机器学习实战阅读笔记(一)-机器学习基本概念
机器学习基本概念
什么是机器学习?
简单地说,机器学习就是把无序的数据转换成有用的信息。
属性
比如对鸟进行分类的例子:

比如体重、翼展、有无脚蹼、后背颜色这几个特征可以称作属性,或者将其称为特征。
训练集
算法输入大量已分类数据作为算法的训练集。表1-1是包含六个训练样本的训练集,每个训练样本有4种特征、一个目标变量
目标变量
目标变量是机器学习算法的预测结果,比如鸟类的种属
- 分类算法中目标变量是标称型
- 回归算法中目标变量是连续型
通常将分类问题中的目标变量称为类别,并假定分类问题只存在有限个数的类别。
测试机器学习的效果
为了测试机器学习算法的效果,通常使用两套独立的样本集:
- 训练数据:当机器学习程序开始运行时,使用训练样本集作为算法的输人
- 测试数据:训练完成之后输人测试样本。输人测试样本时并不提供测试样本的目标变量,由程序决定样本属于哪个类别,比较测试样本预测的目标变量值与实际样本类别之间的差别,就可以得出算法的实际精确度。
知识表示
假定这个鸟类分类程序,经过测试满足精确度要求,是否我们就可以看到机器已经学会了如
何区分不同的鸟类了呢?这部分工作称之为知识表示。
机器学习的主要任务
监督学习
监督学习这类算法必须知道预测什么,即目标变量的分类信息。
监督学习要解决两类问题:分类问题和回归问题
分类问题
将实例数据划分到合适的分类中。
回归问题
回归主要用于预测数值型数据。例子:数据拟合 曲线:通过给定数据点的最优拟合曲线。
无监督学习
聚类
在无监督学习中,将数据集合分成由类似的对象组成的多个类的过程被称为聚类
密度估计
将寻找描述数据统计值的过程称之为密度估计。
机器学习算法的分类

如何选择机器学习算法
根据使用机器学习算法的目的

根据需要收集的数据是什么
了解数据的特性
- 特征值是离散型变量还是连续型变量
- 特征值中是否存在缺失的值
- 何种原因造成缺失值
- 数据中是否存在异常值,某个特征发生的频率如何(是否罕见得如同海底捞针),等等
开发机器学习应用程序的步骤
- 收集数据。
- 准备输入数据。
- 分析输入数据。
- 训练算法。
- 测试算法。
- 使用算法
NumPy函数库基础
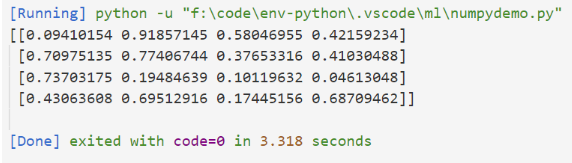
构造了--个4x4的随机数组
import numpy as np
print(np.random.rand(4,4))
NumPy矩阵与数组的区别
NumPy函数库中存在两种不同的数据类型(矩阵matrix和数组array),都可以用于处理行列表示的数字元素。虽然它们看起来很相似,但是在这两个数据类型上执行相同的数学运算可能得到不同的结果,其中NumPy函数库中的matrix与MATLAB中matrices等价。
数组转化为矩阵
调用mat ()函数可以将数组转化为矩阵
>>> import numpy as np
>>> randMat=np.mat(np.random.rand(4,4))
>>> randMat
matrix([[0.60516618, 0.13009869, 0.29892108, 0.35267224],
[0.78700705, 0.30897911, 0.12496339, 0.35604417],
[0.64707587, 0.47488661, 0.80680566, 0.8548645 ],
[0.58508329, 0.62227194, 0.01619913, 0.90581603]])
求逆运算
>>> randMat.I
matrix([[ 1.22804612, 1.06788238, -0.61399795, -0.31841567],
[-8.20682473, 5.17502764, 2.25856527, -0.97038071],
[-1.3124819 , 0.60673258, 1.6576945 , -1.29193104],
[ 4.86812821, -4.25572419, -1.18462803, 1.99937788]])
矩阵与矩阵的逆相乘
结果应该是单位矩阵,除了对角线元素是1, 4 x 4矩阵的其他元素应该全是0。实际输出结果略有不同,矩阵里还留下了许多非常小的元素,这是计算机处理误差产生的结果。输人下述命令,得到误差值:
>>> invMat=randMat.I
>>> invMat*randMat
matrix([[ 1.00000000e+00, -1.66533454e-16, -1.07552856e-16,
-2.77555756e-16],
[ 1.33226763e-15, 1.00000000e+00, 2.18575158e-16,
4.44089210e-16],
[-1.11022302e-16, 0.00000000e+00, 1.00000000e+00,
2.22044605e-16],
[-2.22044605e-16, 0.00000000e+00, 3.46944695e-17,
1.00000000e+00]])
>>> np.eye(4,4)-invMat*randMat
matrix([[ 4.44089210e-16, 1.66533454e-16, 1.07552856e-16,
2.77555756e-16],
[-1.33226763e-15, -2.22044605e-16, -2.18575158e-16,
-4.44089210e-16],
[ 1.11022302e-16, 0.00000000e+00, 0.00000000e+00,
-2.22044605e-16],
[ 2.22044605e-16, 0.00000000e+00, -3.46944695e-17,
0.00000000e+00]])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号