Apache Hudi(0.6.0)快速入门
1.1 Hudi是什么
Apache Hudi(Hadoop Upserts Deletes and Incrementals,简称Hudi,发音为Hoodie)由UBer开源,它以极低的延迟将数据快速摄取到HDFS或云存储(S3)中,其最主要的特点是支持记录(Record)级别的插入更新(Upsert)和删除,同时还提供增量查询的支持。
本质上,Hudi并非是一种全新的文件格式,相反,它仅仅是充分利用了开源的列格式(Parquet)和行格式(Avro)的文件作为数据的存储形式,并在数据写入的同时生成特定的索引,进而可以提供更快的查询性能。
Hudi自身无法完成对数据的读写操作,它强依赖于外部的Spark、Flink、Presto和Impala等计算引擎才可以使用,目前尤其对Spark依赖严重(在0.7.0中新增了Flink支持)。
1.2 Hudi的应用场景
1.2.1 近实时摄取
| 数据源系统 | Hudi的摄取方式 | 目标存储系统 |
|---|---|---|
| RDBMS | 使用Upsert加载数据,通过读取BinLog或Sqoop增量数据写入到HDFS上的Hudi表,可以避免低效的全量加载。 | HDFS |
| NoSQL | 使用HBase表来维护Hudi数据的索引,但实际数据依旧是位于HDFS中。 | HBase+HDFS |
| MQ | Hudi在处理Kafka这种数据源时可以强制使用最小文件大小来改善NameNode负载,避免了频繁创建小文件的问题。 | HDFS |
1.2.2 近实时分析
SQL on Hadoop解决方案(如Presto和Spark SQL)具有出色的性能,一般可以在**几秒钟内完成查询**。而Hudi是一个可以提供面向实时分析更有效的替代方案,并支持对存储在HDFS中更大规模数据集的近实时查询。此外,它是一个非常轻量级的库,无需额外的组件依赖即可使用,并不会增加操作开销。
1.2.3 增量处理管道
1.2.4 HDFS数据分发
一个常见的用例是先在Hadoop体系中进行处理数据,然后再分发回面向在线服务的存储系统,以供应用程序使用。在这种用例中一般都会引入诸如Kafka之类的队列系统来防止目标存储系统被压垮。但如果不使用Kafka的情况下,仅将每次运行的Spark管道更新插入的输出转换为Hudi数据集,也可以有效地解决这个问题,然后以增量方式获取数据(就像读取Kafka topic一样)写入服务存储层。
1.3 Hudi的核心概念
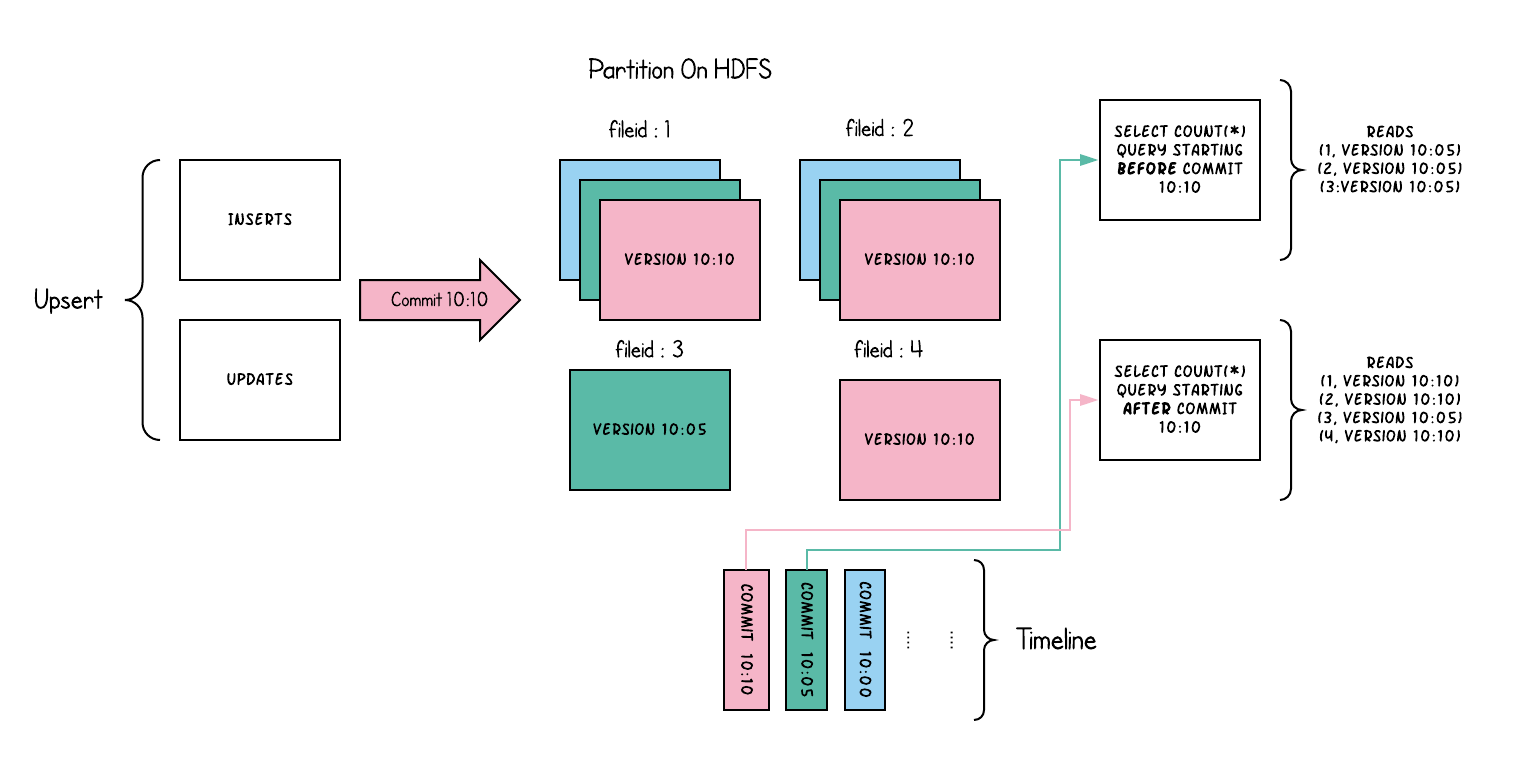
1.3.1 时间轴(Timeline)
。
-
时间轴(Timeline)的实现类(位于hudi-common-0.6.0.jar中):
注意:由于hudi-spark-bundle.jar和hudi-hadoop-mr-bundle.jar属于Uber类型的jar包,已经将hudi-common-0.6.0.jar的所有class打包进去了。时间轴相关的实现类位于org.apache.hudi.common.table.timeline包下。
最顶层的接口约定类为:HoodieTimeline。
默认使用的时间轴类:HoodieDefaultTimeline继承自HoodieTimeline。
活动时间轴类为:HoodieActiveTimeline(此类维护最近12小时内的时间,可配置)。
存档时间轴类为:HoodieArchivedTimeline(超出12小时的时间在此类中维护,可配置)。
-
时间轴(Timeline)的核心组件:
| 组件名称 | 组件说明 |
|---|---|
| Instant action |
在时间轴上执行的操作 COMMITS(一次提交表示将一组记录原子写入到数据集中) CLEANS(删除数据集中不再需要的旧文件版本的后台活动) DELTA_COMMIT(增量提交,将一批记录原子写入到MOR表) COMPACTION(比如更新从基于行的日志文件变成列格式) ROLLBACK(指提交/增量提交不成功且已回滚并删除在写入时产生的文件) SAVEPOINT(在发生失败时将数据还原到时间轴的某个即时时间) 实现类:org.apache.hudi.common.table.timeline.HoodieTimeline |
| Instant time |
是一个时间戳(格式为20190117010349)且单调增加。 实现类:org.apache.hudi.common.table.timeline.HoodieInstant |
| State |
即时的状态包括: REQUESTED(已调度但尚未启动) INFLIGHT(正在执行操作) COMPLETED(操作完成) INVALID(操作失败) 实现类:org.apache.hudi.common.table.timeline.HoodieInstant.State |
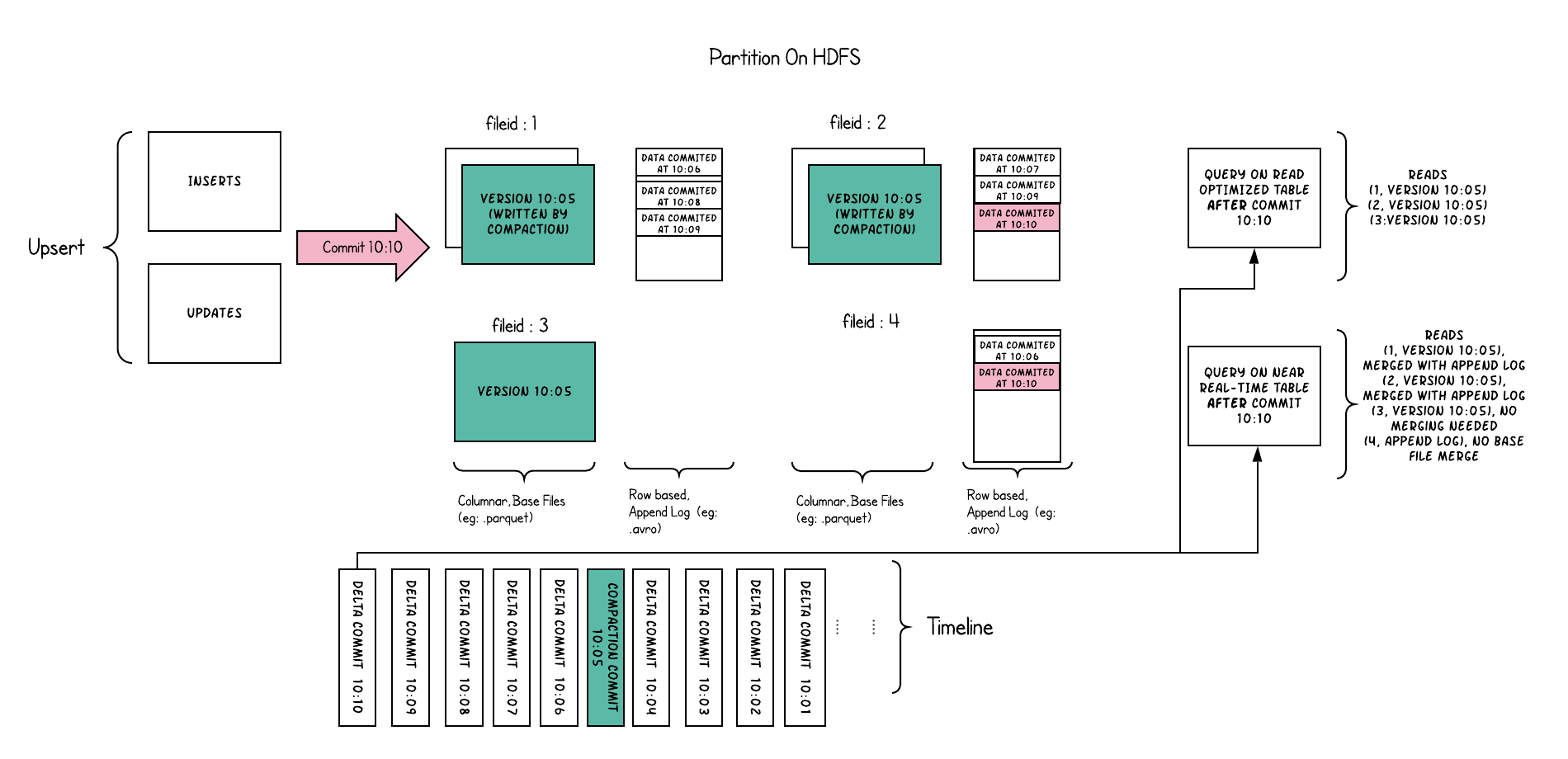
1.3.2 文件组织形式
Hudi将DFS上的数据集组织到基本路径(HoodieWriteConfig.BASE_PATH_PROP)下的目录结构中。数据集分为多个分区(DataSourceOptions.PARTITIONPATH_FIELD_OPT_KEY),这些分区与Hive表非常相似,是包含该分区的数据文件的文件夹。
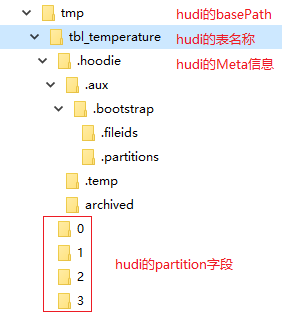
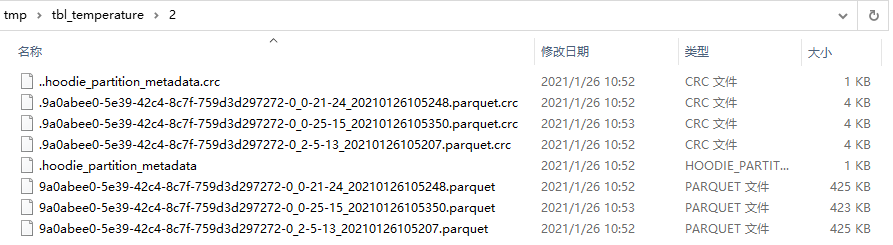
在每个分区内,文件被组织为文件组,由文件id充当唯一标识。 每个文件组包含多个文件切片,其中每个切片包含在某个即时时间的提交/压缩生成的基本列文件(.parquet)以及一组日志文件(.log),该文件包含自生成基本文件以来对基本文件的插入/更新。 Hudi采用MVCC设计,其中压缩操作将日志和基本文件合并以产生新的文件切片,而清理操作则将未使用的/较旧的文件片删除以回收DFS上的空间。
1.3.3 索引机制(4类6种)
Hudi通过索引机制提供高效的Upsert操作,该机制会将一个RecordKey+PartitionPath组合的方式作为唯一标识映射到一个文件ID,而且,这个唯一标识和文件组/文件ID之间的映射自记录被写入文件组开始就不会再改变。Hudi内置了4类(6个)索引实现,均是继承自顶层的抽象类HoodieIndex而来,如下:
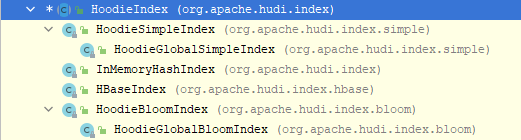
| 索引类型 | 实现类 | 索引规则 |
|---|---|---|
| Simple | HoodieSimpleIndex | 简单索引,基于RecordKey+PartitionPath组合的方式作为索引,仅在特定分区内查找数据。 |
| HoodieGlobalSimpleIndex | 简单的全局索引,基于RecordKey+PartitionPath组合的方式作为索引,在全部分区中查找数据。 | |
| Memory | InMemoryHashIndex | 由内存中维护的HashMap来支持的Hoodie Index实现,基于RecordKey+PartitionPath组合的方式作为索引。 |
| HBase | HBaseIndex |
在HBase中维护Hoodie Index。 存储Index的HBase表名称使用HoodieHBaseIndexConfig.HBASE_TABLENAME_PROP指定, Row_Key是RecordKey, 列簇是HBaseIndex.SYSTEM_COLUMN_FAMILY(默认为_s), 还包括3个默认的列,即: HBaseIndex.COMMIT_TS_COLUMN(默认为commit_ts)、 HBaseIndex.FILE_NAME_COLUMN(默认为file_name)、 HBaseIndex.PARTITION_PATH_COLUMN(默认为partition_path)。 |
| Bloom | HoodieBloomIndex | 基于布隆过滤器实现的索引机制,仅在特定分区内查找。每个Parquet文件在其元数据中都包含其row_key的Bloom筛选器。 |
| HoodieGlobalBloomIndex | 基于布隆过滤器实现的全局索引机制,会在所有分区中查找。它会先获取所有分区(只加载带有.hoodie_partition_metadata文件的分区),然后再加载各分区内的最新文件。 |
注意:
-
全局索引:指在全表的所有分区范围下强制要求键保持唯一,即确保对给定的键有且只有一个对应的记录。全局索引提供了更强的保证,也使得更删的消耗随着表的大小增加而增加(O(表的大小)),更适用于是小表。
-
非全局索引:仅在表的某一个分区内强制要求键保持唯一,它依靠写入器为同一个记录的更删提供一致的分区路径,但由此同时大幅提高了效率,因为索引查询复杂度成了O(更删的记录数量)且可以很好地应对写入量的扩展。
1.3.4 查询视图(3类)
-
读优化视图 : 直接查询基本文件(数据集的最新快照),其实就是列式文件(Parquet)。并保证与非Hudi列式数据集相比,具有相同的列式查询性能。
-
增量视图 : 仅查询新写入数据集的文件,需要指定一个Commit/Compaction的即时时间(位于Timeline上的某个Instant)作为条件,来查询此条件之后的新数据。
-
实时快照视图 : 查询某个增量提交操作中数据集的最新快照,会先进行动态合并最新的基本文件(Parquet)和增量文件(Avro)来提供近实时数据集(通常会存在几分钟的延迟)。

| 权衡 | 读优化视图 | 实时快照视图 | 增量视图 |
|---|---|---|---|
| 数据延迟 | 更高 | 更低 | 更高 |
| 查询延迟 | 更低(原始列式性能) | 更低(查询会先合并列式+行增量) | 更低 |
1.4 Hudi支持的存储类型
1.4.1 写时复制(Copy on Write,COW)表
COW表主要使用列式文件格式(Parquet)存储数据,在写入数据过程中,执行同步合并,更新数据版本并重写数据文件,类似RDBMS中的B-Tree更新。
1) 更新:在更新记录时,Hudi会先找到包含更新数据的文件,然后再使用更新值(最新的数据)重写该文件,包含其他记录的文件保持不变。当突然有大量写操作时会导致重写大量文件,从而导致极大的I/O开销。
2)读取:在读取数据集时,通过读取最新的数据文件来获取最新的更新,此存储类型适用于少量写入和大量读取的场景。
1.4.2 读时合并(Merge On Read,MOR)表
MOR表是COW表的升级版,它使用列式(parquet)与行式(avro)文件混合的方式存储数据。在更新记录时,类似NoSQL中的LSM-Tree更新。
1) 更新:在更新记录时,仅更新到增量文件(Avro)中,然后进行异步(或同步)的compaction,最后创建列式文件(parquet)的新版本。此存储类型适合频繁写的工作负载,因为新记录是以追加的模式写入增量文件中。
2) 读取:在读取数据集时,需要先将增量文件与旧文件进行合并,然后生成列式文件成功后,再进行查询。
1.4.3 COW和MOR的对比
| 权衡 | 写时复制COW | 读时合并MOR |
|---|---|---|
| 数据延迟 | 更高 | 更低 |
| 更新代价(I/O) | 更高(重写整个parquet文件) | 更低(追加到增量日志) |
| Parquet文件大小 | 更小(高更新代价(I/O)) | 更大(低更新代价) |
| 写放大 | 更高 | 更低(取决于压缩策略) |
| 适用场景 | 写少读多 | 写多读少 |
1.4.4 COW和MOR支持的视图
| 存储类型 | 支持的视图 | 不支持的视图 | |
|---|---|---|---|
| COW | 读优化 + 增量 + 实时视图 | 无 | |
| MOR | 读优化 + 近实时 |
增量(如果使用增量视图查询时会提示:Incremental view not implemented yet, for merge-on-read tables) |
|
1.5 安装Hudi
1.5.1 自行编译(待验证)
// 下载hudi的源码发行版 wget -P /tmp/ http://archive.apache.org/dist/hudi/0.6.0/hudi-0.6.0.src.tgz // 解压hudi到/usr/hdp/current/下 tar -zxf /tmp/hudi-0.6.0.src.tgz -C /usr/hdp/current/ // 编译hudi(确保服务器上有$SCALA_HOME) mvn -DskipTests clean package
// 下载Hudi on Spark的Jar包(放入$SPARK_HOME/jars/下) wget https://repo1.maven.org/maven2/org/apache/hudi/hudi-spark-bundle_2.11/0.6.0/hudi-spark-bundle_2.11-0.6.0.jar // 下载Hudi on MapReduce的Jar包(放入$HADOOP_HOME/share/hadoop/mapreduce/下) wget https://repo1.maven.org/maven2/org/apache/hudi/hudi-hadoop-mr-bundle/0.6.0/hudi-hadoop-mr-bundle-0.6.0.jar // 创建软连接(在$HIVE_HOME/lib/下) ln -s $SPARK_HOME/jars/ $HIVE_HOME/lib/ ln -s $HADOOP_HOME/share/hadoop/mapreduce/hudi-hadoop-mr-bundle-0.6.0.jar $HIVE_HOME/lib/
1.6 Hudi的SparkSQL使用
Hudi支持对文件系统(HDFS、LocalFS)和Hive的读写操作,以下分别使用COW和MOR存储类型来操作文件系统和Hive的案例。
1.6.1 文件系统操作
1.6.1.1 基于COW表的LocalFS/HDFS使用
package com.mengyao.hudi import com.mengyao.Configured import org.apache.spark.sql.SaveMode._ import org.apache.hudi.DataSourceReadOptions._ import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.common.model.EmptyHoodieRecordPayload import org.apache.hudi.config.HoodieIndexConfig._ import org.apache.hudi.config.HoodieWriteConfig._ import org.apache.hudi.index.HoodieIndex import org.apache.spark.SparkConf import org.apache.spark.sql.functions._ import org.apache.spark.sql.{DataFrame, SparkSession} import scala.collection.JavaConverters._ /** * Spark on Hudi(COW表) to HDFS/LocalFS * @ClassName Demo1 * @Description * @Created by: MengYao * @Date: 2021-01-11 10:10:53 * @Version V1.0 */ object Demo1 { private val APP_NAME = Demo1.getClass.getSimpleName private val MASTER = "local[2]" val SOURCE = "hudi" val insertData = Array[TemperatureBean]( new TemperatureBean("4301",1,28.6,"2019-12-07 12:35:33"), new TemperatureBean("4312",0,31.4,"2019-12-07 12:25:03"), new TemperatureBean("4302",1,30.1,"2019-12-07 12:32:17"), new TemperatureBean("4305",3,31.5,"2019-12-07 12:33:11"), new TemperatureBean("4310",2,29.9,"2019-12-07 12:34:42") ) val updateData = Array[TemperatureBean]( new TemperatureBean("4310",2,30.4,"2019-12-07 12:35:42")// 设备ID为4310的传感器发生修改,温度值由29.9->30.4,时间由12:34:42->12:35:42 ) val deleteData = Array[TemperatureBean]( new TemperatureBean("4310",2,30.4,"2019-12-07 12:35:42")// 设备ID为4310的传感器要被删除,必须与最新的数据保持一致(如果字段值不同时无法删除) ) def main(args: Array[String]): Unit = { System.setProperty(Configured.HADOOP_HOME_DIR, Configured.getHadoopHome) // 创建SparkConf val conf = new SparkConf() .set("spark.master", MASTER) .set("spark.app.name", APP_NAME) .setAll(Configured.sparkConf().asScala) // 创建SparkSession val spark = SparkSession.builder() .config(conf) .getOrCreate() // 关闭日志 spark.sparkContext.setLogLevel("OFF") // 导入隐式转换 import spark.implicits._ import DemoUtils._ // 类似Hive中的DB(basePath的schema决定了最终要操作的文件系统,如果是file:则为LocalFS,如果是hdfs:则为HDFS) val basePath = "file:/D:/tmp" // 类似Hive中的Table val tableName = "tbl_temperature_cow1" // 数据所在的路径 val path = s"$basePath/$tableName" // 插入数据 insert(spark.createDataFrame(insertData.toBuffer.asJava, classOf[TemperatureBean]), tableName, "deviceId", "deviceType", "cdt", path) // 修改数据 // update(spark.createDataFrame(updateData.toBuffer.asJava, classOf[TemperatureBean]), tableName, "deviceId", "deviceType", "cdt", path) // 删除数据 // delete(spark.createDataFrame(deleteData.toBuffer.asJava, classOf[TemperatureBean]), tableName, "deviceId", "deviceType", "cdt", path) // 【查询方式1:默认为快照(基于行或列获取最新视图)查询 // query(spark.read.format(SOURCE).load(s"$path/*/*").orderBy($"deviceId".asc)) // query(spark.read.format(SOURCE).options(buildQuery(QUERY_TYPE_SNAPSHOT_OPT_VAL)).load(s"$path/*/*").withColumn("queryType", lit("查询方式为:快照(默认)")).orderBy($"deviceId".asc)) // 【查询方式2:读时优化 // query(spark.read.format(SOURCE).options(buildQuery(QUERY_TYPE_READ_OPTIMIZED_OPT_VAL)).load(s"$path/*/*").withColumn("queryType", lit("查询方式为:读时优化")).orderBy($"deviceId".asc)) // 【查询方式3:增量查询 // 先取出最近一次提交的时间 // val commitTime: String = spark.read.format(SOURCE).load(s"$path/*/*").dropDuplicates("_hoodie_commit_time").select($"_hoodie_commit_time".as("commitTime")).orderBy($"commitTime".desc).first().getAs(0) // 再查询最近提交时间之后的数据 // query(spark.read.format(SOURCE).options(buildQuery(QUERY_TYPE_INCREMENTAL_OPT_VAL,Option((commitTime.toLong-2).toString))).load(s"$path/*/*").withColumn("queryType", lit("查询方式为:增量查询")).orderBy($"deviceId".asc).toDF()) spark.close() } /** * 新增数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def insert(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(默认COW) TABLE_TYPE_OPT_KEY -> COW_TABLE_TYPE_OPT_VAL, // 执行insert操作 OPERATION_OPT_KEY->INSERT_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的,必须是数值类型 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.BLOOM.name, // 执行insert操作的shuffle并行度 INSERT_PARALLELISM->"2" )) // 如果数据存在会覆盖 .mode(Overwrite) .save(path) } /** * 修改数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def update(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(默认COW) TABLE_TYPE_OPT_KEY -> COW_TABLE_TYPE_OPT_VAL, // 执行upsert操作 OPERATION_OPT_KEY->UPSERT_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.BLOOM.name, // 执行upsert操作的shuffle并行度 UPSERT_PARALLELISM-> "2" )) // 如果数据存在会覆盖 .mode(Append) .save(path) } /** * 删除数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def delete(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(默认COW) TABLE_TYPE_OPT_KEY -> COW_TABLE_TYPE_OPT_VAL, // 执行delete操作 OPERATION_OPT_KEY->DELETE_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.BLOOM.name, // 执行delete操作的shuffle并行度 DELETE_PARALLELISM->"2", // 删除策略有软删除(保留主键且其余字段为null)和硬删除(从数据集中彻底删除)两种,此处为硬删除 PAYLOAD_CLASS_OPT_KEY->classOf[EmptyHoodieRecordPayload].getName )) // 如果数据存在会覆盖 .mode(Append) .save(path) } /** * 查询类型 * <br>Hoodie具有3种查询模式:</br> * <br>1、默认是快照模式(Snapshot mode,根据行和列数据获取最新视图)</br> * <br>2、增量模式(incremental mode,查询从某个commit时间片之后的数据)</br> * <br>3、读时优化模式(Read Optimized mode,根据列数据获取最新视图)</br> * @param queryType * @param queryTime * @return */ def buildQuery(queryType: String, queryTime: Option[String]=Option.empty) = Map( queryType match { // 如果是读时优化模式(read_optimized,根据列数据获取最新视图) case QUERY_TYPE_READ_OPTIMIZED_OPT_VAL => QUERY_TYPE_OPT_KEY->QUERY_TYPE_READ_OPTIMIZED_OPT_VAL // 如果是增量模式(incremental mode,查询从某个时间片之后的新数据) case QUERY_TYPE_INCREMENTAL_OPT_VAL => QUERY_TYPE_OPT_KEY->QUERY_TYPE_INCREMENTAL_OPT_VAL // 默认使用快照模式查询(snapshot mode,根据行和列数据获取最新视图) case _ => QUERY_TYPE_OPT_KEY->QUERY_TYPE_SNAPSHOT_OPT_VAL }, if(queryTime.nonEmpty) BEGIN_INSTANTTIME_OPT_KEY->queryTime.get else BEGIN_INSTANTTIME_OPT_KEY->"0" ) }
1.6.1.2 基于MOR表的LocalFS/HDFS使用
package com.mengyao.hudi import com.mengyao.Configured import org.apache.hudi.DataSourceReadOptions._ import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.common.model.EmptyHoodieRecordPayload import org.apache.hudi.config.HoodieIndexConfig.INDEX_TYPE_PROP import org.apache.hudi.config.HoodieWriteConfig._ import org.apache.hudi.index.HoodieIndex import org.apache.spark.sql.{DataFrame, SparkSession} import org.apache.spark.sql.SaveMode._ import org.apache.spark.SparkConf import org.apache.spark.sql.functions.lit import scala.collection.JavaConverters._ /** * Spark on Hudi(MOR表) to HDFS/LocalFS * @ClassName Demo1 * @Description * @Created by: MengYao * @Date: 2021-01-11 10:10:53 * @Version V1.0 */ object Demo2 { private val APP_NAME: String = Demo1.getClass.getSimpleName private val MASTER: String = "local[2]" val SOURCE: String = "hudi" val insertData = Array[TemperatureBean]( new TemperatureBean("4301",1,28.6,"2019-12-07 12:35:33"), new TemperatureBean("4312",0,31.4,"2019-12-07 12:25:03"), new TemperatureBean("4302",1,30.1,"2019-12-07 12:32:17"), new TemperatureBean("4305",3,31.5,"2019-12-07 12:33:11"), new TemperatureBean("4310",2,29.9,"2019-12-07 12:34:42") ) val updateData = Array[TemperatureBean]( new TemperatureBean("4310",2,30.4,"2019-12-07 12:35:42")// 设备ID为4310的传感器发生修改,温度值由29.9->30.4,时间由12:34:42->12:35:42 ) val deleteData = Array[TemperatureBean]( new TemperatureBean("4310",2,30.4,"2019-12-07 12:35:42")// 设备ID为4310的传感器要被删除,必须与最新的数据保持一致(如果字段值不同时无法删除) ) def main(args: Array[String]): Unit = { System.setProperty(Configured.HADOOP_HOME_DIR, Configured.getHadoopHome) // 创建SparkConf val conf = new SparkConf() .set("spark.master", MASTER) .set("spark.app.name", APP_NAME) .setAll(Configured.sparkConf().asScala) // 创建SparkSession val spark = SparkSession.builder() .config(conf) .getOrCreate() // 关闭日志 spark.sparkContext.setLogLevel("OFF") // 导入隐式转换 import spark.implicits._ import DemoUtils._ // 类似Hive中的DB(basePath的schema决定了最终要操作的文件系统,如果是file:则为LocalFS,如果是hdfs:则为HDFS) val basePath = "file:/D:/tmp" // 类似Hive中的Table val tableName = "tbl_temperature_mor" // 数据所在的路径 val path = s"$basePath/$tableName" // 插入数据 // insert(spark.createDataFrame(insertData.toBuffer.asJava, classOf[TemperatureBean]), tableName, "deviceId", "deviceType", "cdt", path) // 修改数据 // update(spark.createDataFrame(updateData.toBuffer.asJava, classOf[TemperatureBean]), tableName, "deviceId", "deviceType", "cdt", path) // 删除数据 // delete(spark.createDataFrame(deleteData.toBuffer.asJava, classOf[TemperatureBean]), tableName, "deviceId", "deviceType", "cdt", path) // 【查询方式1:默认为快照(基于行或列获取最新视图)查询 query(spark.read.format(SOURCE).load(s"$path/*/*").orderBy($"deviceId".asc)) // query(spark.read.format(SOURCE).options(buildQuery(QUERY_TYPE_SNAPSHOT_OPT_VAL)).load(s"$path/*/*").withColumn("queryType", lit("查询方式为:快照(默认)")).orderBy($"deviceId".asc)) // 【查询方式2:读时优化 query(spark.read.format(SOURCE).options(buildQuery(QUERY_TYPE_READ_OPTIMIZED_OPT_VAL)).load(s"$path/*/*").withColumn("queryType", lit("查询方式为:读时优化")).orderBy($"deviceId".asc)) // 【查询方式3:增量查询(不支持) spark.close() } /** * 新增数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def insert(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(使用MOR) TABLE_TYPE_OPT_KEY -> MOR_TABLE_TYPE_OPT_VAL, // 执行insert操作 OPERATION_OPT_KEY->INSERT_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的,必须是数值类型 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.BLOOM.name, // 执行insert操作的shuffle并行度 INSERT_PARALLELISM->"2" )) // 如果数据存在会覆盖 .mode(Overwrite) .save(path) } /** * 修改数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def update(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(使用MOR) TABLE_TYPE_OPT_KEY -> MOR_TABLE_TYPE_OPT_VAL, // 执行upsert操作 OPERATION_OPT_KEY->UPSERT_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.BLOOM.name, // 执行upsert操作的shuffle并行度 UPSERT_PARALLELISM-> "2" )) // 如果数据存在会覆盖 .mode(Append) .save(path) } /** * 删除数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def delete(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(使用MOR) TABLE_TYPE_OPT_KEY -> MOR_TABLE_TYPE_OPT_VAL, // 执行delete操作 OPERATION_OPT_KEY->DELETE_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.BLOOM.name, // 执行delete操作的shuffle并行度 DELETE_PARALLELISM->"2", // 删除策略有软删除(保留主键且其余字段为null)和硬删除(从数据集中彻底删除)两种,此处为硬删除 PAYLOAD_CLASS_OPT_KEY->classOf[EmptyHoodieRecordPayload].getName )) // 如果数据存在会覆盖 .mode(Append) .save(path) } /** * 查询类型 * <br>Hoodie具有3种查询模式:</br> * <br>1、默认是快照模式(Snapshot mode,根据行和列数据获取最新视图)</br> * <br>2、增量模式(incremental mode,查询从某个commit时间片之后的数据)</br> * <br>3、读时优化模式(Read Optimized mode,根据列数据获取最新视图)</br> * @param queryType * @param queryTime * @return */ def buildQuery(queryType: String, queryTime: Option[String]=Option.empty): Map[String, String] = { Map( queryType match { // 如果是读时优化模式(read_optimized,根据列数据获取最新视图) case QUERY_TYPE_READ_OPTIMIZED_OPT_VAL => QUERY_TYPE_OPT_KEY->QUERY_TYPE_READ_OPTIMIZED_OPT_VAL // 如果是增量模式(incremental mode,查询从某个时间片之后的新数据) case QUERY_TYPE_INCREMENTAL_OPT_VAL => QUERY_TYPE_OPT_KEY->QUERY_TYPE_INCREMENTAL_OPT_VAL // 默认使用快照模式查询(snapshot mode,根据行和列数据获取最新视图) case _ => QUERY_TYPE_OPT_KEY->QUERY_TYPE_SNAPSHOT_OPT_VAL }, if(queryTime.nonEmpty) BEGIN_INSTANTTIME_OPT_KEY->queryTime.get else BEGIN_INSTANTTIME_OPT_KEY->"0" ) } }
1.6.2 Hive操作
1.6.2.1 基于COW表的Hive使用
package com.mengyao.hudi import com.mengyao.Configured import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.common.model.EmptyHoodieRecordPayload import org.apache.hudi.config.HoodieIndexConfig._ import org.apache.hudi.config.HoodieWriteConfig._ import org.apache.hudi.hive.MultiPartKeysValueExtractor import org.apache.hudi.index.HoodieIndex import org.apache.spark.SparkConf import org.apache.spark.sql.SaveMode._ import org.apache.spark.sql.{DataFrame, SparkSession} import scala.collection.JavaConverters._ import scala.collection.mutable._ /** * Spark on Hudi(COW表) to Hive * @ClassName Demo3 * @Description * @Created by: MengYao * @Date: 2021-01-23 16:13:23 * @Version V1.0 */ class Demo3(db:String, table:String, partition:String, url:String, user:String="hive", password:String="hive") { private val hiveCfg = hiveConfig(db,table,partition, url, user, password) private val SOURCE = "hudi" /** * 新增数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def insert(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(默认COW) TABLE_TYPE_OPT_KEY -> COW_TABLE_TYPE_OPT_VAL, // 执行insert操作 OPERATION_OPT_KEY->INSERT_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的,必须是数值类型 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.GLOBAL_BLOOM.name, // 执行insert操作的shuffle并行度 INSERT_PARALLELISM->"2" ) ++= hiveCfg ) // 如果数据存在会覆盖 .mode(Overwrite) .save(path) } /** * 修改数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def update(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(默认COW) TABLE_TYPE_OPT_KEY -> COW_TABLE_TYPE_OPT_VAL, // 执行upsert操作 OPERATION_OPT_KEY->UPSERT_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.GLOBAL_BLOOM.name, // 执行upsert操作的shuffle并行度 UPSERT_PARALLELISM->"2" ) ++= hiveCfg ) // 如果数据存在会覆盖 .mode(Append) .save(path) } /** * 删除数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def delete(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(默认COW) TABLE_TYPE_OPT_KEY -> COW_TABLE_TYPE_OPT_VAL, // 执行delete操作 OPERATION_OPT_KEY->DELETE_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.BLOOM.name, // 执行delete操作的shuffle并行度 DELETE_PARALLELISM->"2", // 删除策略有软删除(保留主键且其余字段为null)和硬删除(从数据集中彻底删除)两种,此处为硬删除 PAYLOAD_CLASS_OPT_KEY->classOf[EmptyHoodieRecordPayload].getName ) ++= hiveCfg ) // 如果数据存在会覆盖 .mode(Append) .save(path) } private def hiveConfig(db:String, table:String, partition:String,url:String,user:String="hive", password:String="hive"): Map[String, String] = { scala.collection.mutable.Map( // 设置jdbc 连接同步 HIVE_URL_OPT_KEY -> url, // 设置访问Hive的用户名 HIVE_USER_OPT_KEY -> user, // 设置访问Hive的密码 HIVE_PASS_OPT_KEY -> password, // 设置Hive数据库名称 HIVE_DATABASE_OPT_KEY -> db, // 设置Hive表名称 HIVE_TABLE_OPT_KEY->table, // 设置要同步的分区列名 HIVE_PARTITION_FIELDS_OPT_KEY->partition, // 设置数据集注册并同步到hive HIVE_SYNC_ENABLED_OPT_KEY -> "true", // 设置当分区变更时,当前数据的分区目录是否变更 BLOOM_INDEX_UPDATE_PARTITION_PATH -> "true", // HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY -> classOf[MultiPartKeysValueExtractor].getName ) } } object Demo3 { private val APP_NAME = classOf[Demo3].getClass.getSimpleName val insertData = Array[TemperatureBean]( new TemperatureBean("4301",1,28.6,"2019-12-07 12:35:33"), new TemperatureBean("4312",0,31.4,"2019-12-07 12:25:03"), new TemperatureBean("4302",1,30.1,"2019-12-07 12:32:17"), new TemperatureBean("4305",3,31.5,"2019-12-07 12:33:11"), new TemperatureBean("4310",2,29.9,"2019-12-07 12:34:42") ) val updateData = Array[TemperatureBean]( new TemperatureBean("4310",2,30.4,"2019-12-07 12:35:42")// 设备ID为4310的传感器发生修改,温度值由29.9->30.4,时间由12:34:42->12:35:42 ) val deleteData = Array[TemperatureBean]( new TemperatureBean("4310",2,30.4,"2019-12-07 12:35:42")// 设备ID为4310的传感器要被删除,必须与最新的数据保持一致(如果字段值不同时无法删除) ) def main(args: Array[String]): Unit = { // 类似Hive中的DB(basePath的schema决定了最终要操作的文件系统,如果是file:则为LocalFS,如果是hdfs:则为HDFS) val basePath = "hdfs://node01:9820/apps/demo/hudi/hudi-hive-cow/" // Hive中的Table val tableName = "tbl_hudi_temperature_cow" // 数据所在的路径 val path = s"$basePath/$tableName" // 创建SparkConf val conf = new SparkConf() .set("spark.app.name", APP_NAME) .setAll(Configured.sparkConf().asScala) // 创建SparkSession val spark = SparkSession.builder() .config(conf) .getOrCreate() // 关闭日志 spark.sparkContext.setLogLevel("DEBUG") // 导入隐式转换 import spark.implicits._ // 创建Demo3实例 val demo = new Demo3("test_db", tableName,"deviceType","jdbc:hive2://node01:10000","root","123456") // 插入数据 // demo.insert(spark.createDataFrame(insertData.toBuffer.asJava, classOf[TemperatureBean]),tableName, "deviceId", "deviceType", "cdt", path) // 修改数据 // demo.update(spark.createDataFrame(updateData.toBuffer.asJava, classOf[TemperatureBean]),tableName, "deviceId", "deviceType", "cdt", path) // 删除数据 // demo.delete(spark.createDataFrame(deleteData.toBuffer.asJava, classOf[TemperatureBean]),tableName, "deviceId", "deviceType", "cdt", path) spark.stop() } }
首先,在Demo3类的main方法中,仅将demo.insert的代码取消注释,确保demo.update和demo.delete的代码是被注释掉的。然后打包并上传到服务器。
然后,在服务器中执行如下脚本:
spark-submit --verbose --class com.mengyao.hudi.Demo3 --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --executor-cores 1 --queue default demo.jar
在yarn中,看到作业执行成功时:

再去查看hive中test_db库下是否多了一张叫做tbl_hudi_temperature_cow的表
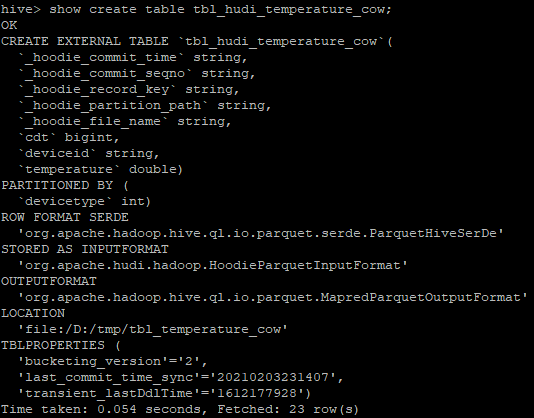
查看详细的建表信息

首先,在Demo3类的main方法中,仅将demo.update的代码取消注释,确保demo.insert和demo.delete的代码是被注释掉的。然后打包并上传到服务器。
然后,在服务器中执行如下脚本:
spark-submit --verbose --class com.mengyao.hudi.Demo3 --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --executor-cores 1 --queue default demo.jar
在yarn中,看到作业执行成功时

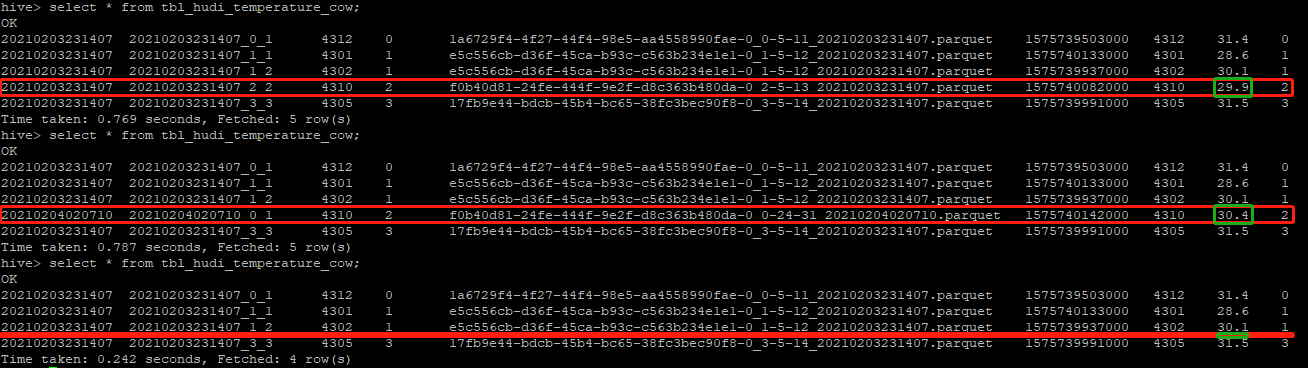
再去Hive中查询数据(发现deviceid为4310的数据的温度变成了30.4度)

为了看出更新的效果,本次修改与上次插入的数据对比图如下:

c) 测试删除数据
首先,在Demo3类的main方法中,仅将demo.delete的代码取消注释,确保demo.insert和demo.update的代码是被注释掉的。然后打包并上传到服务器。
然后,在服务器中执行如下脚本:
spark-submit --verbose --class com.mengyao.hudi.Demo3 --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --executor-cores 1 --queue default demo.jar
在yarn中,看到作业执行成功时

再去Hive中查询数据(查看deviceid为4310的数据是否已经被成功删除)

为了看出更新的效果,本次删除与上次修改以及上上次插入的数据对比图如下:
1.6.2.2 基于MOR表的Hive使用
package com.mengyao.hudi import com.mengyao.Configured import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.common.model.EmptyHoodieRecordPayload import org.apache.hudi.config.HoodieIndexConfig._ import org.apache.hudi.config.HoodieWriteConfig._ import org.apache.hudi.hive.MultiPartKeysValueExtractor import org.apache.hudi.index.HoodieIndex import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, SparkSession} import org.apache.spark.sql.SaveMode._ import scala.collection.JavaConverters._ import scala.collection.mutable._ /** * Spark on Hudi(MOR表) to Hive * @ClassName Demo4 * @Description * @Created by: MengYao * @Date: 2021-01-23 16:13:23 * @Version V1.0 */ class Demo4(db:String, table:String, partition:String, url:String, user:String="hive", password:String="hive") { private val hiveCfg = hiveConfig(db,table,partition, url, user, password) private val SOURCE = "hudi" /** * 新增数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def insert(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(默认COW) TABLE_TYPE_OPT_KEY -> MOR_TABLE_TYPE_OPT_VAL, // 执行insert操作 OPERATION_OPT_KEY->INSERT_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的,必须是数值类型 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.GLOBAL_BLOOM.name, // 执行insert操作的shuffle并行度 INSERT_PARALLELISM->"2" ) ++= hiveCfg ) // 如果数据存在会覆盖 .mode(Overwrite) .save(path) } /** * 修改数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def update(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(默认COW) TABLE_TYPE_OPT_KEY -> MOR_TABLE_TYPE_OPT_VAL, // 执行upsert操作 OPERATION_OPT_KEY->UPSERT_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.GLOBAL_BLOOM.name, // 执行upsert操作的shuffle并行度 UPSERT_PARALLELISM->"2" ) ++= hiveCfg ) // 如果数据存在会覆盖 .mode(Append) .save(path) } /** * 删除数据 * @param df 数据集 * @param tableName Hudi表 * @param primaryKey 主键列名 * @param partitionField 分区列名 * @param changeDateField 变更时间列名 * @param path 数据的存储路径 */ def delete(df: DataFrame, tableName: String, primaryKey: String, partitionField: String, changeDateField: String, path: String): Unit = { df.write.format(SOURCE) .options(Map( // 要操作的表 TABLE_NAME->tableName, // 操作的表类型(默认COW) TABLE_TYPE_OPT_KEY->MOR_TABLE_TYPE_OPT_VAL, // 执行delete操作 OPERATION_OPT_KEY->DELETE_OPERATION_OPT_VAL, // 设置主键列 RECORDKEY_FIELD_OPT_KEY->primaryKey, // 设置分区列,类似Hive的表分区概念 PARTITIONPATH_FIELD_OPT_KEY->partitionField, // 设置数据更新时间列,该字段数值大的数据会覆盖小的 PRECOMBINE_FIELD_OPT_KEY->changeDateField, // 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器 INDEX_TYPE_PROP-> HoodieIndex.IndexType.BLOOM.name, // 执行delete操作的shuffle并行度 DELETE_PARALLELISM->"2", // 删除策略有软删除(保留主键且其余字段为null)和硬删除(从数据集中彻底删除)两种,此处为硬删除 PAYLOAD_CLASS_OPT_KEY->classOf[EmptyHoodieRecordPayload].getName ) ++= hiveCfg ) // 如果数据存在会覆盖 .mode(Append) .save(path) } private def hiveConfig(db:String, table:String, partition:String,url:String,user:String="hive", password:String="hive"): Map[String, String] = { scala.collection.mutable.Map( // 设置jdbc 连接同步 HIVE_URL_OPT_KEY -> url, // 设置访问Hive的用户名 HIVE_USER_OPT_KEY -> user, // 设置访问Hive的密码 HIVE_PASS_OPT_KEY -> password, // 设置Hive数据库名称 HIVE_DATABASE_OPT_KEY -> db, // 设置Hive表名称 HIVE_TABLE_OPT_KEY->table, // 设置要同步的分区列名 HIVE_PARTITION_FIELDS_OPT_KEY->partition, // 设置数据集注册并同步到hive HIVE_SYNC_ENABLED_OPT_KEY -> "true", // 设置当分区变更时,当前数据的分区目录是否变更 BLOOM_INDEX_UPDATE_PARTITION_PATH -> "true", // HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY -> classOf[MultiPartKeysValueExtractor].getName ) } } object Demo4 { private val APP_NAME = classOf[Demo3].getClass.getSimpleName val insertData = Array[TemperatureBean]( new TemperatureBean("4301",1,28.6,"2019-12-07 12:35:33"), new TemperatureBean("4312",0,31.4,"2019-12-07 12:25:03"), new TemperatureBean("4302",1,30.1,"2019-12-07 12:32:17"), new TemperatureBean("4305",3,31.5,"2019-12-07 12:33:11"), new TemperatureBean("4310",2,29.9,"2019-12-07 12:34:42") ) val updateData = Array[TemperatureBean]( new TemperatureBean("4310",2,30.4,"2019-12-07 12:35:42")// 设备ID为4310的传感器发生修改,温度值由29.9->30.4,时间由12:34:42->12:35:42 ) val deleteData = Array[TemperatureBean]( new TemperatureBean("4310",2,30.4,"2019-12-07 12:35:42")// 设备ID为4310的传感器要被删除,必须与最新的数据保持一致(如果字段值不同时无法删除) ) def main(args: Array[String]): Unit = { // 类似Hive中的DB(basePath的schema决定了最终要操作的文件系统,如果是file:则为LocalFS,如果是hdfs:则为HDFS) val basePath = "hdfs://node01:9820/apps/demo/hudi/hudi-hive-mor/" // Hive中的Table val tableName = "tbl_hudi_temperature_mor1" // 数据所在的路径 val path = s"$basePath/$tableName" // 创建SparkConf val conf = new SparkConf() .set("spark.app.name", APP_NAME) .setAll(Configured.sparkConf().asScala) // 创建SparkSession val spark = SparkSession.builder() .config(conf) .getOrCreate() // 关闭日志 spark.sparkContext.setLogLevel("DEBUG") // 导入隐式转换 import spark.implicits._ // 创建Demo4实例 val demo = new Demo4("test_db", tableName,"deviceType","jdbc:hive2://node01:10000","root","123456") // 插入数据 // demo.insert(spark.createDataFrame(insertData.toBuffer.asJava, classOf[TemperatureBean]),tableName, "deviceId", "deviceType", "cdt", path) // 修改数据 // demo.update(spark.createDataFrame(updateData.toBuffer.asJava, classOf[TemperatureBean]),tableName, "deviceId", "deviceType", "cdt", path) // 删除数据 demo.delete(spark.createDataFrame(deleteData.toBuffer.asJava, classOf[TemperatureBean]),tableName, "deviceId", "deviceType", "cdt", path) spark.stop() } }
首先,在Demo4类的main方法中,仅将demo.insert的代码取消注释,确保demo.update和demo.delete的代码是被注释掉的。然后打包并上传到服务器。
然后,在服务器中执行如下脚本:
spark-submit --verbose --class com.mengyao.hudi.Demo4 --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --executor-cores 1 --queue default demo.jar
在yarn中,看到作业执行成功时

再去查看hive中test_db库下是否多了2张表,分别是:
| 核心实现类 | 说明 | |
|---|---|---|
| tbl_hudi_temperature_mor1_ro表 | org.apache.hudi.hadoop.HoodieParquetInputFormat | _ro表的意思是Read Optimized,此表的查询性能最好。 |
| tbl_hudi_temperature_mor1_rt表 | org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat |

查看tbl_hudi_temperature_mor1_ro表的详细建表信息
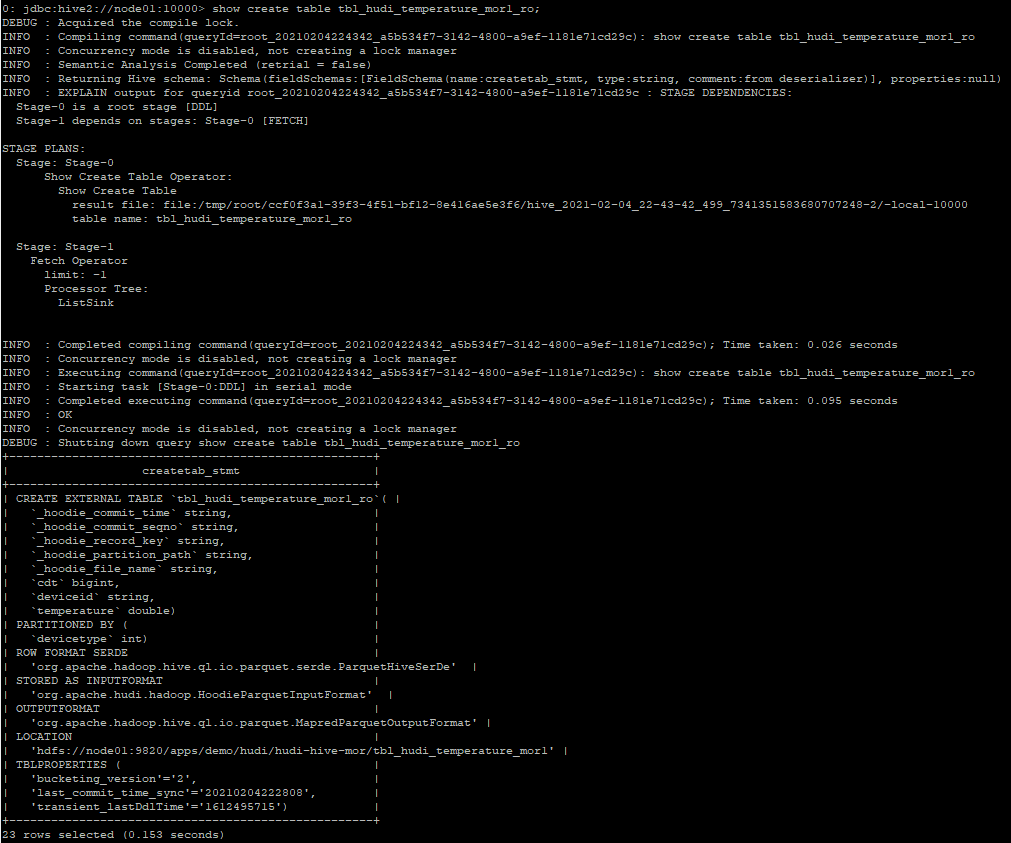
查看tbl_hudi_temperature_mor1_rt表的详细建表信息
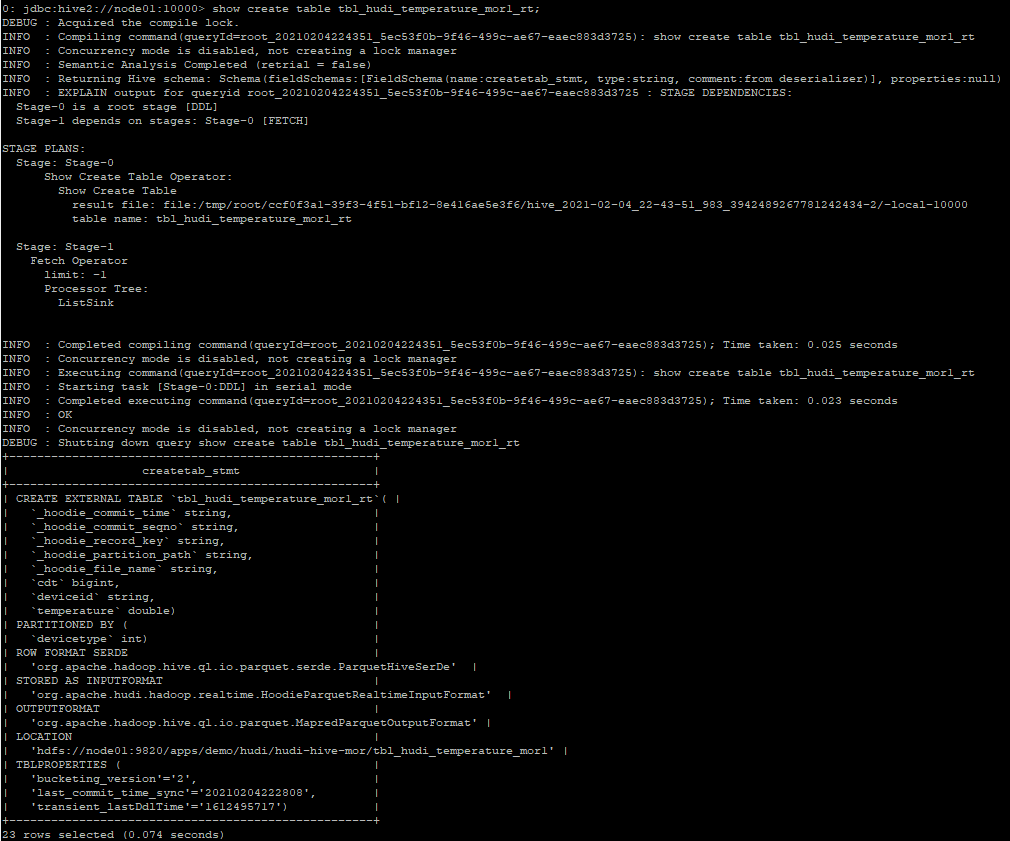


b) 测试修改数据
首先,在Demo4类的main方法中,仅将demo.update的代码取消注释,确保demo.insert和demo.delete的代码是被注释掉的。然后打包并上传到服务器。
然后,在服务器中执行如下脚本:
spark-submit --verbose --class com.mengyao.hudi.Demo4 --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --executor-cores 1 --queue default demo.jar
在yarn中,看到作业执行成功时




c) 测试删除数据
首先,在Demo4类的main方法中,仅将demo.delete的代码取消注释,确保demo.insert和demo.update的代码是被注释掉的。然后打包并上传到服务器。
然后,在服务器中执行如下脚本:
spark-submit --verbose --class com.mengyao.hudi.Demo4 --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --executor-cores 1 --queue default demo.jar
在yarn中,看到作业执行成功时




1.7 Hudi的WriteClient使用
package com.mengyao.hudi; import com.mengyao.Configured; import org.apache.hudi.client.HoodieWriteClient; import org.apache.hudi.client.WriteStatus; import org.apache.hudi.common.model.HoodieRecord; import org.apache.hudi.common.model.OverwriteWithLatestAvroPayload; import org.apache.hudi.config.HoodieIndexConfig; import org.apache.hudi.config.HoodieWriteConfig; import org.apache.hudi.index.HoodieIndex; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import scala.collection.JavaConverters; import java.text.SimpleDateFormat; import java.util.Arrays; import java.util.Date; import java.util.HashMap; /** * WriteClient模式是直接使用RDD级别api进行Hudi编程 * Application需要使用HoodieWriteConfig对象,并将其传递给HoodieWriteClient构造函数。 HoodieWriteConfig可以使用以下构建器模式构建。 * @ClassName WriteClientMain * @Description * @Created by: MengYao * @Date: 2021-01-26 10:40:29 * @Version V1.0 */ public class WriteClientMain { private static final String APP_NAME = WriteClientMain.class.getSimpleName(); private static final String MASTER = "local[2]"; private static final String SOURCE = "hudi"; public static void main(String[] args) { // 创建SparkConf SparkConf conf = new SparkConf() .setAll(JavaConverters.mapAsScalaMapConverter(Configured.sparkConf()).asScala()); // 创建SparkContext JavaSparkContext jsc = new JavaSparkContext(MASTER, APP_NAME, conf); // 创建Hudi的WriteConfig HoodieWriteConfig hudiCfg = HoodieWriteConfig.newBuilder() .forTable("tableName") .withSchema("avroSchema") .withPath("basePath") .withProps(new HashMap()) .withIndexConfig(HoodieIndexConfig.newBuilder().withIndexType(HoodieIndex.IndexType.BLOOM).build()) .build(); // 创建Hudi的WriteClient HoodieWriteClient hudiWriteCli = new HoodieWriteClient<OverwriteWithLatestAvroPayload>(jsc, hudiCfg); // 1、执行新增操作 JavaRDD<HoodieRecord> insertData = jsc.parallelize(Arrays.asList()); String insertInstantTime = new SimpleDateFormat("yyyyMMddHHmmss").format(new Date()); JavaRDD<WriteStatus> insertStatus = hudiWriteCli.insert(insertData, insertInstantTime); // 【注意:为了便于理解,以下所有判断Hudi操作数据的状态不进行额外的方法封装】 if (insertStatus.filter(ws->ws.hasErrors()).count()>0) {// 当提交后返回的状态中包含error时 hudiWriteCli.rollback(insertInstantTime);// 从时间线(insertInstantTime)中回滚,插入失败 } else { hudiWriteCli.commit(insertInstantTime, insertStatus);// 否则提交时间线(insertInstantTime)中的数据,到此,插入完成 } // 2、也可以使用批量加载的方式新增数据 String builkInsertInstantTime = new SimpleDateFormat("yyyyMMddHHmmss").format(new Date()); JavaRDD<WriteStatus> bulkInsertStatus = hudiWriteCli.bulkInsert(insertData, builkInsertInstantTime); if (bulkInsertStatus.filter(ws->ws.hasErrors()).count()>0) {// 当提交后返回的状态中包含error时 hudiWriteCli.rollback(builkInsertInstantTime);// 从时间线(builkInsertInstantTime)中回滚,批量插入失败 } else { hudiWriteCli.commit(builkInsertInstantTime, bulkInsertStatus);// 否则提交时间线(builkInsertInstantTime)中的数据,到此,批量插入完成 } // 3、执行修改or新增操作 JavaRDD<HoodieRecord> updateData = jsc.parallelize(Arrays.asList()); String updateInstantTime = new SimpleDateFormat("yyyyMMddHHmmss").format(new Date()); JavaRDD<WriteStatus> updateStatus = hudiWriteCli.upsert(updateData, updateInstantTime); if (updateStatus.filter(ws->ws.hasErrors()).count()>0) {// 当提交后返回的状态中包含error时 hudiWriteCli.rollback(updateInstantTime);// 从时间线(updateInstantTime)中回滚,修改失败 } else { hudiWriteCli.commit(updateInstantTime, updateStatus);// 否则提交时间线(updateInstantTime)中的数据,到此,修改完成 } // 4、执行删除操作 JavaRDD<HoodieRecord> deleteData = jsc.parallelize(Arrays.asList()); String deleteInstantTime = new SimpleDateFormat("yyyyMMddHHmmss").format(new Date()); JavaRDD<WriteStatus> deleteStatus = hudiWriteCli.delete(deleteData, deleteInstantTime); if (deleteStatus.filter(ws->ws.hasErrors()).count()>0) {// 当提交后返回的状态中包含error时 hudiWriteCli.rollback(deleteInstantTime);// 从时间线(deleteInstantTime)中回滚,删除失败 } else { hudiWriteCli.commit(deleteInstantTime, deleteStatus);// 否则提交时间线(deleteInstantTime)中的数据,到此,删除完成 } // 退出WriteClient hudiWriteCli.close(); // 退出SparkContext jsc.stop(); } }
1.8 如何使用索引
1.8.1 使用SparkSQL的数据源配置
在SparkSQL的数据源配置中,面向读写的通用配置参数均通过options或option来指定,可用的功能包括: 定义键和分区、选择写操作、指定如何合并记录或选择要读取的视图类型。
df.write.format("hudi")
.options(Map(
// 要操作的表
TABLE_NAME->tableName,
// 操作的表类型(默认COW)
TABLE_TYPE_OPT_KEY -> COW_TABLE_TYPE_OPT_VAL,
/**
* 执行insert/upsert/delete操作,默认是upsert
* OPERATION_OPT_KEY->INSERT_OPERATION_OPT_VAL,
* BULK_INSERT_OPERATION_OPT_VAL,
* UPSERT_OPERATION_OPT_VAL,
* DELETE_OPERATION_OPT_VAL,
*/
OPERATION_OPT_KEY->INSERT_OPERATION_OPT_VAL,
// 设置主键列
RECORDKEY_FIELD_OPT_KEY->primaryKey,
// 设置分区列,类似Hive的表分区概念
PARTITIONPATH_FIELD_OPT_KEY->partitionField,
// 设置数据更新时间列,该字段数值大的数据会覆盖小的,必须是数值类型
PRECOMBINE_FIELD_OPT_KEY->changeDateField,
/**
* 要使用的索引类型,可用的选项是[SIMPLE|BLOOM|HBASE|INMEMORY],默认为布隆过滤器
* INDEX_TYPE_PROP -> HoodieIndex.IndexType.SIMPLE.name,
* HoodieIndex.IndexType.GLOBAL_SIMPLE.name,
* HoodieIndex.IndexType.INMEMORY.name,
* HoodieIndex.IndexType.HBASE.name,
* HoodieIndex.IndexType.BLOOM.name,
* HoodieIndex.IndexType.GLOBAL_SIMPLE.name,
*/
INDEX_TYPE_PROP -> HoodieIndex.IndexType.BLOOM.name,
// 执行insert操作的shuffle并行度
INSERT_PARALLELISM->"2"
))
// 如果数据存在会覆盖
.mode(Overwrite)
.save(path)
1.8.2 使用WriteClient方式配置
WriteClient是使用基于Java的RDD级别API进行编程的的一种方式,需要先构建HoodieWriteConfig对象,然后再作为参数传递给HoodieWriteClient构造函数。
// 创建Hudi的WriteConfig HoodieWriteConfig hudiCfg = HoodieWriteConfig.newBuilder() .forTable("tableName") .withSchema("avroSchema") .withPath("basePath") .withProps(new HashMap()) .withIndexConfig(HoodieIndexConfig.newBuilder().withIndexType( HoodieIndex.IndexType.BLOOM // HoodieIndex.IndexType.GLOBAL_BLOOM // HoodieIndex.IndexType.INMEMORY // HoodieIndex.IndexType.HBASE // HoodieIndex.IndexType.SIMPLE // HoodieIndex.IndexType.GLOBAL_SIMPLE ).build()) .build();
1.8.3 声明索引的关键参数
在Hudi中,使用索引的关键参数主要有2个,即hoodie.index.type和hoodie.index.class两个。这两个参数只需要配置其中一个即可,原因如下:
| 索引的配置参数 | 对应代码中的KEY | 解释 |
|---|---|---|
| hoodie.index.type | HoodieIndexConfig.INDEX_TYPE_PROP | 当配置此参数时,会从HBASE、INMEMORY、BLOOM、GLOBAL_BLOOM、SIMPLE、GLOBAL_SIMPLE这几个index中选择对应的Index实现类。 |
| hoodie.index.class | HoodieIndexConfig.INDEX_CLASS_PROP | 当配置此参数时,如果是HBASE、INMEMORY、BLOOM、GLOBAL_BLOOM、SIMPLE、GLOBAL_SIMPLE这几个index实现类的类全名就会直接通过反射实例化,否则会按照自定义Index类(必须是继承自HoodieIndex)进行加载。 |
1.8.4 索引参数在源码中的实现
可以在Hudi索引超类HoodieIndex的源码中看到createIndex方法的定义和实现:
public abstract class HoodieIndex<T extends HoodieRecordPayload> implements Serializable { protected final HoodieWriteConfig config; protected HoodieIndex(HoodieWriteConfig config) { this.config = config; } public static <T extends HoodieRecordPayload> HoodieIndex<T> createIndex(HoodieWriteConfig config) throws HoodieIndexException { if (!StringUtils.isNullOrEmpty(config.getIndexClass())) { Object instance = ReflectionUtils.loadClass(config.getIndexClass(), new Object[]{config}); if (!(instance instanceof HoodieIndex)) { throw new HoodieIndexException(config.getIndexClass() + " is not a subclass of HoodieIndex"); } else { return (HoodieIndex)instance; } } else { switch(config.getIndexType()) { case HBASE: return new HBaseIndex(config); case INMEMORY: return new InMemoryHashIndex(config); case BLOOM: return new HoodieBloomIndex(config); case GLOBAL_BLOOM: return new HoodieGlobalBloomIndex(config); case SIMPLE: return new HoodieSimpleIndex(config); case GLOBAL_SIMPLE: return new HoodieGlobalSimpleIndex(config); default: throw new HoodieIndexException("Index type unspecified, set " + config.getIndexType()); } } } @PublicAPIMethod( maturity = ApiMaturityLevel.STABLE ) public abstract JavaPairRDD<HoodieKey, Option<Pair<String, String>>> fetchRecordLocation(JavaRDD<HoodieKey> var1, JavaSparkContext var2, HoodieTable<T> var3); @PublicAPIMethod( maturity = ApiMaturityLevel.STABLE ) public abstract JavaRDD<HoodieRecord<T>> tagLocation(JavaRDD<HoodieRecord<T>> var1, JavaSparkContext var2, HoodieTable<T> var3) throws HoodieIndexException; @PublicAPIMethod( maturity = ApiMaturityLevel.STABLE ) public abstract JavaRDD<WriteStatus> updateLocation(JavaRDD<WriteStatus> var1, JavaSparkContext var2, HoodieTable<T> var3) throws HoodieIndexException; @PublicAPIMethod( maturity = ApiMaturityLevel.STABLE ) public abstract boolean rollbackCommit(String var1); @PublicAPIMethod( maturity = ApiMaturityLevel.STABLE ) public abstract boolean isGlobal(); @PublicAPIMethod( maturity = ApiMaturityLevel.EVOLVING ) public abstract boolean canIndexLogFiles(); @PublicAPIMethod( maturity = ApiMaturityLevel.STABLE ) public abstract boolean isImplicitWithStorage(); public void close() { } public static enum IndexType { HBASE, INMEMORY, BLOOM, GLOBAL_BLOOM, SIMPLE, GLOBAL_SIMPLE; private IndexType() { } } }
1.9 生产环境下的推荐配置
spark.driver.extraClassPath=/etc/hive/conf
spark.driver.extraJavaOptions=-XX:+PrintTenuringDistribution -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof
spark.driver.maxResultSize=2g
spark.driver.memory=4g
spark.executor.cores=1
spark.executor.extraJavaOptions=-XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof
spark.executor.id=driver
spark.executor.instances=300
spark.executor.memory=6g
spark.rdd.compress=true
spark.kryoserializer.buffer.max=512m
spark.serializer=org.apache.spark.serializer.KryoSerializer
spark.shuffle.service.enabled=true
spark.sql.hive.convertMetastoreParquet=false
spark.submit.deployMode=cluster
spark.task.cpus=1
spark.task.maxFailures=4
spark.yarn.driver.memoryOverhead=1024
spark.yarn.executor.memoryOverhead=3072
spark.yarn.max.executor.failures=100
1.10 上面代码依赖的其他类


package com.mengyao.hudi import org.apache.spark.sql.{DataFrame, SparkSession} import org.apache.spark.sql.types.{DataTypes, StructField, StructType} import java.sql.Date import java.sql.Timestamp object DemoUtils { def schemaExtractor(caz: Class[_]): StructType = { val fields = caz.getDeclaredFields.map(field => { StructField(field.getName, field.getType.getSimpleName.toLowerCase match { case "byte" => DataTypes.ByteType case "short" => DataTypes.ShortType case "int" => DataTypes.IntegerType case "double" => DataTypes.DoubleType case "float" => DataTypes.FloatType case "long" => DataTypes.LongType case "boolean" => DataTypes.BooleanType // java.sql.Date case "date" => DataTypes.DateType // java.sql.Timestamp case "timestamp" => DataTypes.TimestampType case _ => DataTypes.StringType }, true) }) StructType(fields) } /** * 测试输出 * */ def query(df: DataFrame, numRows: Int = Int.MaxValue): Unit = { df.show(numRows, false) } case class A(a:Byte,b:Short,c:Int,d:Double,e:Float,f:Long,g:Boolean,h:Date,i:Timestamp,j:String) { def getA = a def getB = b def getC = c def getD = d def getE = e def getF = f def getG = g def getH = h def getI = i def getJ = j } def main(args: Array[String]): Unit = { val data = A(1.byteValue, 2.shortValue, 3.intValue, 4.doubleValue, 5.floatValue, 6.longValue, true, new Date(System.currentTimeMillis), new Timestamp(System.currentTimeMillis), "hello") println(schemaExtractor(classOf[A]).mkString("\n")) val spark = SparkSession.builder().appName("A").master("local[*]").getOrCreate() import scala.collection.JavaConverters._ spark.createDataFrame(Array[A](data).toBuffer.asJava, classOf[A]).show(false) spark.close } }
package com.mengyao; import java.util.*; import java.util.stream.Collectors; /** * * @ClassName Configured * @Description * @Created by: MengYao * @Date: 2021-01-11 10:10:53 * @Version V1.0 */ public class Configured { private static final ResourceBundle bundle = ResourceBundle.getBundle("config", Locale.CHINESE); private static Map<String, String> config = new HashMap<>(); public static final String USER_NAME = "user.name"; public static final String JAVA_HOME = "JAVA_HOME"; public static final String HADOOP_HOME = "HADOOP_HOME"; public static final String HADOOP_CONF_DIR = "HADOOP_CONF_DIR"; public static final String HADOOP_HOME_DIR = "hadoop.home.dir"; public static final String SPARK_HOME = "SPARK_HOME"; public static final String DEFAULT_CHARSET = "default.charset"; public static Map<String, String> get() { return bundle.keySet().stream() .collect(Collectors.toMap(key->key, key->bundle.getString(key), (e1,e2)->e2, HashMap::new)); } public static Map<String, String> env() { return bundle.keySet().stream() .filter(k -> k.matches("(JAVA_HOME|HADOOP_CONF_DIR|SPARK_HOME|SPARK_PRINT_LAUNCH_COMMAND)")) .collect(Collectors.toMap(key->key, key->bundle.getString(key), (e1,e2)->e2, HashMap::new)); } public static Map<String, String> sparkConf() { return bundle.keySet().stream() .filter(key->Objects.nonNull(key)&&key.startsWith("spark")) .collect(Collectors.toMap(key->key, key->bundle.getString(key), (e1,e2)->e2, HashMap::new)); } public static Map<String, String> appConf() { return bundle.keySet().stream() .filter(key->Objects.nonNull(key)&&key.startsWith("app")) .collect(Collectors.toMap(key->key, key->bundle.getString(key), (e1,e2)->e2, HashMap::new)); } public static String getDefaultCharset() { return bundle.getString(DEFAULT_CHARSET); } public static String getUserName() { return bundle.getString(USER_NAME); } public static String getJavaHome() { return bundle.getString(JAVA_HOME); } public static String getHadoopHome() { return bundle.getString(HADOOP_HOME); } public static String getHadoopConfDir() { return bundle.getString(HADOOP_CONF_DIR); } public static String getSparkHome() { return bundle.getString(SPARK_HOME); } }

