行转列,值转换成列
1. 值转换成列操作。值转列操作:[1777题库]
值转换成列 ,也可以用pivot 函数 是hive3 里面新增的函数.



表:Products +-------------+---------+ | Column Name | Type | +-------------+---------+ | product_id | int | | store | enum | | price | int | +-------------+---------+ 在 SQL 中,(product_id,store) 是这个表的主键。 store 字段是枚举类型,它的取值为以下三种 ('store1', 'store2', 'store3') 。 price 是该商品在这家商店中的价格。 找出每种产品在各个商店中的价格。 可以以 任何顺序 输出结果。 返回结果格式如下例所示。 示例 1: 输入: Products 表: +-------------+--------+-------+ | product_id | store | price | +-------------+--------+-------+ | 0 | store1 | 95 | | 0 | store3 | 105 | | 0 | store2 | 100 | | 1 | store1 | 70 | | 1 | store3 | 80 | +-------------+--------+-------+ 输出: +-------------+--------+--------+--------+ | product_id | store1 | store2 | store3 | +-------------+--------+--------+--------+ | 0 | 95 | 100 | 105 | | 1 | 70 | null | 80 | +-------------+--------+--------+--------+ 解释: 产品 0 的价格在商店 1 为 95 ,商店 2 为 100 ,商店 3 为 105 。 产品 1 的价格在商店 1 为 70 ,商店 3 的产品 1 价格为 80 ,但在商店 2 中没有销售。
====方法1====== SELECT product_id , min( case when store = 'store1' then price else null end ) store1, min( case when store = 'store2' then price else null end ) store2, min( case when store = 'store3' then price else null end ) store3 FROM Products group by product_id ====方法2===== SELECT product_id , nullif( sum( case when store = 'store1' then price else 0 end ) ,0) store1, nullif( sum( case when store = 'store2' then price else 0 end ) ,0) store2, nullif( sum( case when store = 'store3' then price else 0 end ) ,0) store3 FROM Products group by product_id === 体会如上两种方法, 结果是一样的。 其实就是 null 和0 的关系,最终为0 的结果让展示为null,这个地方是重点。
2.行转列。
2.1 CONCAT 是一个拼接函数 , 可以是n个参数拼在一起
SELECT first_name, last_name, CONCAT(first_name, ' ', last_name) AS full_name FROM employees;
2.2 concat_ws (With Separator)
注意: CONCAT_WS must be "string or array<string>
- 第一个参数是分隔符,后面的参数是要连接的字符串。
SELECT CONCAT_WS('-', '2024', '09', '12') AS date; -- 结果: '2024-09-12'
2.3 COLLECT_SET(col):COLLECT_SET 是 Hive 中的一个聚合函数,用于将一组值收集到一个集合中,并去除重复值。它返回一个数组,包含了所有不同的值。
SELECT
order_id,
COLLECT_SET(product) AS unique_products
FROM
orders
GROUP BY
order_id;
|
order_id
|
unique_products
|
|---|---|
|
1
|
["Apple", "Banana"]
|
|
2
|
["Apple", "Orange"]
|
|
3
|
["Banana"]
|

2.4 COLLECT_LIST(col):
·函数指接收基本数据类型
·它的主要作用是将某字段的值进行不去重汇总,产生array类型字段。
SELECT
order_id,
COLLECT_LIST(product) AS product_list
FROM
orders
GROUP BY
order_id;
order_id product_list
1 ["Apple","Banana"]
2 ["Apple","Orange"]
3 ["Banana","Banana"]
2.5 PIVOT
在 Hive 3.0 及以上版本中,`PIVOT` 函数用于将行数据转换为列数据。它可以帮助我们将某个字段的不同值转化为列,并对其他字段进行聚合。
在 Hive 3.0 及以上版本中,`PIVOT` 函数用于将行数据转换为列数据。它可以帮助我们将某个字段的不同值转化为列,并对其他字段进行聚合。 ### PIVOT 语法 ```sql SELECT * FROM table_name PIVOT (aggregate_function(column_to_aggregate) FOR column_to_pivot IN (value1 AS alias1, value2 AS alias2, ...)); ``` - **aggregate_function**:用于聚合的函数,如 `SUM`、`COUNT`、`AVG` 等。 - **column_to_aggregate**:需要进行聚合的列。 - **column_to_pivot**:用于转列的列。 - **value1, value2, ...**:要转为列的值。 - **alias1, alias2, ...**:新列的别名。 ### 示例 假设我们有一个名为 `sales` 的表,包含以下数据: | product | month | sales | |---------|-------|-------| | Apple | Jan | 100 | | Apple | Feb | 150 | | Banana | Jan | 200 | | Banana | Feb | 250 | | Orange | Jan | 300 | | Orange | Feb | 350 | ### 1. 创建基础表 首先,我们创建 `sales` 表: ```sql CREATE TABLE sales ( product STRING, month STRING, sales INT ); ``` ### 2. 插入数据 接下来,向 `sales` 表中插入一些示例数据: ```sql INSERT INTO TABLE sales VALUES ('Apple', 'Jan', 100), ('Apple', 'Feb', 150), ('Banana', 'Jan', 200), ('Banana', 'Feb', 250), ('Orange', 'Jan', 300), ('Orange', 'Feb', 350); ``` ### 3. 使用 PIVOT 现在,我们可以使用 `PIVOT` 函数将 `month` 转为列,并对 `sales` 进行求和: 其他字段作为列, 聚合函数里的字段值作为 for 后面字段的值作为字段。 ```sql SELECT * FROM sales PIVOT (SUM(sales) FOR month IN ('Jan' AS Jan, 'Feb' AS Feb)); ``` ### 4. 查询结果 执行上述查询后,结果将如下所示: | product | Jan | Feb | |---------|-----|-----| | Apple | 100 | 150 | | Banana | 200 | 250 | | Orange | 300 | 350 | ### 总结 - `PIVOT` 函数用于将行数据转换为列数据,适合用于数据透视表的创建。 - 需要在 Hive 3.0 及以上版本中使用。 如果你有其他问题或需要更多示例,请告诉我!
3. 列转行
lateral view ,参考比较 expolde split
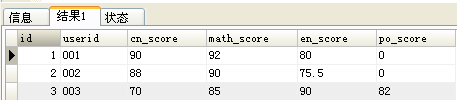
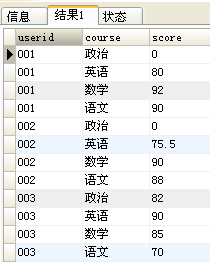
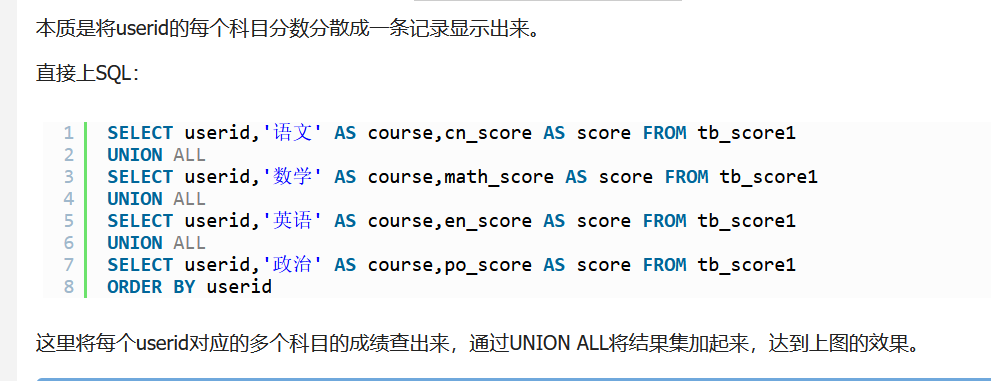
另外一种方法:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~