Interspeech 2020调研:文本前端
本文主要介绍Interspeech2020中关于语音合成文本前端相关的进展,总体来说,主要是关注中文里面的多音字注音。
g2pM: A Neural Grapheme-to-Phoneme Conversion Package for Mandarin Chinese Based on a New Open Benchmark Dataset
代码地址
g2pM-A Neural Grapheme-to-Phoneme Conversion Package for Mandarin Chinese
摘要
-
开源了一个包含99000+句话的中文多音字数据集(Chinese Polyphones with Pinyin,CPP)。
-
在上述数据集上,仅使用一个简单的Bi-LSTM训练,就可以获得接近SOTA的测试集正确率,略低于利用中文BERT模型训练的文本转音素(Grapheme-to-Phoneme,G2P)模型。
简介
相关工作
目前大部分解决中文多音字的G2P模型可以分为以下几类:基于规则的方法和数据驱动方法。
-
基于规则的方法:使用收集的词典和预先定义的规则。
-
数据驱动方法:使用决策树、最大熵模型、双向LSTM模型在字词句等不同层面抽取特征,但是这类方法几乎都需要依赖额外的工具比如分词器和词性标注器。最近出现了一些工作将G2P当作是序列转录任务,利用编解码模型生成多语种音素。
Multilingual grapheme-to-phoneme conversion with byte representation
Neural machine translation for multilingual grapheme-to-phoneme conversion
数据集的构建
数据收集
-
删除超过50个字符,低于5个字符的句子。
-
在汉字两侧使用“_”(U+2581)标注句子中的多音字。比如“1990年9月15日,在克里米亚发现▁了▁此天体。”。
-
为了防止数据倾斜,每个多音字的句子样本数量控制在10到250之间。
人工标注
-
利用CC-CEDICT提供多音字的候选项,标注者只需要在这些候选读音中选择即可。
-
不是将数据集分成N份,供N个标注者标注。而是每个标注者都标注同样的,完整的数据集,以便后续校对。
数据切分
训练集、开发集和测试集,8:1:1。
模型
模型输入一个汉字,输出多音字的所有候选读音的概率值。
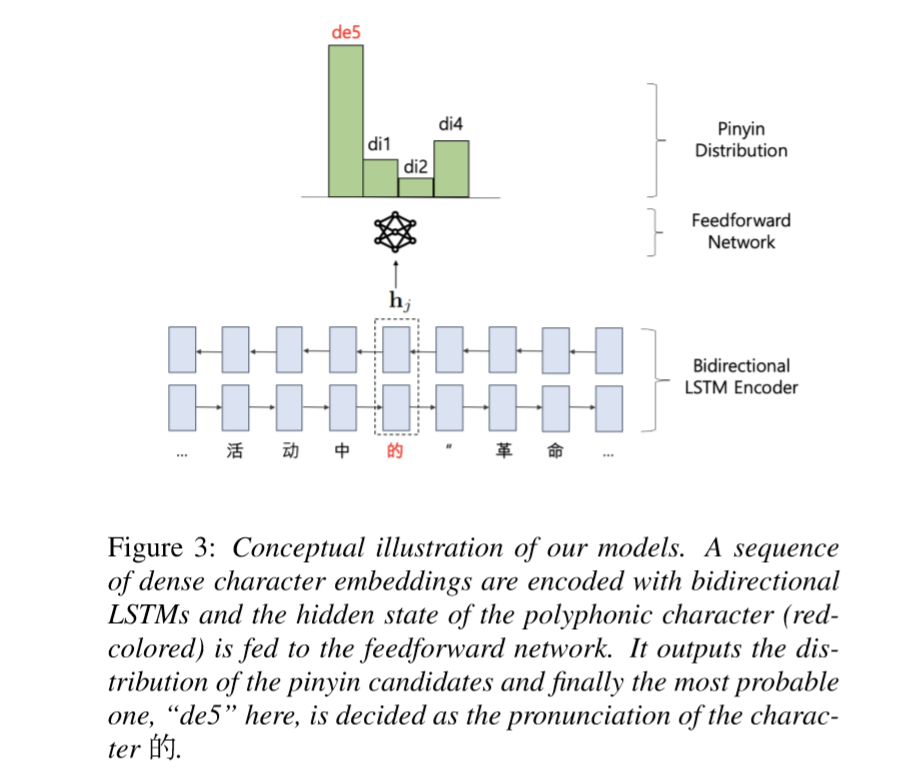
模型主体结构为1层双向LSTM和2层全连接层。
损失函数就是交叉熵。
评测结果
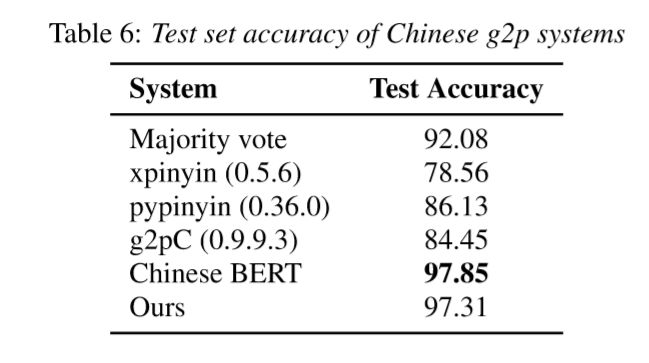
如上表所示,这个简单模型的表现相当不错,稍低于基于BERT的G2P模型。
上表中的Majority Vote是投票法,统计训练集中多音字的拼音,推断时候遇到多音字,直接给这个多音字的最高频拼音,从这个数据看,投票法测试准确率都挺高了,感觉对其它的方法并不公平;第二个是xpinyin,第三个是python-pinyin,规则+词典的方法;第四个是g2pC,使用条件随机场CRF解决多音字的问题;第五个是利用中文BERT,后面接一个简单的全连接层,输入多音字,输出多音字候选读音的概率,训练时不冻结权重。
Distant Supervision for Polyphone Disambiguation in Mandarin Chinese
摘要
本文主要是提出了一个预测中文发音的模型,并且该模型是利用远程监督(distantly supervised)的方式训练获得的。具体地,就是利用声学模型的对齐方法产生大量的字符-音素对,然后训练一个带有注意力机制的序列到序列生成模型;此外,利用音素序列训练的语言模型去消除自动生成数据集中的噪音。
这里所谓的“远程监督”,就是通过将知识库与非结构化文本进行对齐,来自动构建大量训练数据,减少模型对人工标注数据的依赖,增强模型跨领域适应的能力。
简介
动机
数据驱动的文本转音素模型会面临以下挑战:
-
缺少大量的标注数据。人工标注的成本十分昂贵。
-
数据分布不平衡。汉字的出现频率呈长尾分布;此外,中文中的多音字虽然同样一个字符对应多个读音,但多数多音字的某一个读音常常占据主导地位。
-
标注存在偏差。由于多音字的使用方式多样,标注者不同的发音习惯会导致数据集中存在标注偏差。
模型结构
提出的模型包括三个部分:字符-音素转换模块(Character-Phoneme Transformation Module),远程监督数据生成模块和重排模块。字符-音素转换模块使用Seq2Seq框架,以捕获输入字符的上下文,输入文本和输出音素之间的关系;该模块输入汉字序列,输出对应的音素序列。远程监督模块(Distantly Supervised Data Generation Module)使用声学模型的对齐方法,该模块输入汉字序列和对应的声学特征,输出音素序列,通过这个模块可以在无人工标注情况下,获得大量训练数据。但是远程监督模块获得的数据同样引入了大量的噪音,因此引入了重排模块(Reranking Module),该模块通过大量的音素序列训练,对前N个生成的候选音素序列进行重新排序。最高得分对应的预测音素序列将作为最终的结果。如下图所示。

远程监督数据生成模块
如上图右侧所示,该模块输入字符序列和对应的声学特征,输出生成的<字符序列-音素序列>对。在该论文中,该模块使用大约8000小时的中文语音数据训练,LF-MMI作为目标函数。一个包括5层,每一层包含1024个节点,输入映射层包括512个节点。\(t-2\)帧到\(t+2\)帧拼接起来作为时刻\(t\)的输入特征,输出为2408大小的上下文相关音素。通过测试,该G2P模型结合预训练4-gram语言模型在Aishell测试语料上的字错率(Character Error Rate,CER)为2.91。也就是说,通过该模型可以以较高的准确率生成音素序列。
字符-音素转换模块
不同于将多音字消歧当作对单个字符的分类任务,该文直接将文本转音素(Grapheme-to-Phoneme,G2P)作为翻译任务,因此直接采用的是Seq2Seq模型去预测输入字符序列对应的音素序列。也就是说,对于给定的字符序列\(x\),对于每一个可能的音素序列\(y\),该模型计算概率\(p(y|x)\)。该文实验了三种常用的Seq2Seq模型,分别为带有全局注意力机制的LSTM网络、Tansformer和CNN模型,Fairseq中这三个模型均有实现。相比循环网络,卷积网络更容易发现序列中的结构信息。这三个模型的层数分别为2、6和20,编解码器相同。束搜索宽度为5,该模块输出的50-best的预测结果作为重排模块的输入。
重排模块
由于训练数据是自动生成的,因此存在着大量的噪音。与此同时,实践中非平行语料较为充足,比如中英平行语料比较少,但是单英语语料却很多。因此,该文训练了一个基于Transformer的语言模型\(p(y)\)重排上述字符-音素模型生成的N-best候选音素序列。其主要目的就是希望充分利用非平行语料解决噪音问题。Seq2Seq模型的预测分数和语言模型线性结合:
其中,\(\lambda\)为固定权重,论文中设置为1.0。
重排模块的参数设置和字符-音素转换模块的Transformer相似,在AUTO数据集(远程监督模块生成的数据集)上进行训练[1]。
[1] K. Yee, N. Ng, Y. N. Dauphin, and M. Auli, “Simple and effective noisy channel modeling for neural machine translation,” in Empirical Methods in Natural Language Processing, 2019, pp. 5695–5700.
实验
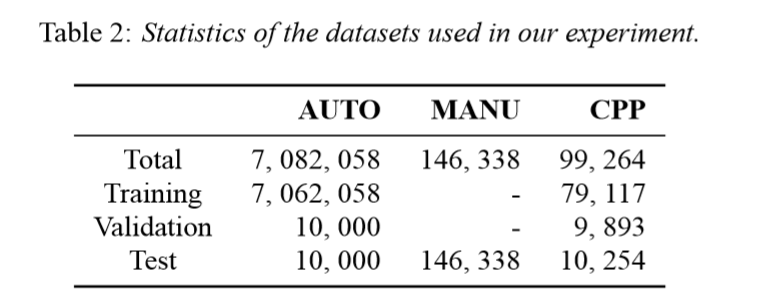
数据集
使用三个数据集进行实验,分别为AUTO、MANU和CPP,后两个均为人工标注的数据集。
实验设置
-
Baseline。为了便于比较,使用了基于词典的Pypinyin和上文中提到的g2pM模型作为基线。
-
方案。对于Seq2Seq模型,分别使用LSTM、Transformer和CNN三种不同的模型,为了便于分析语言模型的作用,实验了加上语言模型之后的表现(表中使用“+LM”标识)。此外,为了和g2p模型公平对比,该文提出的模型同样在CPP数据集上进行了训练(表中使用“(CPP)”标识)。由于CPP数据集每一句话仅标注一个多音字,因此训练之前使用g2pM对所有汉字生成发音。
在三个测试集上的正确率如下表。
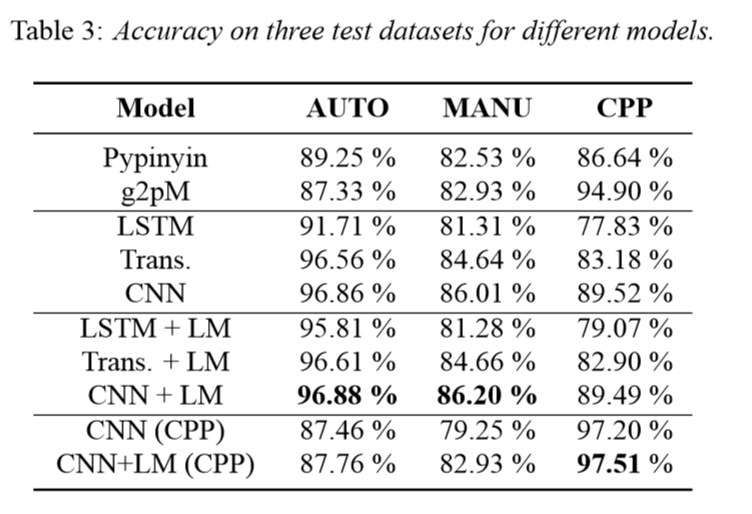
可以看到,加入语言模型的CNN模型的正确率最高,在各个测试集上的表现也最好。CNN模型相比于Transformer,CNN更擅长捕获局部结构。
A Mask-based Model for Mandarin Chinese Polyphone Disambiguation
摘要
该文将从上下文中抽取的掩码向量作为一个额外的输入,在提出的模型中,将掩码向量作为模型输入。掩码向量的输入主要有以下几个:1)丰富了输入特征;2)掩码向量作为加权Softmax的权重,防止模型错误预测其它多音字的拼音;3)带有掩码向量约束的候选对象会将损失传递到损失函数,以更好地指导模型训练。此外为了解决多音字发音分布不均衡的问题,引入了一个修正焦点损失函数(Modified Focal Loss)。
模型主体主要是BLSTM和CNN组成的编码网络获取语义特征。
简介
输入特征
提出的模型主要包括6种特征输入,包括中文字符,中文分词,词性,多音字,标记位和掩码向量。
-
中文字符(Chinese Character,CC):包括单音字和多音字字符。
-
中文分词(Chinese Word Segment,CWS):字符级别的分词结果,以\({B,M,E,S}\)作为标记。
-
词性(Part Of Speech,POS):字符级别的词性标注。
-
多音字(Polyphones,PP):语料中的所有多音字字符和非多音字集合。
-
标记位(Flag Token,Flag):需要消歧、不需要消岐和单音节,以\({0,1,2}\)作为标记。
-
掩码向量(Mask Vecotr,Mask):掩码向量的维度等于拼音集合的长度加上两个特殊的token(
<UN_LABLE>和<NO_LABEL>),前者标识单音字,而后者标识该多音字不需要消歧。
以“仅会在行业规范和会计制度方面进行指导”为例,假设仅对第一个“会”(hui4,候选读音有hui4、kuai4)、“行”(hang2,候选读音有hang2、xing2)和“和”(he2,候选读音有he2、he4、huo4、huo2、hu2)打标签并进行训练,第二个“行”和“行”将不会被打标签。那么上述的特征输入如图所示。

基于掩码的中文多音字消歧模型

字符级别的特征嵌入层(Character-Level Feature Embedding)
这里似乎没有什么可说的,主要是先将各种类别的特征先转换为One-hot,然后利用前馈网络(Feedforward Neural Network,FNN)映射为低维稠密嵌入向量。但是这里有个问题,中文汉字做One-hot然后接前馈网络,这个参数是不是有点多;此外,掩码向量怎么映射为One-hot,是不是掩码向量直接就接前馈网络就行。之后不同特征的嵌入向量进行拼接,然后利用多层前馈网络(Multi-layers Feedforward Neural Network,MFNN)映射为固定长度的向量。
上下文特征编码层(Context Feature Encoding Layer)
上下文特征编码层输入字符级别的特征嵌入层生成的向量,通过BLSTM和一维卷积提取语义级别的信息,之后利用前馈网络将获取的上下文向量压缩到稠密向量中,表征在句子中的每一个字符。需要长距离上下文的情况下,BLSTM是一种抽取句子级别信息的有效方式。一维卷积是抽取n-gram(n元语法)特征的关键方法,对多音字消歧任务比较重要。
受限输出层(Restricted Output Layer)
为了限制输入多音字的候选读音,首先输出层利用掩码向量和加权Softmax去选取最高概率的读音。此外,提出的模型使用修改焦点损失(Modified Focal loss)而非交叉熵作为损失函数。
加权Softmax
对于每个多音字的候选读音集合,实际上仅占整个拼音集合很小的一部分。而Softmax会给每一个拼音分配一个非0概率,这就会导致概率值分布会非常发散,从而对整个训练产生负面影响。因此,在该文中使用加权Softmax,并且将掩码向量作为加权Softmax的加权权重。
假设Softmax函数的输入为\(V={v_1,v_2,...,v_n}\),其中\(v_i\)表示向量\(V\)的第\(i\)个元素;输入的掩码向量记作\(M={m_1,m_2,...,m_n}\),其中\(m_i\)是布尔值,表示是否掩蔽元素\(v_i\)。则对于每个元素的概率值计算方法如下:
通过加权Softmax可以在计算概率值的时候,排除掉特定多音字的非候选读音。在训练的时候,加权Softmax也可以让模型更集中精力关注多音字的候选读音,而非整体的拼音集合。
修改焦点损失(Modified Focal Loss)
由于拼音出现频次的不平衡性,会导致模型过多关注常常出现的拼音,而忽视那些稀有和难以分类的样例,从而降低模型的表现。因此该文提出了一种修改版的焦点损失(Modified Focal Loss,MFL),设置一个阈值\(\alpha\)判断一个样本是大量或者容易分类的样本,还是一个困难而稀有的拼音,对前者降权,而对后者加权,从而使得模型更加关注难以标注读音的样本。
原始的焦点损失(Focal Loss)如下:
其中\(p_t\)表示模型对真实标签的预测概率,值域为\([0,1]\);\(\gamma\)为超参数,值域为\((0,+\infty)\)。
本文提出的修改版的焦点损失(Modified Focal Loss,MFL)如下:
其中,\(\alpha\)为可调的置信参数,值域为\((0.0,1.0)\)。当模型对真实读音的预测概率大于\(\alpha\)时,就认为该输入多音字是容易分类的,那么该样本对于整体损失的贡献将会降低,否则会增大整体损失。
实验
数据集
使用的好像是标贝内部的多音字数据集,有692,357句话,每句话至少有一个多音字,训练集和测试集比例大约9:1。
模型结构和结果
-
BLSTM。双向LSTM的层数设置为2,隐层大小设置为512.
-
B-CNN。双向LSTM和CNN层数都设置为2,隐层大小设置为512。CNN的卷积核数设置为64,步长设置为64.
-
BC-W。和2相同,但是使用了加权Softmax。
-
BC-F。和3相同,但是应用了修改焦点损失,且\(\gamma\)设置为0.7.
-
BC-WM。和3相同,但是使用了加权Softmax。超参数\(\alpha\)设置为0.5,\(\gamma\)设置为0.7。
多音字正确率如下。

如上表所示,系统5的正确率最高。
Enhancing Sequence-to-Sequence Text-to-Speech with Morphology
摘要
本篇文章主要是给出了一个结论:使用语素(morphology)边界可以显著提升语音合成的质量。相比于不加入边界的音素输入,向原始文本中加入语素边界后,合成的语音质量更好。并且由于语素分割任务较为简单,而且分割准确率较高,因此这个简单的预处理步骤,在语音合成的序列到序列建模领域有较大潜力。
简介
语素/形态学(Morphology)
在一些词典中会指明语素,比如Unisyn[1]和Combilex[2]。
[1] S. Fitt, “Unisyn lexicon,” 2020. [Online]. Available: http://www.cstr.ed.ac.uk/projects/unisyn/
[2] S. Fitt and K. Richmond, “Redundancy and productivity in the speech technology lexicon - can we do better?” in Proc. Interspeech. ISCA, 2006, pp. 1202–1204.
在Unisyn中直接标明了语素边界,比如单词unanswered有前缀<un-,词根{answer}和后缀-ed>,因此字母和语素条目就会被记作<un<{answer}>ed>。
如下表是论文中输入到Tacotron的几种形式,以potholes为例。

加入语素边界的动机在于,以coathanger为例,包含两个子词单元th、ng,这两个子词单元的发音和there中的th,range中的ng就不同。而语素边界原则上可以帮助解决英语拼写引起的某些发音歧义:子词单元th在{coat}{hang}>er>表示的含义要明显比coathanger更清楚一些。
关于如何获得这些词素边界,该论文并没有讨论。之前也提到Unisyn提供了语素信息,对于集外词(Out-Of-Vocabulary,OOV),可以通过一些模型[3]获得词素边界。
[3] M. Bikmetova and K. Richmond, “Neural network modelling of grapheme-to-phoneme transformations: automatic morphological analysis,” Bulletin of UGATU, vol. 84, no. 2, pp. 121–126, 2019.
评测结果
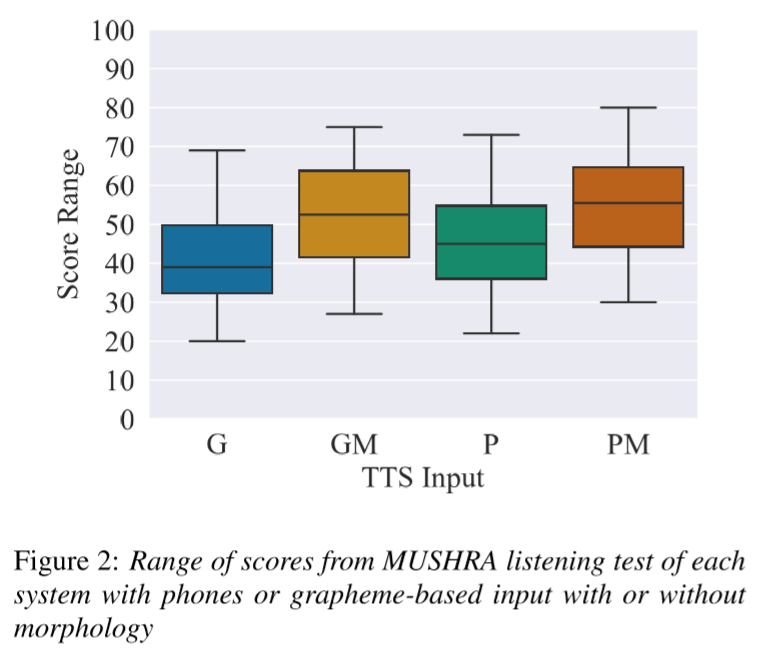
MUSHRA试听评测结果上看,输入语素边界的模型(横轴带有M标识的模型)所生成的语音要明显好一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号