
OpenCL中的子缓冲区例子
子缓冲区可以把一组数据拆分成多个部分,然后每个部分送到不同的设备上运行。这里将给出一个例子,代码的运行环境是VS2015、OpenCL3,显卡是AMD A4处理器的核芯显卡和另一个AMD的入门级独立显卡。CPP文件如下:
string kernelStr = u8R"( kernel void add(global const int* input, global int* output, int type) { int id = get_global_id(0); if (type == 0) output[id] = input[id] + 12; else output[id] = input[id] + 2; })"; int main() { cl::Platform platform = cl::Platform::getDefault(); vector<cl::Device> devices; platform.getDevices(CL_DEVICE_TYPE_ALL, &devices); for (auto& item : devices) { string name; item.getInfo(CL_DEVICE_NAME, &name); cout << name << endl; } cl::Context context(devices); cl::CommandQueue cmdQueueCpu(context, devices[0]); cl::CommandQueue cmdQueueGpu(context, devices[1]); cl::Program program(context, kernelStr); try { program.build("-cl-std=CL2.0"); } catch (...) { cl_int buildErr = CL_SUCCESS; auto buildInfo = program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(&buildErr); for (auto &pair : buildInfo) { std::cerr << pair.second << std::endl << std::endl; } return -1; } vector<int> a(128, 10); cl::Buffer inputa(context, a.begin(), a.end(), true, true); /* 注释1 */ cl::Buffer output1(context, CL_MEM_READ_WRITE, 64 * sizeof(int)); cl::Buffer output2(context, CL_MEM_READ_WRITE, 64 * sizeof(int)); cl_buffer_region region; region.origin = 0; region.size = 64 * sizeof(int); /* 字节为单位 */ cl::Buffer mycpu = inputa.createSubBuffer(CL_MEM_READ_ONLY, CL_BUFFER_CREATE_TYPE_REGION, ®ion); region.origin = 64 * sizeof(int); region.size = 64 * sizeof(int); cl::Buffer mygpu = inputa.createSubBuffer(CL_MEM_READ_ONLY, CL_BUFFER_CREATE_TYPE_REGION, ®ion); auto kernel = cl::KernelFunctor<cl::Buffer&, cl::Buffer&, int>(program, "add"); cl_int error = 0; cl::Event e1 = kernel(cl::EnqueueArgs(cmdQueueCpu, cl::NDRange(64)), mycpu, output1, 1, error); cl::Event e2 = kernel(cl::EnqueueArgs(cmdQueueGpu, cl::NDRange(64)), mygpu, output2, 0, error); vector<int> out1(64, -1), out2(64, -1); cl::copy(cmdQueueCpu, output1, out1.begin(), out1.end()); cl::copy(cmdQueueGpu, output2, out2.begin(), out2.end()); return 0; }
上述代码就是把变量a拆分成两个64个数字的子缓冲区,然后在两个设备上计算。输出的结果如下截图,可以看出out1全是12,out2全是22,结果正确。在编程的时候需要注意cl_buffer_region的成员origin不是任意值都行,它是有对齐限制的。比如,某些显卡要求子缓冲区必须128字节对齐,那么这个值就一定要是128的整数倍,可以是0,128,256……其它值会导致createSubBuffer(...)报错。

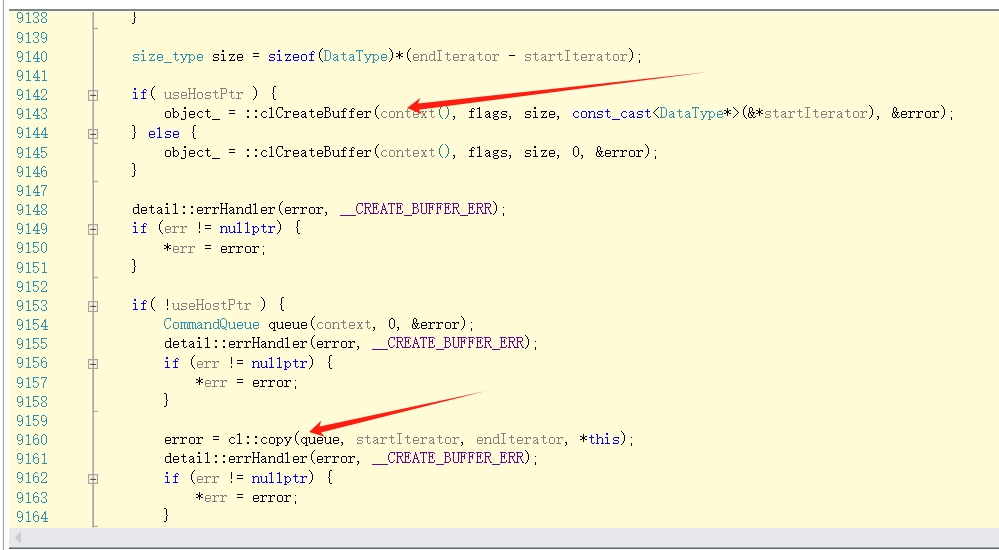
另外上述代码中的注释1处,最后一个参数useHostPtr必须用true,否则容易运行出错或内核执行错误。原因大概是(我的猜测)在创建子缓冲区时必须用数据初始化缓冲区(书上的例子是这样的,直接基于数据指针创建缓冲区对象),而不使用cl::copy(...)复制数据。在最后一个参数为false时,会导致创建缓冲区内部调用cl::copy(...)函数使用一个默认命令队列复制数据(见下图第二个红箭头)。OpenCL源代码截图如下:
也可仿照《OpenCL异构并行计算》书上的方式创建缓冲区inputa:
//... vector<int> a(128, 10); cl_mem memInput = clCreateBuffer(context(), CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, a.size() * sizeof(int), a.data(), 0); cl::Buffer inputa(memInput, false); //...
