解决数据库高并发访问瓶颈问题
一、缓存式的Web应用程序架构:
在Web层和db层之间加一层cache层,主要目的:减少数据库读取负担,提高数据读取速度。cache存取的媒介是内存,可以考虑采用分布式的cache层,这样更容易破除内存容量的限制,同时增加了灵活性。
二、业务拆分:
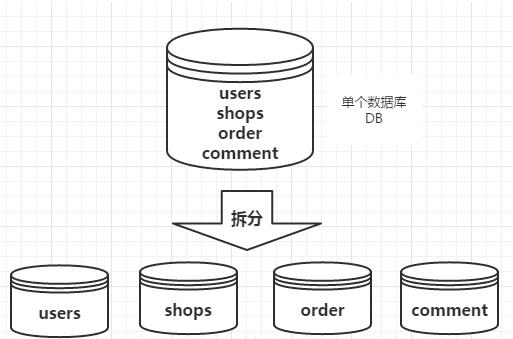
电商平台,包含了用户、商品、评价、订单等几大模块,最简单的做法就是在一个数据库中分别创建users、shops、comment、order四张表。
但是,随着业务规模的增大,访问量的增大,我们不得不对业务进行拆分。每一个模块都使用单独的数据库来进行存储,不同的业务访问不同的数据库,将原本对一个数据库的依赖拆分为对4个数据库的依赖,这样的话就变成了4个数据库同时承担压力,系统的吞吐量自然就提高了。
三、MySQL主从复制,读写分离:
当数据库的写压力增加,cache层(如Memcached)只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负。使用主从复制技术(master-slave模式)来达到读写分离,以提高读写性能和读库的可扩展性。读写分离就是只在主服务器上写,只在从服务器上读,基本原理是让主数据库处理事务性查询,而从数据库处理select查询,数据库复制被用于把事务性查询(增删改)导致的改变更新同步到集群中的从数据库。
MySQL读写分离提升系统性能:
1、主从只负责各自的读和写,极大程度缓解X锁和S锁争用。
2、slave可以配置MyISAM引擎,提升查询性能以及节约系统开销。
3、master直接写是并发的,slave通过主库发送来的binlog恢复数据是异步的。
4、slave可以单独设置一些参数来提升其读的性能。
5、增加冗余,提高可用性。
实现主从分离可以使用MySQL中间件如:Atlas
MySQL主从复制的原理:数据复制的实际就是Slave从Master获取Binary log文件,然后再本地镜像的执行日志中记录的操作。由于主从复制的过程是异步的,因此Slave和Master之间的数据有可能存在延迟的现象,此时只能保证数据最终的一致性。
四、分表分库:
在cache层的高速缓存,MySQL的主从复制,读写分离的基础上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM。采用Master-Slave复制模式的MySQL架构,只能对数据库的读进行扩展,而对数据的写操作还是集中在Master上。这时需要对数据库的吞吐能力进一步地扩展,以满足高并发访问与海量数据存储的需求。
对于访问极为频繁且数据量巨大的单表来说,首先要做的是减少单表的记录条数,以便减少数据查询所需的时间,提高数据库的吞吐,这就是所谓的分表。在分表之前,首先需要选择适当的分表策略,使得数据能够较为均衡地分布到多张表中,并且不影响正常的查询。
分表能够解决单表数据量过大带来的查询效率下降的问题,但是却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库master服务器无法承载写操作压力时,不管如何扩展Slave服务器都是没有意义的,对数据库进行拆分,从而提高数据库写入能力,即分库。
数据库经过业务拆分及分库分表,虽然查询性能和并发处理能力提高了。但是原本跨表的事务上升为分布式事务;由于记录被切分到不同的库和不同的表中,难以进行多表关联查询,并且不能不指定路由字段对数据进行查询。且分库分表后需要进一步对系统进行扩容(路由策略变更)将变得非常不方便,需要重新进行数据迁移。
分表策略:
使用用户ID是最常用的分库的路由策略。
当数据比较大的时候,对数据进行分表操作,首先要确定需要将数据平均分配到多少张表中,也就是:表容量。
这里假设有100张表进行存储,则我们在进行存储数据的时候,首先对用户ID进行取模操作,根据 user_id%100 获取对应的表进行存储查询操作。
在实际的开发中,我们的用户ID更多的可能是通过UUID生成的,这样的话,我们可以首先将UUID进行hash获取到整数值,然后在进行取模操作。
分库策略:
数据库分表能够解决单表数据量很大的时候数据查询的效率问题,但是无法给数据库的并发操作带来效率上的提高,因为分表的实质还是在一个数据库上进行的操作,很容易受数据库IO性能的限制。
因此,如何将数据库IO性能的问题平均分配出来,很显然将数据进行分库操作可以很好地解决单台数据库的性能问题。
分库策略与分表策略的实现很相似,最简单的都是可以通过取模的方式进行路由。
分库与分表实现策略:
上述的配置中,数据库分表可以解决单表海量数据的查询性能问题,分库可以解决单台数据库的并发访问压力问题。
有时候,我们需要同时考虑这两个问题,因此,我们既需要对单表进行分表操作,还需要进行分库操作,以便同时扩展系统的并发处理能力和提升单表的查询性能,就是我们使用到的分库分表。
分库分表的策略相对于前边两种复杂一些,一种常见的路由策略如下:
1、中间变量 = user_id%(库数量*每个库的表数量);
2、库序号 = 取整(中间变量/每个库的表数量);
3、表序号 = 中间变量%每个库的表数量;
参考:
https://blog.csdn.net/u010832551/article/details/77836681

 浙公网安备 33010602011771号
浙公网安备 33010602011771号