awk命令
数据处理工具
常用于将一行分成数个字段来处理
awk的工作原理
awk 'BEGIN{ commands } pattern{ commands } END{ commands }'
- 第一步:执行
BEGIN{ commands }语句块中的语句; - 第二步:从文件或标准输入(stdin)读取一行,然后执行
pattern{ commands }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。 - 第三步:当读至输入流末尾时,执行
END{ commands }语句块。
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中。
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块。
pattern语句块中的通用命令是最重要的部分,它也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块。
示例
echo -e "A line 1nA line 2" | awk 'BEGIN{ print "Start" } { print } END{ print "End" }'
Start
A line 1
A line 2
End
awk内置变量(预定义变量)
$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$0 这个变量包含执行过程中当前行的文本内容。
FS 字段分隔符(默认是任何空格)。
NF 表示字段数,在执行过程中对应于当前的字段数。
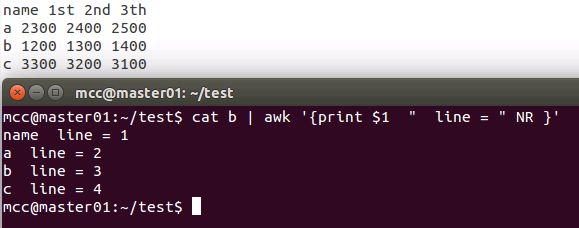
NR 表示记录数,在执行过程中对应于当前的行号。
![]()
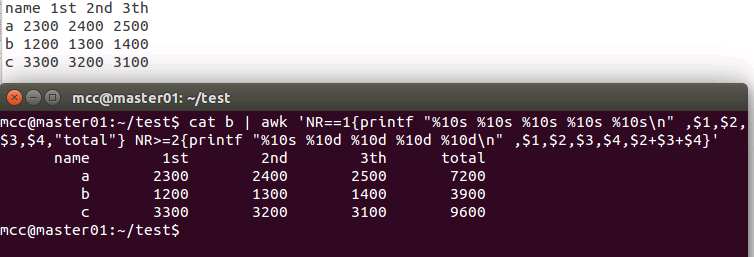
cat b | awk 'NR==1{printf "%10s %10s %10s %10s %10s\n" ,$1,$2,$3,$4,"total"} NR>=2{printf "%10s %10d %10d %10d %10d\n" ,$1,$2,$3,$4,$2+$3+$4}'
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号