
神经网络学习之----过拟合,以及 google神经网络小工具
拟合一般分为三个状态:欠拟合(Underfitting) 、正确拟合(Just right) 、过拟合(Overfitting)
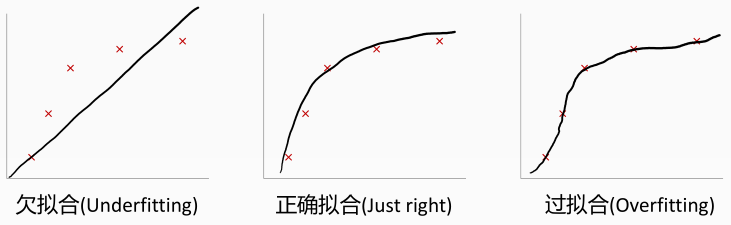
线性回归模型 拟合的函数和训练集的关系:
第一张图片拟合的函数和训练集误差较大,我们称这种情况为欠拟合(Underfitting)
第二张图片拟合的函数和训练集误差较小,我们称这种情况为正确拟合(Just right)
第三张图片拟合的函数完美的匹配训练集数据,我们称这种情况为过拟合(Overfitting)
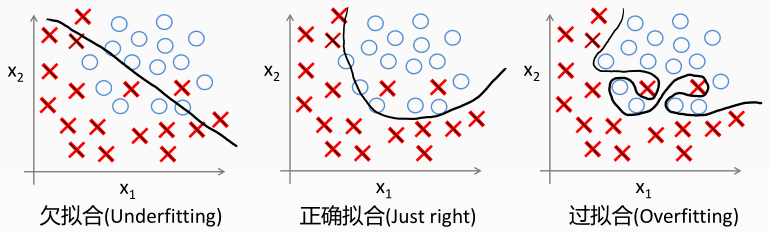
逻辑回归 同样也存在欠拟合和过拟合问题,如下图
那么,如何解决欠拟合和过拟合问题
欠拟合问题,根本的原因是特征维度过少,导致拟合的函数无法满足训练集,误差较大。
解决方案:
欠拟合问题可以通过增加特征维度来解决。
过拟合问题,根本的原因则是特征维度过多,导致拟合的函数完美的经过训练集,但是对新数据的预测结果则较差。
解决方案:
1. 增加数据集:拥有更多的数据量往往使模型训练的更好。
2. 正则化方法
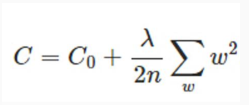
保留所有参数,但是减少每一个参数的值
当我们有很多特征而假设函数依然能够很好的工作,确保每一个特征对预测值都有所贡献。
可参考:https://blog.csdn.net/xiaoyi_eric/article/details/80909492
3. Dropout
可参考:https://blog.csdn.net/u013007900/article/details/78120669/
Google的神经网络小工具:http://playground.tensorflow.org/
可参考:https://www.jianshu.com/p/f191c7b453b9

