TCP和UDP
TCP(Transmission Control Protocol 传输控制协议)
面向连接,提供可靠的服务,无重复、无丢失、无差错,面向字节流,只能是点对点,首部 20 字节,全双工。
UDP(User Datagram Protocol用户数据报协议)
无连接,尽最大努力交付,面向报文, 支持一对一、一对多、多对多,首部 8 字节。
怎么用 udp 实现 tcp:
由于在传输层 udp 已经是不可靠的,那就要在应用层自己实现一 些保证可靠传输的机制,
简单来说,要使用 udp 来构建可靠的面向连接的数据传输,就要实现类似于 tcp 的超时重传(定时器),拥塞控制(滑动窗口),有序接收(添加包序号), 应答确认(ack 和 seq)。
目前已经有了实现 udp 可靠运输的机制——udt:主要目的高速广 域网海量数据传输,他是应用层协议。
tcp 如何保证传输的可靠性?
tcp 是面向连接,可靠的字节流服务。
面向连接意味着两个使用 tcp 的应用(通常是一个客户端和一个服务器)在彼此交换数据之前必须先建立一个 tcp 连接。
在一个 tcp 连接中,仅有两方进行彼此通信,广播和多播 不能用于 tcp。
Tcp 通过下列方式提供可靠性:
将应用数据分割为 tcp 认为最合适发送的数据块;
确认机制:当 tcp 收到发自 tcp 链接另一端的数据时,它将发送一个确认(对于收到的请求,给出确认响应)。
超时重传:当 tcp 发出一个段后,他启动一个定时器,等待目的端确认收到这个报文段。若不能及时收到一个确认,将重发这个报文段。
若 tcp 收到包,校验出包有错,丢弃报文段,不给出响应, tcp 发送端会超时重传;
对于重复数据,直接丢弃。
对于失序数据进行重新排序,然后交给应用层(tcp 报文段作为 ip 数据报进行传输, 而 ip 数据报的到达会失序,因此 tcp 报文段的到达也可能失序。若必要, tcp 将对收到的数 据进行重新排列,以正确的顺序交给应用层)。
流量控制:tcp 可以进行流量控制,防止较快主机致使较慢主机的缓冲区溢出。
拥塞控制:当网络拥塞时,减少数据的发送
字节流服务:
两个应用程序通过 tcp 连接, tcp 不在字节中插入记录标识符,我们将这种称为字节流服务。
Tcp 对字节流的内容不做任何解释,tcp 不知道传输的字节流数据是二进制数据还是 ascii 字符或其他类型数据,对字节流的解释由 tcp 连接双方的应用层。
面向报文:
面向报文的传输方式是应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。
Tcp:
流量控制:防止较快主机使较慢主机缓冲区溢出,是点对点;
拥塞控制: 全局性,防止过多的数据注入网络。慢开始、拥塞避免、快重传、快恢复。
tcp 采用滑动窗口进行流量控制,滑动窗口大小可变,窗口大小的单位是字节。
发送窗口在连接建立时由双方确定,但在通信过程中,接收端可以根据自己的资源情况, 随时动态的调整对方的发送窗口上限制。
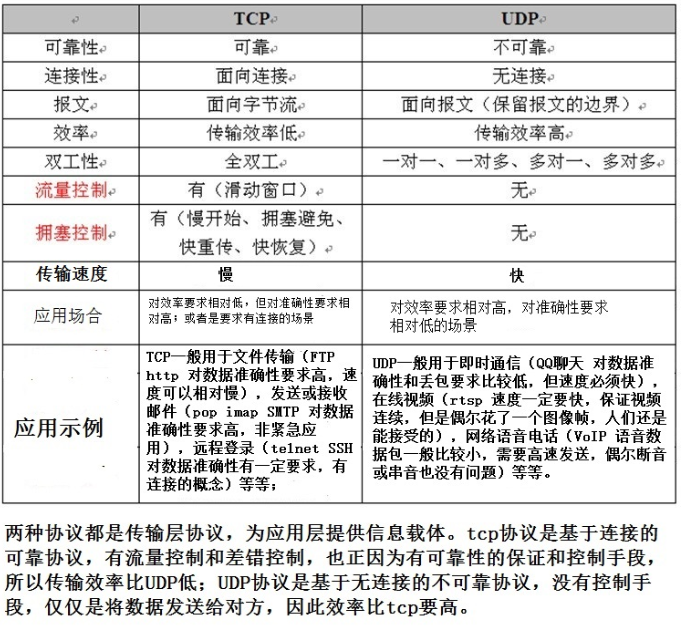
TCP和UDP的区别:
TCP/UDP编程模型:
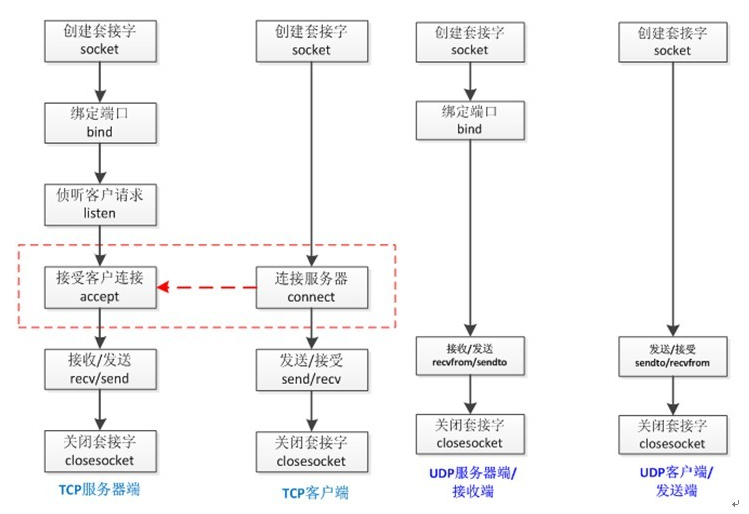
具体编程时的区别:
socket()的参数不同
UDP Server不需要调用listen和accept
UDP收发数据用sendto/recvfrom函数
TCP:地址信息在connect/accept时确定
UDP:在sendto/recvfrom函数中每次均 需指定地址信息
UDP:shutdown函数无效
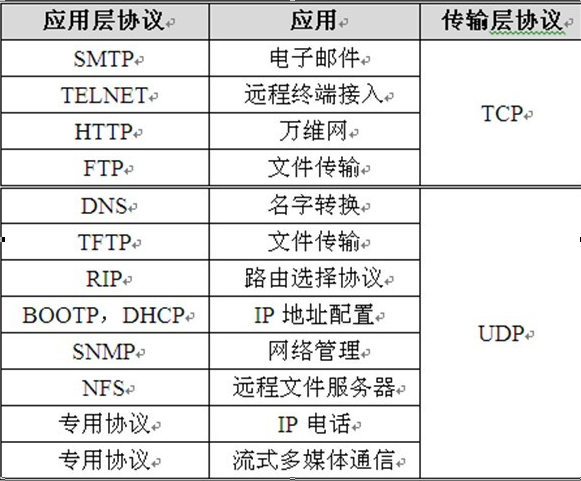
TCP和UDP协议的一些应用:
TCP面向字节流
打个比方比喻TCP,你家里有个蓄水池,你可以里面倒水,蓄水池上有个龙头,你可以通过龙头将水池里的水放出来,然后用各种各样的容器装(杯子、矿泉水瓶、锅碗瓢盆)接水。
上面的例子中,往水池里倒几次水和接几次水是没有必然联系的,也就是说你可以只倒一次水,然后分10次接完。另外,水池里的水接多少就会少多少;往里面倒多少水,就会增加多少水,但是不能超过水池的容量,多出的水会溢出。
结合TCP的概念,水池就好比接收缓存,倒水就相当于发送数据,接水就相当于读取数据。好比你通过TCP连接给另一端发送数据,你只调用了一次write,发送了100个字节,但是对方可以分10次收完,每次10个字节;你也可以调用10次write,每次10个字节,但是对方可以一次就收完。(假设数据都能到达)但是,你发送的数据量不能大于对方的接收缓存(流量控制),如果你硬是要发送过量数据,则对方的缓存满了就会把多出的数据丢弃。
UDP面向报文
UDP和TCP不同,发送端调用了几次write,接收端必须用相同次数的read读完。UPD是基于报文的,在接收的时候,每次最多只能读取一个报文,报文和报文是不会合并的,如果缓冲区小于报文长度,则多出的部分会被丢弃。也就说,如果不指定MSG_PEEK标志,每次读取操作将消耗一个报文。
原因
其实,这种不同是由TCP和UDP的特性决定的。TCP是面向连接的,也就是说,在连接持续的过程中,socket中收到的数据都是由同一台主机发出的(劫持什么的不考虑),因此,知道保证数据是有序的到达就行了,至于每次读取多少数据自己看着办。
而UDP是无连接的协议,也就是说,只要知道接收端的IP和端口,且网络是可达的,任何主机都可以向接收端发送数据。这时候,如果一次能读取超过一个报文的数据,则会乱套。比如,主机A向发送了报文P1,主机B发送了报文P2,如果能够读取超过一个报文的数据,那么就会将P1和P2的数据合并在了一起,这样的数据是没有意义的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号