
谷粒商城所学知识点整理总结
环境搭建
Mysql
docker run -p 3306:3306 --name mysql \ -v /mydata/mysql/log:/var/log/mysql \ -v /mydata/mysql/data:/var/lib/mysql \ -v /mydata/mysql/conf:/etc/mysql \ -e MYSQL_ROOT_PASSWORD=root \ -d mysql:5.7
配置utf-8编码/mydata/conf/my.cnf(新建),重启生效
[client] default-character-set=utf8 [mysql] default-character-set=utf8 [mysqld] init_connect='SET collation_connection = utf8_unicode_ci' init_connect='SET NAMES utf8' character-set-server=utf8 collation-server=utf8_unicode_ci skip-character-set-client-handshake skip-name-resolve
进入容器:docker exec -it mysql /bin/bash
Redis
先创建对应的文件,然后执行代码,不然会将 redis.conf 创建为一个目录
1、mkdir -p /mydata/redis/conf
2、touch
/mydata/redis/conf/redis.conf
3、
docker run -p 6379:6379 --name redis -v /mydata/redis/data:/data \ -v/mydata/redis/conf/redis.conf:/etc/redis/redis.conf \ -d redis redis-server /etc/redis/redis.conf
4、开启redis 持久化:vi /mydata/redis/conf/redis.conf
添加 appendonly yes
重启生效
进入容器:docker exec -it redis redis-cli
ES
1、mkdir -p /mydata/elasticsearch/config
2、mkdir -p /mydata/elasticsearch/data
3、设置该配置文件可以被远程任何机器访问:echo "http.host: 0.0.0.0" >>/mydata/elasticsearch/config/elasticsearch.yml
4、授予所有权限:chmod -R 777 /mydata/elasticsearch/
5、创建容器并挂载
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms64m -Xmx512m" \ -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \ -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ -d elasticsearch:7.4.2
# 设置开机启动elasticsearch
docker update elasticsearch --restart=always
配置IK分词器
1、前往ik分词器网站https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v7.8.1,找到es对应版本的ik分词器,下载。再通过 xftp 将ik 分词器解压包添加到挂载目录plugin下
2、前往es里,docker exec -it id /bin/bash ,执行
elasticsearch-plugin list,如果出现ik说明安装成功。
配置ik分词
1、进入 ik 目录下的config目录,vi IKAnalyzer.cfg.xml,打开自定义的分词库设置,设置自定义分词库地址
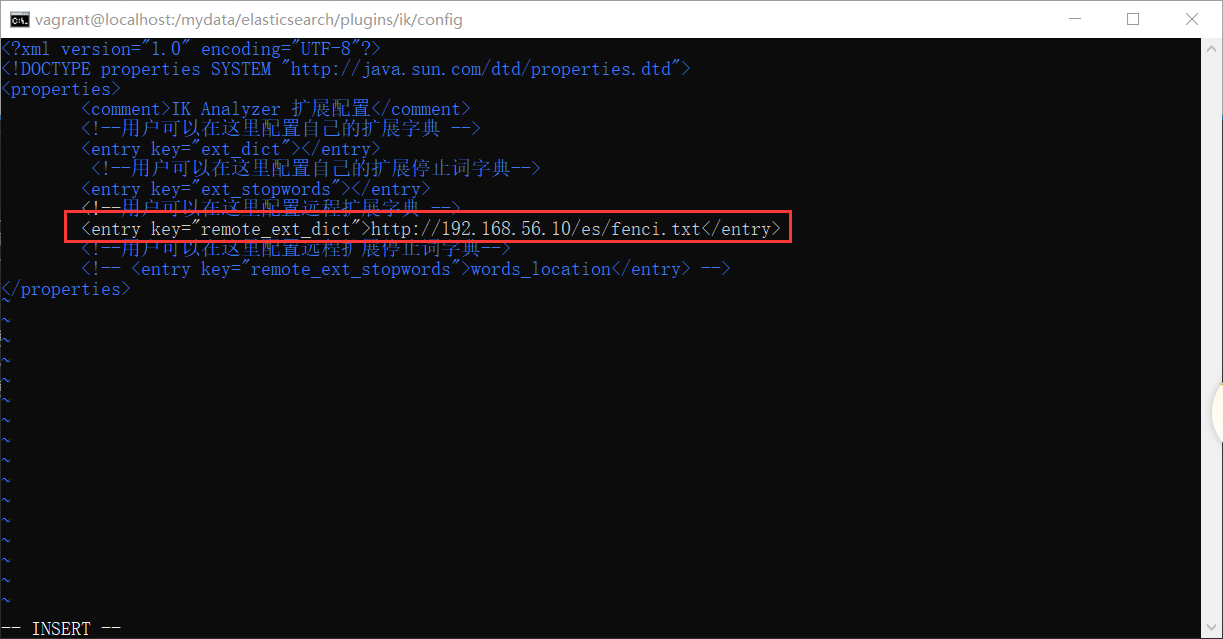
2、保存退出,重启nginx。
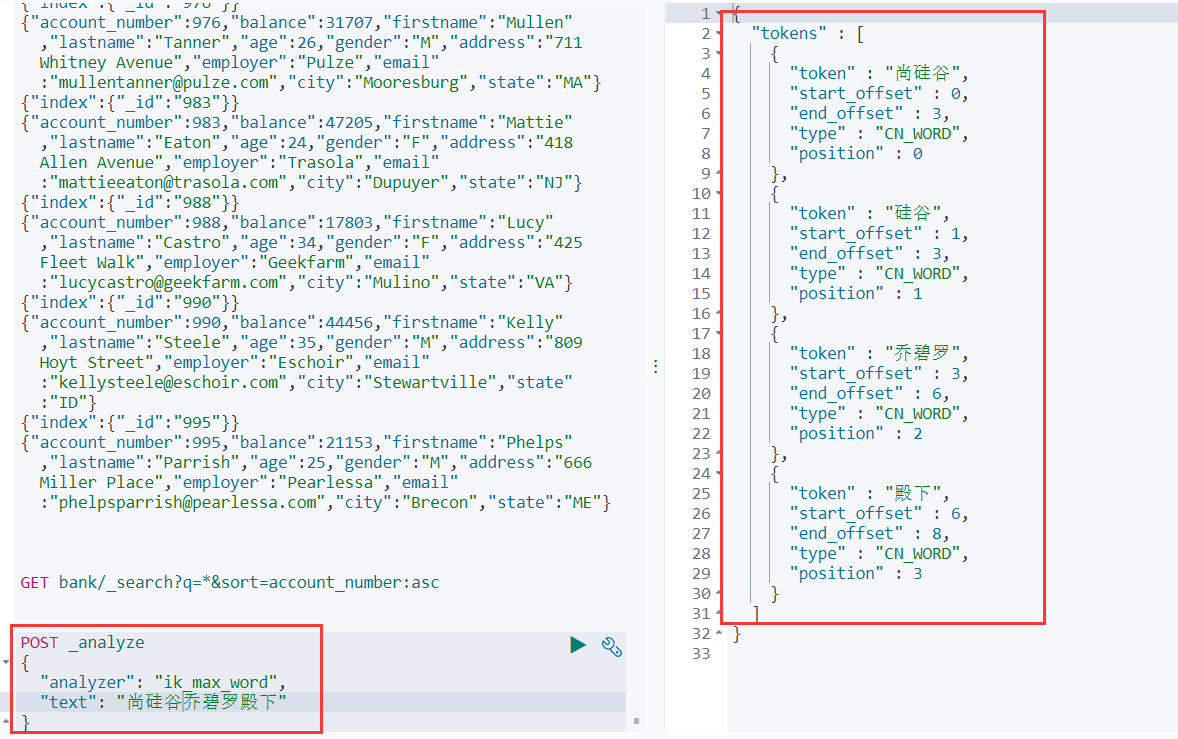
3、登陆 kibana,使用自定义分词作为语句来测试,查看结果
Nginx
1、docker run -p80:80 --name nginx -d nginx:1.10
2、创建目录:
mkdir -p /mydata/nginx/html
mkdir -p /mydata/nginx/logs
mkdir -p /mydata/nginx/conf
3、拷贝配置文件到挂载目录:
docker container cp nginx:/etc/nginx /mydata/nginx/conf
4、因为会多出一个目录,所以需要对目录进行调整
1)mv /mydata/nginx/conf/nginx/* /mydata/nginx/conf/
2)rm -rf /mydata/nginx/conf/nginx
5、停止运行中的nginx,然后删除
Docker stop nginx
Docker rm nginx
6、重新创建一个nginx:
docker run -p 80:80 --name nginx \ -v /mydata/nginx/html:/usr/share/nginx/html \ -v /mydata/nginx/logs:/var/log/nginx \ -v /mydata/nginx/conf/:/etc/nginx \ -d nginx:1.10
配置文件动静分离和反向代理:

Kibana
1、创建容器
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 -p 5601:5601 -d kibana:7.4.2
2、开机启动:docker update kibana --restart=always
RabbitMQ
docker run -d --name rabbitmq -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 25672:25672 -p 15671:15671 -p 15672:15672 rabbitmq:management

阿里云免密登陆

Cloud与AlibabaCloud组件、SpringBoot版本关系
见 版本说明
预检请求与跨域解决
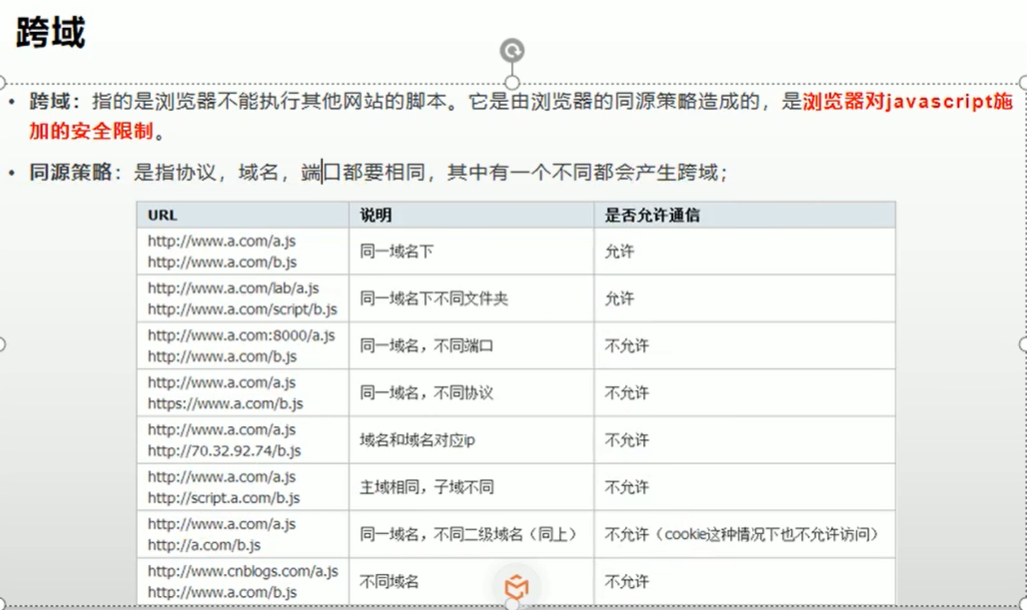
预检请求:对那些可能对服务器产生副作用的 HTTP 请求方法,浏览器必须首先使用 OPTIONS 方法发起一个预检请求,从而获知服务器端是否允许该跨域请求。
跨域:是浏览器对 JavaScript 施加的安全限制,使浏览器不能执行其他网站的脚本。

解决:
1、使用Nginx反向代理请求来解决
2、配置跨域放行。如在Controller 上添加@CrossOrigin注解。或者配置放行请求
@Configuration public class MyCorsConfiguration { @Bean public CorsWebFilter corsWebFilter() { UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource(); CorsConfiguration corsConfiguration = new CorsConfiguration(); //1.配置跨域 corsConfiguration.addAllowedHeader("*"); //头 corsConfiguration.addAllowedMethod("*"); //请求方式 corsConfiguration.addAllowedOrigin("*"); //请求来源 corsConfiguration.setAllowCredentials(true); //是否允许携带cookie source.registerCorsConfiguration("/**", corsConfiguration); return new CorsWebFilter(source); } }
配置中心
1、系统会默认读取nacos配置文件中的名字为“当前应用名.properties”的文件
2、在Controller层上添加@RefreshScope注解,实现nacos配置中心修改动态刷新。
具体配置:
1、配置中心可以根据模块来读取不同的配置文件,此时就可以指定指定的命名空间了,配置就会读取指定的命名空间下的所有配置文件(也会读取指定命名空间下默认会读取的配置文件)。指定命名空间的参数是spring.cloud.nacos.config.namespace=命名空间id,默认是public
2、在命名空间下还可以指定分组名,来读取指定命令空间下指定分组的所有配置文件(也会读取指定命名空间下默认会读取的配置文件)。spring.cloud.nacos.config.group=分组名
3、当配置文件较多时,还可以将不同的配置划分为各自的文件,然后指定读取相应的文件,此时可以不再指定分组名(也会读取指定命名空间下默认会读取的配置文件)
4、对于以上三种,,如果没有指定分组会读取default group下的默认命名配置文件,如果没有指定命名空间,那么会从public下读取相应的默认命名配置文件。
本地和nacos服务器上的优先使用服务器上的配置
知识点
远程调用
feign接口的方法名和URL必须和调用接口的对应上。而参数类型可以不是同一个Class类,只要属性能够对上就可以。
Feign远程调用会丢失请求头
如 Cookie,如果调用的模块有 Cookie 信息的验证,那么这条请求就会被拦截,此时可以使用装饰者模式添加配置,在 feign 请求生成时将之前请求携带的 Cookie 添加到 feign 请求中。
@Bean public RequestInterceptor requestInterceptor(){ return new RequestInterceptor() { @Override public void apply(RequestTemplate requestTemplate) { // 1、获取开始请求 ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); if(requestAttributes != null){ HttpServletRequest request = requestAttributes.getRequest(); // 2、将开始的请求头Cookie数据设置到新请求中去 String cookie = request.getHeader("Cookie"); requestTemplate.header("Cookie",cookie); } } }; }
异步编程丢失请求头
在异步线程创建新的线程请求时,也会丢失之前请求携带的请求头数据,解决原理和 feign 一样。
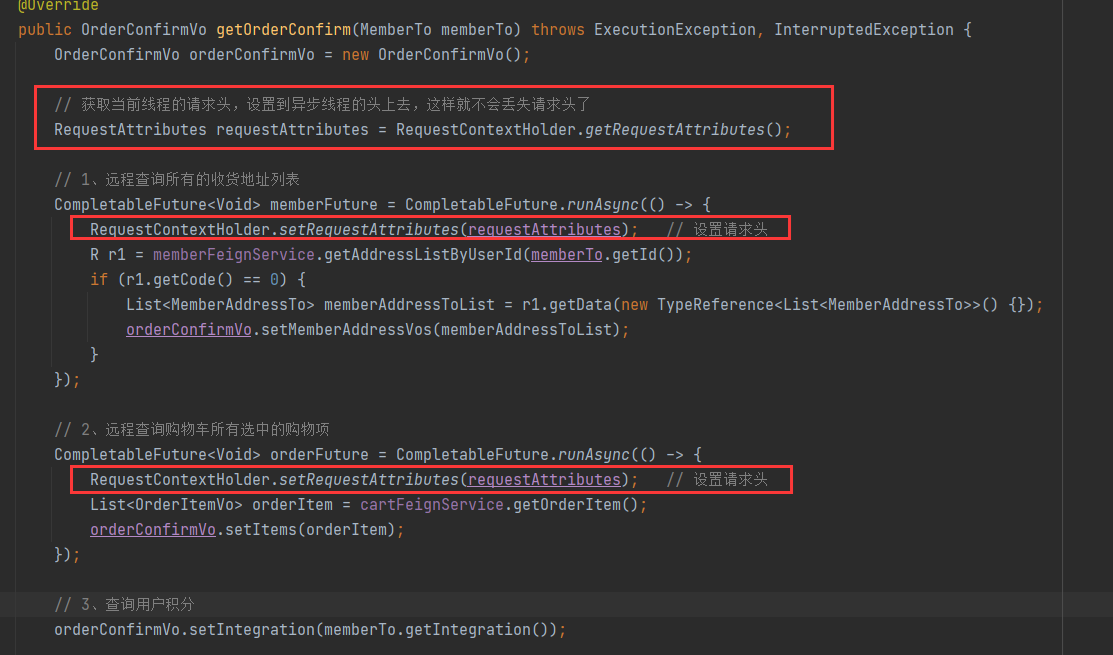
在不同的异步线程中都可以使用RequestContextHolder.setRequestAttributes,原理是RequestContextHolder内部的 RequestAttributes 是使用ThreadLocal存储的。
JSR303数据校验
常用注解:
JSR303验证注解
@NULL,是否为null
@NotNull,是否不为null
@NotBlank,是否不为null且长度至少为1(trim()之后不能为0)
@NotEmpty,是否不为null并且长度不为0,不能支持数字类型的
@Min,大于指定的值
@Pattern,正则表达式,用于String类型
@Max,小于指定的值
@Past,日期必须早于现在的时间
@Url,必须为URL格式
@Range,指定min与max之间的数
1、属性上加判断注解,可以指定注解返回的异常信息内容
2、请求的Controller层的方法参数添加@Valid注解,可以在方法参数后面加一个BindingResult result参数,可以获得校验的结果,然后在Controller层里编写异常处理的代码
优化1:统一异常处理类:将Controller层的异常代码统一管理,先自定义异常处理类,然后在类上标注
@RestControllerAdvice(basePackages="com.gulimall.product.controller")注解,然后该方法就可以处理指定包下的所有方法异常
优化2:类中编写方法进行处理,方法上@ExceptionHandler(value=)来指定处理的异常类型。
优化3:可以在公共类中定义枚举来包含异常的code与信息内容,然后来调用
@RestControllerAdvice(basePackages = "com.gulimall.product.app") public class GulimallExceptionControllerAdvice { // JSR303数据校验异常 @ExceptionHandler(value = MethodArgumentNotValidException.class) public R handlerException(MethodArgumentNotValidException e) { log.error("数据校验出现问题{},异常类型:{}", e.getMessage(), e.getClass()); e.printStackTrace(); BindingResult bindResult = e.getBindingResult(); Map<String, String> resultMap = new HashMap<>(); bindResult.getFieldErrors().forEach((fieldError) -> { resultMap.put(fieldError.getField(), fieldError.getDefaultMessage()); }); // return R.error(400,"数据校验出现问题").put("data",resultMap); return R.error(BizCodeEnum.VAILD_EXCEPTION.getCode(), BizCodeEnum.VAILD_EXCEPTION.getMsg()).put("data", resultMap); } @ExceptionHandler(value = Throwable.class) public R handlerException(Throwable throwable) { throwable.printStackTrace(); return R.error(BizCodeEnum.UNKNOW_EXCEPTION.getCode(), BizCodeEnum.UNKNOW_EXCEPTION.getMsg()); } }
优化4:分组。要先创建几个代表分组的接口,在entity的异常注解中设置group来让不同的方法启用不同的注解异常@NotNull(groups = {AddGroup.class, UpdateStatusGroup.class})
,然后再修改@Valid注解为@Validated({AddGroup.class})指定分组
注意:使用@Validated({})指定了分组 那么属性上的校验注解要生效就必须指定分组且分组必须为这里@Validated({})里面存在的分组,不然校验不起作用
// 但是如果只使用@Validated(),没有指定组名,那么指定组名的校验注解就不会生效,没有指定组名的就会生效。
Mybatis-Plus 实体类相关
逻辑删除
1、
mybatis-plus: global-config: db-config: id-type: auto # 主键自增 logic-delete-value: 1 #逻辑删除值 logic-not-delete-value: 0 #逻辑未删除值
2、在属性上添加@TableLogic(value = "1", delval = "0")注解,如果括号里没有配置就使用配置文件配置的,如果配置了就使用括号里的配置。
属性为空时不显示此属性

主键为自己输入,非自增
使用@TableId默认是自增的,这时候自己设置ID插入时会抛异常,可以指定为自己输入。@TableId(type = IdType.INPUT)
时间属性设置为自动填充
1、添加注解
2、添加配置类

域名原理
1、当在网址输入域名时,会首先在本地 hosts文件查看有没有对应域名设置,如果有,直接就去访问域名关联的ip地址。
2、如果本地没有配置,那么就去本地配置DNS 地址上寻找域名配置,DNS相当于公共的 hosts 配置,找到后再访问 ip 地址

OSS对象存储
在后台配置好公匙和密匙,以及OSS的域名,使用官网提供的方法编写返回返回的 Policy方法,前端通过后端返回的 Policy 直接访问OSS服务器存储对象数据。
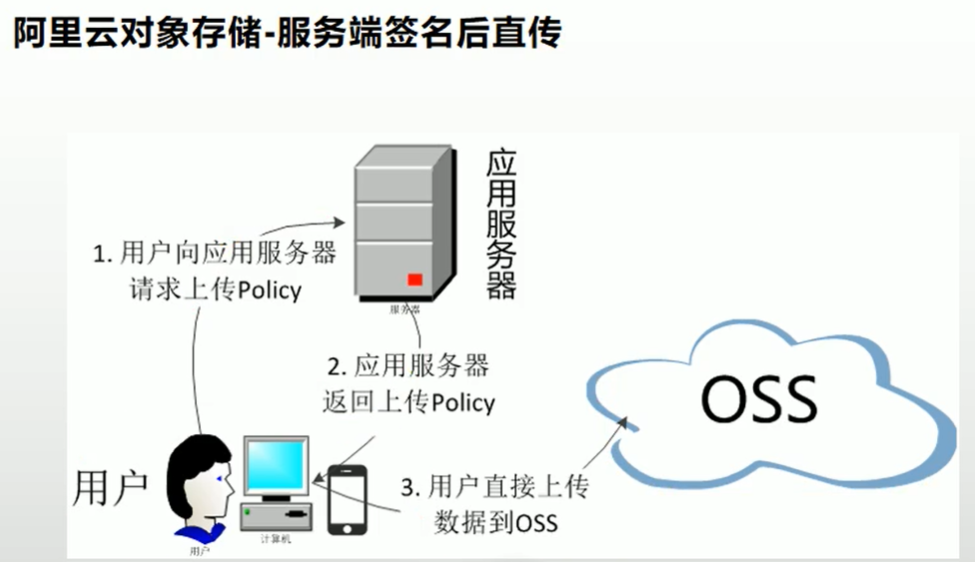
异步线程
使用
1、创建异步线程。
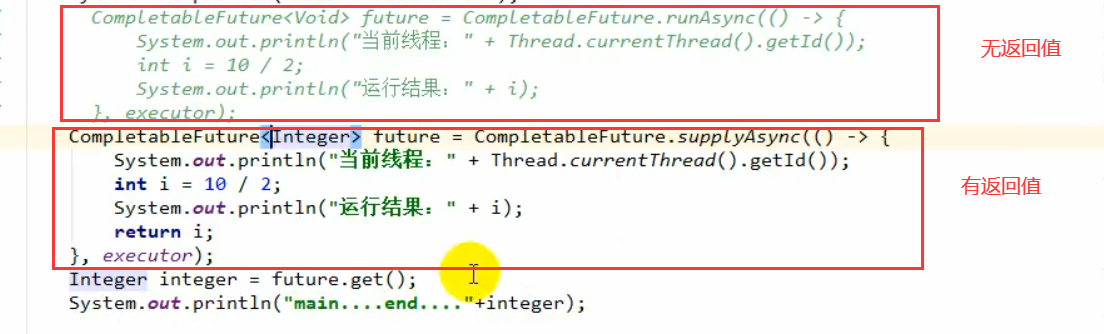
2、执行完添加回调方法。


whenComplete 回调同步方法
whenCompleteAsync 回调方法交给线程池执行(一般是异步,也有可能是会再次交给同一个线程执行)
exceptionally:捕获返回值和异常,并对返回值进行修改。(在异常发生时才会触发)
handle:捕获返回值异常,并对返回值进行修改(是否发生异常都会触发)
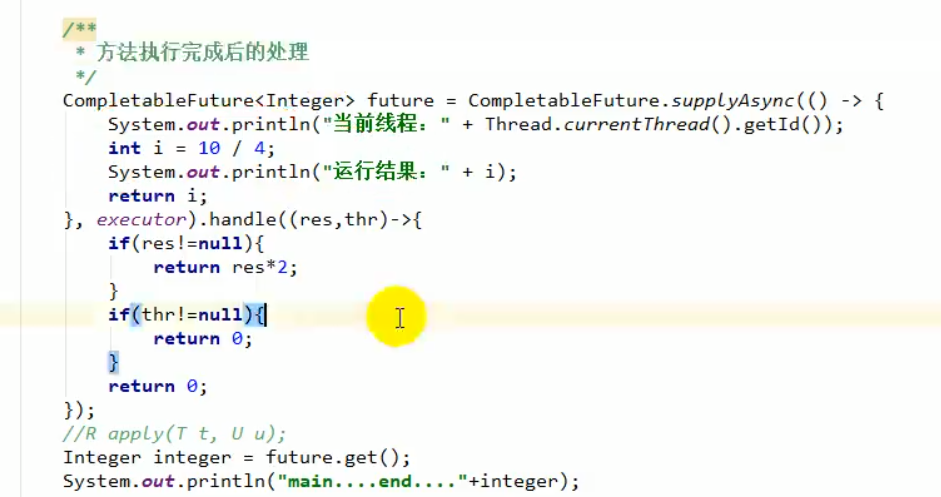
3、线程串行化

thenRun系列的,在上一个线程执行完后直接执行,不需要获取其返回值。
thenAccept系列,在上一个线程执行完后获取其返回值执行,但是和thenRun系列一样,执行完后不会有返回值。
thenApply系列的,是在上一个线程执行完,得到其返回值来执行,执行完后再将这个方法返回值返回出供下一个线程继续使用。
其他的带Async就是交给线程池执行,否则就是跟随上一个线程同步执行。



4、两任务同时执行完再继续执行




和上面的规律一样,
runAfterBoth 对应 thenRun,两个任务执行完立刻执行,
thenAcceptBoth 对应 thenAccept,两个任务执行完获取其结果,再执行
thenCombine 对应 thenApply,两个任务执行完获取其结果再执行,最后会有返回值



5、两任务单个完成就继续执行





![]()

6、多任务全部执行完 / 执行完一个就继续执行
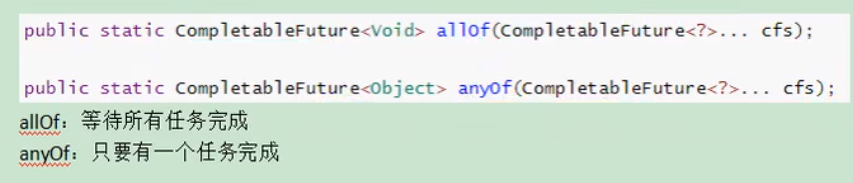

配置
1、编写配置属性的配置类,并将其加入容器
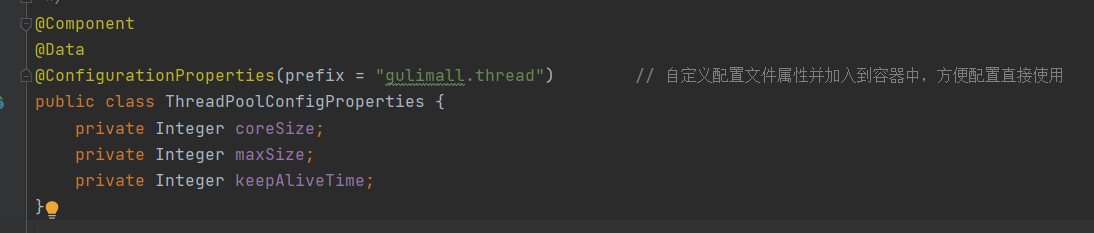
2、这样就可以直接在配置文件中定义配置的属性
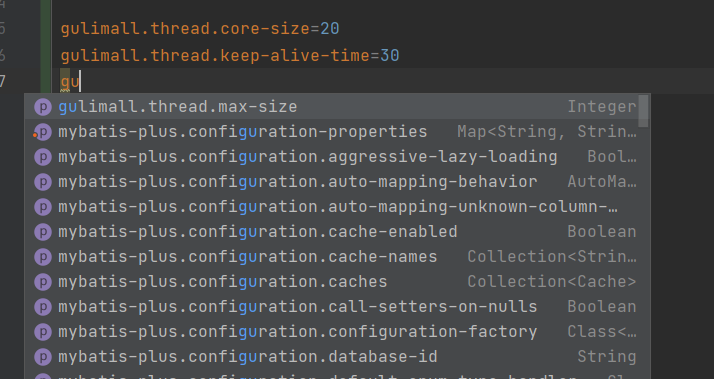
3、编写线程池的配置,由于上面将配置属性的配置类加入了容器,所以可以直接获取
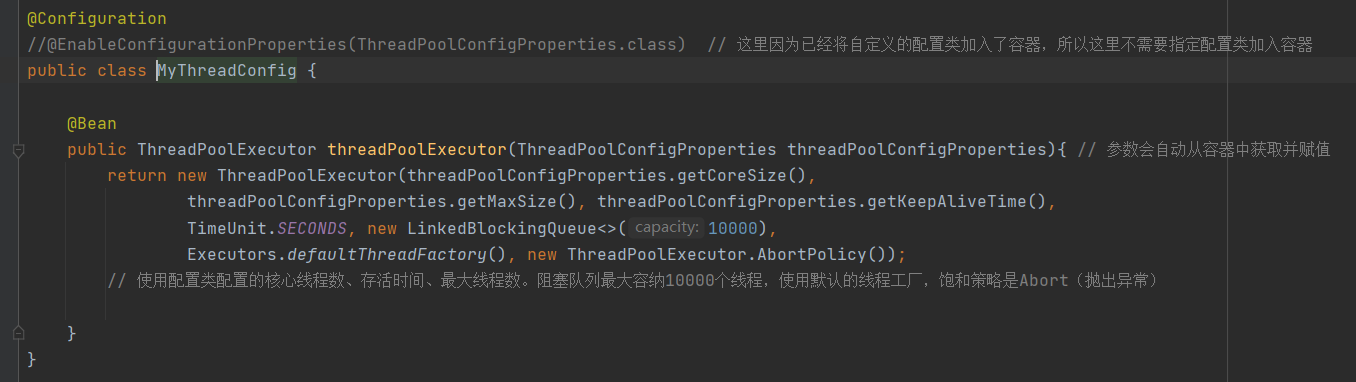
这个可以对比SpringCache 的配置,那里CacheProperties 配置类默认没有加入容器,所以需要额外声明,这里则不需要。
使用案例
密码加密
密码加密是为了防止数据库外泄导致密码泄漏。常用的加密算法是 MD5,其特点是
1、长度一致。不管原密码长度多少,加密后的长度都是一样的。
2、不可逆。不支持将加密后的密码转回加密前的原密码。
3、易计算。计算效率高。
但是也存在缺点,会被暴力破解。所以 SpringSecurity 在使用 BCryptPasswordEncoder 编写加密规则时,引入了加盐概念。也就是规定一个数据(盐值)和传来的密码按规则进行拼接,这样在破解时由于不知道这个盐值和拼接规则,破解的难度就会加大。具体实现是通过方法生成一个随机的盐值,然后通过 hash 加密将这个盐值与原密码进行加密(会对盐值和原密码再进行处理),生成最终加密的密码。在验证密码时,由于加密过程是不可逆的,所以验证时需要将原密码进行加密与数据库的密码进行比较,如果相同通过。
加密:encode
![]()
验证:matches
![]()
每次调用加密方法生成的密码因为每次都使用不同的盐值而是不同的,而使用 matches 可以验证的原理就是在加密后的密码中保存了盐值,同一个盐值加上原密码就可以推出最终密码,从而验证密码是否一致
OAuth2.0
OAuth2.0 是一种广泛用于社交登陆的安全、开发的用户资源授权协议。任何服务提供商都可以实现自身的OAuth协议,来兼容不同的平台、语言。社交登陆过程用到的服务器主要分为授权服务器和资源服务器,授权服务器用于验证用户信息,通过返回访问令牌,然后就可以通过访问令牌去资源服务器访问相应的信息资源。
令牌种类:
1、授权码模式:最常用的,也是最安全的一种,首先通过第三方应用验证登陆,授权服务器返回 code,再通过 code 搭配 app_id、app_secret 来从授权服务器获取授权令牌,最终通过授权令牌访问资源服务器。优点是访问令牌token存储在服务器上,不易被截取,同时code是一次性,使用后失效,更安全。同时支持更新 token,避免了 token 过期问题。应用于第三方平台的登陆。
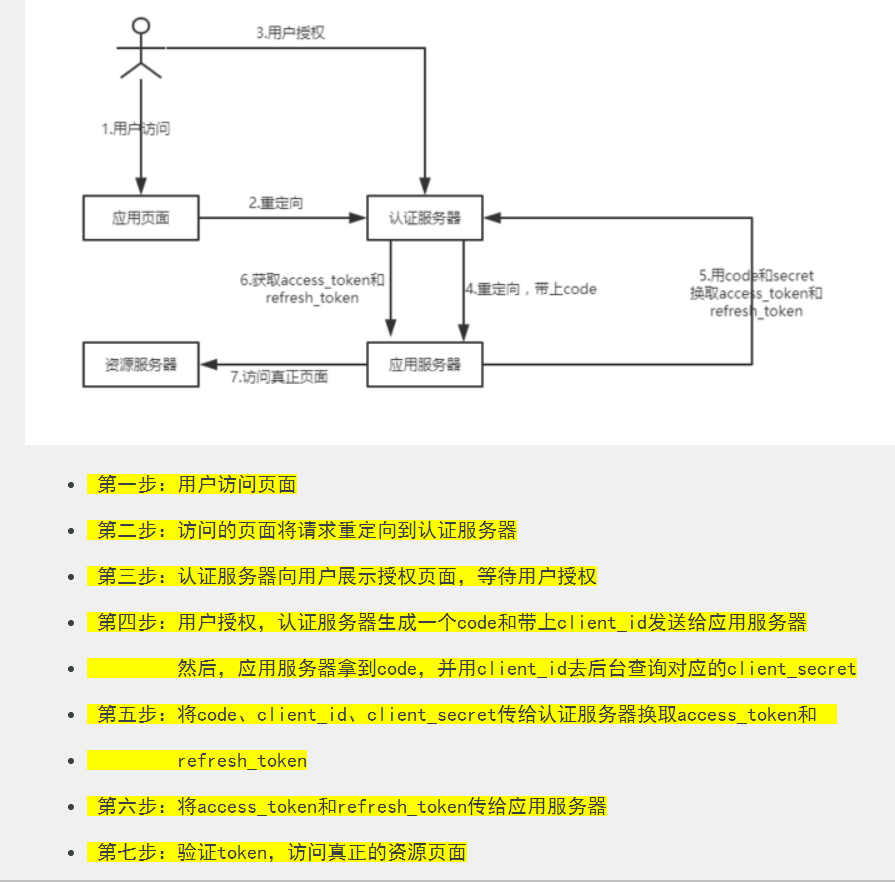
2、简化模式:省去了获取code 的步骤,直接从认证服务器获取 token,是基于浏览器的应用,所以容易被截取 Token,这点可以通过减小 Token 的存活时间解决,但是不支持刷新 token,所以 token 过期后又无法使用。优点就是过程简单。
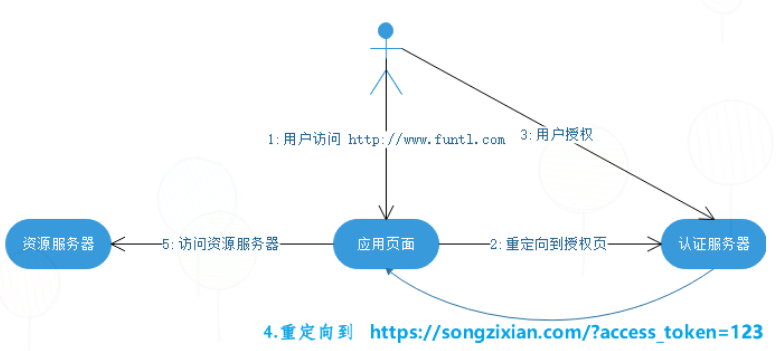
3、密码模式:与简化模式大致一样,只不过是直接输入用户名、密码访问认证服务器来获取 token,因为是直接输入密码,所以需要认证的平台和当前平台有高度的信任。这种一般用于一家企业的两个产品平台上。

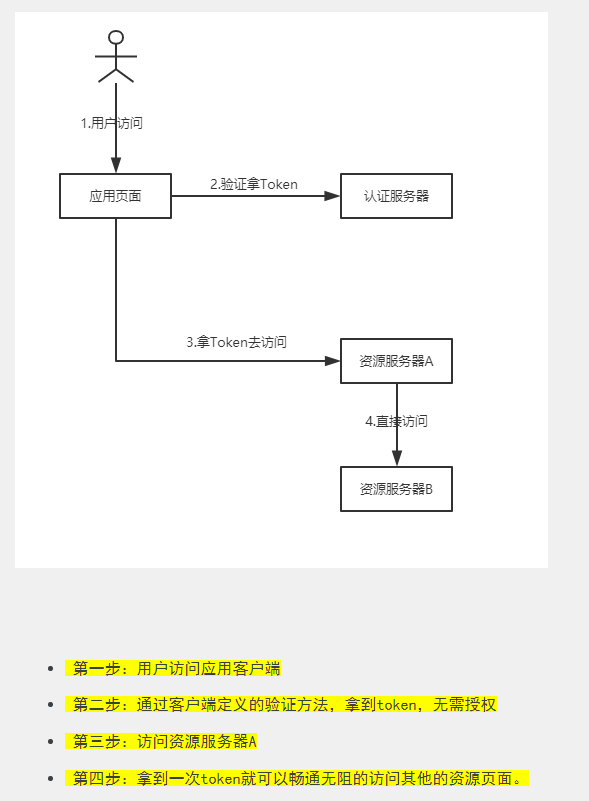
4、客户端凭证模式:在一次验证通过后,返回的 token 无平台限制,可以访问任意平台的资源。这种模式安全隐患也是最大的。
微博开通使用的就是授权码模式:
先在微博开放平台提交进行身份认证,然后添加应用,填写必要的消息,以及高级消息的授权回调页、取消回调页。然后根据文档中 OAuth2.0 中找到 “Web网站的授权”,将URL添加到点击微博图标后跳转的URL,client_id 为基本信息的 App Key,redirect_uri 为填写登陆通过后跳转的URL。
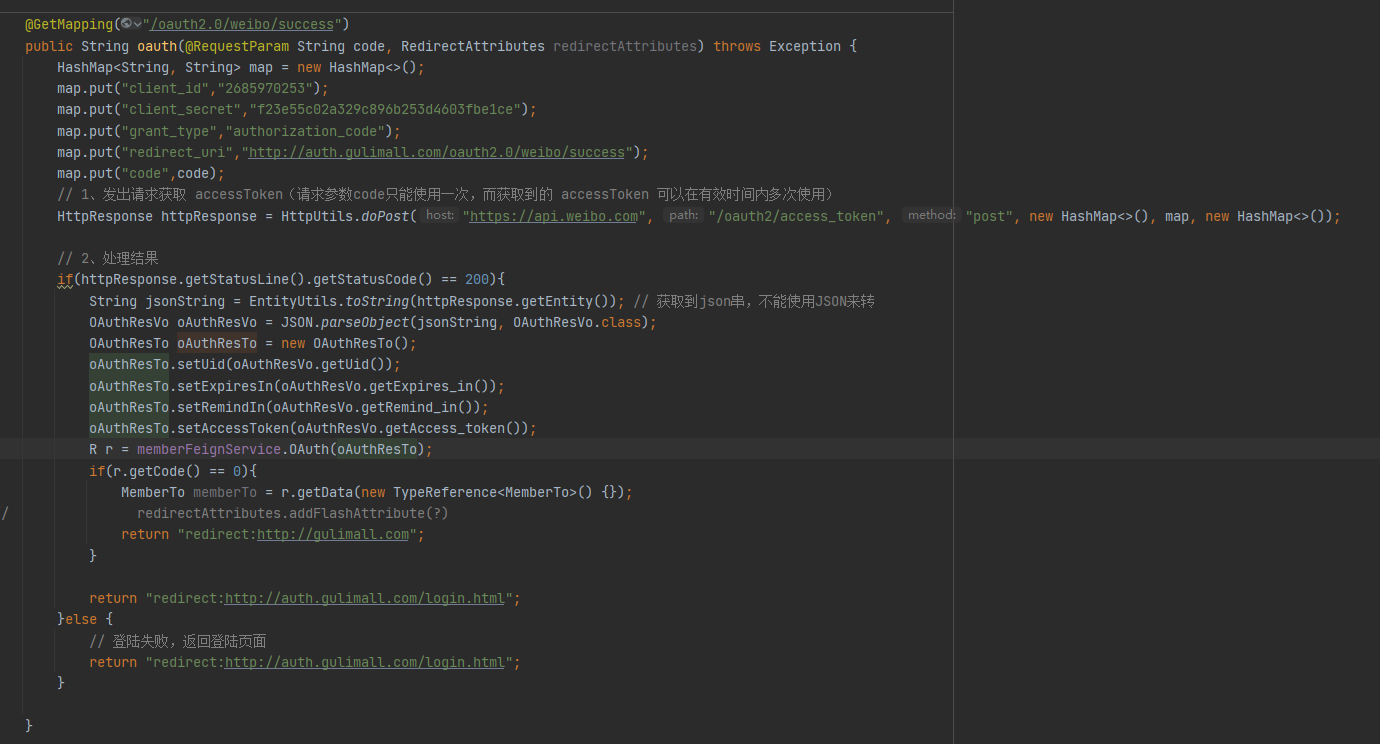
Session数据共享
在默认情况下,集群项目中,一个服务器保存的Session数据,另一个服务器是访问不到的,但是可以通过一些方法来实现。
Session复制(不推荐)
优点:配置简单。
缺点:在数据量大或者集群服务器多时影响带宽、降低系统性能。同时由于每台服务器都需要存储所有的session数据,会浪费大量空间。
客户端存储(不推荐)
将session 存储在 Cookie 里。
优点:节省服务器空间。
缺点:Cookie不安全,可能会造成数据泄漏。Cookie 长度限制,数据量太大会发不出去。每次发送都会携带数据,浪费带宽。

Hash一致性
同一个会话发送到同一个服务器中。可以使用 nginx 使用 ip_hash 的负载均衡策略。
优点:配置简单,不会浪费带宽、空间资源
缺点:服务器重启后 session 可能会丢失。当集群拓展时 session 会重新分布,这样也会导致一些用户丢失原本的 session 数据。

将数据存入中间件(推荐)
如 Redis。当前项目就是使用 Redis 来存储 session 数据,具体就是使用 SpringSession 来实现的。并通过配置增加了Cookie 作用的域名范围。
@Configuration public class SessionConfig { @Bean public CookieSerializer cookieSerializer() { DefaultCookieSerializer cookieSerializer = new DefaultCookieSerializer(); //放大作用域 cookieSerializer.setDomainName("gulimall.com"); cookieSerializer.setCookieName("GULISESSION"); cookieSerializer.setSameSite(null); return cookieSerializer; } @Bean public RedisSerializer<Object> springSessionDefaultRedisSerializer() { return new GenericJackson2JsonRedisSerializer(); } }
缺点:由于是通过 Cookie 实现的,所以 Cookie 作用的范围也是这一因素的限制条件,最多只能在同一个域名下作用。如果想要实现不同域名间的访问,可以通过单点登陆。
购物车
在购物车模块添加一个拦截器,在请求进来时根据是否登陆来创建一个当前用户(临时用户)购物车信息对象,将其存入 ThreadLocal 以及 Redis 中(Redis 中的 key 就是 " 固定前缀 + 用户ID(如果是临时用户就是随机生成的UUID)"),并创建一个 Cookie 保存购物车用户数据(生成的UUID)。下次查询时就先判断是否已登陆状态,如果是将通过用户ID查出其登陆下的购物车数据,以及 Cookie 携带的UUID对应的 Redis 购物车数据,进行合并,最后删除 UUID 对应的 Redis 数据。
public class CartInterceptor implements HandlerInterceptor { public static final ThreadLocal<UserInfoTo> threadLocal = new ThreadLocal<>(); /** * 执行前拦截,将请求携带的cookie存入 threadLocal * @param request * @param response * @param handler * @return * @throws Exception */ @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { MemberTo memberTo = (MemberTo) request.getSession().getAttribute(LoginConstant.LOGIN_USERNAME); UserInfoTo userInfoTo = new UserInfoTo(); // 如果已登录将ID加入属性 if(memberTo != null){ userInfoTo.setUserId(memberTo.getId()); }else{ userInfoTo.setTempUser(true); } Cookie[] cookies = request.getCookies(); if(cookies != null && cookies.length>0){ for (Cookie cookie : cookies) { if(cookie.getName().equals(CartConstant.CART_COOKIE_NAME)){ userInfoTo.setUserKey(cookie.getValue()); } } } if(StringUtils.isEmpty(userInfoTo.getUserKey())){ // 如果为空,说明没有传来对应的 Cookie,那么就创建一个UUID的Cookie userInfoTo.setUserKey(UUID.randomUUID().toString()); } threadLocal.set(userInfoTo); return true; } /** * 返回请求前执行,将对应的user_key 的Cookie返回回去 * @param request * @param response * @param handler * @param modelAndView * @throws Exception */ @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception { UserInfoTo userInfoTo = threadLocal.get(); boolean isEmpty = true; Cookie[] cookies = request.getCookies(); for (Cookie cookie : cookies) { if(cookie.getName().equals(CartConstant.CART_COOKIE_NAME)){ isEmpty = false; } } // 如果不是临时用户或是第一次绑定的临时用户,那么就返回user_key 的Cookie if(!userInfoTo.getTempUser() || isEmpty){ Cookie cookie = new Cookie(CartConstant.CART_COOKIE_NAME,userInfoTo.getUserKey()); // 如果不是临时用户,那么就延长有效时间 cookie.setDomain("cart.gulimall.com"); cookie.setMaxAge(CartConstant.CART_COOKIE_LIVE_TIME); response.addCookie(cookie); } } }
userKey 存储的是购物车的随机码,userId 就是已登陆的用户ID,tempUser 表示当前用户是否是临时用户,用于来查询购物车数据时是否进行数据合并。
消息队列
特点
1、一个队列可以被多个客户端监听,但一个消息只能被一个客户端所接收。一个客户端处理完一个消息后才会去接收下一个消息
2、接收消息时需要添加注解@EnableRabbit,如果不需要监听队列就不需要添加这个注解
3、在定义接收消息的方法时,在方法参数上可以使用 Message 作为消息的原生结构,此时可以使用 getBody来获取携带的数据,getMessageProperties 来获取头属性消息;也可以直接定义消息数据的类型,直接获取携带的数据。

4、@RabbitListener表示监听某个队列,可以标注在方法上或类上。标注在类上就可以搭配@RabbitHandler 注解表示某个方法是来监听某个队列的消息,没有@RabbitHandler注解的就不是监听方法。这样做是可以定义接收多个类型对象数据消息的接收接口。

消息队列的实体类要用同一个
消息可靠性
1、生产者到服务器 Broker。发送成功回调。
1)开启发送端确认。
![]()
2)添加回调方法

2、服务器到消息队列,失败回调。
1)开启配置
![]()
spring.rabbitmq.template.mandatory=true:队列未收到消息,就回调错误消息给发送者
2)添加失败回调方法
3、消息队列到生产者。手动 ACK。
1)添加配置,默认是auto,自动确认。
![]()
2)接收方法里进行手动确认
deleveryTag 是一个自增的消息唯一标识
此外,如果发生异常,可以取消这次确认,并选择是否重新加入队列。拒绝确认有两种方式。一种Nack,一种是 Reject。区别是 Nack 会将当前消息之前的所有未确认的消息也取消确认,而 Reject 只针对于当前消息。(未确认/取消确认的消息会被标记为 unacked 状态,即使宕机也不会丢失)。

4、每条发送的消息都进行持久化存储,进行定时检查,对失败的消息进行重发。
5、开启RabbitMQ的事务(效率低,不推荐)
channel.txSelect()声明启动事务模式;
channel.txComment()提交事务;
channel.txRollback()回滚事务。
消息幂等性
在使用手动确认时,会存在一个问题,如果在消息执行完后还未手动确认,发生了断点,那么下次就会被检测到未确认,重新发送,这就导致客户端对一条消息消费了多次。所以应该将消费端设计为幂等性的(如果把手动确认放在开始,那么就和自动确认没区别了,甚至还意识不到丢失了消息,更严重)。
可以将单次操作与一个唯一值绑定,在每次执行前先判断是否重复,如果未重复才执行。
就比如当前项目中的幂等性处理:库存在解锁时先判断工作单状态(解锁会伴随着工作单的修改,改成已解锁状态),是未解锁状态才会进行解锁。并且将解锁整个修改的操作设为一个大事务。避免只执行了部分操作就发生异常。
除此之外,还可以判断当前是否是第一次接收此消息来进行判断。判断方式可以从记录消息队列的表中查询;或者直接使用 message.getMessageProperties().getRedelivered(); 返回的 Boolean ,其就是反应此次消息是否是非第一次传来的。
消息积压
场景:客户端宕机、并发量太大
解决:
1、限制消息发送,将额外的消息拒收,提示稍后重试
2、添加更多的消费者。
3、将多余的消息记录先存储到数据库,然后慢慢来处理
延时队列
延时队列适用于一些需要定时自动执行的操作。比如当前项目中的库存解锁,就是用于订单超时自动取消带来的解锁库存操作。
实现方式
方式1、为消息设置TTL,弊端,因为是先进先出,所以必须等待先进的消息过期才能拿到里面的消息,即使后进的先过期也不行。所以效率不高
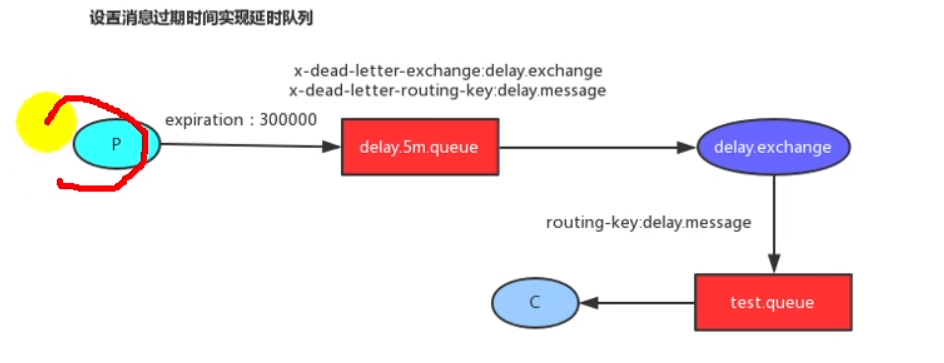
方式2、为队列设置过期,等到消息进入后到达时间后直接被死信队列获取到。这也是当前项目使用的。

延时队列的定义:
/** * 延迟队列(死信队列) */ @Bean public Queue orderDelayQueue() { /* Queue(String name, 队列名字 boolean durable, 是否持久化 boolean exclusive, 是否排他 boolean autoDelete, 是否自动删除 Map<String, Object> arguments) 属性【TTL、死信路由、死信路由键】 */ HashMap<String, Object> arguments = new HashMap<>(); arguments.put("x-dead-letter-exchange", "order-event-exchange");// 死信路由 arguments.put("x-dead-letter-routing-key", "order.release.order");// 死信路由键 arguments.put("x-message-ttl", 60000); // 消息过期时间 1分钟 Queue queue = new Queue("order.delay.queue", true, false, false, arguments); return queue; } /** * 交换机与延迟队列的绑定 */ @Bean public Binding orderCreateBinding() { /* * String destination, 目的地(队列名或者交换机名字) * DestinationType destinationType, 目的地类型(Queue、Exhcange) * String exchange, * String routingKey, * Map<String, Object> arguments * */ return new Binding("order.delay.queue", Binding.DestinationType.QUEUE, "order-event-exchange", "order.create.order", null); }
其他操作都与普通的消息发送一致
分布式事务
分布式事务是指一个业务涉及到多个服务的操作,那么普通的本地事务是无法约束远程的方法,也就导致了本地的方法或远程的方法某一个发生了异常,整个操作不能全部回滚的问题。
2PC模式(刚性事务)
如果需要强一致性,也就是修改的数据必须保证实时性。最简单的解决方式就是利用 MySQL 的2PC模式(也叫XA模式),其原理是在第一阶段将远程调用的方法事务不进行提交,继续向下执行。等到所有的操作都执行完毕,进入第二阶段,提交之前所有的事务。这种方式的优点就是配置简单,缺点就是效率低。因为在处于就绪状态涉及到的数据表,因为事务还未提交,所以占用着这些数据的锁,同时还可能会涉及到表锁、间隙锁等问题,造成其他数据也不能使用,这样其他相关的操作就会阻塞,所以在高并发下效率很低。
Seata
seata 就是 2PC模式的改进版。改良的地方主要是在第一阶段直接提交事务,并且记录操作,在发生异常后按照记录的日志进行逆操作回滚数据。
而seata主要分为三种模式:
AT模式:将分支事务执行过程分为了两个阶段。
第一阶段是分支事务提交,并将回滚日志记录在回滚表中。
二阶段是主业务的提交带动分支事务的提交,随后删除日志表中对应的回滚记录。或者是发生异常导致主事务回滚,带动分支事务进行回滚。
TCC模式:与AT模式不同之处就是将第一阶段的提交执行逻辑与第二阶段回滚(回滚数据库处理)、提交全部自定义
Saga模式:适用于长事务,分支事务异步执行,可以由多个参与者参与,编写分支事务以及补偿服务(回滚操作),第一阶段不会加锁,执行效率高
配置


//1.2.0 Seata + 1.2.1 Nacos 配置 1、添加依赖 <!--分布式事务解决--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> <exclusions> <exclusion> <groupId>io.seata</groupId> <artifactId>seata-all</artifactId> </exclusion> <exclusion> <groupId>io.seata</groupId> <artifactId>seata-spring-boot-starter</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>io.seata</groupId> <artifactId>seata-spring-boot-starter</artifactId> <version>1.2.0</version> </dependency> 2、添加数据库seata,然后加表,将相关数据保存在db中 drop table if exists `global_table`; create table `global_table` ( `xid` varchar(128) not null, `transaction_id` bigint, `status` tinyint not null, `application_id` varchar(32), `transaction_service_group` varchar(32), `transaction_name` varchar(128), `timeout` int, `begin_time` bigint, `application_data` varchar(2000), `gmt_create` datetime, `gmt_modified` datetime, primary key (`xid`), key `idx_gmt_modified_status` (`gmt_modified`, `status`), key `idx_transaction_id` (`transaction_id`) ); -- the table to store BranchSession data drop table if exists `branch_table`; create table `branch_table` ( `branch_id` bigint not null, `xid` varchar(128) not null, `transaction_id` bigint , `resource_group_id` varchar(32), `resource_id` varchar(256) , `lock_key` varchar(128) , `branch_type` varchar(8) , `status` tinyint, `client_id` varchar(64), `application_data` varchar(2000), `gmt_create` datetime, `gmt_modified` datetime, primary key (`branch_id`), key `idx_xid` (`xid`) ); -- the table to store lock data drop table if exists `lock_table`; create table `lock_table` ( `row_key` varchar(128) not null, `xid` varchar(96), `transaction_id` long , `branch_id` long, `resource_id` varchar(256) , `table_name` varchar(32) , `pk` varchar(36) , `gmt_create` datetime , `gmt_modified` datetime, primary key(`row_key`) ); 3、在执行需要执行分布式事务的库中添加 undo_log表 drop table `undo_log`; CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) NOT NULL, `context` varchar(128) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; 4、 修改conf/file.conf 和 file.conf.example 文件,将 store的mode改为db,并且设置数据库的库名、地址、密码;修改 registry.conf,将 registry的type 改成 nacos,serverAddr改成 localhost:8848 5、 配置文件添加seata的配置 seata: application-id: ${spring.application.name} tx-service-group: default service: vgroupMapping: default: default grouplist: default: 127.0.0.1:8091 6、在主业务方法上添加@GlobalTransactional注解,在调用的分布式事务上添加@Transactional 注解
缺点:说到底还是2PC模式的改良版,在高并发场景效率还是不够高。但是适用于数据一致性要求高的场景。
最终一致性(柔性事务)
在数据一致性要求不高的场景,可以使用最终一致性来解决,也就是在短时间可能造成数据不一致的情况,但是随着时间推移,数据最终会一致。
当前项目中使用的就是这个。具体实现就是在订单业务中,调用了远程锁库存方法,这样如果只使用本地事务,那么发生异常会有两种情况。
1、远程锁库存执行时发生异常,但是由于事务回滚,而主业务在收到结果后也回滚,无损失。
2、远程锁库存正常执行完毕,但是主业务随后的某个位置发生异常,那么已执行过的锁库存就无法回滚了。
针对于第二种,在锁库存后发送一个消息给延时队列,保证消息到达消费者时锁库存一定是已经完成了,接下来判断当前订单状态是否是取消(订单已经完成而解锁了库存)并且库存工作单是否已解锁(防止订单取消时已经解锁了造成重复解锁)。这样就可以保证库存数据最终一致性了。
支付
加密算法
对称加密:发送方和接收方解密和加密使用的四把钥匙是同一种钥匙,安全系数低,接收方和发送方破解了一个钥匙,就可以进行自由的接收和发送,实现完整地通信。
非对称加密:发送方和接收方加密和解密使用的钥匙都不一样,即使破解了一个,也无法实现自由通信。支付宝使用的就是非对称加密。
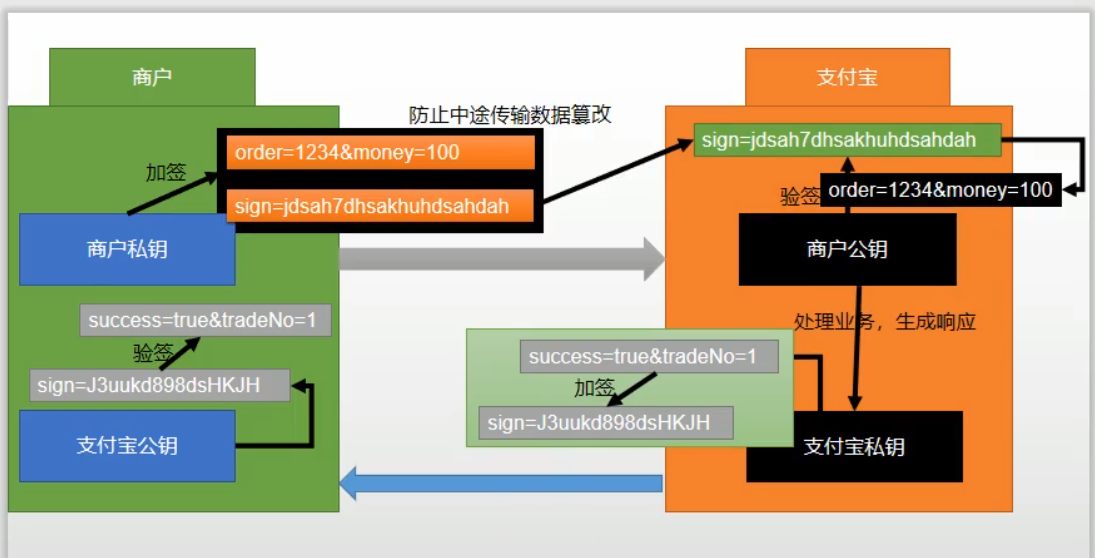
1、支付宝在和商户进行通信时,发送的每条请求都会现有发送方使用私匙,私匙是本地隐藏的,不对外公开,公钥是约定好解析的钥匙,也就是公开的钥匙。
2、支付宝和商户在发送请求时除了要操作的数据外,还会携带一个密匙,接收时就会先判断密匙是否对的上,如果对不上就不处理。
收单
因为订单消息会发送一个定时的订单取消消息,所以如果在支付界面等到订单取消执行后再支付,那么由于订单已取消且库存已解锁,即使通过可以修改订单状态,但是库存可能会被其他用户所抢占完,那么这个订单就会发生异常。所以解决方案就是在订单取消后立刻调用支付宝的收单方法,并且限制单次订单的最大时间,超时后也会自动收单。
1、设置单从订单的自动收单时间

2、主动关闭订单
定时任务
Cron表达式
语法:秒 分 时 日 月 周 年 (spring 不支持年,所以可以不写)
特殊字符:
,:枚举;
(cron="7,9,23****?"):任意时刻的7,9,23秒启动这个任务;
-:范围:
(cron="7-20****?""):任意时刻的7-20秒之间,每秒启动一次
*:任意;
指定位置的任意时刻都可以
/:步长;
(cron="7/5****?"):第7秒启动,每5秒一次;
(cron="*/5****?"):任意秒启动,每5秒一次;
? :(出现在日和周几的位置):为了防止日和周冲突,在周和日上如果要写通配符使用?
(cron="***1*?"):每月的1号,而且必须是周二然后启动这个任务;
L:(出现在日和周的位置)”,
last:最后一个
(cron="***?*3L"):每月的最后一个周二
W:Work Day:工作日
(cron="***W*?"):每个月的工作日触发
(cron="***LW*?"):每个月的最后一个工作日触发
#:第几个
(cron="***?*5#2"):每个月的 第2个周4
使用
1、@EnableScheduling 开启定时任务
2、@Scheduled开启一个定时任务
3、自动配置类TaskSchedulingAutoConfiguration

Spring 中的特点
1)spring周一都周天就是1-7
2)没有年,只有6个参数
3)默认是阻塞的,也就是在执行过程中如果发生阻塞,定时任务也被阻塞,比如

虽然是周五每秒钟执行一次,但是却需要等待上一个方法执行完才能执行下一个定时任务。
阻塞解决
1、 将业务使用异步线程池进行处理
CompletableFuture.runAsync(() -> {
},execute);
2、 SpringBoot内部支持了定时任务的线程池,可以让每个任务各分配一个线程执行。配置文件:TaskSchedulingProperties。
配置:spring.task.scheduling.pool.size: 5
但是由于版本bug,有的版本可以实现,有的版本还是会阻塞
3、引入异步任务。
异步任务
配置
1、@EnableAsync:开启异步任务
2、@Async:给希望异步执行的方法标注
3、自动配置类TaskExecutionAutoConfiguration

异步线程本身也是维护了一个线程池来实现的。
线程池的配置:
![]()
Sentinel 熔断降级限流
使用配置

spring.cloud.sentinel.transport.dashboard=localhost:8333
spring.cloud.sentinel.transport.port=8719
实时监控、界面可视化
1、引入依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> <version>2.2.6.RELEASE</version> </dependency>
2、添加暴露路径配置
management.endpoints.web.exposure.include=*
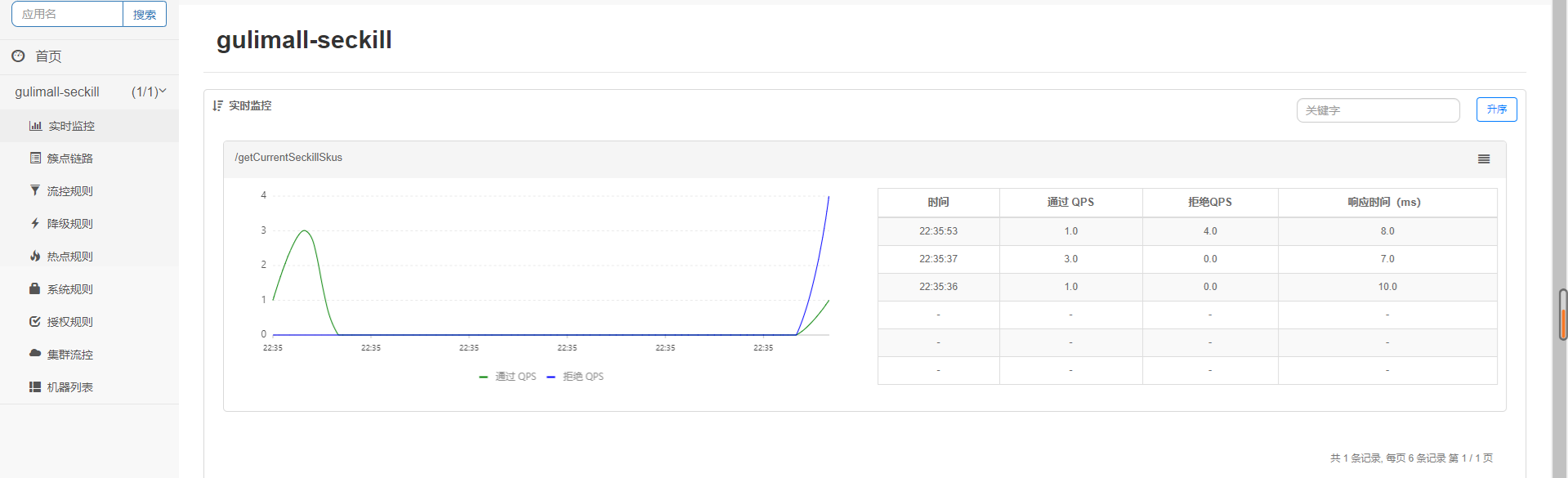
流控
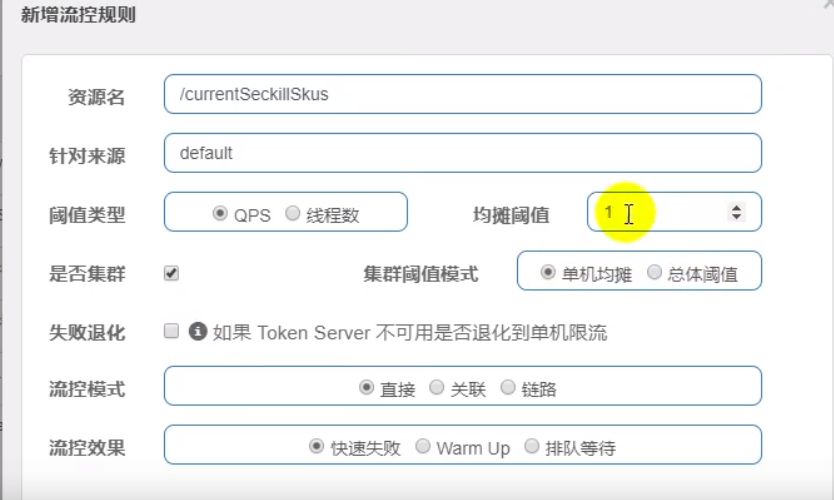
QPS:单秒访问数
单机均值:限制单台机器同时的访问量
总体阀值:限制所有机器同时的访问量
流控模式:直接:限制的是当前接口
链路:限制的是通过远程调用链式调用当前请求的请求,可以指定特定调用当前请求的URL
关联:限制关联的资源,如数据库数据,另一个服务用到这个请求所涉及的数据,那么也会被限制
限制效果:直接拒绝:顾名思义
Warm up:在预热时间慢慢执行
排队等待:进入队列,排队执行
流控搭配的是限流信息,当流控达到设置的阀值时,后面的请求就会执行前面的限流提示方法,如果没有设置自定义限流方法,那么就显示默认的提示信息

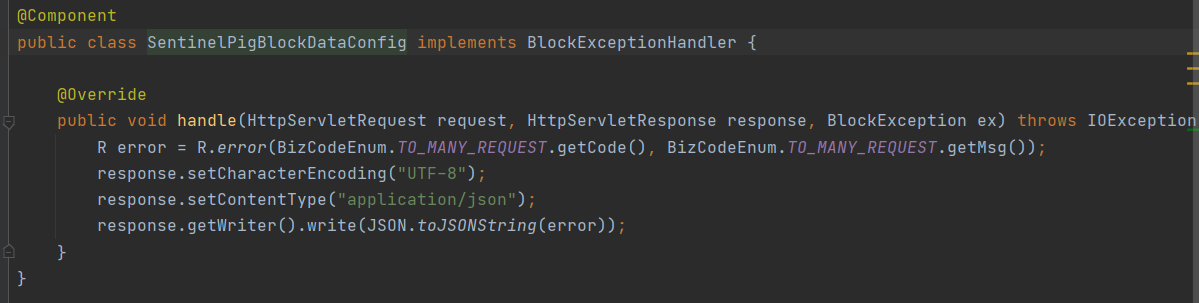
自定义默认的限流提示信息(对整个请求进行限流)
@Component public class SentinelPigBlockDataConfig implements BlockExceptionHandler { @Override public void handle(HttpServletRequest request, HttpServletResponse response, BlockException ex) throws IOException { R error = R.error(BizCodeEnum.TO_MANY_REQUEST.getCode(), BizCodeEnum.TO_MANY_REQUEST.getMsg()); response.setCharacterEncoding("UTF-8"); response.setContentType("application/json"); response.getWriter().write(JSON.toJSONString(error)); } }
效果:
自定义限制流量的资源
代码块
1、使用try catch包围要限制的代码块
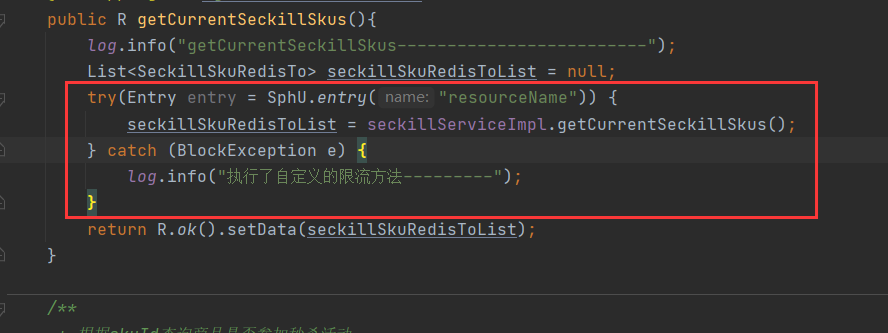
2、对请求下的资源进行限流

使用这个方式(包括下面的限流整个方法方式)不会触发上面设置的自定义限流方法,而是执行catch(BlockException e)里的操作,然后继续向后执行
方法
1、 在限制的方法上添加@SentinelResource 注解,并指定资源名
@SentinelResource(value = "resourceName1")
这样再配置资源的限流,在超过时就会抛出异常
2、 可以添加阻塞方法

这样在超过限流后就会执行这个方法,作为原本方法执行的替代。需要注意的是处理方法的返回值以及可见性要和限流方法一致,同时需要添加BlockException的异常参数。
除了BlockHanlder 还可以指定 fallback 函数,fallback 指定的函数是在所有异常触发时都会执行,而 BlockHanlder 是限流方法触发,如果fallback函数在其他类,需要再额外指定 fallbackClass 参数,表示该方法在哪个类中,方法也必须是static
网关限流
可以将请求直接在网关层进行限流处理,进一步减小各个服务的压力
在网关服务里添加依赖
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-sentinel-gateway</artifactId> </dependency>
配置

API名称:就是配置的网关ID
间隔:设置统计间隔(如2s就是每2s统计一次,那么第一秒统计完第二秒就不统计了到第三秒再统计)
Burst size:在达到阀值后额外再允许的请求数
同时也可以勾选针对请求属性来对携带特定属性的请求进行处理,并且可以添加API分组来一次性设置多个API
限流提示
默认的提示
自定义提示信息和调用方法
方法一(优先级更高):添加配置


方法二:添加组件(和上面普通模块自定义一样)
降级

降级策略
RT:在一秒内,如果有五个请求执行的时间超过了设置RT时间后(单位毫秒),那么在后面的时间窗口内的时间会对进来的请求直接进行处理(如果是普通方法那么就走限流逻辑,如果是feign远程方法就走Feign熔断逻辑)。超过窗口时间后会重新计算。
Feign熔断
配置
1、添加配置,打开feign的sentinel配置
feign.sentinel.enable=true
2、添加feign的熔断回调方法(在服务宕机时调用)


随后配合前面的降级配置,在2秒中有五次响应时间超过大于规定的时间,后面的请求就会直接执行这个熔断回调方法(如果没有配置熔断回调方法就直接返回错误)。
注:设置降级的操作必须在调用的模块中对feign调用方法资源进行配置,不能在被调用模块资源里设置
总结
1、降级针对于所有资源;熔断只针对于不同模块间的远程调用。
2、降级是一种对系统整体上的各个资源的主动控制;而熔断是针对于具体的某个远程调用接口,往往是被动触发。
3、熔断本质上是属于降级的一种策略。远程资源如果达到了降级规定的条件那么就会被动触发熔断。
Sleuth 链路追踪
基础配置
引入依赖

配置打印

Zipkin可视化配置
1、安装服务器:docker run -d -p 9411:9411 openzipkin/zipkin
2、添加依赖:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
(内部引入了Sleuth的基础依赖)
3、 添加配置
#链路调用可视化配置
#服务追踪
spring.zipkin.base-url=http://192.168.77.130:9411/
#关闭服务发现
spring.zipkin.discovery-client-enabled=false
spring.zipkin.sender.type=web
#配置采样器
spring.sleuth.sampler.probability=1
4、 在主类上移除TraceRedisAutoConfiguration类(视频里不需要移除,测试版本需要)

5、到此为止,如果某个服务中引入了seata,也就是spring-cloud-starter-alibaba-seata,因为其内部通过SeataFeignClientAutoConfiguration集成了feign,所以在使用feign远程调用时就会冲突导致连接不上,发生错误。
此时可以使用spring.sleuth.feign.enabled=false ,或在主类上移除SeataFeignClientAutoConfiguration来关闭,但是在使用Zipkin查看链路时不能查看到调用情况。所以还需要添加配置类
/** * @Author Rookie-6688 * @Description 解决整合调用链zipkin时在移除 SeataFeignClientAutoConfiguration 后不能查看调用链的问题 * @Create 2021-05-19 23:25 */ @Component @ConditionalOnClass({RequestInterceptor.class, GlobalTransactional.class}) public class SetSeataInterceptor implements RequestInterceptor { @Override public void apply(RequestTemplate template) { String currentXid = RootContext.getXID(); if (!StringUtils.isEmpty(currentXid)) { template.header(RootContext.KEY_XID, currentXid); } } }
来将主业务的全局事务的XID,透传到全局事务的各个子服务(feign远程调用的各个事务)中。
链路数据持久化
将链路数据保存到Mysql、ES中

其他
手动发送Post请求
HttpResponse httpResponse = HttpUtils.doPost("https://api.weibo.com", "/oauth2/access_token", "post", new HashMap<>(), map, new HashMap<>());
Model、RedirectAttributes 传值
1、redirectAttributes 存储的数据可以在重定向后的页面使用。Model存储的数据只能用于请求转发
2、redirectAttributes.addFlashAttribute("errors",errorMap); // 原理是将数据保存在cookie里重定向
3、model.addAttribute、redirectAttributes.addAttribute发出的请求会将数据放在URL的?后面,可以直接通过@RequestParam 获取(重定向,请求转发)。
将return 的数据作为Html数据展示
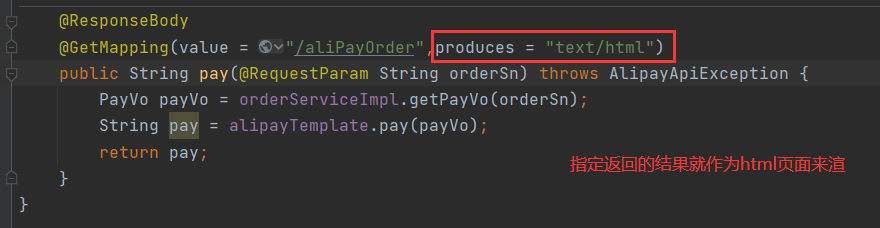
pay:
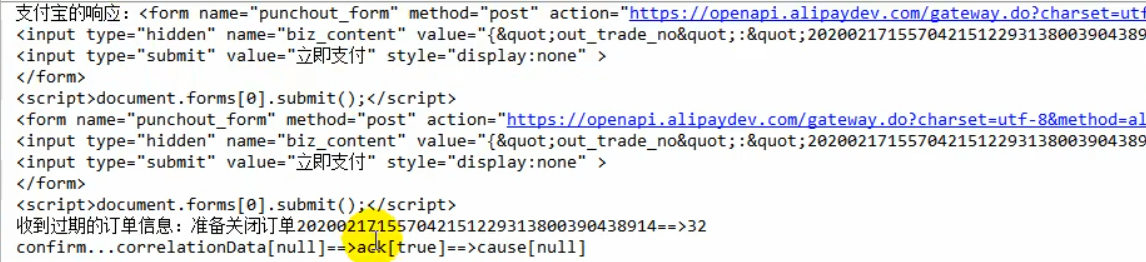
项目注意
1、 单一模块:因为秒杀往往伴随着高并发,所以应该涉及为一个单独的模块,这样即使流量过大导致服务器瘫痪也只不会影响其他模块。同时秒杀的商品消息,库存都已经存储在redis,避免高并发访问数据库
2、 链接加密:对秒杀请求的链接加密,防止恶意攻击(项目使用了秒杀随机码)
3、 库存预热:避免进行数据库操作,防止数据库崩溃,使用redis的信号量替代库存
4、 动静分离:静态资源不需要访问后台服务器,减少服务器压力
5、 恶意请求拦截:对于某个ip同时发送的上千次请求直接进行拦截,不进行处理
6、 流量错峰:将流量分担到更大的时间段上,比如增加验证码验证
7、 限流、熔断、降级:限流。前端点击一次抢购后需要等待几秒才能点第二次,后端在并发量达到一定次数后对一定比率的请求进行处理。熔断。某一部分发生异常后不再继续执行,直接返回失败消息如远程调用,如果一秒内有多个请求都请求超时,那么随后的请求执行到这就直接返回错误消息,不再执行远程调用(是一种主动的方式)。降级。将一部分请求降级,等待一段时间后才去处理(或者直接返回异常)
8、 队伍削峰。将一些不需要强一致性的数据操作放入队列中处理。如商品库存的扣减,先通过信号量来扣除,然后又队列慢慢去数据库修改库存
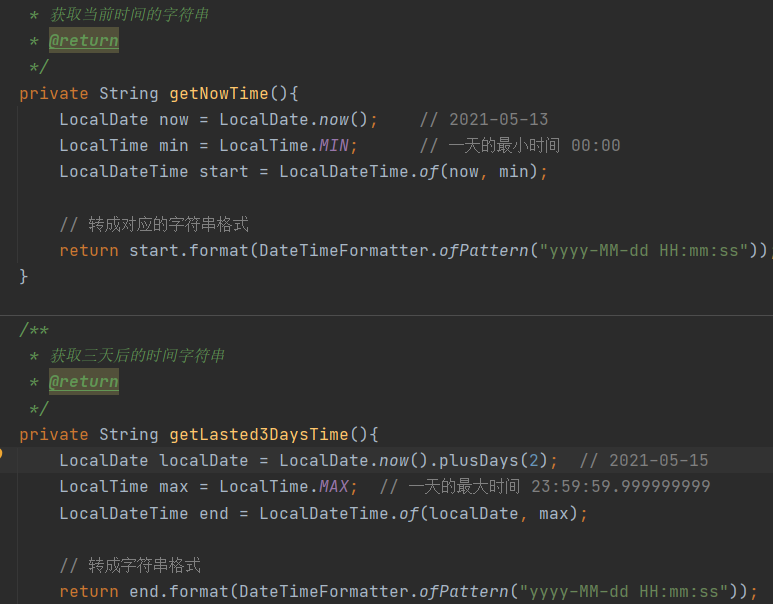
LocalDate 使用
UUID与雪花算法生成ID、自增ID
UUID:优点:1、简单,生成性能快,2、唯一。数据库合表可以不需要担心主键冲突问题
缺点:没有顺序,数据库新增、查询、遍历效率低
雪花算法:优点:1、生成效率高。2、同时根据时间生成ID,所以是递增,查询、插入、遍历效率也高3、同时是唯一,在合表也不需要担心主键冲突
缺点:因为是通过时间来生成的,当时间回溯时,可能会生成同一个主键
自增ID:优点:简单
缺点:1、当生成的并发量大时,对数据库压力会变高 2、在合表时会比较麻烦 3、强依赖数据库,当数据库宕机后就无法实现
启动Jar 包
java -jar jar包名 --server.port=端口号
数据库性能
1、多张表查询时尽量不要使用 in ,效率很低。
2、大表之间,如果查询的条件列有索引,那么没必要进行联表查询,因为连接查询会进行笛卡尔积次数的遍历,效率反而没有单表多次查询效率高(前提是大表,且有索引)。
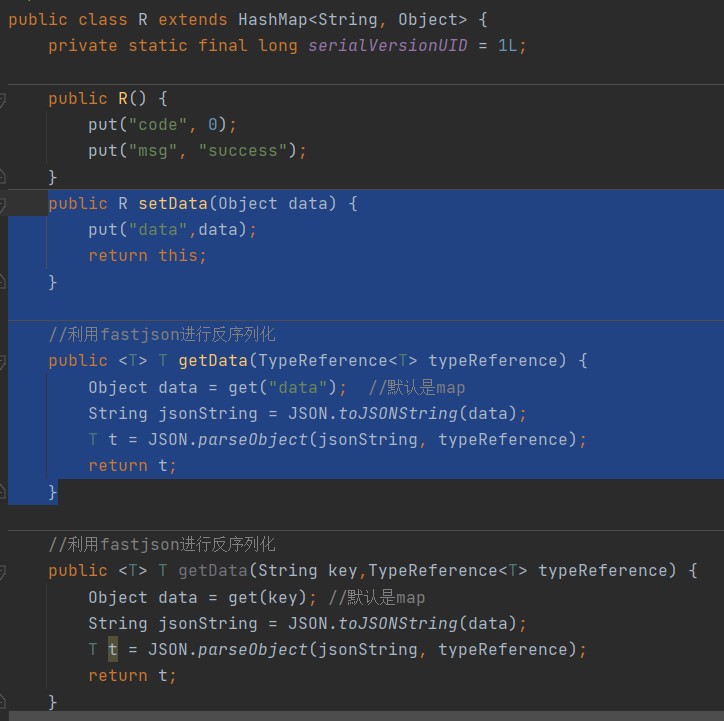
远程调用转成想要的类型
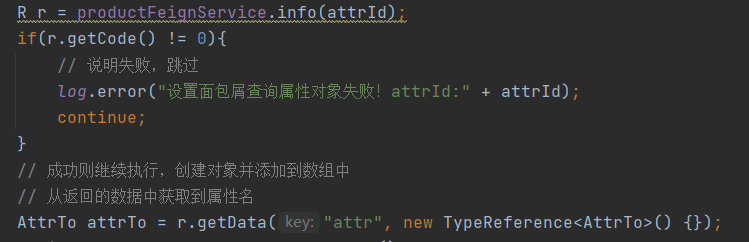
1、在使用feign返回的Result数据里获取传过来的数据时,不要强转(目前已知Map<Long,Integer>在强转时会将Long转成String类型),正确做法应该使用阿里的TypeReference:

如果存储的是自定义类对象

 浙公网安备 33010602011771号
浙公网安备 33010602011771号