
神经机器翻译中有用的技巧
本篇总结神经机器翻译的实践中,较为基础的最佳实践。
应该使用哪个模型作为基线
Transformer是2017年发布的模型,即使到2020年仍然是比较好的基线模型,大热的BERT就是其升级版。
代码地址
这里实际推荐比较使用Fairseq指定arch为Transformer,按照官方教程直接就可以跑起来。为了便于理解和快速使用Fairseq,也可以浏览一些中文博客:利用Fairseq训练新的机器翻译模型 - 冬色 - 博客园,Fairseq-快速可扩展的序列建模工具包 - 冬色 - 博客园等。
Fairseq实际是序列建模工具包,包含很多模型,较为复杂。对于初学者而言,显得较为笨重,如果只是希望了解下Transformer,快速地跑起来,可以用一些专门实现Transformer的库。平时如果用到了MultiHead Attention这些模块,也可以从这个库中直接复制过去使用。
论文地址
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in Neural Information Processing Systems. 2017: 5998-6008.
解读文章
Transformer影响力比较大,至今已有10k+的引用量,解读文章更是数不胜数。
有哪些较好的工具包
使用机器翻译工具包,可以省去实验中很多繁琐细节的实现,比如数据装载、日志统计、经典模块的使用等。注意,所有工具包都有一定的学习成本。
如果熟悉Pytorch较为推荐,Pytorch官方FAIR推出的框架。各个模块解耦,大量采用注册机制,代码可读性尚可。显存占用经过优化,计算效率高。
如果熟悉Tensorflow较为推荐,Tensorflow官方Google推出。
同时支持Pytorch和Tensorflow,官方地址:OpenNMT。
有哪些经过时间检验的技巧
标签平滑(Label Smoothing)
标签平滑适用于在分类问题中,类别数较多的情况下,防止过拟合,本质是一种正则化策略,显式添加噪音防止模型对自己的判断过于自信。如果使用Fairseq,只需要在训练时指定使用label_smoothed_cross_entropy损失函数即可。一个简单的例子:
python fairseq_cli/train.py <DataPath:str> --max-token <MaxToken:int> --arch transformer --criterion label_smoothed_cross_entropy --label-smoothing 0.1
平均模型参数
对训练获得的,一定训练步数范围内的模型参数进行平均,通常也会有提升,这一点有点像集成学习,但是集成学习一般是对模型的输出结果进行投票或者平均,但是此处是直接对模型本身的参数进行平均。一般可以平均训练末期的,最后10~30轮的模型参数。注意,在平均模型参数时,一定要对模型训练充分,如果待平均的模型本身就没有充分训练,平均模型参数相反可能有害。
如果使用Fairseq,可以使用fairseq/scripts/average_checkpoints.py,其它框架可以参照此代码。
python scripts/average_checkpoints.py --inputs <CheckpointDir:str> --output <AvgCheckpointPath:str> --num-epoch-checkpoints 10
集束搜索(Beam Search)
相比于分类任务,生成任务通常是一个时间步一个时间步依次获得,且之前时间步的结果影响下一个时间步,也即模型的输出都是基于历史生成结果的条件概率。在生成序列时,最暴力的方法当然是穷举所有可能的序列,选取其中连乘概率最大的候选序列,但该方法很明显计算复杂度过高。一个自然的改进想法是,每一个时间步都取条件概率最大的输出,即所谓的贪心搜索(Greedy Search),但这种方法会丢弃绝大部分的可能解,仅关注当下无法保证最终得到的序列最优。集束搜索实际是这两者的折中,简言之,在每一个时间步,不再仅保留当前概率最高的1个输出,而是每次都保留num_beams个输出。
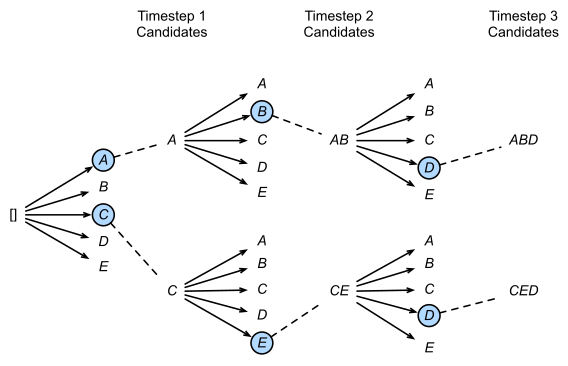
如上图所示,图中的num_beams=2,也就是说每个时间步都会保留到当前步为止,条件概率最优的2个序列。
如果使用fairseq,可以直接在生成时指定参数--beam即可。一个例子:
python fairseq_cli/interactive.py <DataDir:str> --path <CheckpointPath:str> --batch_size 128 --beam 5
集束搜索在fairseq中的具体实现位于fairseq/search.py中。
回译
回译是常见的数据增广技术。使用平行语料训练一个从目标语言到源语言的翻译模型“反翻译模型”,之后利用这个“反翻译模型”将目标语言的文本翻译到源语言,构造新的平行语料。将生成的新平行语料和原来的平行语料,全部作为源语言到目标语言翻译模型的训练数据。当然,“反翻译模型”输入的目标语言文本最好不在原来的平行语料中;如果确实没有外部数据,只有这些语料,应该也会有提升,此时要特别注意数据要去重,模型要加噪。
数据清洗
虽然数据清洗很是老生常谈,而且也并不局限于机器翻译,但是优质的数据不管在哪个领域下都是有益的,大量数据证明,万般技巧不如数据最重要。
机器翻译中除了检查平行语料正确性等,还需要额外注意以下几点:
-
去重。对重复的平行语句直接删除。
-
对源句子与目标句子长度比例进行检测,当长度比超过一定的阈值时就将对应的平行语句对进行删除。
-
使用giza++对训练数据进行了对齐并获得一份双语词典。使用获得的双语词典可以对平行语料进行漏翻检测,通常会对语料的漏翻程度进行打分,分值超过一定阈值时,直接删除对应的语料。
数据量太小怎么办
迁移学习(Transfer Learning)
首先训练其它平行语料比较多的翻译模型,然后以该翻译模型作为初始值,利用少量的平行语料重新进行训练,得到最终的机器翻译模型。
B. Zoph , D. Yuret, J. May, and K. Knight,Transfer Learning for Low-Resource Neural Machine Translation , EMNLP 2016.
多任务学习
充分利用不同语种翻译的相关性,采用共享相同的NMT参数同时学习多个翻译任务。
此外,谷歌于2016年下半年提出的Zero-Shot翻译方法,基于多语种共享的词汇集,使用单个神经机器翻译(NMT)模型在多种语言之间进行翻译,除了提升训练数据中包含的语种对之间互译的翻译质量之外,还能完成训练数据中不包含的语言对之间的zero-shot翻译。
Thang Luong, Quoc Le, Ilya Sutskever, Oriol Vinyals, and Lukasz Kaiser, Multi-task Sequence to Sequence Learning,ICLR 2016.
Melvin Johnson, Mike Schuster, Quoc V. Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda B. Viégas, Martin Wattenberg, Greg Corrado, Macduff Hughes, and Jeffrey Dean. Google’s multilingual neural machine translation system: Enabling zero-shot translation.
对偶学习(Dual Learning)
机器翻译中,可以利用对偶学习提升对无监督数据的利用。例如中英机器翻译任务中,同时训练中文到英文、英文到中文两个翻译模型,两个模型互相提升,最终获得较好的效果。
Di He, Yingce Xia, Tao Qin, Liwei Wang, Nenghai Yu, Tie-Yan Liu, and Wei-Ying Ma, Dual Learning for Machine Translation, NIPS 2016.
枢轴语言(Pivot Language)
如果希望获得中文到法语的翻译模型,但是中文到法语的平行语料较少,中文到英文、英文到法语的平行语料比较多,可以利用英文作为“枢轴语言”,在中文和法语之间作为桥接,训练中英、英法两个翻译模型,最终完成中翻法的任务。
Yong Cheng, Qian Yang, Yang Liu, Maosong Sun, and Wei Xu. 2017. Joint Training for Pivot-based Neural Machine Translation. IJCAI 2017

