- 日志聚合服务器的URL地址 --> <property> <name>yarn.log.server.url</name> <value>http://node01:19888/apps/yarn/logs</value> </property> </configuration>
// 注意:一定要执行这一步骤,否则NodeManager无法启动,因为yarn-site.xml中的yarn.nodemanager.aux-services.spark_shuffle.class导致,此时只要吧$SPARK_HOME/yarn/spark-2.4.6-yarn-shuffle.jar复制大$HADOOP_HOME/SHARE/hadoop/yarn/lib下即可)
cp /usr/bdp/service/spark/yarn/spark-2.4.6-yarn-shuffle.jar /usr/bdp/service/hadoop/share/hadoop/yarn/
2.1.5、mapred-site.xml
// 编辑mapred-site.xml
vim /usr/bdp/service/hadoop/etc/hadoop/mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定MR框架通过YARN方式运行 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端口号 --> <property> <name>mapreduce.jobhistory.address</name> <value>node01:10020</value> </property> <!-- 历史服务器的WEB UI端口号 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node01:19888</value> </property> <!-- 提交MR作业时使用位于HDFS上的暂存目录 --> <property> <name>yarn.app.mapreduce.am.staging-dir</name> <value>/apps/yarn/staging</value> </property> <!-- 内存中缓存的historyfile文件信息,默认20000 --> <property> <name>mapreduce.jobhistory.joblist.cache.size</name> <value>2000</value> </property> <!-- 指定MR作业的AM程序的环境变量 --> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/bdp/service/hadoop</value> </property> <!-- 指定MR做的Map程序的环境变量 --> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/bdp/service/hadoop</value> </property> <!-- 指定MR做的Reduce程序的环境变量 --> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/bdp/service/hadoop</value> </property> </configuration>
2.1.6、capacity-scheduler.xml
<!-- 将yarn.scheduler.capacity.resource-calculator配置的默认值
由org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
改为org.apache.hadoop.yarn.util.resource.DominantResourceCalculator,
确保资源调度模式采用CPU+Memory方式。 --> <property> <name>yarn.scheduler.capacity.resource-calculator</name> <value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value> </property>
2.1.7、workers
// 编辑workers
vim /usr/bdp/service/hadoop/etc/hadoop/workers
node01
2.1.8、start-dfs.sh和stop-dfs.sh
# 1、编辑$HADOOP_HOME/sbin目录下的start-dfs.sh
vim /usr/bdp/service/hadoop/sbin/start-dfs.sh
# 新增如下3行 HDFS_NAMENODE_USER=root HDFS_DATANODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
# 2、编辑$HADOOP_HOME/sbin目录下的stop-dfs.sh
vim /usr/bdp/service/hadoop/sbin/stop-dfs.sh
# 新增如下3行
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2.1.9、start-yarn.sh和stop-yarn.sh
# 1、编辑$HADOOP_HOME/sbin目录下的start-yarn.sh vim /usr/bdp/service/hadoop/sbin/start-yarn.sh # 新增如下2行 YARN_RESOURCEMANAGER_USER=root YARN_NODEMANAGER_USER=root # 2、编辑$HADOOP_HOME/sbin目录下的stop-yarn.sh vim /usr/bdp/service/hadoop/sbin/stop-yarn.sh # 新增如下2行 YARN_RESOURCEMANAGER_USER=root YARN_NODEMANAGER_USER=root
2.1.10、格式化HDFS
// 执行HDFS的格式化操作 hdfs namenode -format // 输出日志如下 [root@node01 service]# hdfs namenode -format 2021-01-23 22:29:16,701 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = node01/192.168.10.101 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 3.1.0 STARTUP_MSG: classpath = /usr/bdp/service/hadoop/etc/hadoop:/usr/bdp/service/hadoop/share/hadoop/common/lib/httpcore-4.4.4.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jetty-util-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jackson-core-2.7.8.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/mockito-all-1.8.5.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerb-core-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerb-crypto-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/accessors-smart-1.2.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/stax2-api-3.1.4.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerb-simplekdc-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerby-asn1-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jersey-server-1.19.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/guava-11.0.2.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jetty-servlet-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-lang-2.6.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/httpclient-4.5.2.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jsch-0.1.54.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-cli-1.2.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-io-2.5.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerb-identity-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/xz-1.0.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerb-server-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerby-config-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/avro-1.7.7.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-math3-3.1.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/javax.servlet-api-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/log4j-1.2.17.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jackson-annotations-2.7.8.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jetty-io-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/paranamer-2.3.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/junit-4.11.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jetty-xml-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jetty-http-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jettison-1.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/hadoop-auth-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-beanutils-1.9.3.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jsr305-3.0.0.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jetty-server-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/token-provider-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerb-common-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-compress-1.4.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-configuration2-2.1.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/curator-recipes-2.12.0.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jetty-webapp-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/curator-client-2.12.0.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/curator-framework-2.12.0.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jetty-security-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/zookeeper-3.4.9.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-net-3.6.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/woodstox-core-5.0.3.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jersey-json-1.19.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/hadoop-annotations-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/gson-2.2.4.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/snappy-java-1.0.5.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/slf4j-api-1.7.25.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/json-smart-2.3.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/netty-3.10.5.Final.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/asm-5.0.4.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-collections-3.2.2.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jersey-core-1.19.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jersey-servlet-1.19.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerb-util-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerby-pkix-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jsr311-api-1.1.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/nimbus-jose-jwt-4.41.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerb-client-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerb-admin-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-codec-1.11.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/re2j-1.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-logging-1.1.3.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerby-xdr-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/metrics-core-3.2.4.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jcip-annotations-1.0-1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jackson-databind-2.7.8.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/hamcrest-core-1.3.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/kerby-util-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jsp-api-2.1.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jul-to-slf4j-1.7.25.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/jaxb-api-2.2.11.jar:/usr/bdp/service/hadoop/share/hadoop/common/lib/commons-lang3-3.4.jar:/usr/bdp/service/hadoop/share/hadoop/common/hadoop-common-3.1.0-tests.jar:/usr/bdp/service/hadoop/share/hadoop/common/hadoop-kms-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/common/hadoop-common-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/common/hadoop-nfs-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/httpcore-4.4.4.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jetty-util-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jackson-core-2.7.8.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerb-core-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/json-simple-1.1.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerb-crypto-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/accessors-smart-1.2.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/stax2-api-3.1.4.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerb-simplekdc-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerby-asn1-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jersey-server-1.19.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/guava-11.0.2.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jetty-servlet-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/httpclient-4.5.2.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jaxb-impl-2.2.3-1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jsch-0.1.54.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-io-2.5.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerb-identity-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/xz-1.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerb-server-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerby-config-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/avro-1.7.7.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-math3-3.1.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/javax.servlet-api-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jackson-annotations-2.7.8.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jetty-io-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/paranamer-2.3.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jetty-xml-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jetty-http-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jettison-1.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/hadoop-auth-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-beanutils-1.9.3.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jetty-server-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/token-provider-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerb-common-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-compress-1.4.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-configuration2-2.1.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/curator-recipes-2.12.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jackson-jaxrs-1.9.13.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jetty-webapp-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jackson-xc-1.9.13.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/curator-client-2.12.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/okio-1.6.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/curator-framework-2.12.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jetty-security-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/zookeeper-3.4.9.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-net-3.6.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/woodstox-core-5.0.3.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jersey-json-1.19.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/hadoop-annotations-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/gson-2.2.4.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/htrace-core4-4.1.0-incubating.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/snappy-java-1.0.5.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/json-smart-2.3.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/netty-3.10.5.Final.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/asm-5.0.4.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-collections-3.2.2.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jersey-core-1.19.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/okhttp-2.7.5.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jersey-servlet-1.19.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerb-util-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/netty-all-4.0.52.Final.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerby-pkix-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jsr311-api-1.1.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/nimbus-jose-jwt-4.41.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerb-client-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jetty-util-ajax-9.3.19.v20170502.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerb-admin-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-codec-1.11.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/re2j-1.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerby-xdr-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jcip-annotations-1.0-1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jackson-databind-2.7.8.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/kerby-util-1.0.1.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/jaxb-api-2.2.11.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/lib/commons-lang3-3.4.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/hadoop-hdfs-httpfs-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/hadoop-hdfs-rbf-3.1.0-tests.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/hadoop-hdfs-3.1.0-tests.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/hadoop-hdfs-native-client-3.1.0-tests.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/hadoop-hdfs-rbf-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/hadoop-hdfs-client-3.1.0-tests.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/hadoop-hdfs-native-client-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/hadoop-hdfs-client-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/hadoop-hdfs-nfs-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/hdfs/hadoop-hdfs-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-common-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.0-tests.jar:/usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-app-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-nativetask-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-uploader-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/javax.inject-1.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/snakeyaml-1.16.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/jackson-jaxrs-json-provider-2.7.8.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/jackson-jaxrs-base-2.7.8.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/guice-servlet-4.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/swagger-annotations-1.5.4.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/json-io-2.5.1.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/jersey-guice-1.19.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/aopalliance-1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/jersey-client-1.19.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/mssql-jdbc-6.2.1.jre7.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/geronimo-jcache_1.0_spec-1.0-alpha-1.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/fst-2.50.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/java-util-1.9.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/guice-4.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/jackson-module-jaxb-annotations-2.7.8.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/HikariCP-java7-2.4.12.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/metrics-core-3.2.4.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/ehcache-3.3.1.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/lib/dnsjava-2.1.7.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-server-timeline-pluginstorage-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-common-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-server-common-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-services-core-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-client-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-registry-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-server-router-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-server-nodemanager-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-server-tests-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-api-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-server-web-proxy-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-services-api-3.1.0.jar:/usr/bdp/service/hadoop/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-3.1.0.jar STARTUP_MSG: build = https://github.com/apache/hadoop -r 16b70619a24cdcf5d3b0fcf4b58ca77238ccbe6d; compiled by 'centos' on 2018-03-30T00:00Z STARTUP_MSG: java = 1.8.0_271 ************************************************************/ 2021-01-23 22:29:16,712 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 2021-01-23 22:29:16,725 INFO namenode.NameNode: createNameNode [-format] Formatting using clusterid: CID-ebe2beee-0cce-4a36-811c-b532fbcd74ff 2021-01-23 22:29:19,074 INFO namenode.FSEditLog: Edit logging is async:true 2021-01-23 22:29:19,111 INFO namenode.FSNamesystem: KeyProvider: null 2021-01-23 22:29:19,112 INFO namenode.FSNamesystem: fsLock is fair: true 2021-01-23 22:29:19,114 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false 2021-01-23 22:29:19,169 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE) 2021-01-23 22:29:19,169 INFO namenode.FSNamesystem: supergroup = supergroup 2021-01-23 22:29:19,169 INFO namenode.FSNamesystem: isPermissionEnabled = false 2021-01-23 22:29:19,169 INFO namenode.FSNamesystem: HA Enabled: false 2021-01-23 22:29:19,225 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling 2021-01-23 22:29:19,238 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000 2021-01-23 22:29:19,238 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 2021-01-23 22:29:19,243 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 2021-01-23 22:29:19,246 INFO blockmanagement.BlockManager: The block deletion will start around 2021 Jan 23 22:29:19 2021-01-23 22:29:19,253 INFO util.GSet: Computing capacity for map BlocksMap 2021-01-23 22:29:19,253 INFO util.GSet: VM type = 64-bit 2021-01-23 22:29:19,256 INFO util.GSet: 2.0% max memory 916.4 MB = 18.3 MB 2021-01-23 22:29:19,256 INFO util.GSet: capacity = 2^21 = 2097152 entries 2021-01-23 22:29:19,272 INFO blockmanagement.BlockManager: dfs.block.access.token.enable = false 2021-01-23 22:29:19,294 INFO Configuration.deprecation: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS 2021-01-23 22:29:19,294 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 2021-01-23 22:29:19,294 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0 2021-01-23 22:29:19,294 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000 2021-01-23 22:29:19,295 INFO blockmanagement.BlockManager: defaultReplication = 3 2021-01-23 22:29:19,295 INFO blockmanagement.BlockManager: maxReplication = 512 2021-01-23 22:29:19,295 INFO blockmanagement.BlockManager: minReplication = 1 2021-01-23 22:29:19,295 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 2021-01-23 22:29:19,295 INFO blockmanagement.BlockManager: redundancyRecheckInterval = 3000ms 2021-01-23 22:29:19,295 INFO blockmanagement.BlockManager: encryptDataTransfer = false 2021-01-23 22:29:19,295 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 2021-01-23 22:29:19,361 INFO util.GSet: Computing capacity for map INodeMap 2021-01-23 22:29:19,361 INFO util.GSet: VM type = 64-bit 2021-01-23 22:29:19,361 INFO util.GSet: 1.0% max memory 916.4 MB = 9.2 MB 2021-01-23 22:29:19,361 INFO util.GSet: capacity = 2^20 = 1048576 entries 2021-01-23 22:29:19,362 INFO namenode.FSDirectory: ACLs enabled? false 2021-01-23 22:29:19,362 INFO namenode.FSDirectory: POSIX ACL inheritance enabled? true 2021-01-23 22:29:19,362 INFO namenode.FSDirectory: XAttrs enabled? true 2021-01-23 22:29:19,362 INFO namenode.NameNode: Caching file names occurring more than 10 times 2021-01-23 22:29:19,368 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 65536 2021-01-23 22:29:19,379 INFO snapshot.SnapshotManager: SkipList is disabled 2021-01-23 22:29:19,383 INFO util.GSet: Computing capacity for map cachedBlocks 2021-01-23 22:29:19,383 INFO util.GSet: VM type = 64-bit 2021-01-23 22:29:19,384 INFO util.GSet: 0.25% max memory 916.4 MB = 2.3 MB 2021-01-23 22:29:19,384 INFO util.GSet: capacity = 2^18 = 262144 entries 2021-01-23 22:29:19,405 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 2021-01-23 22:29:19,406 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 2021-01-23 22:29:19,406 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 2021-01-23 22:29:19,409 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 2021-01-23 22:29:19,409 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 2021-01-23 22:29:19,423 INFO util.GSet: Computing capacity for map NameNodeRetryCache 2021-01-23 22:29:19,423 INFO util.GSet: VM type = 64-bit 2021-01-23 22:29:19,423 INFO util.GSet: 0.029999999329447746% max memory 916.4 MB = 281.5 KB 2021-01-23 22:29:19,423 INFO util.GSet: capacity = 2^15 = 32768 entries 2021-01-23 22:29:19,490 INFO namenode.FSImage: Allocated new BlockPoolId: BP-937104445-192.168.10.101-1611458959479 2021-01-23 22:29:19,509 INFO common.Storage: Storage directory /usr/bdp/data/hadoop/dfs/name has been successfully formatted. 2021-01-23 22:29:19,517 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/bdp/data/hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression 2021-01-23 22:29:19,632 INFO namenode.FSImageFormatProtobuf: Image file /usr/bdp/data/hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 389 bytes saved in 0 seconds . 2021-01-23 22:29:19,643 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2021-01-23 22:29:19,647 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at node01/192.168.10.101 ************************************************************/
2.1.11、启动Hadoop各个守护进程
# 1、启动HDFS start-dfs.sh # 2、启动YARN start-yarn.sh # 3、启动MR的作业历史服务 mapred --daemon start historyserver(mr-jobhistory-daemon.sh start historyserver已废弃)
2.1.12、验证各个守护进程的状态
// 1、使用jsp
[root@node01 ~]# jps 85476 Jps 47383 DataNode 49097 RunJar 47242 NameNode 85051 ResourceManager 84730 JobHistoryServer 47628 SecondaryNameNode 85358 NodeManager
// 2、访问WebUI
HDFS的WebUI地址: http://node01:9870
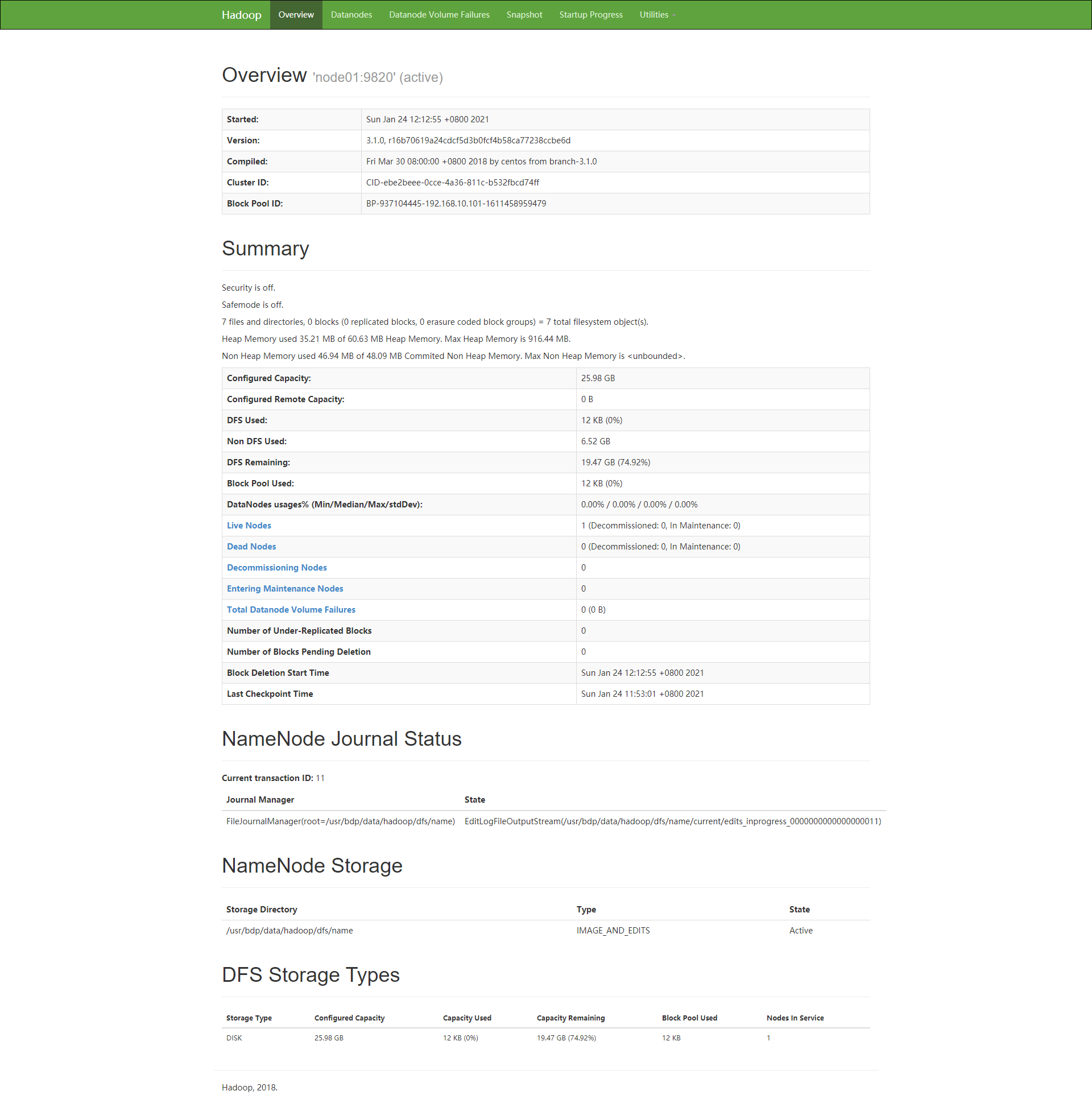
YARN的WebUI地址: http://node01:8088
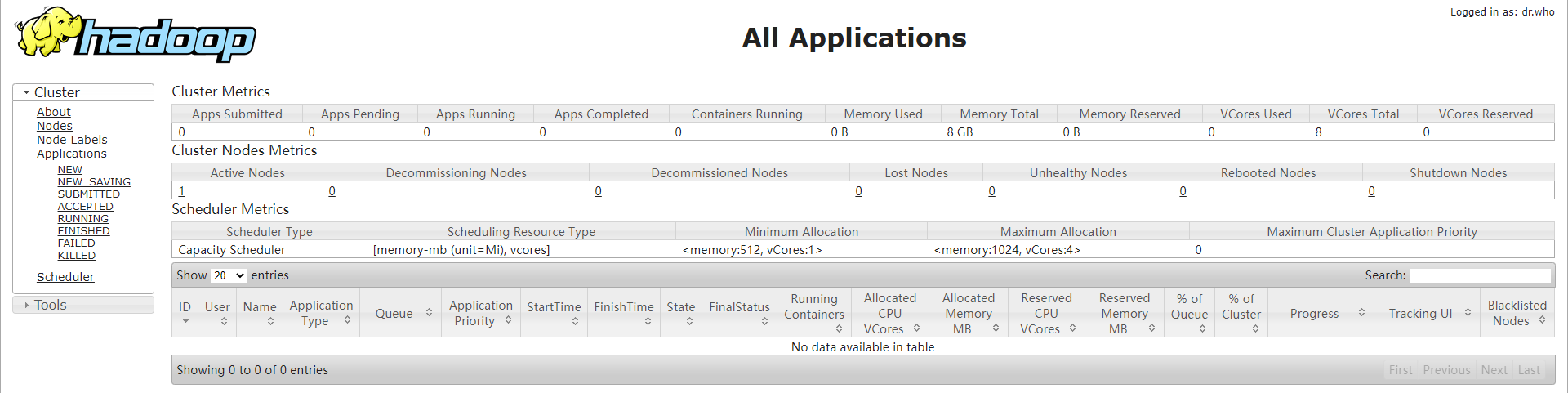
JHS的WebUI地址: http://node01:19888
2.1.13、运行WordCount示例
// 在HFDS中创建WordCount示例的输入目录 hdfs dfs -mkdir -p /apps/jobs/mapreduce/wordcount/input // 上传README.txt hdfs dfs -put $HADOOP_HOME/README.txt /apps/jobs/mapreduce/wordcount/input/ // 提交运行Hadoop自带的MR示例WordCount程序 yarn jar /usr/bdp/service/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar wordcount /apps/jobs/mapreduce/wordcount/input/ /apps/jobs/mapreduce/wordcount/output1 // 查看输出文件 hdfs dfs -ls /apps/jobs/mapreduce/wordcount/output1/
2.1.14、验证ResourceManager和JobHistoryServer的日志聚合功能
// 在ResourceManager首页点击作业的History链接会进入JobHistoryServer的作业详情页
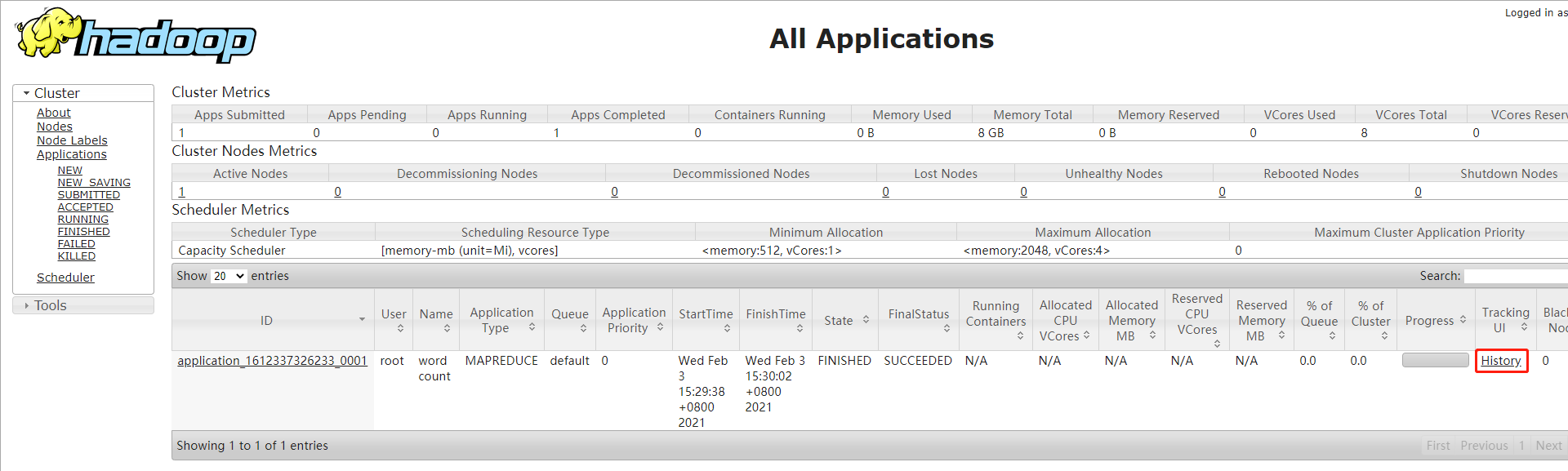
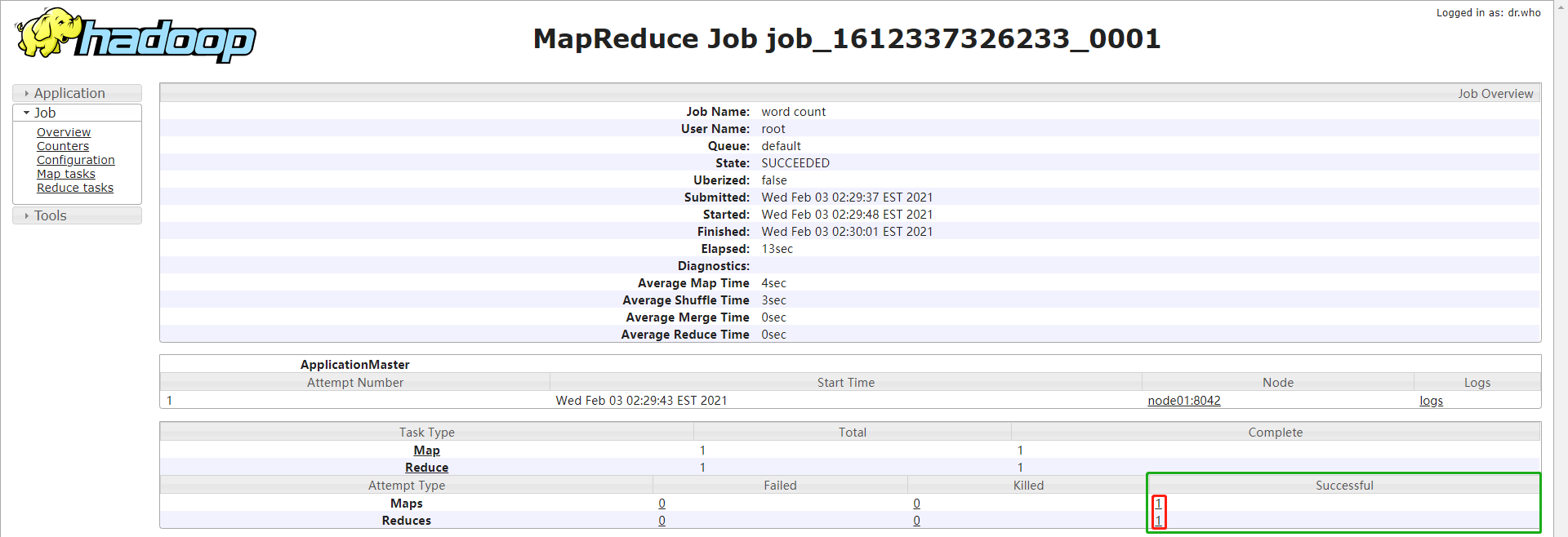


// 或者直接从JobHistoryServer中查看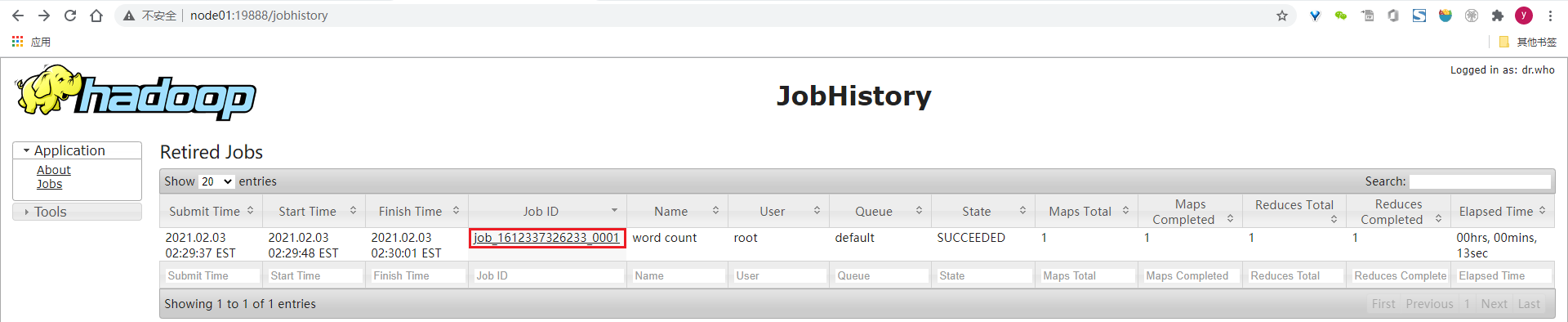
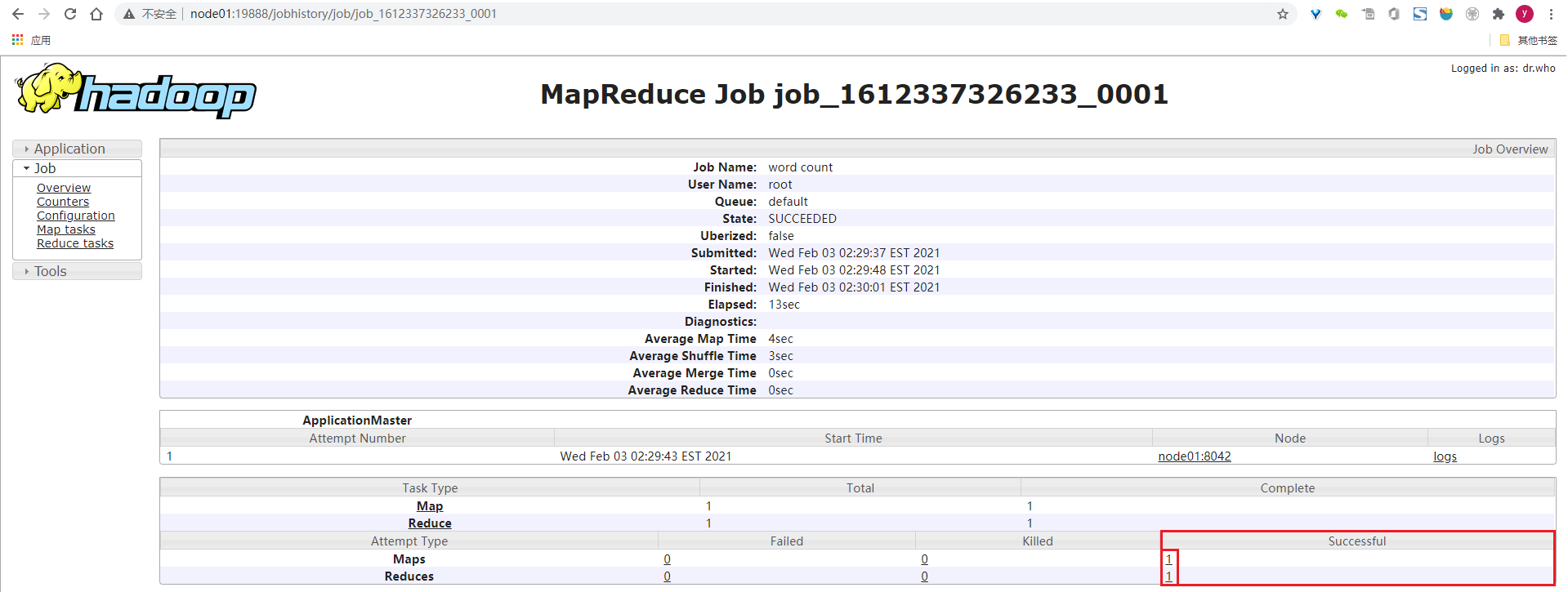

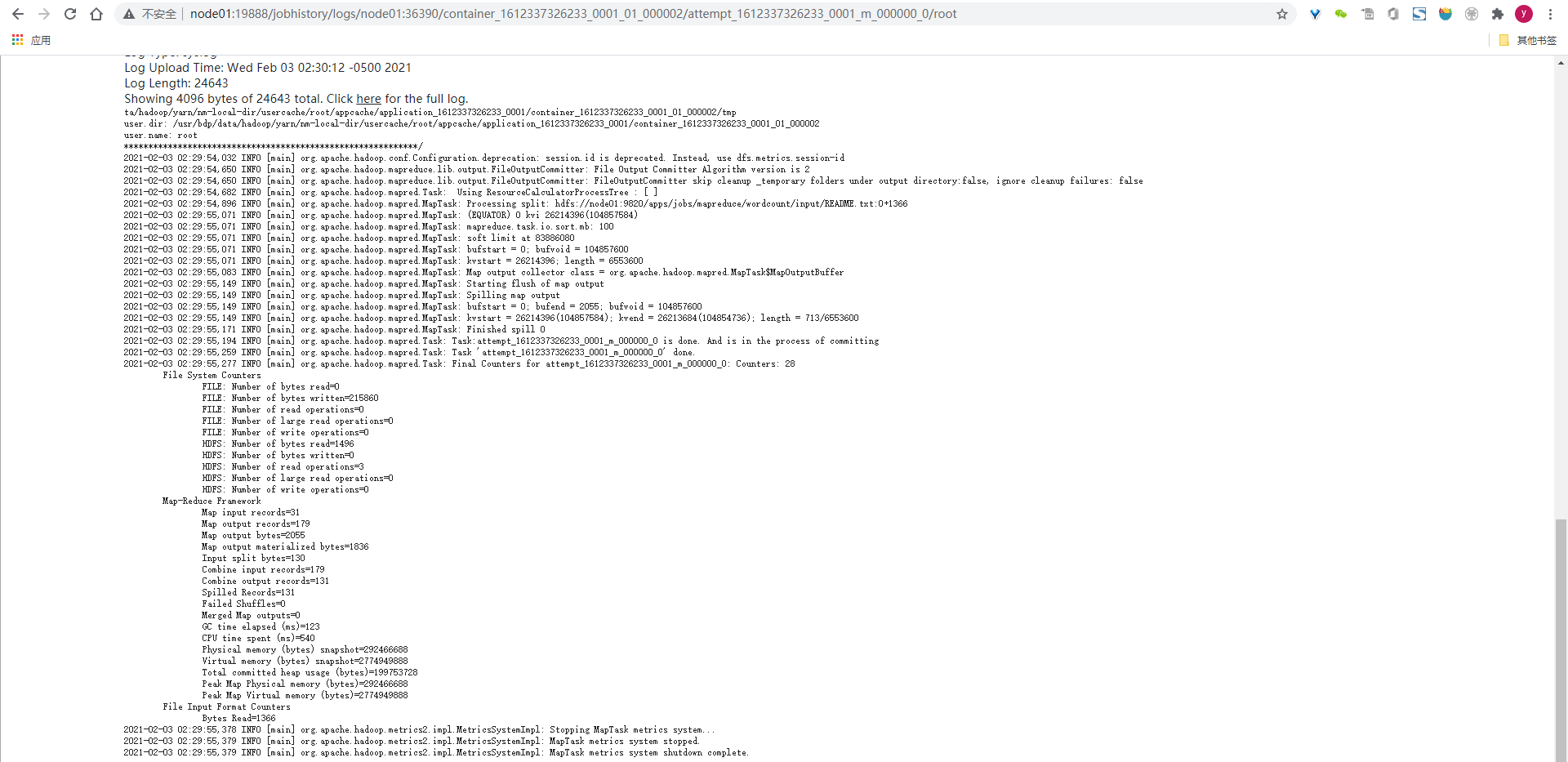
2.2、安装Hive-3.1.0
2.2.1、安装MySQL-8.0.22
2.2.2、hive-env.sh
// 编辑hive-env.sh配置
vim /usr/bdp/service/hive/conf/hive-env.sh
// 新增如下内容
# 在第48行设置Hadoop的安装路径
export HADOOP_HOME=/usr/bdp/service/hadoop
# 在第51行设置Hive的配置文件路径
export HIVE_CONF_DIR=/usr/bdp/service/hive/conf
# 在第54行设置运行Hive Shell的环境依赖,仅对Shell环境生效(如需要配置Server则需要在hive-site.xml中配置hive.aux.jars.path)
export HIVE_AUX_JARS_PATH=/usr/bdp/service/hive/lib
2.2.3、hive-site.xml
// 修改hive-default.xml.template为hive-site.xml
cp /usr/bdp/service/hive/conf/hive-default.xml.template /usr/bdp/service/hive/conf/hive-site.xml
// 编辑hive-site配置
vim /usr/bdp/service/hive/conf/hive-site.xml
// 改为如下内容
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- Hive的Metastore地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://node01:9083</value> </property> <!-- Hive访问Metastore的JDBC连接地址 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value> </property> <!-- Hive访问Metastore的JDBC连接驱动类 --> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <!-- Hive访问Metastore的JDBC连接用户名 --> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- Hive访问Metastore的JDBC连接密码 --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>MySQL_PWD_123</value> </property> <!-- Hive用于存放数据的HDFS目录 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/apps/hive/warehouse</value> </property> <!-- 当datanucleus.schema.autoCreateAll=true且hive. metaore .schema.verification=false会自动创建Hive Metastore相关的表,但不建议这样使用, 推荐使用schematool命令手动初始化Hive Metastore。 --> <property> <name>datanucleus.schema.autoCreateAll</name> <value>true</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <!-- HS2的WebUI监听的主机地址 --> <property> <name>hive.server2.webui.host</name> <value>node01</value> </property> <!-- HS2的WebUI的端口号,默认就是10002 --> <property> <name>hive.server2.webui.port</name> <value>10002</value> </property> <!-- 在HS2 WebUI中查看Query Plan --> <property> <name>hive.log.explain.output</name> <value>true</value> </property> <!-- Hive用于存储不同map/reduce阶段的执行计划和这些阶段的中间输出结果的HDFS目录 --> <property> <name>hive.exec.scratchdir</name> <value>/apps/hive/tmp</value> </property> <!-- 指定scratch目录的权限,默认700 --> <property> <name>hive.scratch.dir.permission</name> <value>733</value> </property> <!-- Hive Thrift客户端使用的用户名 --> <property> <name>hive.server2.thrift.client.user</name> <value>root</value> </property> <!-- Hive Thrift客户端使用的密码 --> <property> <name>hive.server2.thrift.client.password</name> <value>123456</value> </property> </configuration>
2.2.4、设置hive日志
// 修改hive-log4j2.properties.template为hive-log4j2.properties cp /usr/bdp/service/hive/conf/hive-log4j2.properties.template /usr/bdp/service/hive/conf/hive-log4j2.properties // 修改为如下内容
status = INFO name = HiveLog4j2 packages = org.apache.hadoop.hive.ql.log # list of properties property.hive.log.level = INFO property.hive.root.logger = DRFA property.hive.log.dir = /usr/bdp/data/hive/logs property.hive.log.file = hive.log property.hive.perflogger.log.level = INFO # list of all appenders appenders = console, DRFA # console appender appender.console.type = Console appender.console.name = console appender.console.target = SYSTEM_ERR appender.console.layout.type = PatternLayout appender.console.layout.pattern = %d{ISO8601} %5p [%t] %c{2}: %m%n # daily rolling file appender appender.DRFA.type = RollingRandomAccessFile appender.DRFA.name = DRFA appender.DRFA.fileName = ${sys:hive.log.dir}/${sys:hive.log.file} # Use %pid in the filePattern to append <process-id>@<host-name> to the filename if you want separate log files for different CLI session appender.DRFA.filePattern = ${sys:hive.log.dir}/${sys:hive.log.file}.%d{yyyy-MM-dd} appender.DRFA.layout.type = PatternLayout appender.DRFA.layout.pattern = %d{ISO8601} %5p [%t] %c{2}: %m%n appender.DRFA.policies.type = Policies appender.DRFA.policies.time.type = TimeBasedTriggeringPolicy appender.DRFA.policies.time.interval = 1 appender.DRFA.policies.time.modulate = true appender.DRFA.strategy.type = DefaultRolloverStrategy appender.DRFA.strategy.max = 30 # list of all loggers loggers = NIOServerCnxn, ClientCnxnSocketNIO, DataNucleus, Datastore, JPOX, PerfLogger, AmazonAws, ApacheHttp logger.NIOServerCnxn.name = org.apache.zookeeper.server.NIOServerCnxn logger.NIOServerCnxn.level = WARN logger.ClientCnxnSocketNIO.name = org.apache.zookeeper.ClientCnxnSocketNIO logger.ClientCnxnSocketNIO.level = WARN logger.DataNucleus.name = DataNucleus logger.DataNucleus.level = ERROR logger.Datastore.name = Datastore logger.Datastore.level = ERROR logger.JPOX.name = JPOX logger.JPOX.level = ERROR logger.AmazonAws.name=com.amazonaws logger.AmazonAws.level = INFO logger.ApacheHttp.name=org.apache.http logger.ApacheHttp.level = INFO logger.PerfLogger.name = org.apache.hadoop.hive.ql.log.PerfLogger logger.PerfLogger.level = ${sys:hive.perflogger.log.level} # root logger rootLogger.level = ${sys:hive.log.level} rootLogger.appenderRefs = root rootLogger.appenderRef.root.ref = ${sys:hive.root.logger}
2.2.5、添加mysql的驱动jar到$HIVE_HOME/lib/下
// 下载mysql驱动jar到$HIVE_HOME/lib/下
wget -P /usr/bdp/service/hive/lib/ https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.22/mysql-connector-java-8.0.22.jar
2.2.6、手动初始化Hive的Metastore
// 初始化Hive在MySQL中的Metastore schematool -dbType mysql -initSchema
// 查看初始化完成的Hive Metastore(共有74张表)
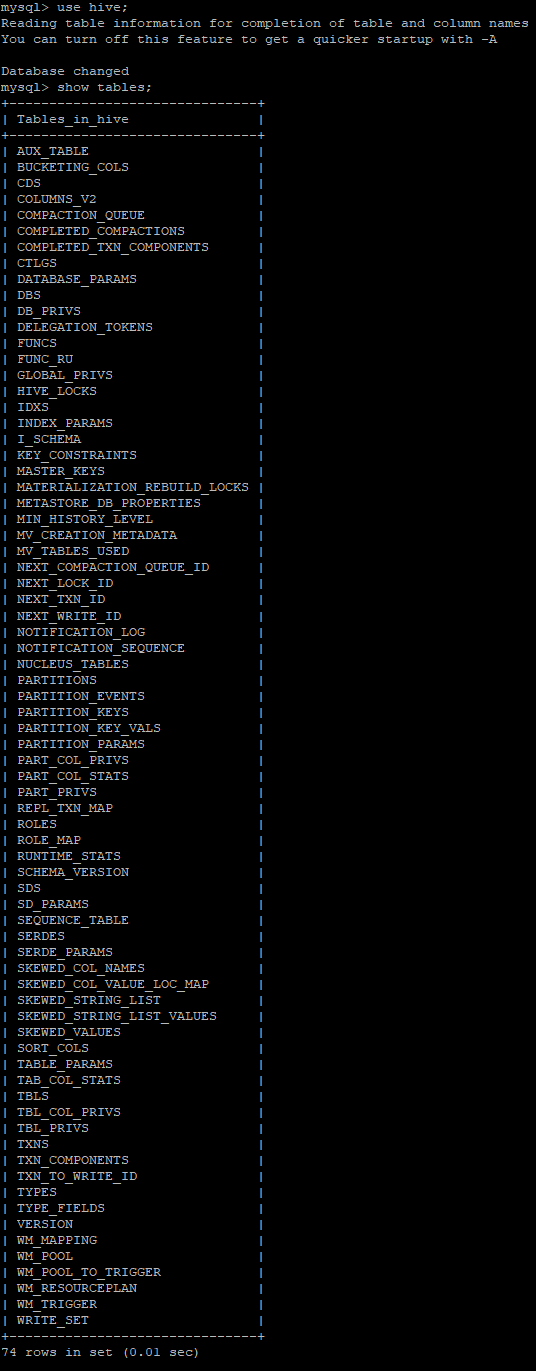
2.2.7、启动Hive的各个守护进程
// 启动Hive Metastore nohup hive --service metastore & // 启动HS2 nohup hive --service hiveserver2 &
2.2.8、验证Hive各个守护进程的运行状态
// 1、使用jsp
[root@node01 hive]# jps
5440 DataNode
6529 JobHistoryServer
5314 NameNode
6947 RunJar
6806 RunJar
5655 SecondaryNameNode
5977 ResourceManager
7161 Jps
6122 NodeManager
// 2、查看WebUI
HS2的地址:http://node01:10002
2.2.9、使用Hive的beeline建库建表
[root@node01 hive]# cd /usr/bdp/service/hive [root@node01 hive]# ./bin/beeline SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/bdp/service/apache-hive-3.1.0-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/bdp/service/hadoop-3.1.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/bdp/service/apache-hive-3.1.0-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/bdp/service/hadoop-3.1.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Beeline version 3.1.0 by Apache Hive beeline> !connect jdbc:hive2://node01:10000/default Connecting to jdbc:hive2://node01:10000/default Enter username for jdbc:hive2://node01:10000/default: root Enter password for jdbc:hive2://node01:10000/default: ****** Connected to: Apache Hive (version 3.1.0) Driver: Hive JDBC (version 3.1.0) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://node01:10000/default> show databases; INFO : Compiling command(queryId=root_20210123000404_5ac71730-cbfa-4cc5-9e68-78cafcc248b7): show databases INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null) INFO : Completed compiling command(queryId=root_20210123000404_5ac71730-cbfa-4cc5-9e68-78cafcc248b7); Time taken: 1.392 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210123000404_5ac71730-cbfa-4cc5-9e68-78cafcc248b7): show databases INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=root_20210123000404_5ac71730-cbfa-4cc5-9e68-78cafcc248b7); Time taken: 0.146 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +----------------+ | database_name | +----------------+ | default | +----------------+ 1 row selected (2.137 seconds) 0: jdbc:hive2://node01:10000/default> create database test_db; INFO : Compiling command(queryId=root_20210123000421_99cbe70b-4b3a-4c9d-8924-7f529b778e6c): create database test_db INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null) INFO : Completed compiling command(queryId=root_20210123000421_99cbe70b-4b3a-4c9d-8924-7f529b778e6c); Time taken: 0.032 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210123000421_99cbe70b-4b3a-4c9d-8924-7f529b778e6c): create database test_db INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=root_20210123000421_99cbe70b-4b3a-4c9d-8924-7f529b778e6c); Time taken: 0.252 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager No rows affected (0.319 seconds) 0: jdbc:hive2://node01:10000/default> show databases; INFO : Compiling command(queryId=root_20210123000424_ea729b54-d62a-4303-b584-1e94bb28c153): show databases INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null) INFO : Completed compiling command(queryId=root_20210123000424_ea729b54-d62a-4303-b584-1e94bb28c153); Time taken: 0.004 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210123000424_ea729b54-d62a-4303-b584-1e94bb28c153): show databases INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=root_20210123000424_ea729b54-d62a-4303-b584-1e94bb28c153); Time taken: 0.021 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +----------------+ | database_name | +----------------+ | default | | test_db | +----------------+ 2 rows selected (0.056 seconds) 0: jdbc:hive2://node01:10000/default> use test_db; INFO : Compiling command(queryId=root_20210123000431_0968b8c0-e9bb-42e1-ab4c-4190fd6be7ca): use test_db INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null) INFO : Completed compiling command(queryId=root_20210123000431_0968b8c0-e9bb-42e1-ab4c-4190fd6be7ca); Time taken: 0.007 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210123000431_0968b8c0-e9bb-42e1-ab4c-4190fd6be7ca): use test_db INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=root_20210123000431_0968b8c0-e9bb-42e1-ab4c-4190fd6be7ca); Time taken: 0.017 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager No rows affected (0.055 seconds) 0: jdbc:hive2://node01:10000/default> create table t1(id bigint,name string); INFO : Compiling command(queryId=root_20210123000452_17faae08-429b-42ac-a3b2-3eb7e057f8f2): create table t1(id bigint,name string) INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null) INFO : Completed compiling command(queryId=root_20210123000452_17faae08-429b-42ac-a3b2-3eb7e057f8f2); Time taken: 0.116 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210123000452_17faae08-429b-42ac-a3b2-3eb7e057f8f2): create table t1(id bigint,name string) INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=root_20210123000452_17faae08-429b-42ac-a3b2-3eb7e057f8f2); Time taken: 1.1 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager No rows affected (1.229 seconds) 0: jdbc:hive2://node01:10000/default> show tables; INFO : Compiling command(queryId=root_20210123000456_b59604e3-4b8a-46ef-9d4b-9c613b6e302d): show tables INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null) INFO : Completed compiling command(queryId=root_20210123000456_b59604e3-4b8a-46ef-9d4b-9c613b6e302d); Time taken: 0.02 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210123000456_b59604e3-4b8a-46ef-9d4b-9c613b6e302d): show tables INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=root_20210123000456_b59604e3-4b8a-46ef-9d4b-9c613b6e302d); Time taken: 0.036 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +-----------+ | tab_name | +-----------+ | t1 | +-----------+ 1 row selected (0.09 seconds) 0: jdbc:hive2://node01:10000> insert into t1(id,name) values(1,'ZhangSan'); INFO : Compiling command(queryId=root_20210124034008_f5204e37-d565-40cb-811e-feab98415951): insert into t1(id,name) values(1,'ZhangSan') INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_col0, type:bigint, comment:null), FieldSchema(name:_col1, type:string, comment:null)], properties:null) INFO : Completed compiling command(queryId=root_20210124034008_f5204e37-d565-40cb-811e-feab98415951); Time taken: 4.676 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210124034008_f5204e37-d565-40cb-811e-feab98415951): insert into t1(id,name) values(1,'ZhangSan') WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. INFO : Query ID = root_20210124034008_f5204e37-d565-40cb-811e-feab98415951 INFO : Total jobs = 3 INFO : Launching Job 1 out of 3 INFO : Starting task [Stage-1:MAPRED] in serial mode INFO : Number of reduce tasks determined at compile time: 1 INFO : In order to change the average load for a reducer (in bytes): INFO : set hive.exec.reducers.bytes.per.reducer=<number> INFO : In order to limit the maximum number of reducers: INFO : set hive.exec.reducers.max=<number> INFO : In order to set a constant number of reducers: INFO : set mapreduce.job.reduces=<number> INFO : number of splits:1 INFO : Submitting tokens for job: job_1611477182476_0002 INFO : Executing with tokens: [] INFO : The url to track the job: http://node01:8088/proxy/application_1611477182476_0002/ INFO : Starting Job = job_1611477182476_0002, Tracking URL = http://node01:8088/proxy/application_1611477182476_0002/ INFO : Kill Command = /usr/bdp/service/hadoop/bin/mapred job -kill job_1611477182476_0002 INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 INFO : 2021-01-24 03:40:35,459 Stage-1 map = 0%, reduce = 0% INFO : 2021-01-24 03:40:46,179 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.97 sec INFO : 2021-01-24 03:40:56,693 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.87 sec INFO : MapReduce Total cumulative CPU time: 3 seconds 870 msec INFO : Ended Job = job_1611477182476_0002 INFO : Starting task [Stage-7:CONDITIONAL] in serial mode INFO : Stage-4 is selected by condition resolver. INFO : Stage-3 is filtered out by condition resolver. INFO : Stage-5 is filtered out by condition resolver. INFO : Starting task [Stage-4:MOVE] in serial mode INFO : Moving data to directory hdfs://node01:9820/apps/hive/warehouse/test_db.db/t1/.hive-staging_hive_2021-01-24_03-40-08_111_7941257932918288775-1/-ext-10000 from hdfs://node01:9820/apps/hive/warehouse/test_db.db/t1/.hive-staging_hive_2021-01-24_03-40-08_111_7941257932918288775-1/-ext-10002 INFO : Starting task [Stage-0:MOVE] in serial mode INFO : Loading data to table test_db.t1 from hdfs://node01:9820/apps/hive/warehouse/test_db.db/t1/.hive-staging_hive_2021-01-24_03-40-08_111_7941257932918288775-1/-ext-10000 INFO : Starting task [Stage-2:STATS] in serial mode INFO : MapReduce Jobs Launched: INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.87 sec HDFS Read: 15518 HDFS Write: 240 SUCCESS INFO : Total MapReduce CPU Time Spent: 3 seconds 870 msec INFO : Completed executing command(queryId=root_20210124034008_f5204e37-d565-40cb-811e-feab98415951); Time taken: 49.226 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager No rows affected (53.937 seconds) 0: jdbc:hive2://node01:10000> insert into t1(id,name) values(2,'LiSi'); INFO : Compiling command(queryId=root_20210124034113_47128349-d466-43de-8f8c-1f6ce7eae691): insert into t1(id,name) values(2,'LiSi') INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_col0, type:bigint, comment:null), FieldSchema(name:_col1, type:string, comment:null)], properties:null) INFO : Completed compiling command(queryId=root_20210124034113_47128349-d466-43de-8f8c-1f6ce7eae691); Time taken: 0.513 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210124034113_47128349-d466-43de-8f8c-1f6ce7eae691): insert into t1(id,name) values(2,'LiSi') WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. INFO : Query ID = root_20210124034113_47128349-d466-43de-8f8c-1f6ce7eae691 INFO : Total jobs = 3 INFO : Launching Job 1 out of 3 INFO : Starting task [Stage-1:MAPRED] in serial mode INFO : Number of reduce tasks determined at compile time: 1 INFO : In order to change the average load for a reducer (in bytes): INFO : set hive.exec.reducers.bytes.per.reducer=<number> INFO : In order to limit the maximum number of reducers: INFO : set hive.exec.reducers.max=<number> INFO : In order to set a constant number of reducers: INFO : set mapreduce.job.reduces=<number> INFO : number of splits:1 INFO : Submitting tokens for job: job_1611477182476_0003 INFO : Executing with tokens: [] INFO : The url to track the job: http://node01:8088/proxy/application_1611477182476_0003/ INFO : Starting Job = job_1611477182476_0003, Tracking URL = http://node01:8088/proxy/application_1611477182476_0003/ INFO : Kill Command = /usr/bdp/service/hadoop/bin/mapred job -kill job_1611477182476_0003 INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 INFO : 2021-01-24 03:41:34,841 Stage-1 map = 0%, reduce = 0% INFO : 2021-01-24 03:41:46,351 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.56 sec INFO : 2021-01-24 03:41:56,848 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.55 sec INFO : MapReduce Total cumulative CPU time: 4 seconds 550 msec INFO : Ended Job = job_1611477182476_0003 INFO : Starting task [Stage-7:CONDITIONAL] in serial mode INFO : Stage-4 is selected by condition resolver. INFO : Stage-3 is filtered out by condition resolver. INFO : Stage-5 is filtered out by condition resolver. INFO : Starting task [Stage-4:MOVE] in serial mode INFO : Moving data to directory hdfs://node01:9820/apps/hive/warehouse/test_db.db/t1/.hive-staging_hive_2021-01-24_03-41-13_926_8184090159289106008-1/-ext-10000 from hdfs://node01:9820/apps/hive/warehouse/test_db.db/t1/.hive-staging_hive_2021-01-24_03-41-13_926_8184090159289106008-1/-ext-10002 INFO : Starting task [Stage-0:MOVE] in serial mode INFO : Loading data to table test_db.t1 from hdfs://node01:9820/apps/hive/warehouse/test_db.db/t1/.hive-staging_hive_2021-01-24_03-41-13_926_8184090159289106008-1/-ext-10000 INFO : Starting task [Stage-2:STATS] in serial mode ERROR : FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.StatsTask INFO : MapReduce Jobs Launched: INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.55 sec HDFS Read: 15524 HDFS Write: 236 SUCCESS INFO : Total MapReduce CPU Time Spent: 4 seconds 550 msec INFO : Completed executing command(queryId=root_20210124034113_47128349-d466-43de-8f8c-1f6ce7eae691); Time taken: 45.036 seconds INFO : Concurrency mode is disabled, not creating a lock manager Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.StatsTask (state=08S01,code=1) 0: jdbc:hive2://node01:10000> select * from t1; INFO : Compiling command(queryId=root_20210124034258_97c5bb69-a3ee-493d-9b05-1f132ebbc5db): select * from t1 INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t1.id, type:bigint, comment:null), FieldSchema(name:t1.name, type:string, comment:null)], properties:null) INFO : Completed compiling command(queryId=root_20210124034258_97c5bb69-a3ee-493d-9b05-1f132ebbc5db); Time taken: 0.224 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210124034258_97c5bb69-a3ee-493d-9b05-1f132ebbc5db): select * from t1 INFO : Completed executing command(queryId=root_20210124034258_97c5bb69-a3ee-493d-9b05-1f132ebbc5db); Time taken: 0.0 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +--------+-----------+ | t1.id | t1.name | +--------+-----------+ | 1 | ZhangSan | | 2 | LiSi | +--------+-----------+ 2 rows selected (0.361 seconds) 0: jdbc:hive2://node01:10000> select * from t1 limit 1; INFO : Compiling command(queryId=root_20210124034302_dc71f43a-44e7-464a-8d03-ba2a3c2536c7): select * from t1 limit 1 INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t1.id, type:bigint, comment:null), FieldSchema(name:t1.name, type:string, comment:null)], properties:null) INFO : Completed compiling command(queryId=root_20210124034302_dc71f43a-44e7-464a-8d03-ba2a3c2536c7); Time taken: 0.191 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210124034302_dc71f43a-44e7-464a-8d03-ba2a3c2536c7): select * from t1 limit 1 INFO : Completed executing command(queryId=root_20210124034302_dc71f43a-44e7-464a-8d03-ba2a3c2536c7); Time taken: 0.0 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +--------+-----------+ | t1.id | t1.name | +--------+-----------+ | 1 | ZhangSan | +--------+-----------+ 1 row selected (0.236 seconds) 0: jdbc:hive2://node01:10000> select * from t1 where id=1; INFO : Compiling command(queryId=root_20210124034319_9e80a128-ceec-4ca7-8665-224a36d248f0): select * from t1 where id=1 INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t1.id, type:bigint, comment:null), FieldSchema(name:t1.name, type:string, comment:null)], properties:null) INFO : Completed compiling command(queryId=root_20210124034319_9e80a128-ceec-4ca7-8665-224a36d248f0); Time taken: 0.357 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210124034319_9e80a128-ceec-4ca7-8665-224a36d248f0): select * from t1 where id=1 INFO : Completed executing command(queryId=root_20210124034319_9e80a128-ceec-4ca7-8665-224a36d248f0); Time taken: 0.0 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +--------+-----------+ | t1.id | t1.name | +--------+-----------+ | 1 | ZhangSan | +--------+-----------+ 1 row selected (0.413 seconds)
2.3、安装Spark-2.4.6
2.3.1、spark-env.sh
// 修改spark-env.sh.template为spark-env.sh cp /usr/bdp/service/spark/conf/spark-env.sh.template /usr/bdp/service/spark/conf/spark-env.sh // 编辑spark-env.sh配置 vim /usr/bdp/service/spark/conf/spark-env.sh // 新增如下内容
HADOOP_CONF_DIR=/usr/bdp/service/hadoop/etc/hadoop YARN_CONF_DIR=/usr/bdp/service/hadoop/etc/hadoop
2.3.2、spark-defaults.conf
// 修改spark-defaults.conf.template为spark-defaults.conf
cp /usr/bdp/service/spark/conf/spark-defaults.conf.template /usr/bdp/service/spark/conf/spark-defaults.conf
// 编辑spark-defaults.conf配置
vim /usr/bdp/service/spark/conf/spark-defaults.conf
// 改为如下内容
spark.master=yarn
spark.submit.deployMode=cluster
#spark.dynamicAllocation.enabled=true
#spark.shuffle.service.enabled=true
spark.serializer=org.apache.spark.serializer.KryoSerializer
spark.shuffle.file.buffer=1m
spark.shuffle.io.backLog=8
spark.shuffle.io.serverThreads=8
spark.shuffle.unsafe.file.output.buffer=5m
spark.sql.autoBroadcastJoinThreshold=26214400
spark.history.fs.logDirectory=hdfs://node01:9820/apps/spark/history
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs://node01:9820/apps/spark/history
spark.history.ui.port=18081
spark.yarn.historyServer.address=node01:18081
spark.yarn.historyServer.allowTracking=true
spark.driver.memory=512m
spark.executor.memory=1024m
spark.yarn.archive=hdfs://node01:9820/apps/spark/archive/spark-jars.jar
spark.sql.warehouse.dir=hdfs://node01:9820/apps/hive/warehouse
2.3.3、初始化spark-defaults.conf中的需要的文件和目录
// spark.history.fs.logDirectory:Spark App的历史日志 hdfs dfs -mkdir -p hdfs://node01:9820/apps/spark/history
// spark.yarn.archive: Spark App所需的jar存档(见2.3.3.1)
hdfs dfs -mkdir -p hdfs://node01:9820/apps/spark/archive
2.3.3.1、生成spark.yarn.archive配置所需的jar包存档
// 进入$SPARK_HOME
cd /usr/bdp/service/spark
// 先将yarn目录下的spark-2.4.6-yarn-shuffle.jar复制到jars目录下
cp /usr/bdp/service/spark/yarn/spark-2.4.6-yarn-shuffle.jar /usr/bdp/service/spark/jars/
// 再把jars目录下的所有jar包打成一个大的jar包存档文件(c表示创建存档文件;v从标准输出中打印详情;0表示只存储不做zip压缩;f指定存档文件名称;)
jar cv0f spark-jars.jar -C /usr/bdp/service/spark/jars/ .
// 最后上传到HDFS的指定目录下
hdfs dfs -put spark-jars.jar /apps/spark/archive/
// 查看HDFS上的jar包存档文件
hdfs dfs -ls hdfs://node01:9820/apps/spark/archive/spark-jars.jar
2.3.4、启动Spark History Server
// 进入SPARK_HOME
cd /usr/bdp/service/spark
// 启动Spark History Server ./sbin/start-history-server.sh
2.3.5、验证Spark History Server守护进行的运行状态
// 1、使用jps [root@node01 spark]# jps 5440 DataNode 10848 Jps 6529 JobHistoryServer 5314 NameNode 6947 RunJar 10723 HistoryServer 6806 RunJar 5655 SecondaryNameNode 5977 ResourceManager 6122 NodeManager // 2、查看WebUI Spark History Server地址:http://node01:18081

