
HashMap的工作原理
有很多 Java 开发者都在使用HashMap,HashMap是一种简单易用,且功能强大的数据结构。但是有多少开发者知道HashMap的底层原理呢?这些天,为了深入理解HashMap这一基础数据结构的底层原理,我阅读了大量的源码(包括 Java 7 和 Java 8)。在这篇文章中,我将解释HashMap的具体实现,展示它在 Java 8 中新的改变,讨论HashMap的性能、内存以及已知的问题。
内部存储方式
Java 的HashMap类实现了Map<K,V>接口,该接口的只要方法有:
-
V put(K key, V value) -
V get(K key, V value) -
V remove(K key, V value) -
Boolean containsKey(Object key)
HashMap使用内部类Entry<K, V>存储数据,该类存储了简单的键值对,以及另外的两个数据:
- 另一个
Entry类的引用。这样HashMap可以用单向链表的形式存储Entry实例。 key的哈希值。存储这个哈希值可以避免每次HashMap需要这个值的时候都重新计算一次
这里给出 Java 7 中Entry的实现:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
…
}
HashMap在以Entry对象为基本元素的单链表中保存数据(也被称作桶(buckets),或者箱(bins)),这些链表被连接到一个Entry数组中,这个内部数组的默认容量是16。

上图展示了一个HashMap对象的内部存储结构,可以看到,数组的元素是可以为空的。每一个Entry对象可以由链表和其他的Entry对象相连。
key的哈希值相同的Entry对象会被放到同一个桶中,然而,key的哈希值不同的Entry对象,也可能出现在一个桶中。
当用户调用put(K key, V value)或者get(Object key)方法时,这些方法首先会计算Entry对象所在桶的索引,然后,遍历桶中的链表,以key为依据来查找需要的Entry对象(使用key的equal()方法比较)。
使用get()时,如果Entry对象存在,返回的是Entry对象的value属性。
使用put()时,如果Entry对象存在,则更新原有的值;若不存在,则创建新的Entry对象,并将该对象加在对应链表的开头。
桶的索引由以下三步产生:
- 首先,生成
key的哈希码 - 然后,
rehashes上一步获得的哈希码,避免key的哈希函数产生的哈希值分布不均匀,而导致许多对象被放到同一个桶中 - 将
rehashes得到的值,与桶数组的长度(减一)做位掩码运算,这样就可以确保得到的索引不会比桶数组的长度大,可以把这一步看作是经过位运算优化的模运算。
这里给出 Java 7和 Java 8中,关于索引处理的源码:
// the "rehash" function in JAVA 7 that takes the hashcode of the key
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// the "rehash" function in JAVA 8 that directly takes the key
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// the function that returns the index from the rehashed hash
static int indexFor(int h, int length) {
return h & (length - 1);
}
为了保证高效,桶数组的长度会被设置为 2 的幂次,让我们看看这是为什么。
假设数组的长度是 17,那么用来做掩码的值也就是 16,16 的二进制表示为b0...010000,这样的话,由 16 做掩码产生的索引只可能是 0 或者 16。这也就意味着,长度为 17 的数组,只有索引为 0 和 16 的两个桶会被用到,显然这样并不高效。
如果数组的长度是 2 的幂次,比如 16,那么计算索引的表达式就是h & 15,15的二进制表示为b0...001111,这样前面的表达式的结构就可以是[0, 15]中的任何一个值,每一个桶都可能会被用到。例如
h = 925,它的二进制表示为b0...011 1011 1000,计算得到的索引也就是b1000= 8h = 1576,二进制表示为b0...110 0010 1000,索引为b1000= 8h = 12356146,二进制表示为b0...1011 1100 1000 1010 0011 0010,索引为0010= 2h = 59843,二进制表示为b0...1110 1001 1100 0011,索引为0011= 3
这就是数组长度为 2 的幂次的原因,这种机制对开发者是透明的,如果开发者创建大小为 37 的HashMap,哈希表中桶数组的大小会自动设置为大于 37 的 2 的幂次,也就是 64。
自动扩容
在得到了索引之后,相应的函数(get、put、remove)会遍历索引对应的链表,查找对于传入的key,是否存在一条对应的数据。然而,如果不改进,这样的机制可能会导致性能问题,因为为了查找一条数据是否存在,需要遍历整个链表。假设桶数组的长度是默认的 16,你需要存储 2 百万个值,最好的情况下,每个链表需要存储 125000 条数据,所以,每次调用get()、put()和remove()函数,都需要遍历 125000 个值。为了避免这种情况,HashMap会对桶数组自动扩容,以保证链表比较短。
当你使用以下构造方法创建HashMap时,你需要指定初始容量和负载因子:
public HashMap(int initialCapacity, float loadFactor)
如果你不指定参数,默认的初始容量是 16,负载因子是 0.75,初始容量指的是桶数组的大小。
每当你使用put()方法将一条数据放入哈希表中时,该方法会检查此时是否需要增加桶数组的长度,所以,哈希表需要存储以下两个数据:
- 哈希表的大小(
size):也就是当前哈希表中存储的总的数据的个数,每当一条数据被添加或者删除的时候,这个值都会更新。 - 门限(
threshold):该值等于桶数组的长度和负载因子的乘积,桶数组每次扩容之后,该值都会刷新。
在添加一个新的键值对之前,put(...)方法会检查size是否大于threshold,若是,将重新生成一个两倍于之前大小的桶数组。因为桶数组的大小改变了,计算索引值的函数(hash(key) & (sizeOfArray - 1))也就变了。所以扩容数组将桶的数量增加了一倍,之后,所有数据会被重新分配到这些桶中(包括旧的和新生成的)。
扩容操作的目的是减小链表的长度,这样可以使put()、remove()和get()方法时间效率保持较高的水准。扩容之后,key的哈希码相同的数据将会被放到同一个桶中,但是,哈希码不同数据,扩容之前可能在同一个桶中,扩容之后可能就不在同一个桶里面了。
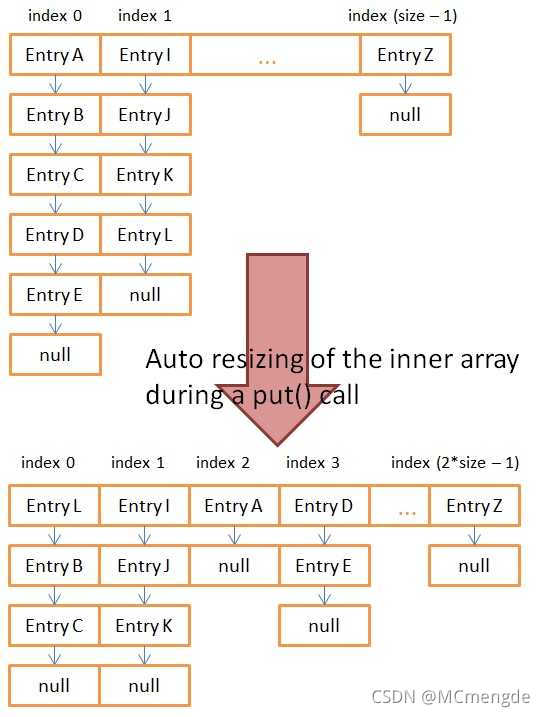
上图展示了桶数组扩容前后的变化。在扩容之前,要得到Entry E,需要遍历一个长度为 5 的链表;扩容之后,只需要遍历长度为 2 的链表就可以了,get()方法的速度快了两倍。
==注意:==哈希表只会增加桶数组的大小,并没有提供减小它的方法。
线程安全
如果你之前了解过HashMap,你一定知道它不是线程安全的,这是为什么呢?假设你有一个写线程,该线程只负责往哈希表中放入数据,还有一个读线程,它只负责从哈希表中读数据,这种方式会有什么问题呢?
在扩容期间,如果一个线程尝试读或者写数据,哈希表可能会使用旧的索引值,扩容完成之后,就找不到该数据对应的新桶是哪个了。
更坏的情况是,当两个线程同时写入数据,而put()方法同一时间被调用了 2 次,而这两次调用都触发了扩容操作。或者,每个线程会同时修改链表,某一个链表可能会最终变成一个循环链表,如果你尝试从循环链表里面获取数据,get()方法将进入死循环。
HashTable是一种线程安全的实现,可以避免以上情况,但是在HashTable中,增删改查的方法都被设置成了同步方法,大大减低了执行效率。例如,线程 1 调用get(key1);线程 2 调用get(key2);线程 3 调用get(key3),同一时间只有一个线程可以执行,然而它们并不冲突,是可以同时获取数据的。
一个更好的线程安全的哈希表实现在 Java 5中出现:ConcurrentHashMap。在该数据结构中,只有桶被设置为同步结构,所以只要数据不在同一个桶中,且没有执行扩容操作,不同的线程就可以同时使用get()、remove()或者put()方法操作数据。在多线程的应用中,使用ConcurrentHashMap是更好的选择。
Key的不变性
为什么说字符串和整型很适合做哈希表的key呢?因为它们是不变的!如果你选择了自己实现的类作为哈希表的key,并且没有将该类设置成不变的,你可能会丢失哈希表中的数据。
请看以下用例:
- 你有一个
key,它拥有一个成员变量 “1” - 你将由该
key组成的数据放入了哈希表 - 哈希表由这个
key(“1”)的哈希码生成了一个哈希值 - 哈希表存储了新创建的数据
- 之后,你将
key的该成员变量的值改为了 “2” - 这个
key的哈希值也将随之改变,但是哈希表并不知道这一变化(哈希表还是存储的之前的值) - 你尝试通过修之后的
key获取数据 - 哈希表通过你给的
key(“2”)计算了新的哈希值,然后去寻找该数据- 第一种情况:因为你修改了
key,哈希表在错误的桶中查找该数据,然后没有找到 - 第二种情况:很幸运,修改之后的
key和之前的key生成了一样的索引,找到了之前的桶。但是,在查找key的时候,首先需要比较哈希值,然后调用equals()方法做比较。由于被你修改的key的哈希值和之前(存储在表中的)的哈希值不一样,同样也找不到数据
- 第一种情况:因为你修改了
这里有一个具体的例子,我在哈希表中放了两个键值对,我修改了第一个key,然后去取这两个值,结构只取到了第二个,第一个在哈希表中丢失了:
public class MutableKeyTest {
public static void main(String[] args) {
class MyKey {
Integer i;
public void setI(Integer i) {
this.i = i;
}
public MyKey(Integer i) {
this.i = i;
}
@Override
public int hashCode() {
return i;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof MyKey) {
return i.equals(((MyKey) obj).i);
} else
return false;
}
}
Map<MyKey, String> myMap = new HashMap<>();
MyKey key1 = new MyKey(1);
MyKey key2 = new MyKey(2);
myMap.put(key1, "test " + 1);
myMap.put(key2, "test " + 2);
// modifying key1
key1.setI(3);
String test1 = myMap.get(key1);
String test2 = myMap.get(key2);
System.out.println("test1= " + test1 + " test2=" + test2);
}
}
上面代码的输出为:“test1 = null test2 = test 2”,不出意料,哈希表使用修改之后的key1找不到之前的字符串了。
Java 8 中的改进
在Java 8 中,HashMap的内部表示改变了很多,事实上,Java 7 中的实现用了一千行代码,而 Java 8 中的实现用了两千行。除了链表,我上面讲的大部分都没有问题。在 Java 8 中,桶数组依然存在,但是被用来存储Node对象,Node中存储的信息和Entry中一样,所以他们依然是链表:
这里给出 Java 8 中Node的部分实现:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
所以,和 Java 7 中不同的到底是什么呢?那就是,Node可以被拓展成TreeNode。TreeNode是红黑树的结点,其中存储了很多的信息,以确保红黑树可以在O(log(n))的时间复杂度内增加、删除或者查询一个元素。
这里给出TreeNode中存储的全部数据,以供参考
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
final int hash; // inherited from Node<K,V>
final K key; // inherited from Node<K,V>
V value; // inherited from Node<K,V>
Node<K,V> next; // inherited from Node<K,V>
Entry<K,V> before, after;// inherited from LinkedHashMap.Entry<K,V>
TreeNode<K,V> parent;
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev;
boolean red;
...
}
红黑树是一种自平衡的二叉查找树,它的内部机制保证在添加或删除结点的过程中,它的高度始终是log(n)。使用红黑树的主要好处就是,当很多数据在同一个桶中的时候,查找一个结点的时间为O(log(n)),倘若使用链表的话,会花费O(n)的时间。
如你所见,红黑树需要更多的空间(我们会在下一个部分讨论这个)。
为了兼容,内部桶数组会同时包含链表结点Node和红黑树结点TreeNode,Oracle 决定根据以下规则同时使用两个数据结构:
- 如果同一个桶中的结点数大于 8,链表就会转化为红黑树。
- 如果桶中的结点数小于 6,红黑树就会退化为链表。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6escd2k7-1631175480540)(HashMap的工作原理.assets/internal_storage_java8_hashmap.jpg)]](https://img-blog.csdnimg.cn/103ef24860424ea7b502035b10236c7b.jpg?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATUNtZW5nZGU=,size_20,color_FFFFFF,t_70,g_se,x_16)
上图中表示了 Java 8 中,桶数组中同时包含红黑树(0)和链表(1, 2, 3)的情况,因为 0 号桶中的结点数已经大于 8 了,所以它转变成了红黑树。
内存开销
Java 7
使用HashMap是需要耗费内存的,Java 7 中,键值对存储在Entry中,每个Entry对象含有以下数据:
- 下一个结点的引用(reference)
- 预先计算的哈希(整型)
key的引用value的引用
而且,Java 7 中使用内部数组存储Entry对象,假设 Java 7 中的HashMap包含 N 个元素,它的内部数组的长度为CAPACITY,那么额外的内存消耗大概是:
s
i
z
e
O
f
(
i
n
t
)
∗
N
+
s
i
z
e
O
f
(
r
e
f
e
r
e
n
c
e
)
∗
(
3
∗
N
+
C
)
sizeOf(int) * N + sizeOf(reference) * (3 * N + C)
sizeOf(int)∗N+sizeOf(reference)∗(3∗N+C)
其中:
- 整形的长度为 4 字节
- 引用(reference)的长度可能和 JVM/OS/Processor 有关,通常是 4 字节
也就是说,内存开销通常是$16 * N + 4 * CAPACITY $
值得注意的是:在自动扩容之后,内部数组的长度是刚好大于 N 的 2 的幂次。
值得一提:在 Java 7 之后,HashMap采用懒加载机制,也就是说,即便你初始化了一个HashMap,其内部数组也要等到第一次调用put()方法的时候才会分配内存。
Java 8
在 Java 8 的实现中,内存分配变得有些复杂了,因为一个Node对象可能存有和Entry对象一样的数据,而当它是TreeNode对象时,就会多出 6 个引用和一个布尔类型。
如果哈希表所有的结点都是链表结点(Node),那么在 Java 8 中的内存消耗和 Java 7 中是一样的。
如果所有的结点都是红黑树结点(TreeNode),那么 Java 8 中的内存消耗变为:
N
∗
s
i
z
e
O
f
(
i
n
t
)
+
N
∗
s
i
z
e
O
f
(
b
o
o
l
e
a
n
)
+
s
i
z
e
O
f
(
r
e
f
e
r
e
n
c
e
)
∗
(
9
∗
N
+
C
A
P
A
C
I
T
Y
)
N * sizeOf(int) + N * sizeOf(boolean) + sizeOf(reference) * (9 * N + CAPACITY)
N∗sizeOf(int)+N∗sizeOf(boolean)+sizeOf(reference)∗(9∗N+CAPACITY)
对于大多数标准的 JVM,以上表达式等于
44
∗
N
+
4
∗
C
A
P
A
C
I
T
Y
44 * N + 4 * CAPACITY
44∗N+4∗CAPACITY 个字节。
性能问题
倾斜的HashMap和平衡的HashMap
在最好的情况下,get()方法和put()方法的时间复杂度是O(1),但是如果不注意key的哈希函数,你调用put()方法和get()方法可能会很慢。好的性能依赖于数据的均匀分布,如果所使用的key使用一个糟糕的哈希函数,你构造的哈希表中的数据就会倾斜分布(无论你的桶数组有多大),所有需要遍历长链表的put()和get()方法都会很慢。最坏的情况下(大多数数据都分布到了同一个桶中),时间复杂度可能是O(n)。
下面给出可视化的例子,下图一为倾斜的哈希表,图二为平衡的哈希表。

这种情况下,对于倾斜的哈希表,get()/put()方法在操作 0 号桶的时候耗时较多,取得Entry K需要遍历 6 条数据。
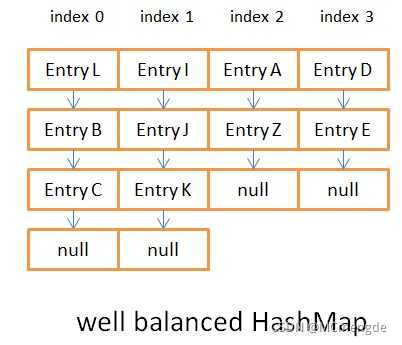
这样平衡度较好的哈希表中,取得Entry K只需要遍历 3 条数据,所有的桶保存的数据量都大致相等。区别就在于key的哈希码生成函数,它决定了数据在各个桶中的分布。
这里有一个极端的例子,我写了一个哈希函数,把所有的数据都放到同一个桶中,然后在哈希表中放入两百万条数据:
public class Test {
public static void main(String[] args) {
class MyKey {
Integer i;
public MyKey(Integer i){
this.i =i;
}
@Override
public int hashCode() {
return 1;
}
@Override
public boolean equals(Object obj) {
…
}
}
Date begin = new Date();
Map <MyKey,String> myMap= new HashMap<>(2_500_000,1);
for (int i=0;i<2_000_000;i++){
myMap.put( new MyKey(i), "test "+i);
}
Date end = new Date();
System.out.println("Duration (ms) "+ (end.getTime()-begin.getTime()));
}
}
在我的机器上(i5-2500k @ 3.6Ghz),跑了 45 分钟都没有结束(45 分钟之后我把程序停掉了)。
现在,我将上面的哈希函数改为下面这个,其他代码不变
@Override
public int hashCode() {
int key = 2097152 - 1;
return key + 2097152 * i;
}
之需要 46 秒就完成了,性能提升显而易见,下面的哈希函数将数据更均匀的分配到不同的桶中,所以put()方法更快了。
当我只用以下哈希函数时,它可以产生分布更均匀的哈希码
@Override
public int hashCode() {
return i;
}
现在只需要 2 秒。
我希望你能够意思到哈希函数的重要性,倘若在 Java 7 中做以上测试,前两个例子的表现会更差(因为 Java 7 中put()方法的时间复杂度时O(n),而 Java 8 中是O(log(n))。
当使用哈希表时,你需要为你的key寻找一个能将数据尽可能均匀分布到各个桶中的哈希函数,应该尽量避免哈希碰撞。字符串类型就很适合做key,因为它的哈希函数很好,整型也是一个不错的选择,因为它的哈希码就是它自己的值。
扩容开销
如果你需要存储大量数据,你应该在创建哈希表的时候指定其容量为你期望的大小。
如果你不指明初始容量,哈希表就会使用默认的容量 16,默认的负载因子 0.75。前 11 次 put() 会很快,但是第 12(16 * 0.75) 次调用的时候,就需要重建一个大小为 32 的内部数组(包含与数组项相关的链表或红黑树),接下来的 13 到 23 次调用会很快,但是到了第 24(32 * 0.75) 次时,又得重新分配一个两倍大小的数组,内部的扩容操作将在第48次、96次、192次调用put()方法时发生。桶数量较小时,重新分配可能很快,但是当桶数量多起来的时候,重新分配数组可能会需要几秒到几分钟不等。如果一开始就指定好了初始容量,就可以避免这些耗时的扩容操作。
但是这也有一个弊病:如果你将初始化容量设置为一个很大的值,例如 2 的 18 次方,但是你只使用其中的 2 的 16 次个桶,就会浪费大量的内存(这个例子中浪费了 2 的 30 次方个字节)。
总结
对于简单的使用,你可能不需要了解HashMap的工作原理,因为你察觉不到O(1)、O(n)和O(log(n))之间的区别,但是理解所用的数据结构的底层原理总归是有好处的。另外,对于 Java 开发者,这些都是经典的面试问题。
当数据很多的时候,知道工作原理以及哈希函数的重要性就很有必要了。
希望本文可以帮你更深入地理解HashMap的实现。
原文链接:How does a HashMap work in JAVA | Coding Geek (coding-geek.com)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)