Attention is all you need及其在TTS中的应用Close to Human Quality TTS with Transformer和BERT
序列编码
深度学习做NLP的方法,基本都是先将句子分词,然后每个词转化为对应的的词向量序列,每个句子都对应的是一个矩阵\(X=(x_1,x_2,...,x_t)\),其中\(x_i\)都代表着第\(i\)个词向量,维度为d维,故\(x\in R^{n×d}\)
-
第一个基本的思路是RNN层,递归式进行:
\[y_t=f(y_{t-1},x_t) \]RNN结构本身比较简单,也适合序列建模,但RNN明显缺点之一在于无法并行,因而速度较慢,而且RNN无法很好学习到全局的结构信息,因为其本质是一个马尔科夫决策过程。
-
第二个思路是CNN层,CNN方案即是窗口式遍历,如尺寸为3的卷积,即是:
\[y_t=f(x_{t-1},x_t,x_{t+1}) \]CNN方便并行,而且容易捕捉到一些全局的结构信息,CNN实际只能获取局部信息,其通过层叠扩大感受野。
-
纯Attention
获取
全局信息的问题上,RNN需要逐步递归,因此一般双向RNN才比较好,CNN只能获取局部信息且通过层叠扩大感受野。Attention:\[y_t=f(x_t,A,B) \]其中,A、B是另外一个序列(矩阵),如果取A=B=X,则称作
self_attention,其意思是直接将\(x_t\)与原来的每个词比较最后求出\(y_t\)
Attention层
一般Attention的定义参见声谱预测网络(Tacotron2)注意力机制部分。
-
Attention定义
![]()
一般的Attention思路也是一个编码序列的方案,因此其跟RNN、CNN一样,是一个序列编码的层:
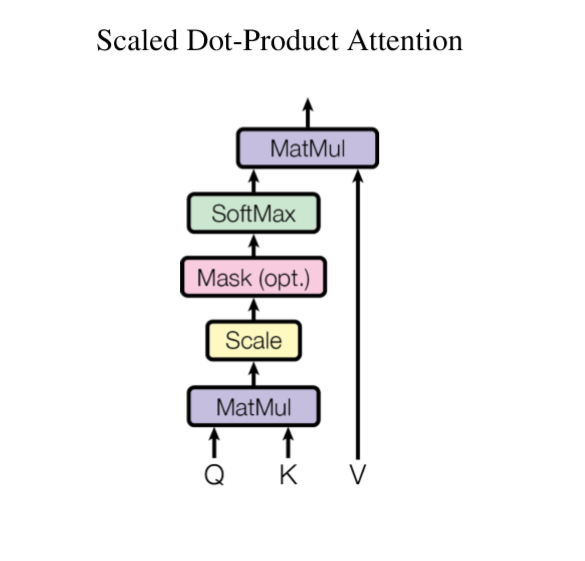
\[Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V \]其中,\(Q\in R^{N×d_k},K\in R^{m×d_k},V\in R^{m×d_v}\)。忽略\(softmax\)和\(\sqrt{d_k}\),其实际是\(n×d_k,d_k×m,m×d_v\)三个矩阵相乘,最后的结果为\(n×d_v\)的矩阵,这也可以认为是一个Attention层将\(n×d_k\)的序列\(Q\)编码为一个新的\(n×d_v\)的序列。
\[Attention(q_t,K,V)=\sum_{s=1}^{m}\frac{1}{Z}exp(\frac{<q_t,k_s>}{\sqrt{d_k}})v_s \]其中,\(Z\)是归一化因子,\(q,K,V\)分别是\(query,key,value\)的简写,\(K,V\)是一一对应的,上式意为通过\(q_t\)这个\(query\),通过与各个\(k_s\)内积并softmax的方式,来得到\(q_t\)与各个\(v_s\)的相似度,然后加权求和,得到一个\(d_v\)维的向量,其中因子\(\sqrt{d_k}\)起调节作用,使得内积不会过大(过大的话,softmax之后就非0即1,不够soft)。
-
Multi-Head Attention
![]()
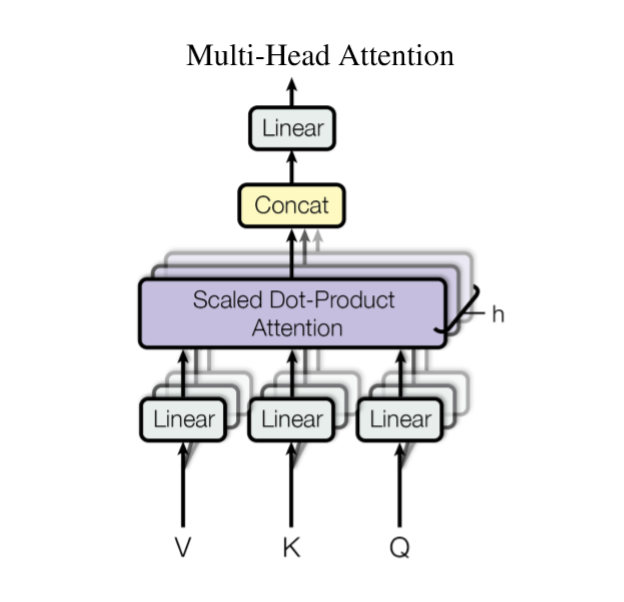
将\(Q,K,V\)通过参数矩阵映射再做Attention,将此过程重复\(h\)次,结果拼接起来即可。具体而言,
\[head_i=Attention(QW_i^Q,KW_i^K,VW_i^V) \]其中,\(W_i^Q\in R^{d_Q×\tilde{d_Q}},W_i^K\in R^{d_k×\tilde{d_k}},W_i^V\in R^{d_V×\tilde{d_V}}\)。之后,
\[MultiHead(Q,K,V)=concat(head_1,head_2,...,head_h) \]最后得到\(n×(h\tilde{d_v})\)的序列,所谓多头(Multi-Head),即是多做几次同样的事情。注意,\(Q,K,V\)做映射时的参数矩阵在各个头之间不共享。
-
Self Attention
假设做阅读理解时,\(Q\)可以是文章的词向量序列,取\(K=V\)为问题的词向量序列,则输出即为所谓的Aligned Question Embedding.
在本论文中,大部分的Attention都是自注意力(self attention),或称内部注意力。
所谓self attention其实就是\(Attention(X,X,X)\),其中\(X\)是输入序列。也就是说在序列内部做Attention,寻求序列内部的联系。论文的重要贡献之一即是表明了内部注意力在机器翻译(甚至是seq2seq)的序列编码上是相当重要的,而之前关于seq2seq的研究基本都只是将注意力机制应用于解码端。更准确来说,本文使用的是self multi-head attention.
\[Y=MultiHead(X,X,X) \] -
Position Embedding
上文提出的模型并不适合捕捉序列的顺序。换言之,如果将\(K,V\)按行打乱顺序,相当于在句子中将词序打乱,则Attention的结果仍一致。这表明了,前述的Attention模型至多是一个精巧的“词袋”模型。
position embedding,也即是位置向量,将每个位置编号,然后每一个编号对应一个向量。通过结合位置向量和词向量训练,这样就可以给每个词引入一定的位置信息,attention也就可以分辨不同位置的词了。
position embedding是本文中注意力机制位置信息的唯一来源,构建position embedding的公式:
\[\left\{\begin{matrix} PE_{2i}(p)=\mathop{sin}(\frac{p}{10000^{\frac{2i}{d_{pos}}}}) \\ PE_{2i+1}(p)=\mathop{cos}(\frac{p}{10000^{\frac{2i}{d_{pos}}}}) \end{matrix}\right. \]将id为\(p\)的位置映射为一个\(d_{pos}\)的位置向量,这个向量的第i个元素的数值就是\(PE_{i}(p)\)。在该论文中,比较训练而得的位置向量和上述公式计算出的位置向量,效果相近。但很明显,通过公式计算的position embedding更易获得。
position embedding本身是一个绝对位置信息,但是在语言中,相对位置也非常重要,采用上式中的位置向量公式一个重要的原因是:
\[sin(\alpha+\beta)=sin\alpha *cos\beta+cos\alpha *sin\beta\\ cos(\alpha+\beta)=cos\alpha *cos\beta-sin\alpha *sin\beta \]这表明了位置\(p+k\)的向量可以表示成位置\(p\)和位置\(k\)的向量的线性变换,这提供了表达相对位置的可能性。结合位置向量和词向量可以采用
元素加和拼接两种方法,直觉上,元素加会带来信息损失,但是该论文中的实验表明两者相差不大。
不足之处
Attention层的好处是能够一步到位的捕获全局信息,因为其直接吧序列两两比较(计算复杂度\(O(n^2)\))。但是由于是矩阵运算,计算量并不是非常严重的问题。相比之下,RNN需要一步一步递推才能捕获全局联系,而CNN需要层叠扩大感受野。
- 本文中专门命名一种Position-Wise Feed-Forward Networks,事实它是窗口为1的一维卷积
- Attention虽然和CNN没有直接联系,但充分借鉴了CNN的思想,如Multi-Head Attention就是Attention做多次然后拼接,这类同于CNN中多个卷积核的思路是一致的,另外残差结构也来源于CNN。
- 无法对位置信息进行很好的建模,用这种纯Attention机制训练一个文本分类模型或者机器翻译模型效果还不错,但是用来训练序列标注问题,效果应该不会太好。
- 并非所有问题都是长程的、全局的依赖,有很多问题只依赖局部结构,论文中提及的restricted版的Self Attention假设当前词只与前后r个词发生联系,因此注意力只发生在这2r+1个词之间,这也就能捕获到序列的局部信息(实际上这就是卷积核中的卷积窗口)
Transformer
该论文中Transformer完全摒弃了递归结构,依赖注意力机制,挖掘输入和输出之间的关系,使得计算并行。
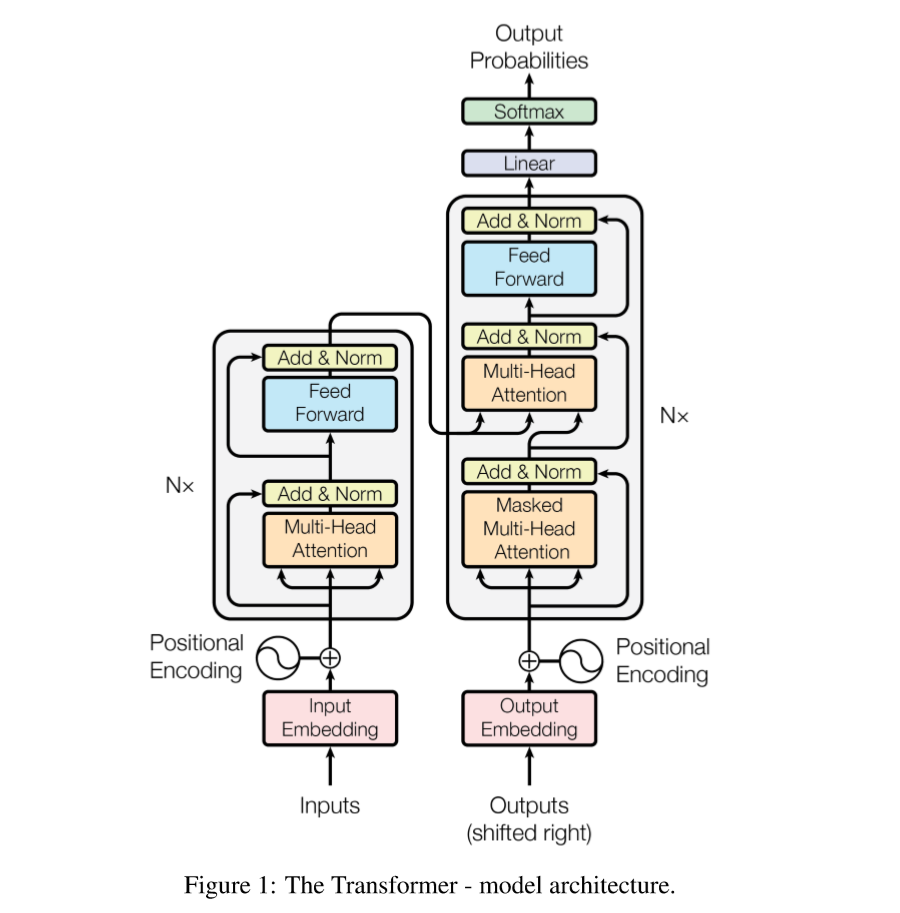
- Encoder: Transformer模型的Encoder由6个基本层堆叠而来,每个基本层包含两个子层,第一个子层是一个Attention,第二个是一个全连接前向神经网络,对着两个子层都引入了残差边和layer normalization。
- Decoder: Transformer模型的Decoder也由6个基本层堆叠而来,每个基本层除了Encoder里面的两个结构之外,还增加了一层注意力机制(Maksed Multi-Head Attention),同样引入了残差边和layer normalization。
总结
注意力机制简单来说就是给定一个查找(query)和一个键值表(key-value),将query映射到正确输入的过程,输出往往是一个加权求和的形式,而权重则是由query、key和value共同决定。
- 在encoder-decoder attention层中,query来自前一个时间步的decoder层,而key和value是encoder的输出,这允许decoder的每个位置都去关注输入序列的所有位置。
- encoder包含self-attention层,在self-attention层中所有的key、value和query都来自前一层的encoder,这样encoder的每个位置都能去关注前一层encoder输出的所有位置。
- decoder中也包含self-attention层
前向神经网络:这是一个position-wise前向神经网络,encoder和decoder的每一层都包含一个前向神经网络,激活顺序为线性、ReLU、线性。
位置编码:引入位置信息
Close to Human Quality TTS with Transformer
论文地址:Close to Human Quality TTS with Transformer
目前的语音合成系统仍然有两个问题亟待解决:1)在训练和推断时低效率;2)使用RNN很难对长时依赖建模。受到机器翻译研究中Transformer网络的启发,将“完全的Attention”嵌入到Tacotron2中。该论文中,使用多头注意力机制取代Tacotron2中RNN结构和原始的注意力机制。利用多头自注意力,能够并行训练编码器和解码器,从而提高了训练效率。同时,不同时刻的两个输入被自注意力直接联系起来,有效解决了长时依赖。这个Tacotron2改进版本添加了一个音素预处理的结构作为输入,使用WaveNet作为声码器。
论文中整个结构如上图,在Encoder Pre-Net之前,添加了一个Text-to-phone Convertor,论文的解释是:英文单词中,不同字母的发音有可能不同,如字母'a',有可能发/ei/音,也有可能发/æ/或/a:/音,之前依赖神经网络学习这种发音规则,但是在数据集小的时候可能无法有效学习到,这里就添了个前端,用规则直接转成音素送入模型里面。
-
Scaled Positional Encoding
《Attention all you need》中的位置编码,这里不像《Attention all you need》中,为了引入位置信息直接和词向量
元素加,而是为位置向量添了一个可训练的权重系数:\[Attention\ is\ all\ you\ need:\ x_i=prenet(phoneme_i)+PE(i)\\ this\ version:\ x_i=prenet(phoneme_i)+\alpha PE(i) \]其中,\(\alpha\)为待训练的权重系数。论文中给出的理由是:原空间是文本,而目标空间是mel频谱,使用固定的位置向量会给编码器和解码器的pre-net带来非常大的限制。
-
Encoder Pre-net
\[embedding(dim:512)\to 3conv(dim:512)\to batch\ normalization\to ReLU\to LinearProjection \]注意:在最后ReLU层之后添加了一个线性映射,主要是因为ReLU输出的值为\([0,+\infty]\),而位置向量的每一维均位于\([-1,+1]\),不同的区间中心会损害模型的表现。
-
Decoder Pre-net
训练时,mel频谱首先会进入2层的全连接网络,这两层的全连接网络主要是为了将mel频谱做embedding,像文本一样映射到子空间,使得\(<phoneme,mel\ frame>\)对能够处在相同的空间中,便于注意力机制发挥作用。实验中,将全连接层的大小由256增至512时,非但没有明显的提升,反而使得收敛变慢,这可能是由于mel频谱拥有小且低维的子空间,256的神经网络层足以映射,过大反而使得模型复杂难以收敛。同样,解码器Pre-net之后,加一个线性映射,保持与位置向量相同的区间中心。
-
Encoder和Decoder
分别将Tacotron2中编码器的
Bi-directional LSTM和解码器的2-layer LSTM替换为Transformer中的编解码器。论文中提到曾想将基于点乘的多头注意力变成基于location-sensitive的注意力,但是发现训练时间加倍并且容易爆内存。 -
Mel Linear, Stop Linear and Post-net
由于stop token的样本不平衡,解决方法就是在stop token的交叉熵损失上加个权,权重5.0~8.0.
-
实验
实验效果上,增加Transformer中Attention的层数和多头注意力的头数可以提高模型表现,但是会减慢训练速度。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文地址:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文宣称将在本月(2018/10)放出模型和代码:BERT model&code
本质是一个预训练模型,效果惊人。该论文中,将预训练模型分为两种,一种是类似Word2Vec那样,提取有效特征给模型用;另一种类似于ResNet在ImageNet上训练完成之后作为Faster R-CNN的骨干网那样,直接作为下游模型的骨架网络,一个模型通吃所有任务。该论文中提出的方法是后者,预训练的BERT使用额外的一个输出层进行微调,即可获得很多任务上当前最好表现。
-
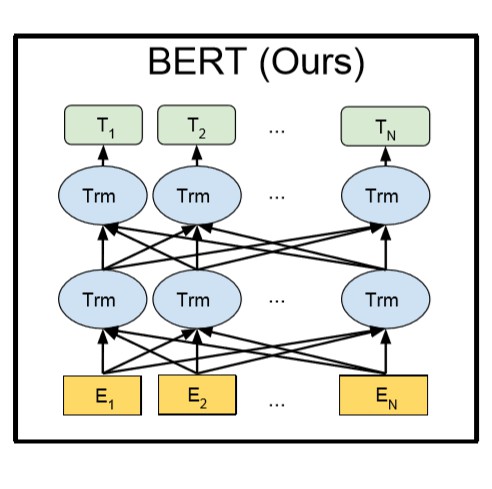
模型结构
BERT的模型结构是一个多层双向Transformer编码器(基于上述Attention all you need中的实现)。
![]()
-
模型输入
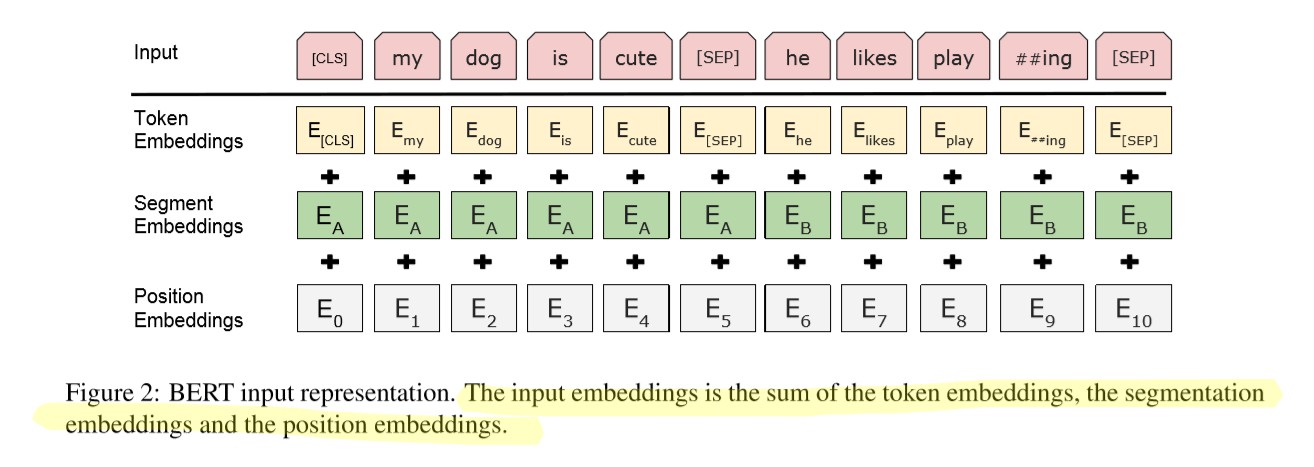
![]()
模型输入:Token embedding + Segmentation embedding + Position embedding
-
预训练任务
不适用传统的从左至右或从右至左的语言模型来预训练BERT,而是使用两种新型的无监督预测任务。
-
Masked LM
随机遮盖输入token中的某些部分,然后预测被遮盖的token,将这一过程称作
masked LM(MLM),在其它文献中也称作Cloze任务。由于[MASK]在微调时从未见过,因此每一次都确定用[MASK]替换要被遮蔽的token。而是随机选择15%的token,在这15%的token中,80%的概率会如上所述,被遮盖掉;10%的概率该token被替换为另一个随机的token;10%的概率不变。这样Transformer就必须对每一个token学习一个分布式上下文表示(distributed contextual representation) -
Next Sentence Prediction
预训练下一句的二分类任务,即选择句子 A和B作为训练样本,B有50%的概率是A的下一个句子,50%的概率不是,要求模型学习判断。这是由于许多下游任务如QA和自然语言推断(NLI)基于对两个文本句子之间关系的理解,因此要训练一个理解句子关系的模型。
-
-
损失函数
\[loss=masked\ LM\ likelihood\ +\ mean\ next\ sentence\ likelihood \]
参考文献
《Attention is All You Need》浅读(简介+代码)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号