

selective search
1.引言:图像的物体识别主要有两个步骤:定位、分类。在分类的过程中,需要对图像中文物体的区域划分出来。传统的方法是利用滑窗,一个窗口一个窗口得选择,将之与目标进行比较,确定物体的位置。
为了降低搜索空间,J.R.R. Uijlings发表在2012 IJCV上的一篇文章中介绍的选择性搜索综合了蛮力搜索和分割策咯,为识别算法中的定位提供了新的解决方法。
-------------------------------------------------------------------------------------------------------------------------------------
2.内容:
(1)初始化一些小的分割区域(基于图G(V,E)的基本表示和相关知识):
几个定义:
##分割区域的内部差in_diff:假设图G简化成了最小生成树MST,则某个分割区域C中的点通过一棵最小生成树连接,那C中包含的最大边的权值就是内部差。(指某个区域的最大跨度)
![]()
#分割区域之间的差别diff:两个区域之间连接的最小边的权值,(离得最近的两个点之间的距离)

#分割区域边界的判断标准:两个区域之间是否有明显的边界,即判断两个区域之间的diff与两个区域里边较小的那个最小内部差MInt的大小;若diff>MInt,则两个区域之间有边界;反之没有。
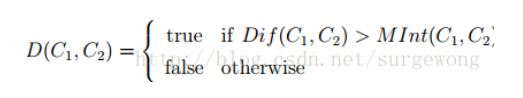

其中MInt的表示引入了一个阈值,目的是为了凸显分割区域大小对边界的影响,面积小的区域边界要比面积大的区域更强。
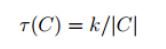
#分割太精细(too fine):一个分割产生的两个区域之间没有明显的边界。分割的太过头了
#分割太粗糙(too coarse):一个分割S,可以通过调整使得它不是太精细,它就是太粗糙。分割的还不够
算法实现过程:
#将图G中所有的边按照权值递增的顺序排序;
#原始分割S[0],每一个顶点是一个区域;
#根据上次S[q-1]的构建
。选择一条边
o[q](vi,vj),如果
vi和
vj在分割
的互不相交的区域中,比较这条边的权值与这两个分割区域之间的MInt,如果o[q](vi,vj) < MInt,那么合并这两个区域,其他区域不变;如果否,什么都不做;
#重复上一步,直到将所有的边都处理完。
第一步的结果是初始化的一个区域序列R{r1,r2,r3...rn},
-------------------------------------------------------------------------------------------------------------------------------------------------------------
(2)计算每个区域的相似性
其中区域相似性的计算,论文中用到下边的公式:

下边分别对各个部分进行介绍
有如下几个策略:
#Scolor(ri,rj):
每个区域,可以得到一个一维的颜色分布直方图。直方图一共有25个区间,如果有3个颜色通道,则n=75,区域i的颜色分布直方图为
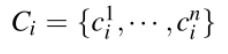
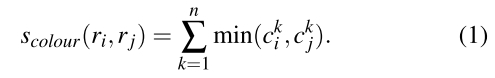
当i和j合并成t,区域t的颜色分布直方图可以用下面式子进行计算:
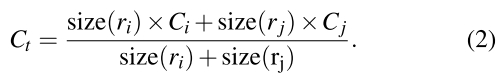
t 的size用下面式子计算:
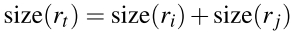
#Stexture(ri,rj)(用到SIFT)
SIFT介绍见:http://www.cnblogs.com/saintbird/archive/2008/08/20/1271943.html
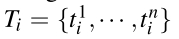
如果有3个颜色通道,n=240=8*3*10,同理得到区域i的纹理直方图要用L1norm归一化。
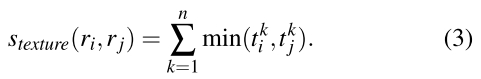
同理,纹理的传递性也可以用(2)式解决。
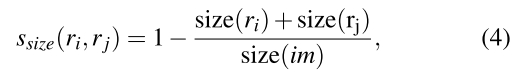
size(im)表示整个图片的像素数目。
Sfill (ri,rj)鼓励有相交或者有包含关系的区域先合并。
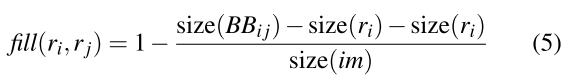
BBij指包含i,j区域的最小外包区域
---------------------------------------------------------------------------------------------------------------------------------
(3)进一步划分区域
-----------------------------------------------------
#找出相似性最大的区域max(S)={ri,rj};
#合并rt=ri∪rj,只在S集合中保留rt,移走ri,rj;
#计算新集合rt与所有与它相邻区域的相似性s(rt,r*);
#S=S∪St R=R∪rt;
#直到S集合为空,重复上述步骤。
-----------------------------------------------------
参考:https://blog.csdn.net/charwing/article/details/27180421

