Sobel算子的指令集加速例子
Sobel算子的卷积核如下。这里以x轴向右为正;y轴向下为正:
$${\mathbf{D_{x}}=\bigl(\begin{smallmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{smallmatrix}\bigr), \mathbf{D_{y}}=\bigl(\begin{smallmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{smallmatrix}\bigr),\mathbf{Z}=\sqrt{\left(Image\ast\mathbf{D_{x}}\right)^{2}+\left(Image\ast\mathbf{D_{y}}\right)^{2}}}$$
下面直接给出我做的指令集加速的代码,计算的是梯度强度图${\mathbf{Z}}$,数据类型是CV_16UC1,图片边缘是按照REFLECT101方式处理的。内部计算方法是边缘位置用普通C++代码处理,而中间的大片区域用SSE加速。代码基于VS2017、OpenCV430和Qt5.9。CPU型号是Intel Core i5-7400。经过对比在Release版程序中该方法比同功能的OpenCV代码快。当然不同的CPU对指令集的支持效率不同,而且在某些情况下OpenCV会使用多线程加速,所以有可能在别的电脑上OpenCV更快。这里的比较结果仅供参考。代码如下:
void lineF1L1(const Mat& image, Mat& output) { const int lastCol = image.cols - 1; const int lastRow = image.rows - 1; /* 第一行 */ const uchar* iptr1 = image.ptr<uchar>(0); const uchar* iptr2 = image.ptr<uchar>(1); ushort* optr = output.ptr<ushort>(0); optr[0] = 0; optr[lastCol] = 0; for (int i = 1; i < lastCol; i++) { optr[i] = abs((iptr1[i + 1] - iptr1[i - 1]) + (iptr2[i + 1] - iptr2[i - 1])) * 2; } /* 最后一行 */ iptr1 = image.ptr<uchar>(lastRow - 1); iptr2 = image.ptr<uchar>(lastRow); optr = output.ptr<ushort>(lastRow); optr[0] = 0; optr[lastCol] = 0; for (int i = 1; i < lastCol; i++) { optr[i] = abs((iptr1[i + 1] - iptr1[i - 1]) + (iptr2[i + 1] - iptr2[i - 1])) * 2; } } void sobel(const Mat& image, Mat& output) { output.create(image.size(), CV_16UC1); lineF1L1(image, output); const int lastRow = image.rows - 1; const int lastCol = image.cols - 1; const int max16 = std::max(0, image.cols / 16 * 16 - 8); __m128i shift08 = _mm_setr_epi8(1, 2, 3, 4, 5, 6, 7, 8, -1, -1, -1, -1, -1, -1, -1, -1); __m128i shift16 = _mm_setr_epi8(2, 3, 4, 5, 6, 7, 8, 9, -1, -1, -1, -1, -1, -1, -1, -1); __m128i picklo = _mm_setr_epi8(0, 1, 4, 5, 8, 9, 12, 13, -1, -1, -1, -1, -1, -1, -1, -1); __m128i pickhi = _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, 0, 1, 4, 5, 8, 9, 12, 13); __m128i extr47 = _mm_setr_epi8(8, 9, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1); for (int i = 1; i < lastRow; i++) { const uchar* iptr1 = image.ptr<uchar>(i - 1); const uchar* iptr2 = image.ptr<uchar>(i); const uchar* iptr3 = image.ptr<uchar>(i + 1); ushort* optr = output.ptr<ushort>(i); /* 第一列 */ optr[0] = abs((iptr3[0] - iptr1[0]) + (iptr3[1] - iptr1[1])) * 2; /* 第二列到max16+1 */ for (int j = 0; j < max16; j += 8) { __m128i pixels1 = _mm_loadu_si128((__m128i*)&iptr1[j]); __m128i pixels2 = _mm_loadu_si128((__m128i*)&iptr2[j]); __m128i pixels3 = _mm_loadu_si128((__m128i*)&iptr3[j]); __m128i i16rc11 = _mm_cvtepu8_epi16(pixels1); /* 第1行第1列像素 */ __m128i r1shift08 = _mm_shuffle_epi8(pixels1, shift08); __m128i i16rc12 = _mm_cvtepu8_epi16(r1shift08); /* 第1行第2列像素 */ __m128i r1shift16 = _mm_shuffle_epi8(pixels1, shift16); __m128i i16rc13 = _mm_cvtepu8_epi16(r1shift16); /* 第1行第3列像素 */ __m128i i16rc21 = _mm_cvtepu8_epi16(pixels2); /* 第2行第1列像素 */ __m128i r2shift16 = _mm_shuffle_epi8(pixels2, shift16); __m128i i16rc23 = _mm_cvtepu8_epi16(r2shift16); /* 第2行第3列像素 */ __m128i i16rc31 = _mm_cvtepu8_epi16(pixels3); /* 第3行第1列像素 */ __m128i r3shift08 = _mm_shuffle_epi8(pixels3, shift08); __m128i i16rc32 = _mm_cvtepu8_epi16(r3shift08); /* 第3行第2列像素 */ __m128i r3shift16 = _mm_shuffle_epi8(pixels3, shift16); __m128i i16rc33 = _mm_cvtepu8_epi16(r3shift16); /* 第3行第3列像素 */ __m128i haddy1 = _mm_add_epi16(_mm_add_epi16(i16rc11, i16rc13), _mm_add_epi16(i16rc12, i16rc12)); __m128i haddy3 = _mm_add_epi16(_mm_add_epi16(i16rc31, i16rc33), _mm_add_epi16(i16rc32, i16rc32)); __m128i haddy = _mm_sub_epi16(haddy3, haddy1); __m128i haddx1 = _mm_add_epi16(_mm_add_epi16(i16rc11, i16rc31), _mm_add_epi16(i16rc21, i16rc21)); __m128i haddx3 = _mm_add_epi16(_mm_add_epi16(i16rc13, i16rc33), _mm_add_epi16(i16rc23, i16rc23)); __m128i haddx = _mm_sub_epi16(haddx3, haddx1); __m128 dy1 = _mm_cvtepi32_ps(_mm_cvtepi16_epi32(haddy)); __m128 dx1 = _mm_cvtepi32_ps(_mm_cvtepi16_epi32(haddx)); __m128 apex1 = _mm_sqrt_ps(_mm_add_ps(_mm_mul_ps(dx1, dx1), _mm_mul_ps(dy1, dy1))); __m128i dz1 = _mm_cvtps_epi32(apex1); __m128i le = _mm_shuffle_epi8(dz1, picklo); /* 此处是i32到u16的强制转换,只取低地址2字节 */ __m128 dy2 = _mm_cvtepi32_ps(_mm_cvtepi16_epi32(_mm_shuffle_epi8(haddy, extr47))); __m128 dx2 = _mm_cvtepi32_ps(_mm_cvtepi16_epi32(_mm_shuffle_epi8(haddx, extr47))); __m128 apex2 = _mm_sqrt_ps(_mm_add_ps(_mm_mul_ps(dx2, dx2), _mm_mul_ps(dy2, dy2))); __m128i dz2 = _mm_cvtps_epi32(apex2); __m128i ri = _mm_shuffle_epi8(dz2, pickhi); /* 此处是i32到u16的强制转换,只取低地址2字节 */ __m128i result = _mm_blend_epi16(le, ri, 0b11110000); _mm_storeu_si128((__m128i*)&optr[j + 1], result); } /* max16+1到倒数第二列 */ for (int j = max16 + 1; j < lastCol; j++) { int dx = (iptr1[j + 1] - iptr1[j - 1]) + 2 * (iptr2[j + 1] - iptr2[j - 1]) + (iptr3[j + 1] - iptr3[j - 1]); int dy = (iptr3[j - 1] - iptr1[j - 1]) + 2 * (iptr3[j] - iptr1[j]) + (iptr3[j + 1] - iptr1[j + 1]); float dz = sqrtf(dx * dx + dy * dy); optr[j] = ushort(dz); } /* 最后一列 */ optr[lastCol] = abs((iptr3[lastCol - 1] - iptr1[lastCol - 1]) + (iptr3[lastCol] - iptr1[lastCol])) * 2; } } void main() { Mat image = imread(R"(2.bmp)", IMREAD_GRAYSCALE); resize(image, image, Size(960, 640)); int64 t1, t2; Mat result; t1 = getTickCount(); sobel(image, result); t2 = getTickCount(); qDebug() << u8"diy(ms):" << (t2 - t1) / getTickFrequency() * 1000; Mat dx, dy, grad; t1 = getTickCount(); spatialGradient(image, dx, dy); dx.convertTo(dx, CV_32FC1); dy.convertTo(dy, CV_32FC1); sqrt(dx.mul(dx) + dy.mul(dy), grad); t2 = getTickCount(); qDebug() << u8"cv(ms)" << (t2 - t1) / getTickFrequency() * 1000; double maxv1, maxv2; minMaxIdx(result, 0, &maxv1); minMaxIdx(grad, 0, &maxv2); qDebug() << "diy max:" << maxv1 << "cv max:" << maxv2; threshold(result, result, 100, 65535, THRESH_BINARY); threshold(grad, grad, 100, 65535, THRESH_BINARY); imshow("sobel diy", result); imshow("sobel cv", grad); int x = 0; }
下面是文本输出:
diy(ms): 0.7707 cv(ms) 9.0627 diy max: 600 cv max: 600
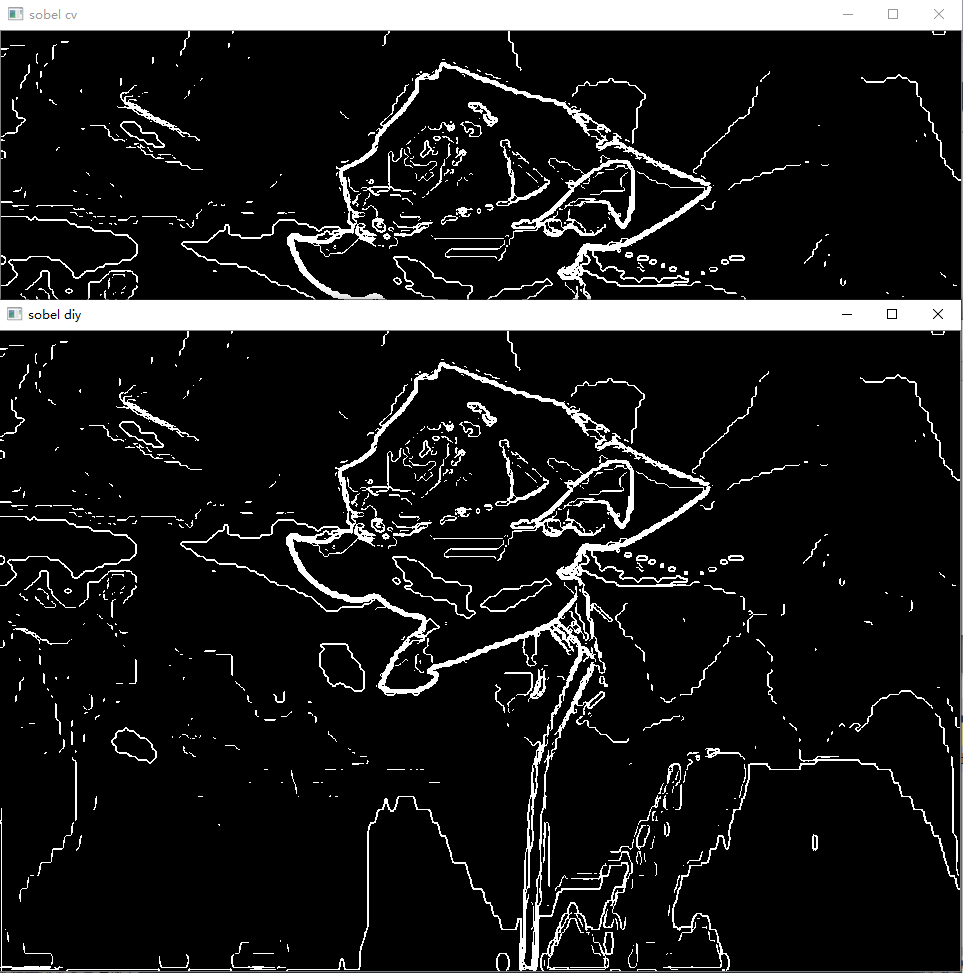
这里是输出结果图片,可以看出我的结果跟OpenCV相同: