Redis cluster集群模式的原理
redis cluster
redis cluster是Redis的分布式解决方案,在3.0版本推出后有效地解决了redis分布式方面的需求
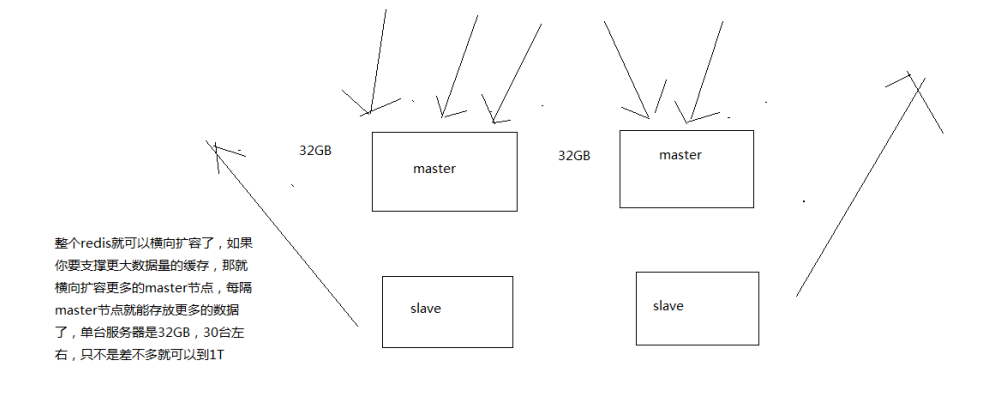
自动将数据进行分片,每个master上放一部分数据
提供内置的高可用支持,部分master不可用时,还是可以继续工作的
支撑N个redis master node,每个master node都可以挂载多个slave node
高可用,因为每个master都有salve节点,那么如果mater挂掉,redis cluster这套机制,就会自动将某个slave切换成master
redis cluster vs. replication + sentinal
如果你的数据量很少,主要是承载高并发高性能的场景,比如你的缓存一般就几个G,单机足够了
replication,一个mater,多个slave,要几个slave跟你的要求的读吞吐量有关系,然后自己搭建一个sentinal集群,去保证redis主从架构的高可用性,就可以了
redis cluster,主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster
数据分布算法
hash算法
比如你有 N 个 redis实例,那么如何将一个key映射到redis上呢,你很可能会采用类似下面的通用方法计算 key的 hash 值,然后均匀的映射到到 N 个 redis上:
hash(key)%N
如果增加一个redis,映射公式变成了 hash(key)%(N+1)
如果一个redis宕机了,映射公式变成了 hash(key)%(N-1)
在这两种情况下,几乎所有的缓存都失效了。会导致数据库访问的压力陡增,严重情况,还可能导致数据库宕机。
一致性hash算法
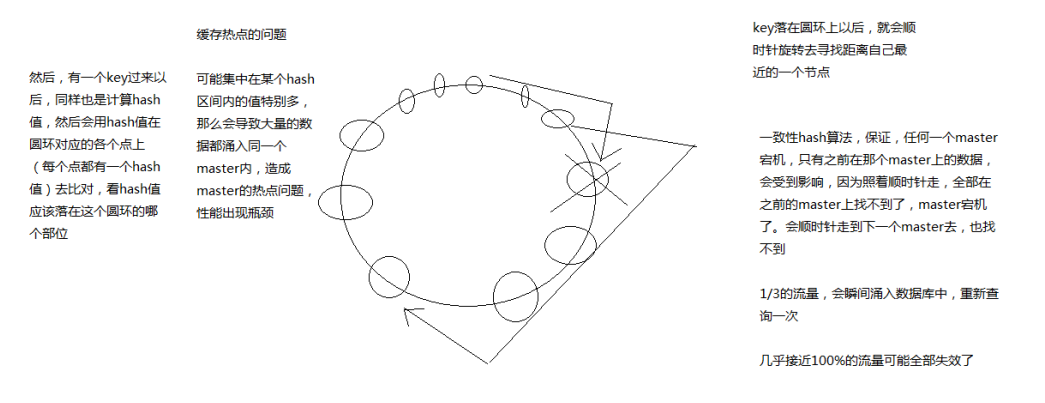
一个master宕机不会导致大部分缓存失效,可能存在缓存热点问题
用虚拟节点改进
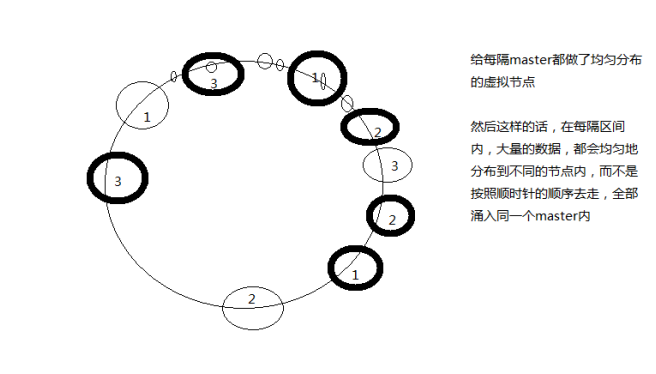
redis cluster的hash slot算法
redis cluster有固定的16384个hash slot,对每个key计算CRC16值,然后对16384取模,可以获取key对应的hash slot
redis cluster中每个master都会持有部分slot,比如有3个master,那么可能每个master持有5000多个hash slot
hash slot让node的增加和移除很简单,增加一个master,就将其他master的hash slot移动部分过去,减少一个master,就将它的hash slot移动到其他master上去
移动hash slot的成本是非常低的
客户端的api,可以对指定的数据,让他们走同一个hash slot,通过hash tag来实现
127.0.0.1:7000>CLUSTER ADDSLOTS 0 1 2 3 4 ... 5000 可以将槽0-5000指派给节点7000负责。
每个节点都会记录哪些槽指派给了自己,哪些槽指派给了其他节点。
客户端向节点发送键命令,节点要计算这个键属于哪个槽。
如果是自己负责这个槽,那么直接执行命令,如果不是,向客户端返回一个MOVED错误,指引客户端转向正确的节点。
redis cluster 多master的写入
在redis cluster写入数据的时候,其实是你可以将请求发送到任意一个master上去执行
但是,每个master都会计算这个key对应的CRC16值,然后对16384个hashslot取模,找到key对应的hashslot,找到hashslot对应的master
如果对应的master就在自己本地的话,set mykey1 v1,mykey1这个key对应的hashslot就在自己本地,那么自己就处理掉了
但是如果计算出来的hashslot在其他master上,那么就会给客户端返回一个moved error,告诉你,你得到哪个master上去执行这条写入的命令
什么叫做多master的写入,就是每条数据只能存在于一个master上,不同的master负责存储不同的数据,分布式的数据存储
100w条数据,5个master,每个master就负责存储20w条数据,分布式数据存储
默认情况下,redis cluster的核心的理念,主要是用slave做高可用的,每个master挂一两个slave,主要是做数据的热备,还有master故障时的主备切换,实现高可用的
redis cluster默认是不支持slave节点读或者写的,跟我们手动基于replication搭建的主从架构不一样的
jedis客户端,对redis cluster的读写分离支持不太好的
默认的话就是读和写都到master上去执行的
如果你要让最流行的jedis做redis cluster的读写分离的访问,那可能还得自己修改一点jedis的源码,成本比较高
读写分离,是为了什么,主要是因为要建立一主多从的架构,才能横向任意扩展slave node去支撑更大的读吞吐量
redis cluster的架构下,实际上本身master就是可以任意扩展的,你如果要支撑更大的读吞吐量,或者写吞吐量,或者数据量,都可以直接对master进行横向扩展就可以了
节点间的内部通信机制
1、基础通信原理
(1)redis cluster节点间采取gossip协议进行通信
跟集中式不同,不是将集群元数据(节点信息,故障,等等)集中存储在某个节点上,而是互相之间不断通信,保持整个集群所有节点的数据是完整的
集中式:好处在于,元数据的更新和读取,时效性非常好,一旦元数据出现了变更,立即就更新到集中式的存储中,其他节点读取的时候立即就可以感知到; 不好在于,所有的元数据的跟新压力全部集中在一个地方,可能会导致元数据的存储有压力
gossip:好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力; 缺点,元数据更新有延时,可能导致集群的一些操作会有一些滞后
(2)10000端口
每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如7001,那么用于节点间通信的就是17001端口
每隔节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几点接收到ping之后返回pong
(3)交换的信息
故障信息,节点的增加和移除,hash slot信息,等等
2、gossip协议
gossip协议包含多种消息,包括ping,pong,meet,fail,等等
meet: 某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信
redis-trib.rb add-node
其实内部就是发送了一个gossip meet消息,给新加入的节点,通知那个节点去加入我们的集群
ping: 每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据
每个节点每秒都会频繁发送ping给其他的集群,ping,频繁的互相之间交换数据,互相进行元数据的更新
pong: 返回ping和meet,包含自己的状态和其他信息,也可以用于信息广播和更新
fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了
3、ping消息深入
ping很频繁,而且要携带一些元数据,所以可能会加重网络负担
每个节点每秒会执行10次ping,每次会选择5个最久没有通信的其他节点
当然如果发现某个节点通信延时达到了cluster_node_timeout / 2,那么立即发送ping,避免数据交换延时过长,落后的时间太长了
比如说,两个节点之间都10分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题
所以cluster_node_timeout可以调节,如果调节比较大,那么会降低发送的频率
每次ping,一个是带上自己节点的信息,还有就是带上1/10其他节点的信息,发送出去,进行数据交换
至少包含3个其他节点的信息,最多包含总节点-2个其他节点的信息
基于重定向的客户端
(1)请求重定向
客户端可能会挑选任意一个redis实例去发送命令,每个redis实例接收到命令,都会计算key对应的hash slot
如果在本地就在本地处理,否则返回moved给客户端,让客户端进行重定向
cluster keyslot mykey,可以查看一个key对应的hash slot是什么
用redis-cli的时候,可以加入-c参数,支持自动的请求重定向,redis-cli接收到moved之后,会自动重定向到对应的节点执行命令
(2)计算hash slot
计算hash slot的算法,就是根据key计算CRC16值,然后对16384取模,拿到对应的hash slot
用hash tag可以手动指定key对应的slot,同一个hash tag下的key,都会在一个hash slot中,比如set mykey1:{100}和set mykey2:{100}
(3)hash slot查找
节点间通过gossip协议进行数据交换,就知道每个hash slot在哪个节点上
smart jedis
(1)什么是smart jedis
基于重定向的客户端,很消耗网络IO,因为大部分情况下,可能都会出现一次请求重定向,才能找到正确的节点
所以大部分的客户端,比如java redis客户端,就是jedis,都是smart的
本地维护一份hashslot -> node的映射表,缓存,大部分情况下,直接走本地缓存就可以找到hashslot -> node,不需要通过节点进行moved重定向
(2)JedisCluster的工作原理
在JedisCluster初始化的时候,就会随机选择一个node,初始化hashslot -> node映射表,同时为每个节点创建一个JedisPool连接池
每次基于JedisCluster执行操作,首先JedisCluster都会在本地计算key的hashslot,然后在本地映射表找到对应的节点
如果那个node正好还是持有那个hashslot,那么就ok; 如果说进行了reshard这样的操作,可能hashslot已经不在那个node上了,就会返回moved
如果JedisCluter API发现对应的节点返回moved,那么利用该节点的元数据,更新本地的hashslot -> node映射表缓存
重复上面几个步骤,直到找到对应的节点,如果重试超过5次,那么就报错,JedisClusterMaxRedirectionException
jedis老版本,可能会出现在集群某个节点故障还没完成自动切换恢复时,频繁更新hash slot,频繁ping节点检查活跃,导致大量网络IO开销
jedis最新版本,对于这些过度的hash slot更新和ping,都进行了优化,避免了类似问题
(3)hashslot迁移和ask重定向
如果hash slot正在迁移,那么会返回ask重定向给jedis
jedis接收到ask重定向之后,会重新定位到目标节点去执行,但是因为ask发生在hash slot迁移过程中,所以JedisCluster API收到ask是不会更新hashslot本地缓存
已经可以确定说,hashslot已经迁移完了,moved是会更新本地hashslot->node映射表缓存的
高可用性与主备切换原理
redis cluster的高可用的原理,几乎跟哨兵是类似的
1、判断节点宕机
如果一个节点认为另外一个节点宕机,那么就是pfail,主观宕机
如果多个节点都认为另外一个节点宕机了,那么就是fail,客观宕机,跟哨兵的原理几乎一样,sdown,odown
在cluster-node-timeout内,某个节点一直没有返回pong,那么就被认为pfail
如果一个节点认为某个节点pfail了,那么会在gossip ping消息中,ping给其他节点,如果超过半数的节点都认为pfail了,那么就会变成fail
2、从节点过滤
对宕机的master node,从其所有的slave node中,选择一个切换成master node
检查每个slave node与master node断开连接的时间,如果超过了cluster-node-timeout * cluster-slave-validity-factor,那么就没有资格切换成master
这个也是跟哨兵是一样的,从节点超时过滤的步骤
3、从节点选举
哨兵:对所有从节点进行排序,slave priority,offset,run id
每个从节点,都根据自己对master复制数据的offset,来设置一个选举时间,offset越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举
所有的master node开始slave选举投票,给要进行选举的slave进行投票,如果大部分master node(N/2 + 1)都投票给了某个从节点,那么选举通过,那个从节点可以切换成master
从节点执行主备切换,从节点切换为主节点
4、与哨兵比较
整个流程跟哨兵相比,非常类似,所以说,redis cluster功能强大,直接集成了replication和sentinal的功能
转自:中华石杉Java工程师面试突击

 浙公网安备 33010602011771号
浙公网安备 33010602011771号