神经网络中的梯度消失
只要神经元足够,神经网络可以以任意精度逼近任意函数。为了拟合非线性函数,需要向神经网络中引入非线性变换,比如使用\(sigmoid\)激活函数:
\(sigmoid(x)\)可简写为\(\sigma(x)\),该函数可以将实数压缩到开区间\((0,1)\)。其导数为:
函数图像如下:
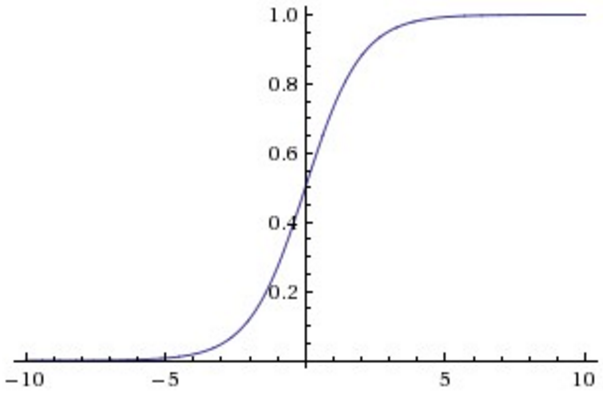
函数两侧十分平滑,两端无限接近0和1,只有中间一段导数较大。当\(x=0\)时,其导数取最大值0.25。选择sigmoid函数作为激活函数的优势:1)可以引入非线性;2)容易求导;3)可以将实数压缩至\((0,1)\)
神经网络主要的训练方法是BP算法,BP算法的基础是导数的链式法则,也就是多个导数的乘积。而sigmoid的导数最大为0.25,且大部分数值都被推向两侧饱和区域,这就导致大部分数值经过sigmoid激活函数之后,其导数都非常小,多个小于等于0.25的数值相乘,其运算结果很小。随着神经网络层数的加深,梯度后向传播到浅层网络时,基本无法引起参数的扰动,也就是没有将loss的信息传递到浅层网络,这样网络就无法训练学习了。这就是所谓的梯度消失。
梯度消失的解决方式主要有:1)使用其它激活函数,如ReLU等;2)层归一化;3)优化权重初始化方式;4)构建新颖的网络结构,如highway net,而capsule net意图取消BP学习过程,釜底抽薪。
其它激活函数
激活函数对神经网络有显著的影响,现行常见的激活函数有ReLU、Leaky ReLU。
-
ReLU
\[f(x)=max(0,x) \]![]()
负数一侧永远为0,正数一侧导数永远为1。ReLU的优势在于:1)不饱和;2)计算效率高;3)收敛速度快。
-
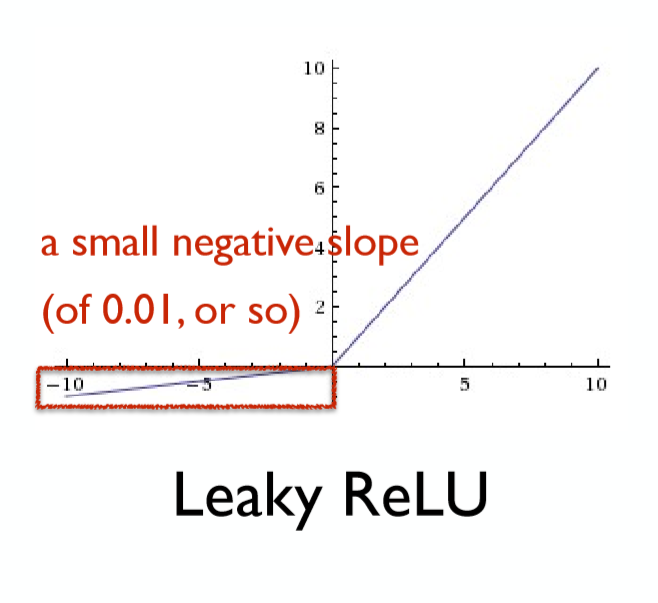
Leaky ReLU
![]()
Leaky ReLU与ReLU十分类似,只不过在负数一侧并不完全抑制,而是给予一个小的导数。
实际上,由于激活函数对于神经网络的影响巨大,对其改进和研究非常多,比如还有Maxout、PReLU等激活函数,一份实践指南:
- 使用ReLU,并注意学习速率的调整
- 试试Leaky ReLU / Maxout
- 试试tanh,但不要抱太大希望
- 不要使用sigmoid 😃
仅供参考。这往往和数据相关,一般多试试就知道好坏了:)。参见Must Know Tips/Tricks in Deep Neural Networks (by Xiu-Shen Wei)
说下对ReLU和sigmoid两者的感悟:
- sigmoid函数在压缩数据“幅度”方面有优势,对于深度网络,使用sigmoid函数可以保证数据幅度不会有问题,幅度稳住后就不会有太大失误
- sigmoid存在梯度消失的问题,在反向传播上有劣势
- ReLU不会对数据做幅度压缩,所以随着深度网络层数加深,数据的幅度会越来越大,最终影响模型的表现
- 但是ReLU在反向传导时,能够将梯度信息“完完全全”地传递到浅层网络
层归一化
也即batch normalization。论文地址:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
主要希望解决的所谓”内部协变量漂移“(internal covariate shift)问题。对于实例集合\((X,Y)\)中的输入值\(X\)分布不可以经常发生变化,因为这不符合样本独立同分布(i.i.d)的假设,使得模型无法捕获数据中的分布,稳定地学习规律。对于神经网络这种包含多个隐层的模型,在训练过程中,各层参数不停变化,所以各个隐层都会面对”covariate shift“的问题,这个问题不仅仅会发生在输入层,而是在神经网络内部都会发生,因此是”internal covariate shift“。
Batch normalization的基本思想:深层神经网络在做非线性变换前的输入值在训练过程中,其分布逐渐发生偏移,之所以训练收敛慢,一般是整体分布逐渐往非线性激活函数的两端靠近,这导致了反向传播时浅层神经网络的梯度消失。而batch normalization就是通过一定的规范化手段,将每个隐层输入的分布强行拉回到均值为0方差为1的标准正态分布上去,这使得输入值落回到非线性激活函数”敏感“区域。这使得梯度变大,学习速度加快,大大提高收敛速度。
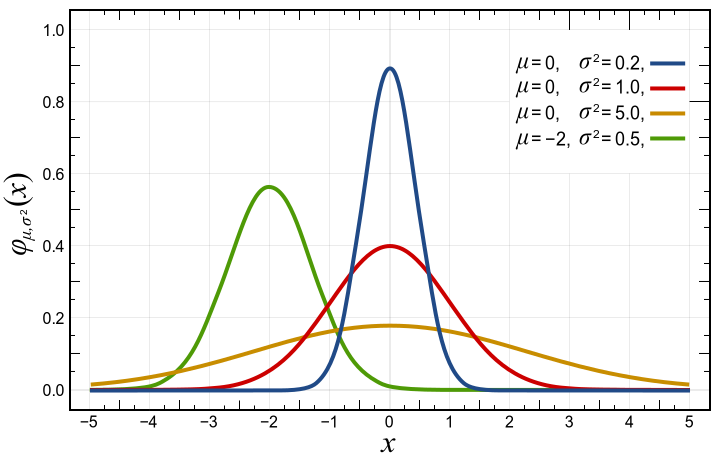
以sigmoid激活函数为例,说明batch normalization的作用。下图红线所示为均值为0,方差为1的标准正态分布:
![]()
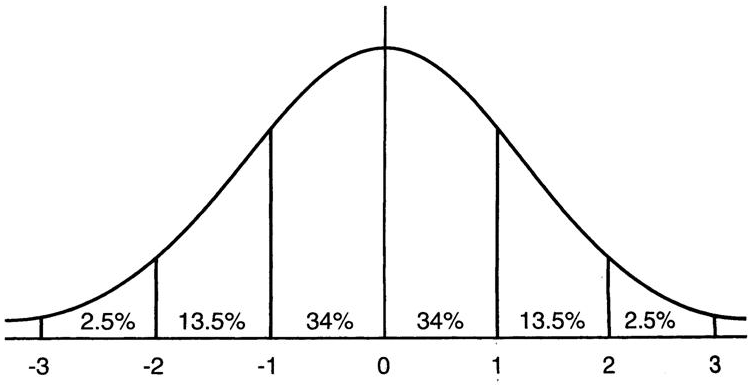
这意味着,在1个标准差范围内,x有64%的概率落在\([-1,1]\)范围内,x有95%的概率落在\([-2,2]\)的范围内。
![]()
上图为sigmoid函数的导数,在\([-2,2]\)的范围内,sigmoid函数的导数很大,而在两端饱和区,导数接近0。这也就意味着,经过batch normalization规范化后,输入值x有较大概率获得大的导数值,远离导数饱和区,从而使得梯度变大,学习速度加快,避免了梯度消失。
但是归一化会破坏数据的分布,使网络的表达能力下降。因此论文中加入了两个参数\(\gamma,\beta\),对变换后满足均值为0方差为1的输出的分布又进行了“恢复”。注意,新添加的两个参数\(\gamma,\beta\)是通过训练得到的,意为将标准化的值从标准正态分布左移右移长胖变瘦些,每个实例移动的程度不同,目的在于希望找到一个线性和非线性的平衡点,既得到非线性较强表达能力的好处,又避免太靠近非线性的饱和区域使得收敛速度变慢。
![]()
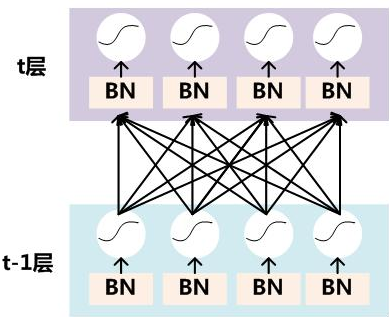
要对每个隐层神经元的激活值做batch normalization,可以想象成每个隐层前又加入了一层batch normalization隐层,其位于激活函数之前,如上图所示。图中的“BN”操作如下:
![]()
即首先将任意值规范化到标准正态分布\(N(0,1)\),然后利用训练得到的参数“恢复”数据的分布。
batch normalization的优势在于:1)大大提高训练速度,加快收敛过程;2)batch normalization是类似于dropout的正则化方法。关于batch normalization起到正则化效果的解释有:过拟合一般发生在数据边缘的噪声位置,而batch normalization将其归一化掉了;归一化的数据引入了噪声,这在训练时有一定程度的正则化效果


权值初始化
前置知识
-
方差
表征数据的离散程度。
计算公式:
\[\sigma^2=\frac{\sum(x-\mu)}{N} \]其中\(\mu\)为样本均值。
若\(x\)服从均匀分布,即\(x\sim U(a,b)\),则\(E(x)=\frac{a+b}{2},D(x)=\frac{(b-a)^2}{12}\)
为了让信息更好的在网络中流动,可以使用xavier的参数初始化方法。
假设输入数据\(x\)和参数\(w\)都满足均值为0,标准差分别为\(\sigma_x,\sigma_w\),而且各个样本都是独立同分布的,则输出为\(z_j=\sum_{i}^{n}w_i*x_i\)。根据概率公式,\(z\)的均值为0,方差为\(n*\sigma_x*\sigma_w\)。将输入的方差\(\sigma_x\)递推展开可得:
其中上标\(k\)表示第\(k\)层的输入数据,\(\sigma_x,\sigma_w\)分别表示数据\(x\)和参数\(w\)的方差。
如前所述,希望输入数据独立同分布,以便收敛的快些,也即是要求\(\sigma_x^k\)对任意\(k\)均不变。即要求连乘内每一项都为1,即\(n^i*\sigma_w^i=1\)对任意\(i\)恒成立,即可推出参数的初始化条件为:\(\sigma_w^k=\frac{1}{n^k}\)
在后向传播中,也希望方差保持一致,这会使得梯度更好地在神经网络中流动。回流的梯度公式:
要使回流的方差不变,则\(n^i*\sigma_w^i=1\)对任意\(i\)恒成立,即可推出参数的初始化条件为:\(\sigma_w^k=\frac{1}{n^{k+1}}\)
通过前向和后向分析,获得两个参数初始化条件。注意,两个初始化条件中的\(n\)不同,前向分析得到的\(n^{k}\)表示某隐层输入维度,后向分析得到的\(n^{k+1}\)表示该隐层的输出维度。将两者杂糅,得\(\sigma_w^k=\frac{2}{n^{k+1}+n^k}\)。
希望使用均匀分布初始化权值,初始化范围是\([-a,a]\),则该均匀分布的方差为:
两者结合,求出\(a\),则:
则初始化范围:\(\left[ -\sqrt{\frac{6}{n^{k+1}+n^k}},\sqrt{\frac{6}{n^{k+1}+n^k}} \right]\)
权值初始化方法,参见CNN数值——xavier(上),深度学习——MSRA初始化
调整网络结构
-
Highway networks
又名高速公路,Highway。Highway Network主要解决的问题是,随着网络层数的加深,梯度信息回流造成网络训练的困难。论文地址:Highway Networks
![]()
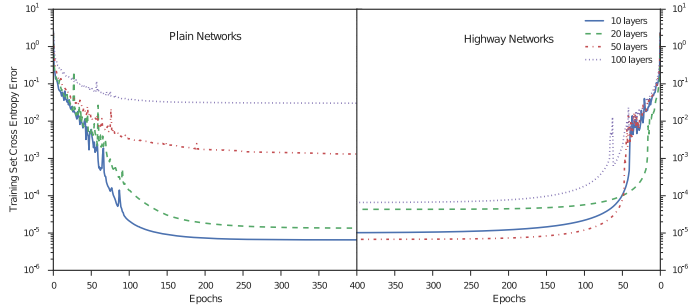
上图为是否添加highway networks结构的对比实验,左图是不添加highway networks结构的神经网络,可以看到,当深度加深,训练误差反而上升。而右图是添加了highway networks结构的神经网络,深度加深而导致训练误差上升的问题得到了缓解。一般而言,深度神经网络训练困难主要是由于梯度回流受阻,当梯度传导到较浅层时已经非常小,对较浅层的权值的扰动很小。
highway networks受LSTM启发,增加了一个门函数,网络的输出由两部分组成,分别是输入和输入的变形。
定义非线性变换\(H(x,W_H)\),门函数\(T(x,W_T)\),携带函数\(C(x,W_c)=1-T(x,W_T)\)。其中门函数可采用sigmoid函数:\(T(x)=\sigma(W_Tx+b_T)\)。则整个网络的输出为:
\[y=H(x,W_H)*T(x,W_T)+x*(1-T(x,W_T))\\ y=H(x,W_H)*T(x,W_T)+x*C(x,W_c) \]注意此处的乘法为element-wise multiplication。门函数\(T(x)\)、非线性变换\(H(x)\)、\(x\)与\(y\)的维度应该是相同的,如果不足,可以用0补足或者使用卷积层变化。
注意到,当门函数\(T(x)\)取极端情况时,
\[y=\left\{\begin{matrix} x,&\quad if\ T(x,W_T)=0 \\ H(x,W_H),&\quad if\ T(x,W_T)=1 \end{matrix}\right. \]其导数为:
\[\frac{\partial{y}}{\partial{x}}=\left\{\begin{matrix} I,&\quad if\ T(x,W_T)=0 \\ H'(x,W_H), &\quad if\ T(x,W_T)=1 \end{matrix}\right. \]可以看到,门函数\(T(x)\)控制着神经网络内信息流动。前向传播时,假设\(T(x)=0.5\)时,输入中一半被激活转换,一半直接进入下一层,这就是所谓“高速公路”的概念。反向传播时,\(T(x)\)同样控制着传导到浅层的梯度大小,并且能够在一定程度上阻止非线性变换的梯度\(H'(x)\)趋向于0。
-
Residual Network
又名残差网络,ResNet。论文地址:Deep Residual Learning for Image Recognition 。有文献称ResNet是上述Highway的特例,但是我没有看到有说服力的解释,下面是两者的小小对比。
Highway:
\[\begin{align} y&=H(x)*T(x)+x*(1-T(x))\\ &=(H(x)-x)*T(x)+x \end{align} \]ResNet:
\[F(x)=H(x)-x \]这就是residual network,其目的和highway network一致,防止神经网络加深导致的训练困难、精度下降的问题。残差网络的一个块如下:
![]()
希望学习非线性变换\(H(x)\),但是\(H(x)\)不易学习,增加一个恒等映射(identity mapping),将非线性变换\(H(x)\)转换为\(F(x)+x\).两者效果相同,但学习难度不同。
Res块(Residual block)通过捷径(shortcut)连接实现,通过shortcut连接将块的输入和输出进行元素级别(element-wise)的叠加即可。
-
另外有直接取消BP算法过程的尝试,比如Capsule Network,参见Capsule Network

参考文献
【深度学习】深入理解Batch Normalization批标准化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号