语音合成技术概述
语音合成,又称文语转换(Text To Speech, TTS),是一种可以将任意输入文本转换成相应语音的技术。
传统的语音合成系统通常包括前端和后端两个模块。前端模块主要是对输入文本进行分析,提取后端模块所需要的语言学信息,对于中文合成系统而言,前端模块一般包含文本正则化、分词、词性预测、多音字消歧、韵律预测等子模块。后端模块根据前端分析结果,通过一定的方法生成语音波形,后端系统一般分为基于统计参数建模的语音合成(或称参数合成)以及基于单元挑选和波形拼接的语音合成(或称拼接合成)。
对于后端系统中的参数合成而言,该方法在训练阶段对语言声学特征、时长信息进行上下文相关建模,在合成阶段通过时长模型和声学模型预测声学特征参数,对声学特征参数做后处理,最终通过声码器恢复语音波形。该方法可以在语音库相对较小的情况下,得到较为稳定的合成效果。缺点在于统计建模带来的声学特征参数“过平滑”问题,以及声码器对音质的损伤。
对于后端系统中的拼接合成而言,训练阶段与参数合成基本相同,在合成阶段通过模型计算代价来指导单元挑选,采用动态规划算法选出最优单元序列,再对选出的单元进行能量规整和波形拼接。拼接合成直接使用真实的语音片段,可以最大限度保留语音音质;缺点是需要的音库一般较大,而且无法保证领域外文本的合成效果。
传统的语音合成系统,都是相对复杂的系统,比如,前端系统需要较强的语言学背景,并且不同语言的语言学知识还差异明显,因此需要特定领域的专家支持。后端模块中的参数系统需要对语音的发声机理有一定的了解,由于传统的参数系统建模时存在信息损失,限制了合成语音表现力的进一步提升。而同为后端系统的拼接系统则对语音数据库要求较高,同时需要人工介入制定很多挑选规则和参数。
这些都促使端到端语音合成的出现。端到端合成系统直接输入文本或者注音字符,系统直接输出音频波形。端到端系统降低了对语言学知识的要求,可以很方便在不同语种上复制,批量实现几十种甚至更多语种的合成系统。并且端到端语音合成系统表现出强大丰富的发音风格和韵律表现力。
深度学习用于语音合成
-
WaveNet
WaveNet并非一个端到端的TTS系统,依赖于其他模块对输入预处理,提供特征。详见下文“声码器”部分,论文地址:WaveNet: A generative model for raw audio
仿照PixelRNN 图像生成方式,WaveNet依据之前采样点来生成下一采样点。WaveNet是一种典型的自回归生成模型,所谓自回归生成模型,即是利用前面若干时刻变量的线性组合来描述以后某时刻变量的线性回归模型,参见第四篇 自回归模型(AR Model)。WaveNet生成下一个采样点的结构为CNN结构。
WaveNet缺陷:1)每次预测一个采样点,速度慢;2)WaveNet并非完整的TTS方案,依赖其余模块提供高层特征,前端分析出错,直接影响合成效果;3)用于TTS时,初始采样点的选择很重要
-
DeepVoice
将传统参数合成的TTS系统分拆成多个子模块,每个子模块用一个神经网络模型代替。论文地址:Deep voice: Real-time neural text-to-speech
DeepVoice将语音合成分成5部分进行,分别为:文本转音素(又称语素转音素, G2P)、音频切分、音素时长预测、基频预测、声学模型。
-
文本转音素
DeepVoice直接输入文本即可,但是由于不同语言存在“同字不同音”的现象,因此需要将文本转化为注音字符。对于中文而言,就是将汉字转化为拼音。
-
音频切分
获得每个音素在对应音频中的起点和终点。使用Deep Speech 2: End-to-End Speech Recognition in English and Mandarin的对齐方法,这些对齐信息用于训练后面的“音素时长预测”模型。
-
音素时长预测和基频预测
该模型为多任务模型,输入带有重音标注的音素序列,输出为音素时长、是否发音的概率和基频
-
声学模型
即后文的“声码器”(Vocoder)。用于将前面得到的高层特征转换为声音波形。DeepVoice的声学模型即是在前文的WaveNet基础上改进的。改进的主要方向是:改变网络层数、残差通道数、矩阵乘代替上采样卷积、CPU优化、GPU优化等。
DeepVoice优势在于:提供了完整的TTS解决方案,不像WaveNet需要依赖其它模块提供特征,使用的人工特征也减少了;合成速度快,实时性好
DeepVoice缺陷:误差累积,5个子模块的误差会累积,一个模块出错,整个合成失败,开发和调试难度大;虽然减少使用了人工特征,但在这个完整的解决方案中,仍然需要使用音素标记、重音标记等特征;直接使用文本输入,不能很好解决多音字问题。
-
-
Tacotron
真正意义上的端到端语音合成系统,输入文本(或注音字符),输出语音。论文地址:Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model。
结构为:Encoder -> Attention -> Decoder -> Post-processing -> Griffin-Lim转为声音波形。后文“Tacotron”部分详述了这个方法。
Tacotron优势在于:减少特征工程,只需输入注音字符(或文本),即可输出声音波形,所有特征模型自行学习;方便各种条件的添加,如语种、音色、情感等;避免多模块误差累积
Tacotron缺陷:模型除错难,人为干预能力差,对于部分文本发音出错,很难人为纠正;端到端不彻底,Tacotron实际输出梅尔频谱(Mel-Spectrum),之后再利用Griffin-Lim这样的声码器将其转化为最终的语音波形,而Griffin-Lim造成了音质瓶颈。
-
DeepVoice2
上文DeepVoice升级版,引入“说话人”向量,能够合成多种音色的语音。
对DeepVoice的改进:
- 音频切分模块和上代结构不变,但加入了batch normalizaiton和残差连接,对原始音频做平滑归一化处理,固定阈值来确定是否为静音音素。
- DeepVoice使用一个模型同时预测音素时长和基频,而DeepVoice2分拆成两个模型。音素时长预测看作是序列标准问题,将连续时长离散化,模型为Neural Architectures for Named Entity Recognition。基频预测使用时长和音素作为输入,只输出发音概率和基频(DeepVoice还输出音素时长)。动机:联合预测还是独立预测,取决于任务之间是否相互促进,存在共同点,音素时长和发音概率&基频关联不大,所以分拆。连续时长离散化的理由在于音素时长不需要十分精准,音素边界存在10~30毫秒的扰动对合成音质无影响,而离散化后更容易处理。
- 声学模型采用继续改进后的WaveNet。
增加“说话人”支持:在encoder、decoder和vocoder三处添加说话人信息,说话人信息是自动从语音数据中学习到的一个16维向量:
- 音频切分模块,激活函数之前,说话人向量和batch normalization的结果做点乘
- 音素时长预测模块,使用说话人向量初始化RNN,并和输入做拼接
- 基频预测模块,使用说话人向量初始化RNN
- 声学模型模块,说话人向量和输入做拼接
-
DeepVoice3 & Tacotron2
DeepVoice3,基于卷积序列到序列模型的多说话人语音合成。论文地址:Deep Voice 3: 2000-Speaker Neural Text-to-Speech
Tacotron2 论文地址:Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
Tacotron
Tacotron是第一个真正意义上的的端到端语音合成系统。输入文本或者注音字符,输出Linear-Spectrum,再经过声码器Griffin-Lim转换为波形。Tacotron目前推出了两代,Tacotron2主要改进是简化了模型,去掉了复杂的CBHG结构,并且更新了Attention机制,从而提高了对齐稳定性。开源地址:Tacotron@github & Tacotron2@github。论文地址: Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model & Natural TTS synthesis by conditioning Wavenet on MEL spectogram predictions 。现以Tacotron为例。
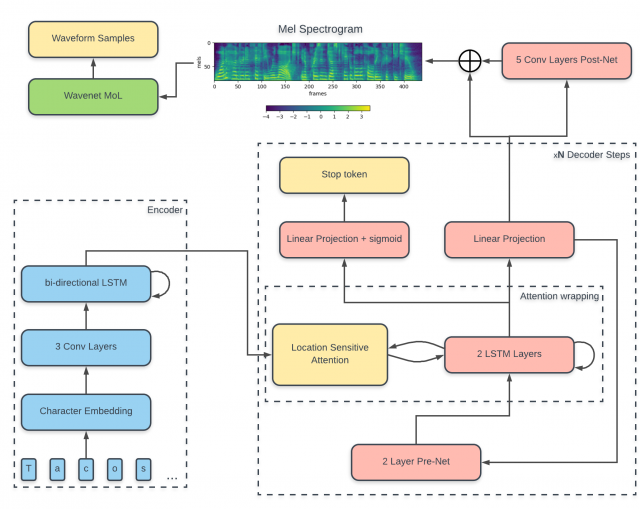
上图为Tacotron在paper中的总体结构,黄色为“输入”,绿色为“输出”,蓝色为“网络”。网络分为4部分,左侧为Encoder,中间为Attention,右下为Decoder,右上为Post-processing。其中,Encoder和Post-processing都包含一个称为CBHG的结构。所谓CBHG即为:1-D convolution bank + highway network + bidirectional GRU,如下图所示。
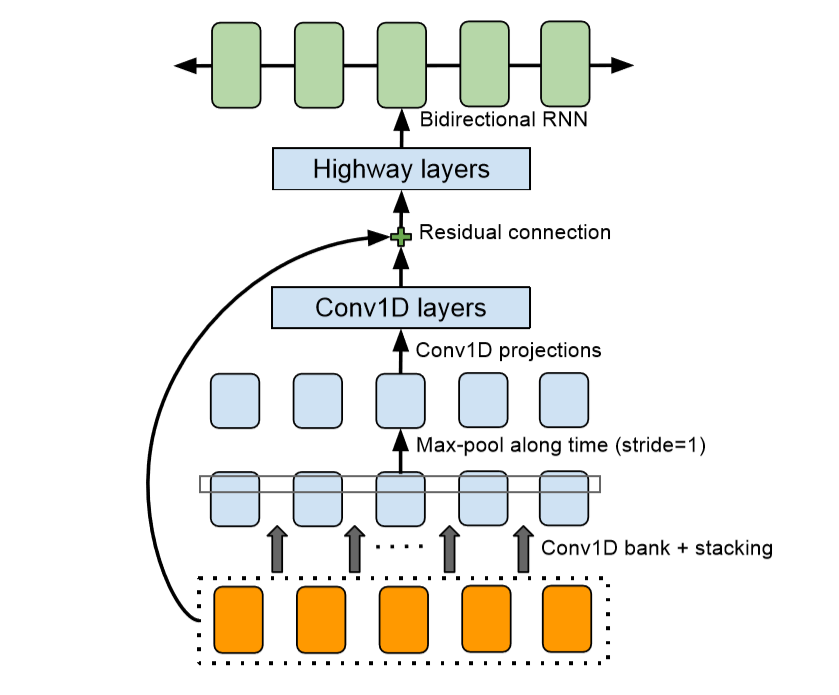
CBHG的网络结构如蓝色框所示,由一维卷积滤波器组,Highway网络和一个双向GRU组成,CBHG是一种强大的网络,常被用来提取序列特征。
Encoder、Attention和Decoder构成了经典的seq2seq结构,因此Tacotron是一种seq2seq+post-processing的混合网络。
Input: 为了避免各种语言的多音字,未录入词发音等问题,Tacotron通常将注音字符作为输入,例如中文可将“拼音”作为输入。这里有个很好用的汉字转拼音的python库:python-pinyin
Output: 根据不同用途,Tacotron可以输出Linear-Spectrum或者Mel-Spectrum两种频谱。如果使用Griffin-Lim作为频谱转波形的声码器(Vocoder),需要Tacotron输出Linear-Spectrum;如果使用WaveNet作为声码器,则Tacotron需要输出Linear-Spectrum或者Mel-Spectrum均可,但Mel-Spectrum的计算代价更小。在Tacotron2中,作者使用了80维的Mel-Spectrum作为WaveNet声码器的输入。
Seq2seq: seq2seq是学习序列到序列的模型,在机器翻译NMT等领域应用广泛。Tacotron套用了该框架。在seq2seq模块中,输入注音字符,输出Mel-Spectrum序列。引入低维Mel-Spectrum的目的在于帮助Attention收敛。该seq2seq模块中还包括了引入CBHG模块,Decoder模块每一时刻同时输出多帧等tricks。
Post-processing: 在Tacotron+WaveNet框架下,由Tacotron输入注音字符,输出频谱;WaveNet输入频谱,输出波形。post-processing模块加在Tacotron和WaveNet之间,主要目的在于串联多个帧,提高生成质量。seq2seq框架决定了Decoder只能看到前面若干帧,而对后面一无所知。但post-processing可以向前向后观测若干帧,参考信息更多,因此生成质量更高。下图中,上面为不加post-processing的声谱图,下面是加了post-processing的声谱图(横轴是离散傅里叶变换DFT)。可以明显看到,加了post-processing模块的声谱图更为清晰、锐利,特别是在低频部分,合成效果更好些。

声码器
Tacotron能够将注音字符解压为频谱,需要声码器将频谱还原成波形。在Tacotron中,作者使用Griffin-Lim算法,从Linear-Spectrum中恢复相位,再通过短时傅里叶变换ISTFT还原出波形。Griffin-Lim算法简单,但是速度慢,很难做到实时。而且通过Griffin-Lim生成波形过于平滑,空洞较多,听感不佳。经过Tacotron2,可以看到,可利用采样点自回归模型提高合成质量。主要的采样点自回归模型有:1)SampleRNN; 2)WaveNet; 3)WaveRNN。这里以WaveNet为例。论文地址:WaveNet: A generative model for raw audio

上图描述了WaveNet这类采样点自回归模型的工作方式。模型输入若干历史采样点,输出下一采样点的预测值,也即是根据历史预测未来。这种工作方式和语言模型很像,只不过音频采样点自回归更难而已,需要考虑更长的历史信息才能够保证足够的预测准确率。
WaveNet是基于CNN的采样点自回归模型,由于CNN结构限制,为了解决长距离依赖问题,必须想办法扩大感受野,但扩大感受野又会增加参数数量,为了在扩大感受野和参数数量中寻求平衡,作者引入了所谓的“扩展卷积”。“扩展卷积”又称“空洞卷积”,就是在计算卷积时跨越若干个点,WaveNet堆叠多层一维扩展卷积,卷积核宽度为2,感受野随着层数的升高而逐渐增大。可以想象,通过这种结构,CNN感受野随着层数的增多而指数级增大。
训练好WaveNet,就可以合成语音波形了。但是由于没有添加语义信息,所以现在的WaveNet生成的波形完全是鹦鹉学舌。所以可以使用Tacotron生成的Mel-Spectrum作为输入,为其添加语义信息。由于采样点长度和Mel-Spectrum长度不匹配,需要想办法将长度对齐,完成这一目标有两种方法:一种是将Mel-Spectrum反卷积上采样到采样点长度,另一种是将Mel-Spectrum直接复制上采样到采样点长度。两种方法差异很小,为了保证模型尽量简洁,故而采用第二种方法。
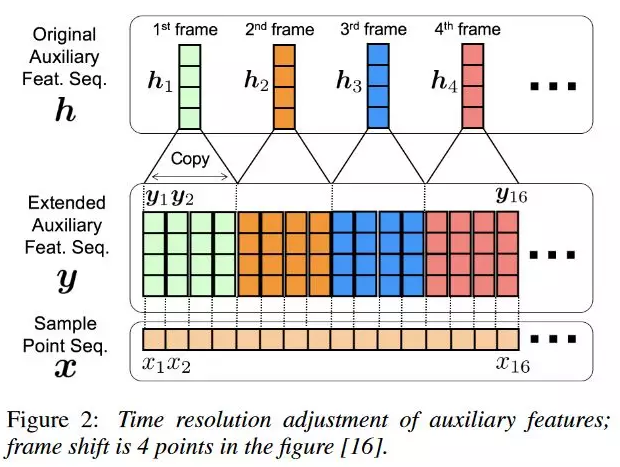
上图展示了第二种方法,将Mel-Spectrum直接复制以上采样到采样点长度的方法。上采样和下采样参见:上采样和下采样-Hoganway,计算机视觉中upsampling(上采样)的三种方式-明天去哪
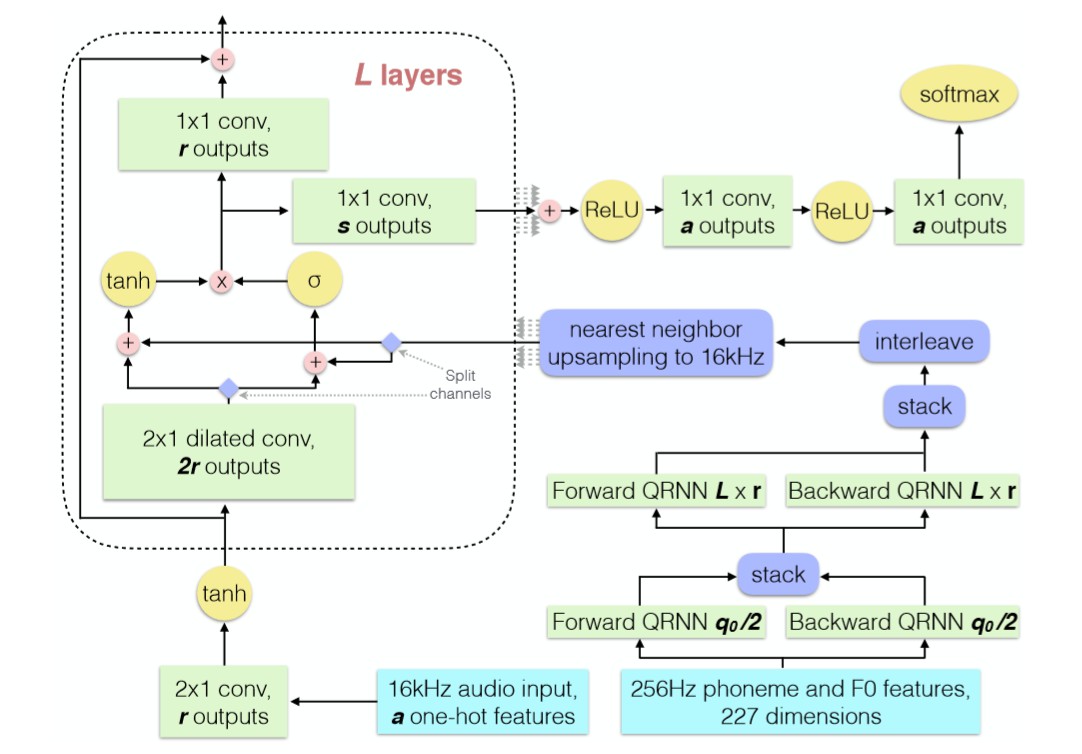
上图为DeepVoice: Real-time Neural Text-to-Speech中将Mel-Spectrum的语义信息嵌入到WaveNet中去的过程。经过复制上采样的Mel-Spectrum首先需要经过一个1*1的卷积,是的Mel-Spectrum维度和WaveNet GAU输入维度相同,然后分两部分累加送入GAU即可。注意,WaveNet每层GAU都需要独立添加Mel-Spectrum语义信息。
Tacotron + WaveNet
一个完整的TTS系统的整体流程即是:注音字符输入Tacotron中,输出Mel-Spectrum;Mel-Spectrum输入WaveNet,输出声音波形。
可以参考基于Tacotron汉语语音合成的开源实践动手训练一个Tacotron模型。
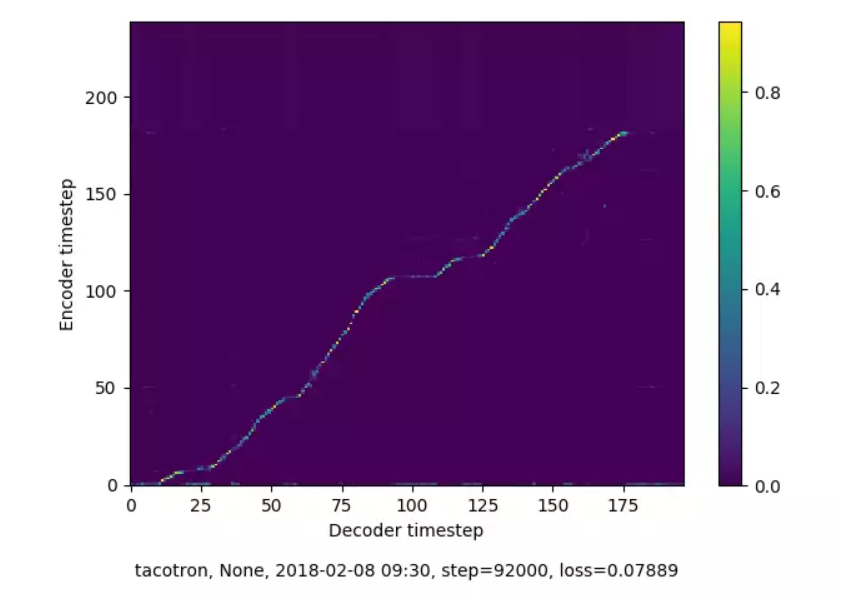
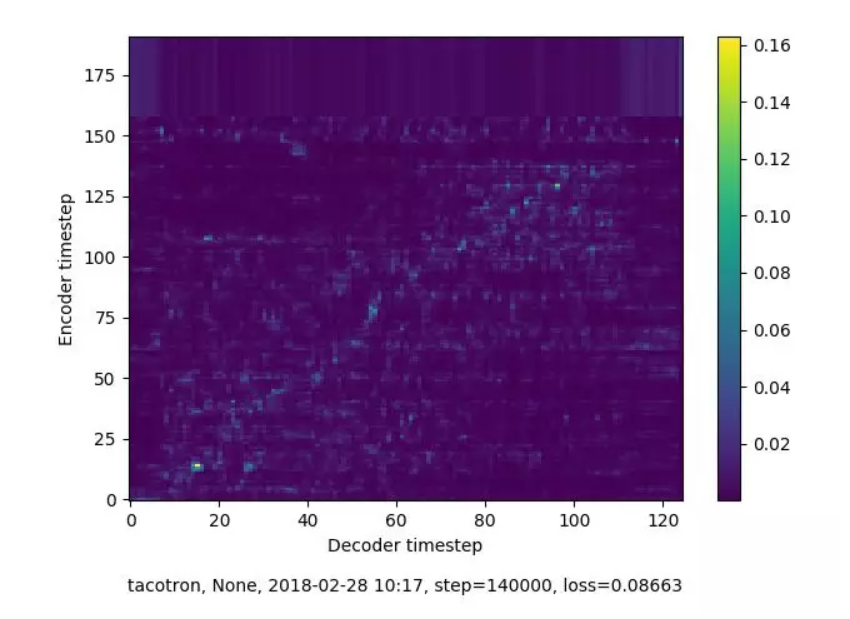
上图为Tacotron的92k步时的对齐情况,表征的是编码器序列(文本,纵轴)和解码器序列(声谱,横轴)是否对应起来。观察训练是否达到预期的条件有两个:1)是否收敛,在上图中即为文本和声谱是否对齐,图中像素点越亮,对齐情况越好;2)loss值低于某阈值,loss值在0.07附近,表明效果已经比较好了。与之对应的,下图为Tacotron的140k步时的对齐情况,像素点模糊,loss值为0.086,训练效果并不好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号