Flink-DataStream流处理应用(Local模式下)运行流程-源码分析
Flink的部署模式,有Local、Cluster和Cloud模式,本案例,在Local模式下分析,Flink的DataStream流处理应用程序的运行流程
MiniCluster -> start
JobManager(主节点服务,实现类是JobManagerRunnerImpl类)
JobMaster()
ResourceManager()
TaskManager(从节点服务,实现类是TaskManagerRunner类)
1、自定义DataStream的应用程序,执行execute方法
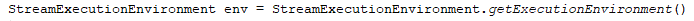

1.1、初始化StreamExecutionEnvironment,在local模式下,调用的是1939行,即无参数的createLocalEnvironment()

1.2、查看createLocalEnvironment方法的定义,内部调用的是createLocalEnvironment(defaultLocalParallelism),传入了一个int类型的默认并行度参数

注意默认并行度参数的值是这么生成的:

1.3、查看createLocalEnvironment(defaultLocalParallelism)方法的定义,内部调用的是createLocalEnvironment(defaultLocalParallelism,configuration),传入了两个参数,分别是并行度参数和配置对象
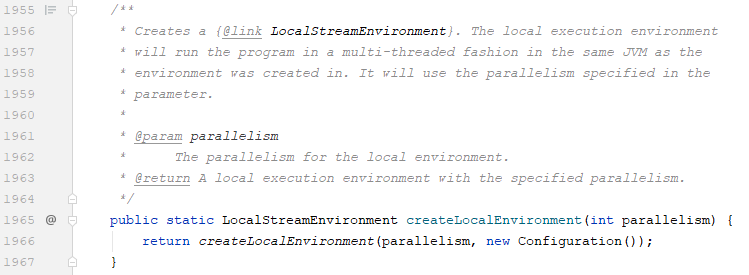
1.4、我们看到了,原来在IDE中,用的是LocalStreamEnvironment对象

1.5、在new LocalStreamEnvironment构造方法中,通过vlidateAndGetConfiguration方法设置了2个配置:execution.target=local 和 execution.attached=true;然后设置并行度为1
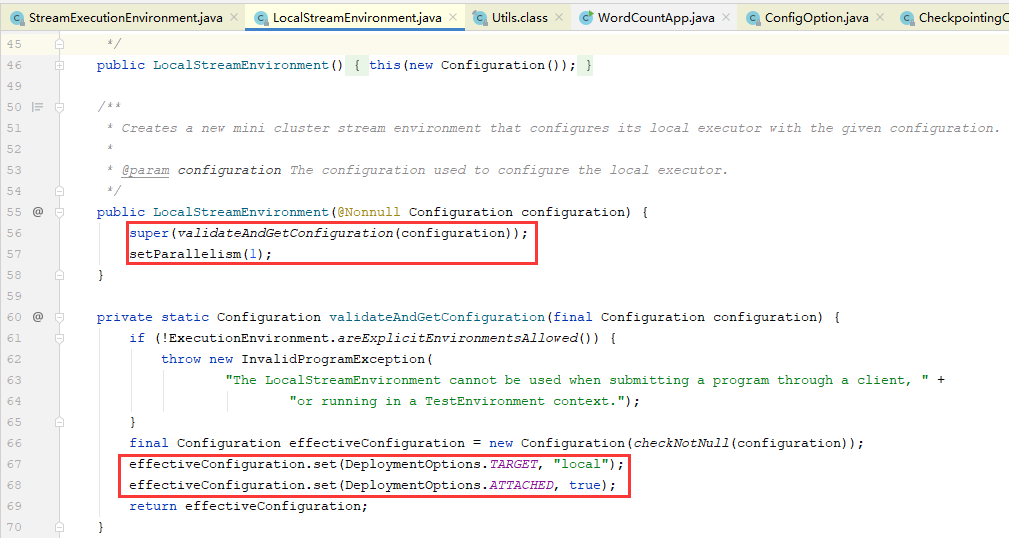
1.6、在new LocalStreamEnvironment的时候,也调用了父类StreamExecutionEnvironment(configuration,userClassLoader)的构造方法,并传入了2个关键参数

1.7、在父类StreamExecutionEnvironment(configuration,userClassLoader)的构造方法,又调用了StreamExecutionEnvironment(executorServiceLoader,configuration,userClassloader),由2个关键参数变成了3个关键参数,即executorServiceLoader=new DefaultExecutorServiceLoader
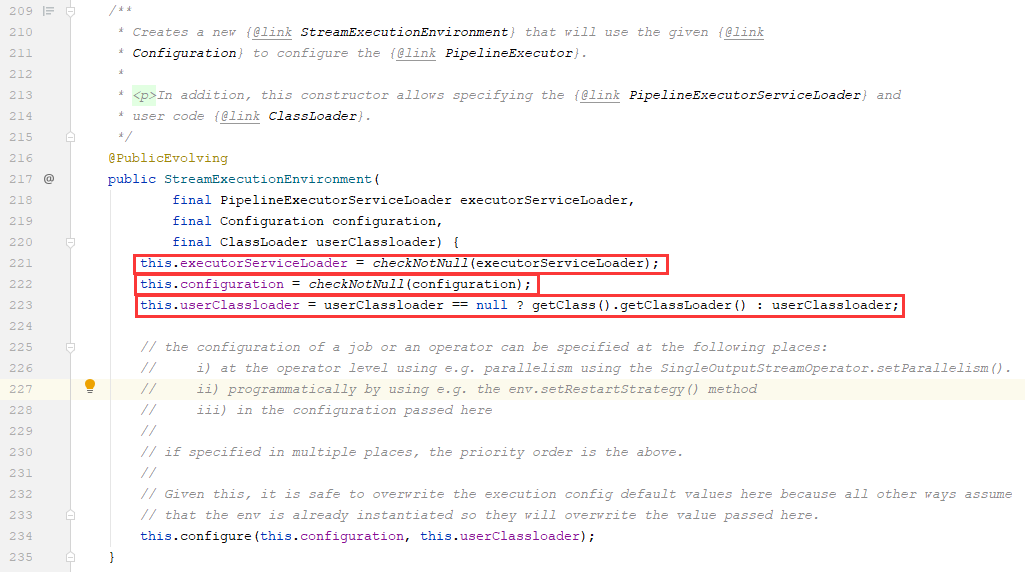
2、调用的是StreamExecutionEnvironment中第1696行的execute(String jobName)方法(注意返回值是JobExecutionResult类型),其内部调用的是:execute(getStreamGraph(jobName));
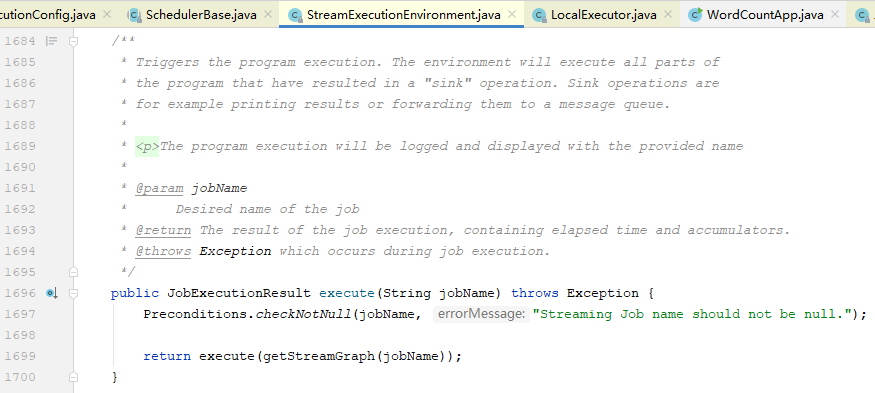
2.1、看一下,getStreamGraph(String jobName)方法的定义,其内部调用的是:getStreamGraph(jobName, true);

2.2、查看getStreamGraph(jobName, clearTransformations)方法的定义,我们发现是通过getStreamGraphGenerator创建的StreamGraph
2.3、查看getStreamGraphGenerator的定义:原来是new StreamGraphGenerator对象

3、在StreamExecutionEnvironment中,1696行的execute(String jobName)方法内部调用了位于1712行的execute(streamGraph)

3.1、在StreamExecutionEnvironment中,1712行的execute(streamGraph)方法内部调用了executeAsync(streamGraph)方法,返回的是JobClient对象

【 注意关键代码】
3.1.1、在1802~1803行:
final PipelineExecutorFactory executorFactory =
executorServiceLoader.getExecutorFactory(configuration); // executorServiceLoader对象是DefaultExecutorServiceLoader类型,调用了getExecutorFactory(configuration)方法,
3.1.2、在1810~1812行:
CompletableFuture<JobClient> jobClientFuture = executorFactory
.getExecutor(configuration) // LocalExecutorFactory.getExecutor(config)的返回值是LocalExecutor对象
.execute(streamGraph, configuration);// 调用LocalExecutor.execute(streamGraph,configuration)
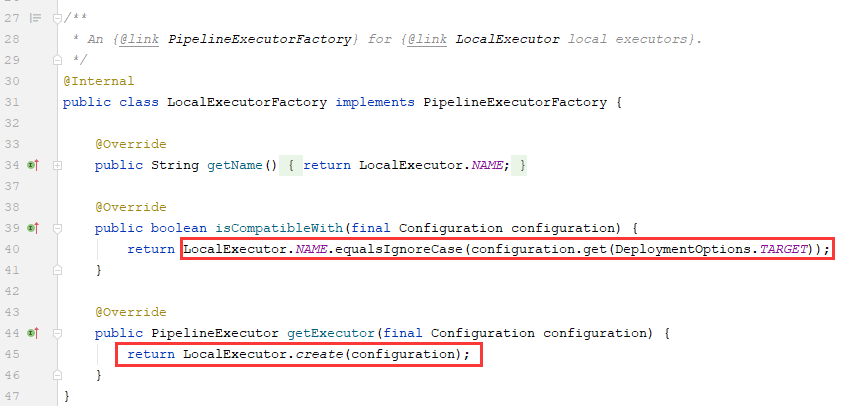
3.1.3、在LocalExecutor类的静态create方法中,传入了configuration和new MiniCluster两个参数。
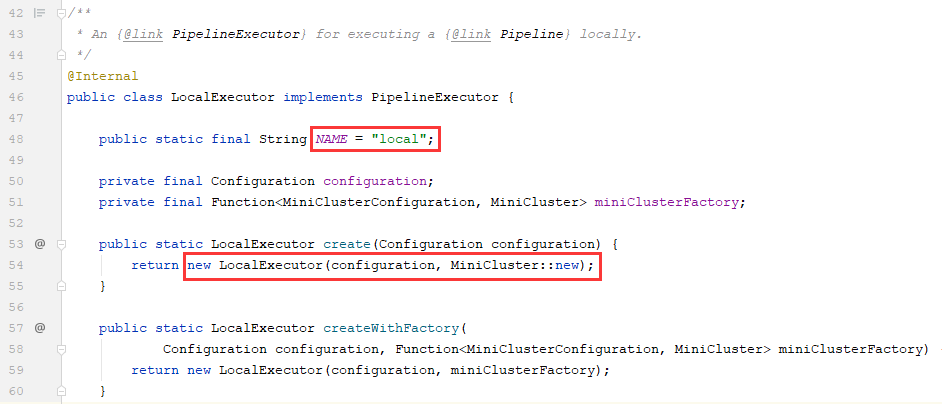
3.1.4、在LocalExecutor类的execute方法中,我们看到,使用PreJobMiniClusterFactory.createWithFactory(configuration, miniClusterFactory).submitJob(jobGraph)提交了应用

3.1.5、在createWithFactory方法中创建了PreJobMiniClusterFactory类的miniClusterFactory对象;然后通过miniClusterFactory.submitJob方法提交应用(先启动了MiniCluster集群,再提交应用,并等待完成)
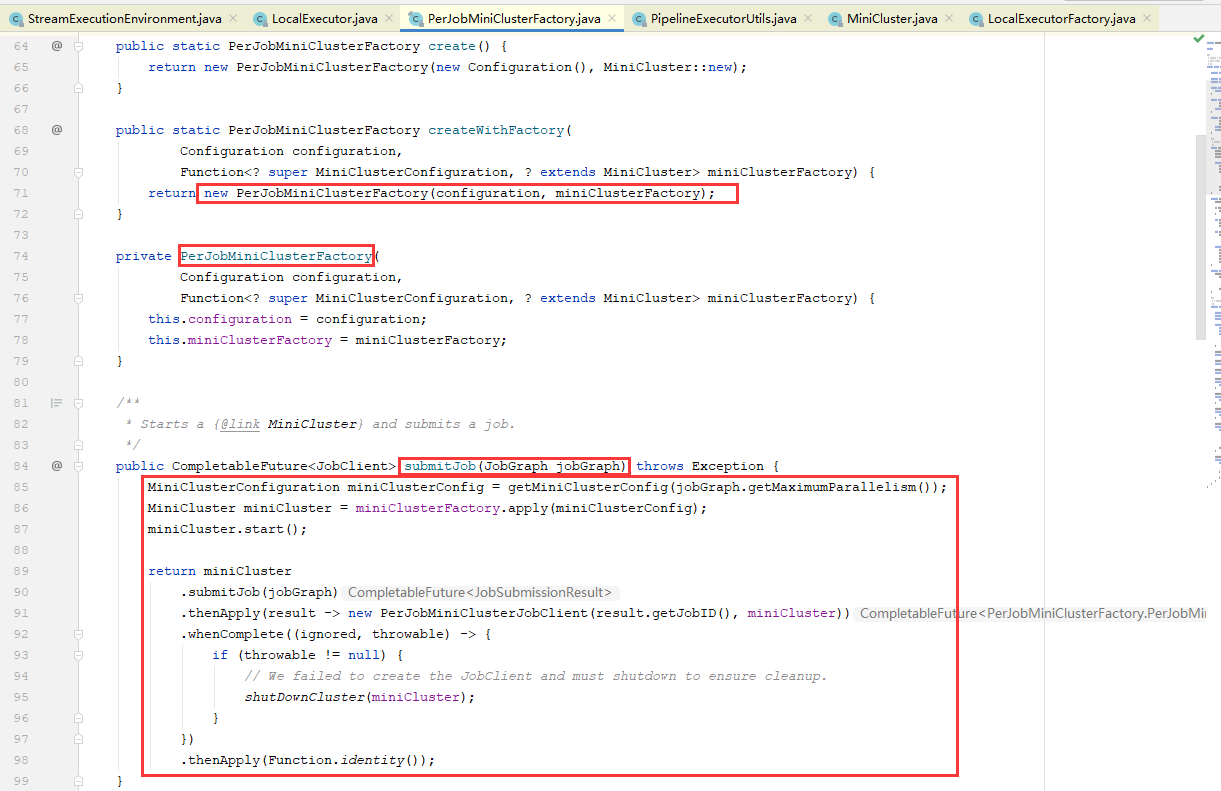
3.1.6、在上面,我们知道了,在PreJobMiniClusterFactory类的submitJob方法中,初始化配置并启动了MiniCluster集群,初始化MiniCluster配置的代码很简单,我们重点关注一下MiniCluster.start方法
初始化MiniCluster配置的getMiniClusterConfig方法:
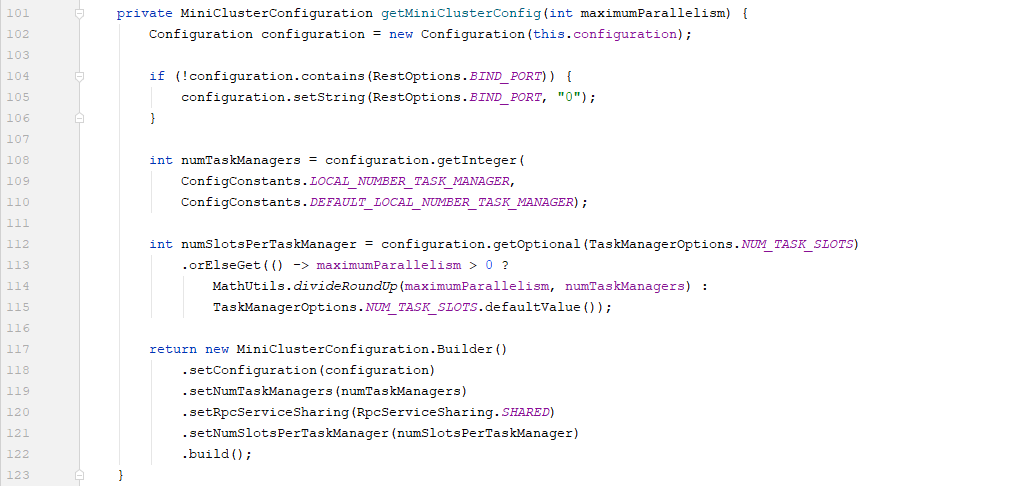
启动MiniCluster的start方法
4、上面的只是说明了,在DataStream应用中,从StreamGraph->JobGraph的转换,接下来,我们看一下,JobGraph->ExecutionGraph的转换
在Dispatcher类中,调用submitJob方法
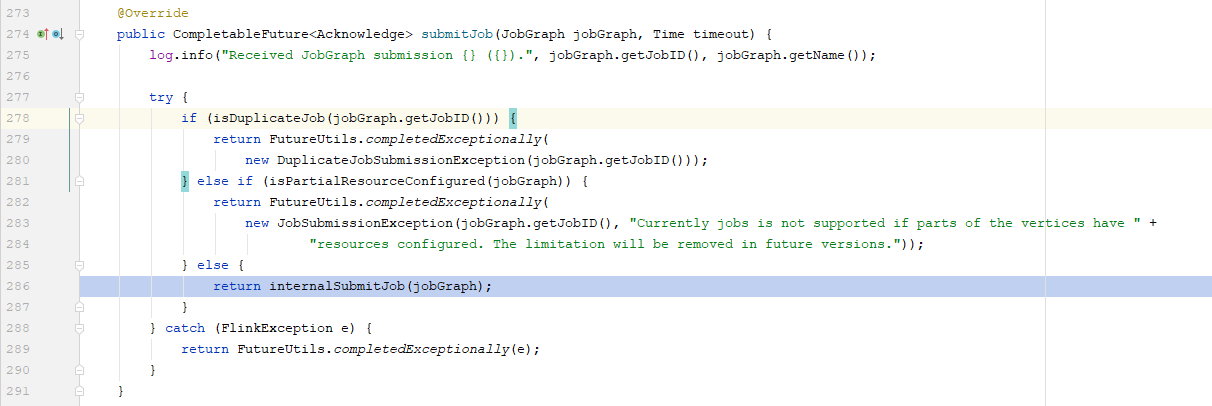
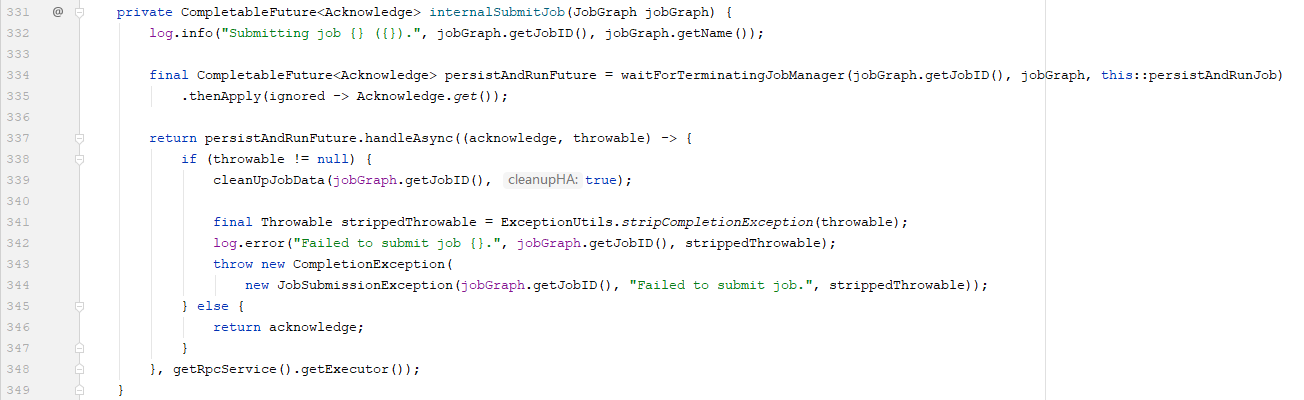
调用createJobManagerRunner(jobGraph)方法,并且通过this::startJobManagerRunner启动了JobManager
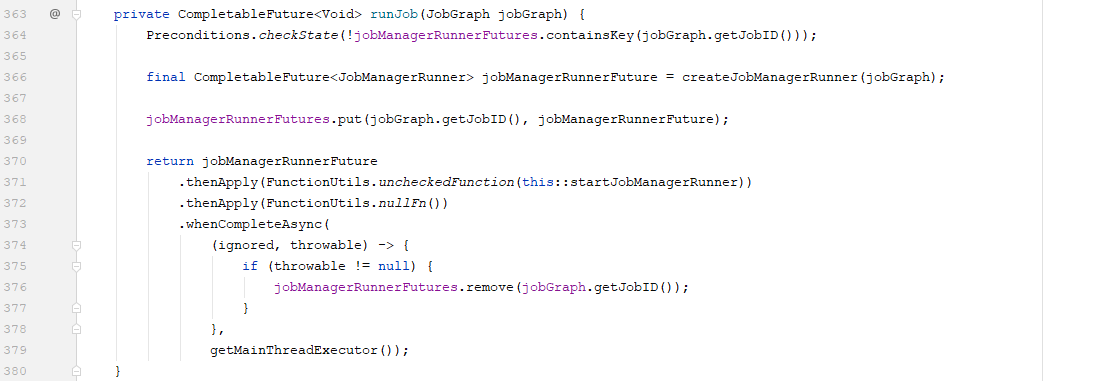
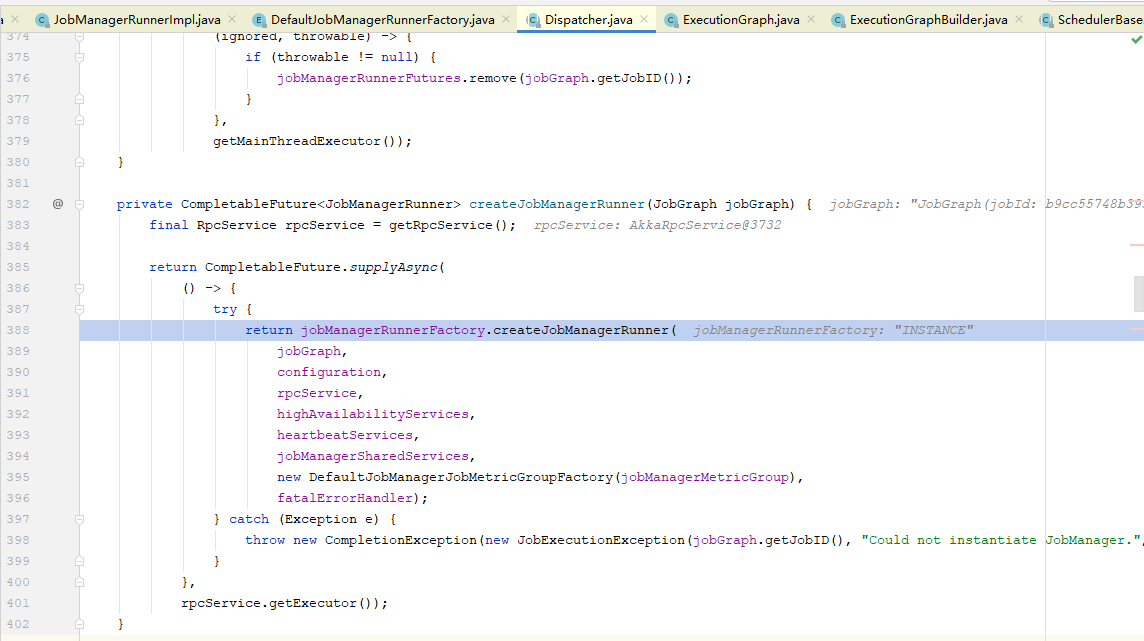
JobManagerRunner类是一个接口,其提供了一个子类JobManagerRunnerImpl的实现
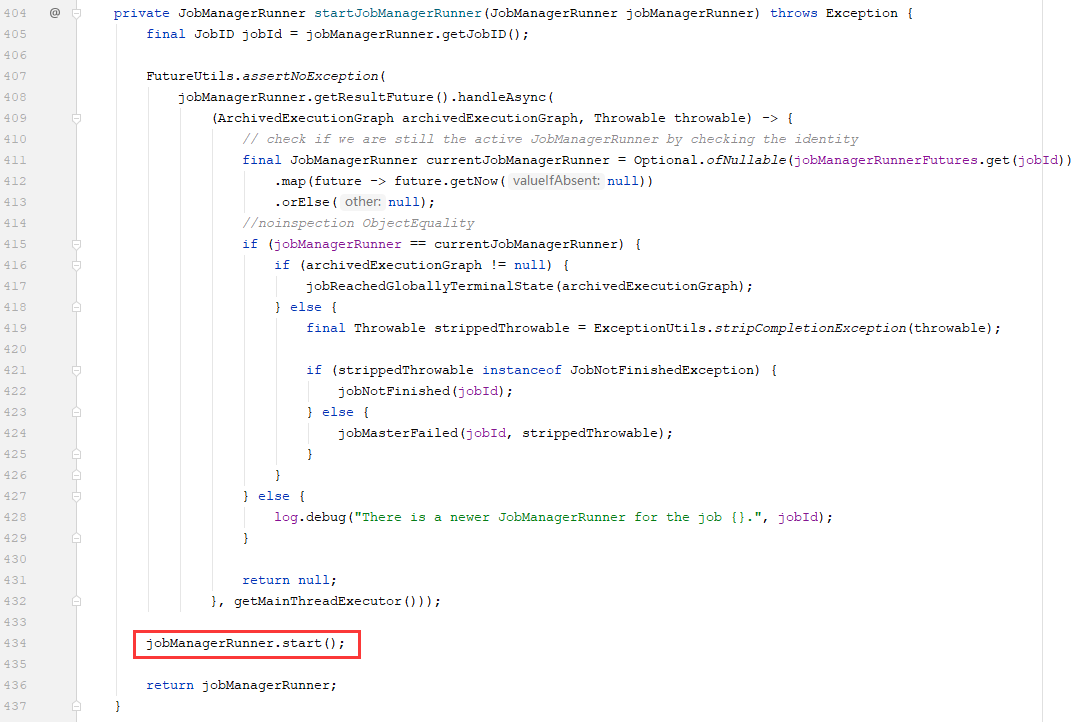
其实是调用JobManagerRunnerImpl类的start方法

===========================
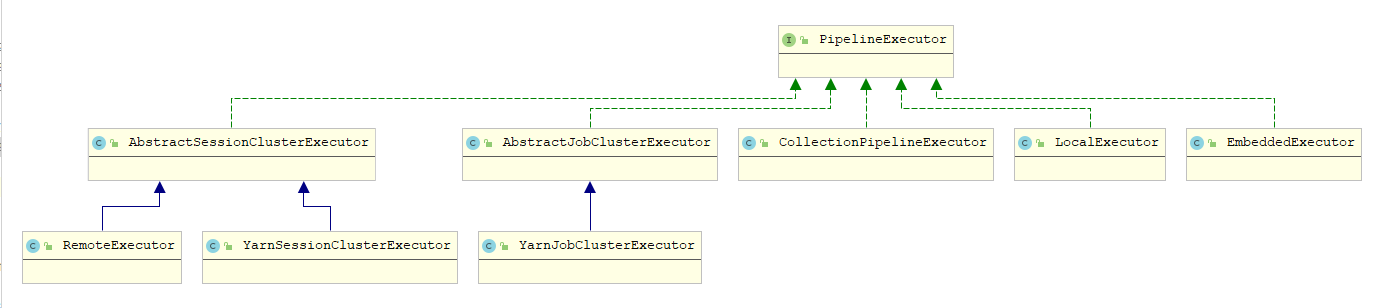
PipelineExecutor是Flink运行应用程序实现,