语音合成中声学模型在可控性上的努力
本文主要介绍3种模型,分别是前向注意力(Forward Attention,FA/FA+TA),逐步单向注意力(Stepwise Monotonic Attention,SMA)和FastSpeech2,前两者都是要求注意力权重尽量保证单调向前。具体来说,假设某一解码步上的注意力权重为:\([0,0.8,0.2,0]\),在求下一个解码步的注意力权重时,对原始的query和key“比较”求得的注意力权重加个“系数”,这个系数是上一个注意力权重,加上上一个注意力权重右移一位,这个注意力权重的系数就是\([0,0.8,0.2,0]+[0,0,0.8,0.2]=[0,0.8,1,0.2]\),可以看到,这个注意力系数会让上一个解码步上“关注”的编码状态和下一个编码状态在本次解码时更加受到关注,也就是本次解码要不然停留在原地,要不然向前一步;FA+TA就是为注意力系数显式加了一个向前向后的选择,也就是计算这个注意力系数时,\(0.1\times [0,0.8,0.2,0]+0.9\times [0,0,0.8,0.2]=[0,0.08,0.74,0.18]\),这个多出来的\(0.1,0.9\)是通过一个额外的网络学习得来,这个网络称之为“转移代理”(Transition Agent,TA),转移代理对向前、向后建模更为明确。注意到,转移代理是对注意力权重的系数,再乘上一个系数,而SMA直接对注意力权重乘个向前或者向后的概率,就完事。FastSpeech1/2是另外一个思路,用一个单独的网络学习每个编码状态对应几个解码状态。
Forward Attention in Sequence-to-Sequence Acoustic Modeling For Speech Synthesis
摘要
在语音合成中,音素序列和对应的声学参数序列遵循着单调性原则,也就是说,在生成语音时音素和声学参数都是同步向前的。该文提出了一种适用于该情形的注意力机制,在每一个解码步上对注意力权重添加单调性条件。在每个时间步上,通过前向算法递归地计算注意力权重,于此同时,提出了一种转移代理机制,在每个解码步上帮助注意力机制决策是向前前进一个“音素”,还是停留在原地。
局部敏感注意力LSA
回顾Tacotron-2中的局部敏感注意力机制(Location Sensitive Attention,LSA)。带有注意力机制的编解码器将输入序列映射到不同长度的输出序列,编解码器通常是由循环神经网络(Recurrent Neural Networks,RNN)实现。编码器通常将输入序列\(t=[t_1,t_2,...,t_N]\)映射到隐状态序列\(x=[x_1,x_2,...,x_N]\),解码器利用编码器隐状态序列\(x\)生成输出序列\(o=[o_1,o_2,...,o_N]\)。
在每一个解码步上\(t\)上,注意力机制都对编码器隐状态进行“软性地”选择,将\(q_t\)记作第\(t\)个解码步上的query,\(q_t\)通常是解码器的隐状态;\(\pi_t\in \{1,2,...,N\}\)可以看作一个类别隐变量,表示根据条件分布\(p(\pi|x,q_t)\)对编码器隐状态的选择。那么上下文向量就可通过下式计算:
其中,\(y_t(n)=p(\pi_t=n|x,q_t)\)。LSA引入了卷积特征以稳定注意力的对齐,具体地,\(k\)个大小为\(l\)的卷积核卷积之前解码步的注意力权重。将\(F\in R^{k\times l}\)记作卷积矩阵,则:
在实际的语音合成中,在编码隐状态和解码隐状态之间的对齐路径\(\{\pi_1,\pi_2,...,\pi_T\}\)表示文本特征对应着多少个声学特征。
前向注意力
将对齐路径的概率分布记作:
将\(P\)记作对齐路径,其保持着单调性和连续性,并且不跳过任何编码器状态。
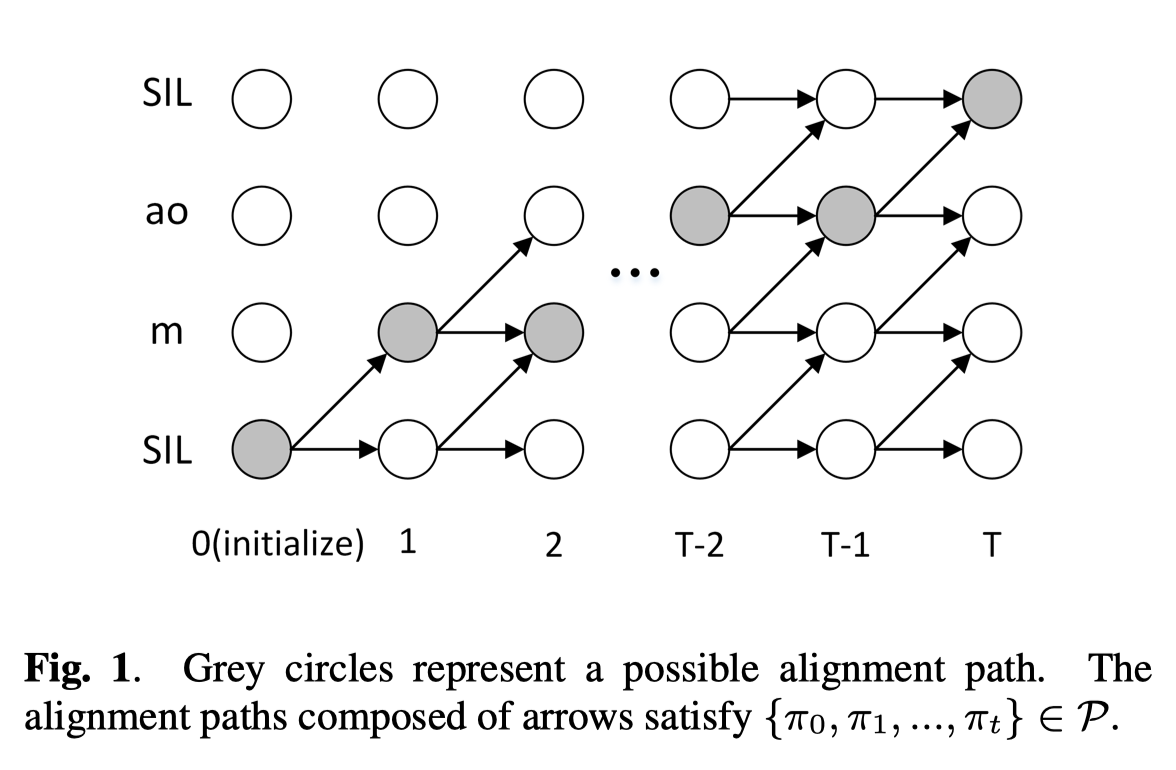
前向变量\(\alpha_t(n)\)定义为对齐路径\(\{\pi_0,\pi_1,...,\pi_t\}\in P\)上的总概率:
其中,\(\pi_0=1,\pi_t=n\)。也就是说,假设第0时间步必选中第1个编码器隐状态,第\(t\)时间步必选中第\(n\)个编码器隐状态。
注意,\(\alpha_t(n)\)由\(\alpha_{t-1}(n)\)和\(\alpha_{t-1}(n-1)\)计算而来:
并且,
保证\(\hat{\alpha}_t(n)\)归一化,\(\hat{\alpha}_t(n)\)表示第\(n\)个编码步上第\(t\)个解码步的对齐权重,张量大小为[batch_size,encoder_times]。并且利用\(\hat{\alpha}_t(n)\)代替注意力权重\(y_t(n)\)求取上下文向量:
前向注意力的算法流程如下:

对应的PyTorch实现:
class AttentionBase(torch.nn.Module):
"""Abstract attention class.
Arguments:
representation_dim -- size of the hidden representation
query_dim -- size of the attention query input (probably decoder hidden state)
memory_dim -- size of the attention memory input (probably encoder outputs)
"""
def __init__(self, representation_dim, query_dim, memory_dim):
super(AttentionBase, self).__init__()
self._bias = Parameter(torch.zeros(1, representation_dim))
self._energy = Linear(representation_dim, 1, bias=False)
self._query = Linear(query_dim, representation_dim, bias=False)
self._memory = Linear(memory_dim, representation_dim, bias=False)
self._memory_dim = memory_dim
def reset(self, encoded_input, batch_size, max_len, device):
"""Initialize previous attention weights & prepare attention memory."""
self._memory_transform = self._memory(encoded_input)
self._prev_weights = torch.zeros(batch_size, max_len, device=device)
self._prev_context = torch.zeros(batch_size, self._memory_dim, device=device)
return self._prev_context
def _attent(self, query, memory_transform, weights):
raise NotImplementedError
def _combine_weights(self, previsous_weights, weights):
raise NotImplementedError
def _normalize(self, energies, mask):
raise NotImplementedError
def forward(self, query, memory, mask, prev_decoder_output):
energies = self._attent(query, self._memory_transform, self._prev_weights)
attention_weights = self._normalize(energies, mask)
self._prev_weights = self._combine_weights(self._prev_weights, attention_weights)
attention_weights = attention_weights.unsqueeze(1)
self._prev_context = torch.bmm(attention_weights, memory).squeeze(1)
return self._prev_context, attention_weights.squeeze(1)
class ForwardAttention(AttentionBase):
"""
Forward Attention:
Forward Attention in Sequence-to-sequence Acoustic Modelling for Speech Synthesis
without the transition agent: https://arxiv.org/abs/1807.06736.
However, the attention with convolutional features should have a negative effect
on the naturalness of synthetic speech.
"""
def __init__(self, *args, **kwargs):
super(ForwardAttention, self).__init__(*args, **kwargs)
def reset(self, encoded_input, batch_size, max_len, device):
super(ForwardAttention, self).reset(encoded_input, batch_size, max_len, device)
self._prev_weights[:,0] = 1
return self._prev_context
def _prepare_transition(self, query, memory_transform, weights):
query = self._query(query.unsqueeze(1))
# W*q_t+V*x_n
energy = query + memory_transform
# energy: [batch_size,encoder_times]
energy = self._energy(torch.tanh(energy + self._bias)).squeeze(-1)
energy = F.softmax(energy, dim=1)
# shifted_weights: [batch_size,encoder_times]
# shifted_weights: [0;encoder_times[:-1]]
shifted_weights = F.pad(weights, (1, 0))[:, :-1]
return energy, shifted_weights
def _attent(self, query, memory_transform, cum_weights):
energy, shifted_weights = self._prepare_transition(query, memory_transform, self._prev_weights)
# \alpha_t(n)=(\alpha_{t-1}(n)+\alpha_{t-1}(n-1))y_t(n)
self._prev_weights = (self._prev_weights + shifted_weights) * energy
return self._prev_weights
def _normalize(self, energies, mask):
energies[~mask] = float(0)
return F.normalize(torch.clamp(energies, 1e-6), p=1)
def _combine_weights(self, previous_weights, weights):
return weights
https://github.com/Tomiinek/Multilingual_Text_to_Speech/blob/master/modules/attention.py
带有对齐代理的前向注意力
所谓的对齐代理,其实就是引入了一个指示器,指示在第\(t\)个解码步上移动到下一个“音素”上的概率,这个指示器由一个全连接层和Sigmoid层组成,输入为上下文向量\(c_t\)、解码器输出\(o_{t-1}\)和query。

可以看到,相比于前向注意力,算法中就是多了一个概率值\(u\),用于控制“注意力”的移动,每一步都根据本时刻的上下文向量、上一时刻的解码器输出以及query计算下一个时刻的概率值。
这可以看作是一个专家产品(Product-of-Experts,PoE)模型,专家产品模型由若干个独立的部分组成,结果由各个组件共同决定。在该文提出的方法中,一个组件\((1-\mu_{t-1})\hat{\alpha}_{t-1}(n)+\mu_{t-1}\hat{\alpha}_{t-1}(n-1)\)描述了单调性对齐的限制,另一个组件\(y_t(n)\)描述了原始的对齐方式,最终的注意力权重\(\hat{\alpha}_t(n)\)的计算由两者共同决定。
与此同时,该文的注意力对齐机制还可以控制音频速度。在生成时向转移代理DNN的Sigmoid输出中添加正或负的偏置值,转移概率\(u_t\)就会增加或者减小,这就会导致注意力移动的速度变快或者变慢,从而导致生成语音变快或变慢。
class ForwardAttentionWithTransition(ForwardAttention):
"""
Forward Attention:
Forward Attention in Sequence-to-sequence Acoustic Modelling for Speech Synthesis
with the transition agent: https://arxiv.org/abs/1807.06736.
Arguments:
decoder_output_dim -- size of the decoder output (from previous step)
"""
def __init__(self, decoder_output_dim, representation_dim, query_dim, memory_dim):
super(ForwardAttentionWithTransition, self).__init__(representation_dim, query_dim, memory_dim)
self._transition_agent = Linear(memory_dim + query_dim + decoder_output_dim, 1)
def reset(self, encoded_input, batch_size, max_len):
super(ForwardAttentionWithTransition, self).reset(encoded_input, batch_size, max_len)
self._t_prob = 0.5
return self._prev_context
def _attent(self, query, memory_transform, cum_weights):
energy, shifted_weights = self._prepare_transition(query, memory_transform, self._prev_weights)
# use last time u_{t-1}
self._prev_weights = ((1 - self._t_prob) * self._prev_weights + self._t_prob * shifted_weights) * energy
return self._prev_weights
def forward(self, query, memory, mask, prev_decoder_output):
# `self._prev_context` should be equal to `context` in `forward()` of `AttentionBase`
context, weights = super(ForwardAttentionWithTransition, self).forward(query, memory, mask, None)
transtition_input = torch.cat([self._prev_context, query, prev_decoder_output], dim=1)
t_prob = self._transition_agent(transtition_input)
self._t_prob = torch.sigmoid(t_prob)
return context, weights
https://github.com/Tomiinek/Multilingual_Text_to_Speech/blob/master/modules/attention.py
实验
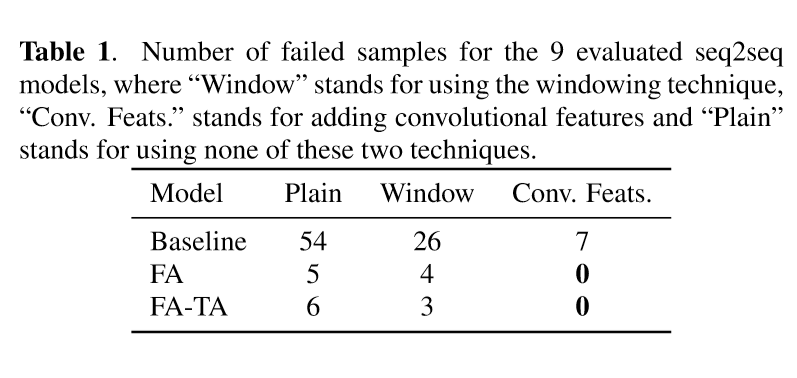
由上图可以看到,生成失败的情形显著减少。
Robust Sequence-to-Sequence Acoustic Modeling with Stepwise Monotonic Attention for Neural TTS
摘要
该文同样是利用语音合成的单调特性,强制输入输出之间不仅仅单调,而且不能跳过输入的每一个时间步。软性注意力可以用来消除训练和推断之间的不一致性。
相关工作
普通注意力
首先还是回顾一下最通用的注意力机制:
其中,\(h_j\)为第\(j\)个编码步的输出,\(s_{i-1}\)为上一时刻\(i-1\)解码器隐状态,\(e_{i,j}\)用于衡量\(s_{i-1}\)和\(h_j\)之间的“相似度”,\(c_i\)是对编码向量进行加权求和,作为第\(i\)步注意力的输出。
单调注意力(Monotonic attention)可以同时保持单调性和局部性,可以应用到包括语音合成领域中:在每个解码步\(i\)上,该机制都会检查上一个解码步选择的memory索引\(t_{i-1}\),从“音素位置”\(j=t_{i-1}\)开始,采样伯努利分布\(z_{i,j}\sim Bernoulli(p_{i,j})\)决定需要保持\(j\)不动,还是移动到下一个位置\(j\leftarrow j+1\)上。“音素位置”\(j\)会一直向前移动,直到到达输入末尾或者收到采样值\(z_{i,j}=1\)。当音素位置\(j\)停止时,该位置上对应的memory,即\(h_j\)将会被直接被作为上下文向量\(c_i\)。可以用下式递归计算\(\alpha_{i,j}\):
或者用下式并行计算:
之后就可以像正常的注意力机制一样,利用注意力权重\(\alpha_{i,j}\)或者\(\alpha_i\)求得上下文向量\(c_i\)了。
注1:
- 伯努利分布Bernoulli
cumprod和cumsum运算符
以向量\(A=[1,2,3,4]\)为例,
cumprod累积乘积
向量\(\mathop{cumprod}(A)\)第一位元素为1:
向量\(\mathop{cumprod}(A)\)第二位元素为2:
向量\(\mathop{cumprod}(A)\)第三位元素为6:
向量\(\mathop{cumprod}(A)\)第四位元素为24:
cumprod累加求和
硬性单调注意力
在最通用的注意力机制中,利用\(\alpha_{i,j}\)计算\(c_i\)的时候,没有使用采样,而是加权求期望,这样能使得训练过程可以反向传播。
在软性注意力中,对同一时刻\(i\),即使\(h_j\)(\(j=1,2,...,T\))是天然有序的,但是在计算\(\alpha_{i,j}\)的时候,\(h_j\)是无序的。即使打乱\(h_j\)的顺序,每个\(h_j\)对应的注意力权重值\(\alpha_{i,j}\)保持不变。并且对于不同时刻对齐到的\(h_j\)并不是单调的,本时刻对齐到\(h_j\),并不影响注意力下次可能就对齐到\(h_{j-1}\),或者\(h_{j-3}\) 😦,这并不符合语音合成的注意力特性。
硬性单调注意力能够保证在计算\(\alpha_{i,j}\)时在编码步\(j\)上是有序的,且让\(\alpha_{i,j}\)在解码步上是单调的。主要思路是,对任意一个时刻\(i-1\),关注且仅关注一个编码隐状态(attend and only attend to one hidden state),记作\(h_j\)。在每一个解码步,计算概率\(p_{i,j}\),决定当前解码步是继续关注原先的编码隐状态\(h_j\),还是跳到下一个\(h_{j+1}\)。
\(e_{i,j}\)的计算和普通的软性注意力(Soft Attention)是一样的,都是求query和每个编码隐状态之间的“相似度”,但是和普通的软性注意力不一样的是,得到\(e_{i,j}\)之后并没有对解码步\(i\)上的所有\(j\)进行Softmax,而是独立进行Sigmoid,得到一个概率值\(p_{i,j}\)。当概率\(p_{i,j}\)的伯努利采样值\(z_{i,j}=1\),则关注原先的编码隐状态\(h_j\),否则\(z_{i,j}=0\)则前进一个编码隐状态\(h_{j+1}\)。如果前进一步(\(z_{i,j}=0\)),在前进之后再次计算\(z_{i,j+1}\),直到\(z_{i,j'}=1\),停止前进,此时得到上下文向量\(c_i=h_{j'}\)。有了上下文向量\(c_i\)之后就可以按照普通的软性注意力里的方法,计算\(s_i\)和\(y_i\)。接着计算下一个上下文向量\(c_{i+1}\),此时需要从\(h_{j'}\)开始,重复上述过程。
训练
公式1介绍了硬性单调注意力的方法,但是这里有一个从伯努利分布的采样操作,采样操作是没办法反向传播的。解决方法和普通的软性注意力一样,使用\(c_i=\sum_{j=1}^T\alpha_{i,j}h_j\)代替原来直接的\(h_j\),但是硬性单调注意力中的\(h_j\)时通过一步一步前进获得的,而求期望则是一个加权求和的过程。那么求每一解码步上联合概率\(\alpha_{i,j}\)的方法如下:
-
当\(i=1\)时,如果是关注\(h_j\),此时对应的概率为\(p_{i,j}\),且\(k=1,2,...,j-1\)都被跳过了,对应的概率为\(\prod_{k=1}^{j-1}(1-p_{1,k})\),则该事件的联合概率为\(\alpha_{1,j}=p_{i,j}\prod_{k=1}^{j-1}(1-p_{1,k})\)
-
当\(i>=2\)时,假设\(i-1\)解码步选中了\(h_k\),那么从时刻\(1\)到时刻\(i-1\)选中\(k\)这总共\(i-1\)个事件的联合概率即为\(\alpha_{i-1,k}\);又假设\(i\)时刻选中了\(h_j\),概率为\(p_{i,j}\),那么说明\(h_k,h_{k+1}...,h_{j-1}\)都应该被跳过,概率为\(\prod_{l=k}^{j-1}(1-p_{i,l})\)
因此整个联合概率模型为:
\[\alpha_{i,j}=p_{i,j}\sum_{k=1}^{j}(\alpha_{i-1,k}\prod_{l=k}^{j-1}(1-p_{i,l}))\tag{2} \]上式中的\(\alpha_{i,j}\)中,外层的\(\sum\)上界中的\(k\)最多可以到\(j\),此时内层的\(\prod\)变为\(\prod_{j}^{j-1}\);定义这种起始点大于终点的累乘结果为1。在这种情形下是正确的,因为当\(k=j\)时,说明\(i\)时刻和\(i-1\)时刻都选中了\(h_j\),概率为\(p_{i,j}(\alpha_{i-1,j}\prod_{l=j}^{j-1}(1-p_{i,l}))=p_{i,j}\alpha_{i-1,j}\)。利用该式对公式2的\(\alpha_{i,j}\)进行化简。
化简方法1
首先对公式2从外层的求和中分离出\(k=j\),则
从连乘符号中分离出\(l=j-1\),并且利用\(\prod_{l=j}^{j-1}(1-p_{i,l})=1\),那么,
把上式中的\((1-p_{i,j-1})\)从内部的连乘和求和符号中拿出来,毕竟已经不和\(l,k\)有关了。变为:
对比一下上面的那个联合概率公式,也就是公式2,把公式2等号右侧的\(p_{i,j}\)除到左边,那么,
和公式4相比,上面公式3的连乘和求和符号部分,就是上标由\(j\)变为了\(j-1\)。把上式3等号右侧的\(p_{i,j}\)除到左边,公式3就变成了:
结合公式4,将求和符号包围的部分替换掉,公式5变为:
令\(q_{i,j}=\frac{\alpha_{i,j}}{p_{i,j}}\),则上式6可以简写为:
到此,将\(\alpha_{i,j}\)的递推公式化简完毕。
化简方法2
现在利用另一种方法化简\(\alpha_{i,j}\)。将公式2内侧的连乘\(\prod_{l=k}^{j-1}(1-p_{i,l})\)变换为\(\frac{\prod_{l=0}^{j-1}(1-p_{i,l})}{\prod_{l=0}^{k-1}(1-p_{i,l})}\),使得分子与\(k\)无关,那么分子就可以从外层的求和中分离出来,上式2变为
令\(q_i=\frac{\alpha_{i,j}}{p_{i,j}}\),将\(p_{i,j}\)除到等号左侧,则
则,
令\(q_{i,j}=\frac{\alpha_{i,j}}{p_{i,j}}\),上式中的\(p_{i,j}\)除到左侧,简化之后的上式:
可以看到,和上面的化简方法1得到的结果一致。
整理一下上述结果:
逐步单调注意力(Stepwise monotonic attention)
逐步单调注意力(Stepwise monotonic attention)在单调注意力(Monotonic attention)的基础上添加额外的限制:在每一个解码步,硬对齐位置应该最多移动一步。
在每一个解码步\(i\)上,该机制探测上一步使用的memory条目\(j=t_{i-1}\),仅需要决定是向前或者停止不动。因此可以直接建立\(p_{i,j}\)分布的递推关系:
同样地,可以更为高效地并行计算:
其中,\([0;]\)表示左侧填充0。
在训练阶段,上下文向量和普通的注意力机制类似。但是可以看到,无论是单调注意力,或是逐步单调注意力,在训练和推断阶段的上下文向量存在不匹配的现象,在训练阶段,送入解码器中的输入是一个“软性”上下文向量而非单一的memory,也就是说在训练阶段,解码器可以利用将来要注意的memory而不是基于当前的memory来预测声学特征。当然,该文建议在推断阶段仍然使用软性注意力,只不过结合上式中求\(\alpha_{i,j}\)的方法,然后对memory进行加权求和。不过如果这样做的话,就没办法流式合成语音了。
实验
实验中比较了5种基于Tacotron的语音合成模型,分别是:
-
基线Tacotron,采用原始的位置敏感注意力机制(Location Sensitive Attention),记作
Baseline; -
混合高斯注意力机制(GMM Attention),20个高斯成分,记作
GMM; -
单调注意力(Monotonic Attention),在推断时采用硬性或软性注意力,记作
MA hard和MA soft; -
前向注意力(Forward Attention),使用或者不使用转移代理,记作
FA+TA和FA w/o TA; -
逐步单调注意力(Stepwise Monotonic Attention),推断时使用硬性或软性注意力,记作
SMA hard和SMA soft。
与基线Tacotron的偏向性测试
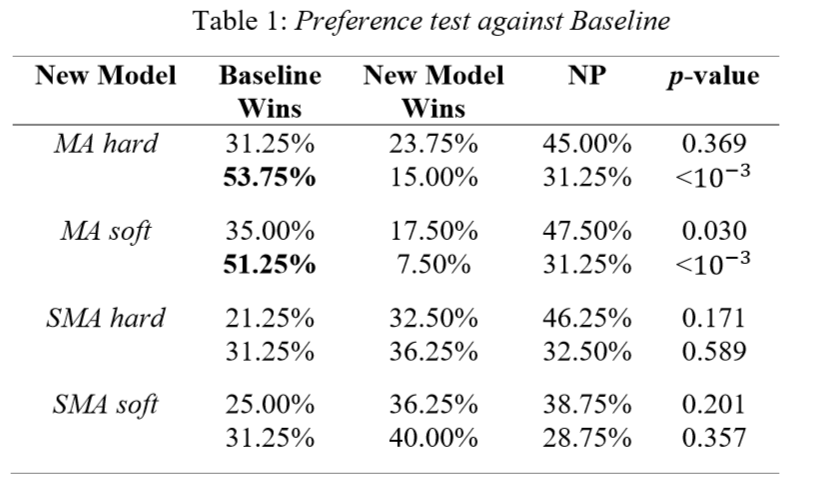
可以看到,SMA优于Baseline,具体来说SMA soft又优于SMA hard。
与软性逐步单调注意力(Soft Stepwise Monotonic Attention)推断的偏向性测试
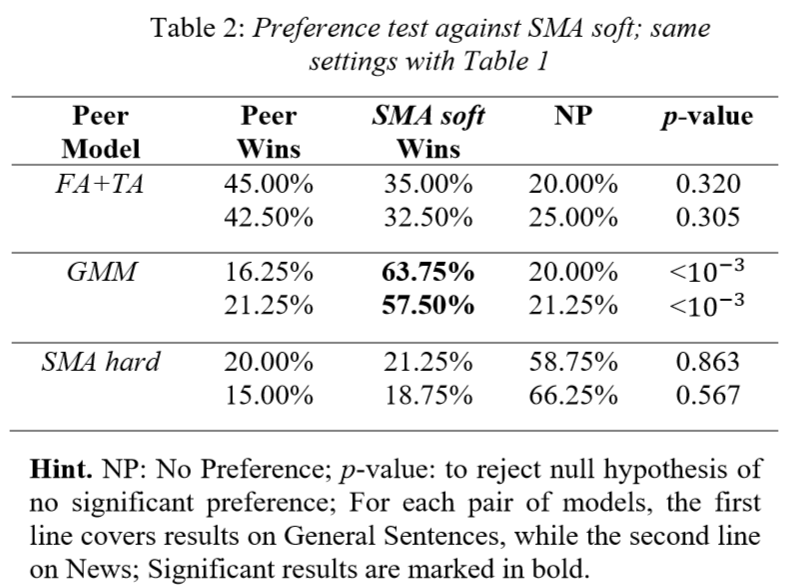
可以看到,SMA soft显著优于GMM,但是比FA+TA还差是什么鬼。
FastSpeech 2: Fast and High-quality End-to-End Text to Speech
摘要
相比于FastSpeech,
-
通过真实目标训练模型,而不是教师模型生成的简化版目标;
-
显式建模语音中的时长、音调和能量,在训练时直接将真实语音中提取的这些特征作为条件输入,在推断时将预测特征作为条件输入;
-
提出了FastSpeech 2s,直接从文本映射为语音,不适用频谱作为中间媒介,提升生成速度,完全端到端并行生成。
相关工作
FastSpeech是一种非自回归的语音合成方法,利用自回归的教师模型提供:1)音素时长以训练时长预测模型;2)生成频谱进行知识蒸馏。但是FastSpeech存在一些问题,比如教师-学生知识蒸馏流程耗费过多时间,从教师模型中提取的注意力权重不够精确。此外,将教师模型的生成目标作为目标损失了训练数据中音调、能量、韵律等方面的多样性信息,生成目标要比真实录音简单且“单调”。
语音合成是一种典型的一对多问题,因为语音中比如音调、时长、音量和韵律等变化,同一段文本可以对应任意多的语音。
如何去解决这种一对多映射问题呢?一个方法就是FastSpeech那样,引入一个教师模型,利用教师模型生成目标和注意力权重,去除变动的部分,简化原始语料中存在的数据偏差;第二个就是FastSpeech 2中采用的方法,将这些易于变动的部分直接剥离开,利用一个单独的预测器生成变动,产生方差(variation)。
为了解决上述问题,FastSpeech 2直接利用原始语音进行训练,使用从原始的目标音频中抽取的时长、音调和能量作为额外输入,并且利用这些额外输入训练对应的预测器。在推断时,直接使用预测的特征作为额外输入,生成语音。考虑到音调对语音比较重要,并且过于多变难以建模,因此利用连续小波变换(Continuous Wavelet Transform,CWT)将音调包络转换为音调谱(Pitch Spectrogram)。总结下来,FastSpeech 2的优势有:
-
移除了教师-学生知识蒸馏机制,简化训练流程;
-
使用真实目标而非生成目标,减少信息损失;
-
显式建模语音中易于变动的特征比如音调、时长、能量等,减轻一对多映射的难题,并且直接从原始语音中提取这些特征,训练时更为精确。
FastSpeech 2/2s
整个FastSpeech 2/2s结构如下图所示,编码器将音素序列编码到音素隐状态序列,利用方差适配器(Variance Adaptor)向隐状态序列中添加额外的方差信息,比如时长、音调、能量等,之后FastSpeech 2/2s利用解码器将多信息混合的隐状态序列转换为梅尔频谱或语音。
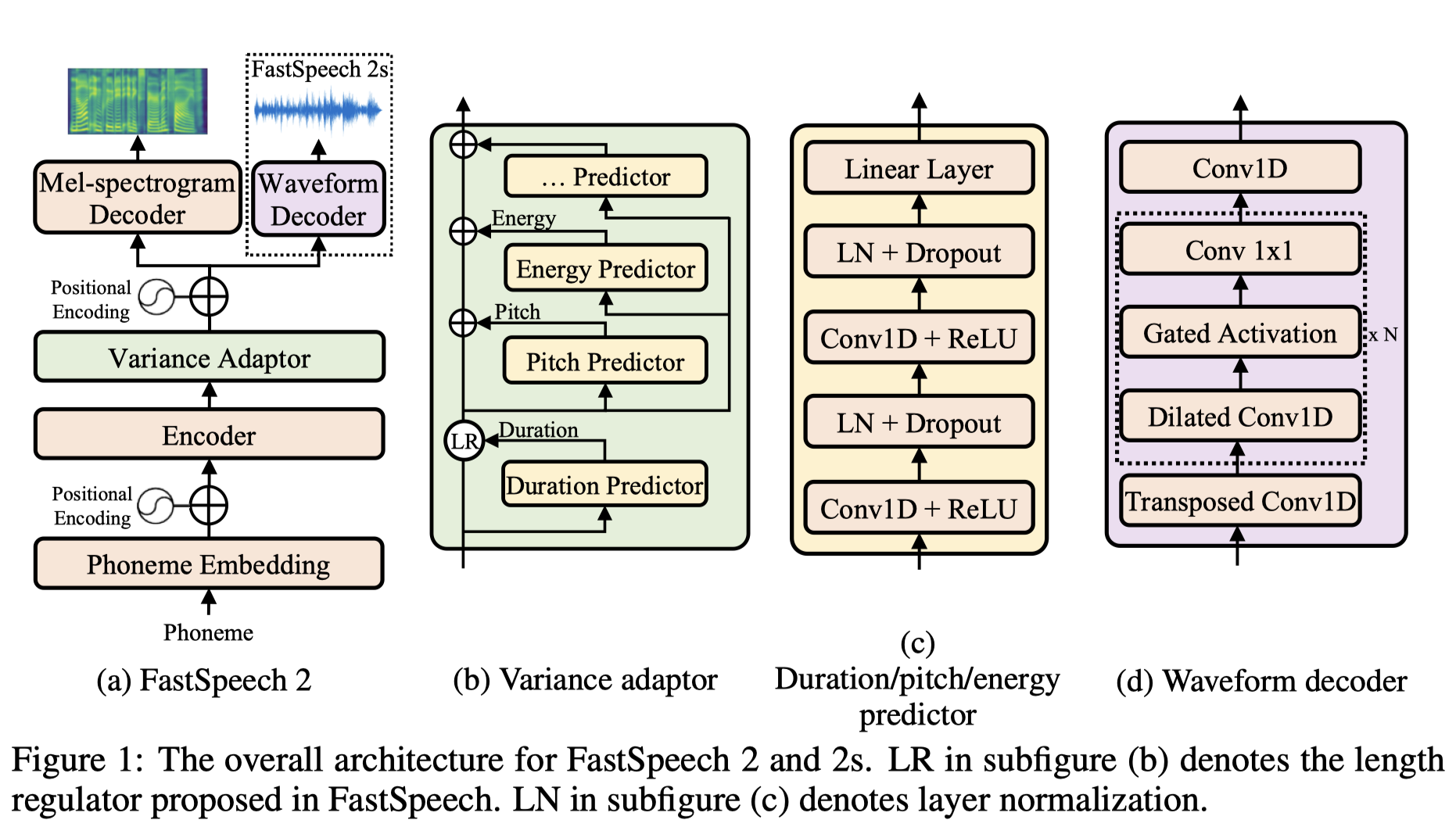
将语音中易于变动的信息总结如下:
-
音素时长,影响语音长度;
-
音调,是影响语音情感和韵律的重要特征;
-
能量,梅尔频谱的幅度,直接影响语音的音量。
实际上可以将语音中更多易于变动的部分分离开来,单独建模,比如情感、风格和说话人等等。在该文中仅单独建模上述三个特征,模型中对应着三个预测器。在训练时,使用从录音文本中提取的真实时长,声调和能量值作为目标去训练时长、音调和能量预测器。
时长预测器
时长预测器输入音素隐状态,输出每一个音素的时长,表示有多少梅尔频谱帧对应着这个音素。使用平均方差(Mean Square Error,MSE)作为损失函数,抽取MFA(Montreal Force Alignment)抽取的时长作为目标值。
音调预测器
由于真实音调中的高方差,预测的音调值和真实音调值分布有比较大的不同,为了更好地对音调包络的变化进行建模,使用连续小波变换(Continuous Wavelet Transform,CWT)将连续的音调序列分解为音调谱(Pitch Spectrogram),并且将音调谱作为音调预测器的目标值,同样使用平均方差MSE作为损失函数。在该文中,将每一帧的音调\(F_0\)量化为对数域的256个值,之后做嵌入,将其转换为对数嵌入向量\(p\),将其加入到扩展隐向量序列。
能量预测器
计算每一个短时傅里叶变换帧能量的L2范数作为能量,之后将每一帧的能量量化到256个值,同样做嵌入,将其转化为能量嵌入向量\(e\),像音调一样加入到扩展隐向量序列中。注意,使用能量预测器直接预测原始的能量值,而非量化之后的值,并且使用平均方差MSE作为损失函数。而不是像音调一样,对能量包络进行连续小波变换的主要原因是能量不像音调一样,有那么大的变化,对能量进行连续小波变换之后,也观察不到任何的提升。
FastSpeech 2s
FastSpeech 2s使用中间隐状态而非频谱直接生成语音,使得整个语音合成模型更加紧凑简洁。之前的工作不直接对语音样本点进行建模的主要原因是,相比于频谱,语音波形更加富有变化;并且大量语音样本点的建模,对有限的GPU显存而言,是一个比较大的挑战。
在FastSpeech 2s中,语音解码器采用对抗训练的方式,使用类似于Parallel WaveGAN(PWG)中的判别器,而生成器输入一小段隐状态序列,然后上采样。
实验
语音质量
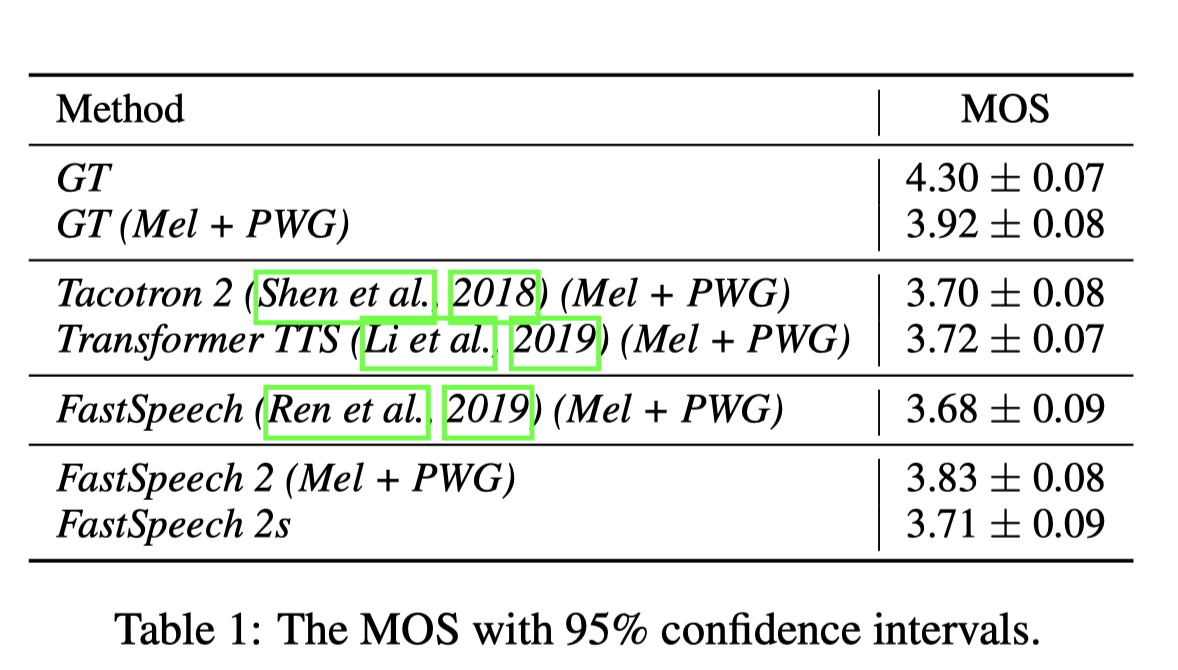
可以看到,合成语音的平均意见得分(Mean Opinion Score,MOS)还是相当高的,但是FastSpeech 2s直接建模语音波形,语音质量稍差。
生成速度
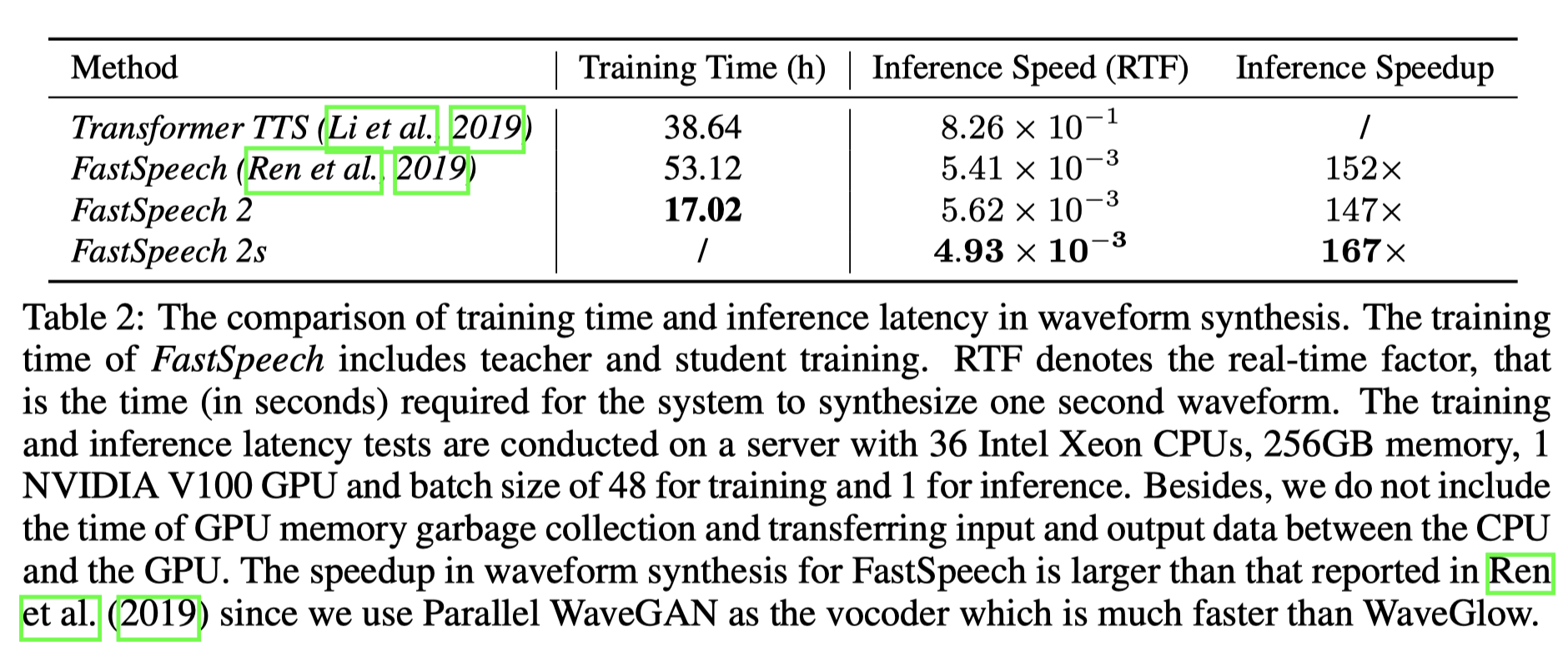
FastSpeech 2的训练速度都比较快,推断速度FastSpeech 2/2s都挺快,超过了实时。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号