安装hadoop 单机版本.
整理笔记
1. 环境变量 etc/profile #Java export JAVA_HOME=/opt/jdk1.8.0_271 export PATH=$PATH:$JAVA_HOME/bin #hadoop export HADOOP_HOME=/opt/hadoop-2.7.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin vim ~/.bashrc 在这里也要添加: source /etc/profile 2.大数据环境变量 /hadoop-2.7.3/etc/hadoop/yarn-env.sh 添加java环境变量. mapred-env.sh hadoop-env.sh yarn-env.sh export JAVA_HOME=/opt/jdk1.8.0_271 3. 3.1 配置 core-site.xml 路径:/hadoop-2.7.3/etc/hadoop/ <property> <name>fs.defaultFS</name> <value>hdfs://192.168.6.200:9000</value> </property> <!-- 指定数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.7.1/data/tmp</value> </property> 3.2 配置hdfs-site.xml 路径:/hadoop-2.7.3/etc/hadoop/ <property> <name>dfs.replication</name> <value>1</value> </property> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.6.200:50090</value> </property> 3.3 配置yarn-sit.sh 路径:/hadoop-2.7.3/etc/hadoop/ <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.6.200</value> </property> <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> 3.4 配置mapred-site.xml <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> 3.5 配置 hive-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.6.200:3306/metastore?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> </configuration> 4. 启动 sh /opt/hadoop-2.7.1/sbin/start-all.sh
准备工作1 . 拷贝文件从主机1 到主机2
1. 将本机的 software 目录拷贝到 hadoop03 的opt目录下.推送到hadoop03上 。
scp -r software root@hadoop03:/opt
2. 将03 opt目录下的东西拷贝到本机
scp -r root@haddop03:/opt/ ./
一、安装hdoop
1. tar解压hadoop软件安装
tar -vxf hadoop-2.7.1_64bit.tar.gz
1.1
还要添加互信机制
ssh-keygen -t rsa && ssh-copy-id hadoop102
2.添加环境变量 vim /etc/profile
#hadoop export HADOOP_HOME=/software/hadoop-2.7.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3. source /etc/profile 生效
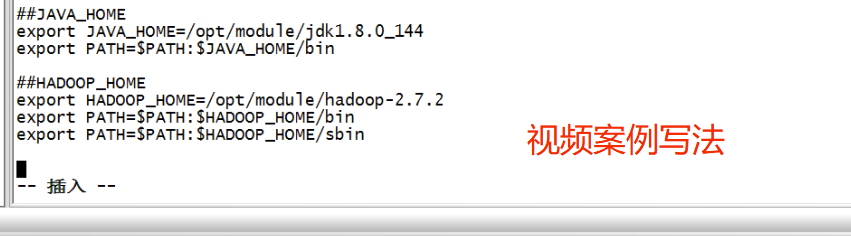
4. 配置hadoop-env.sh
[root@hadoop03 hadoop]# pwd /software/hadoop-2.7.1/etc/hadoop [root@hadoop03 hadoop]# vim hadoop-env.sh
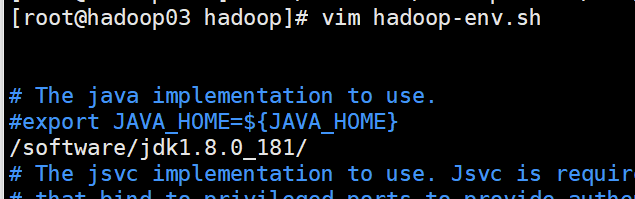
5. 配置:core-site.xml
新建目录 /software/hadoop-2.7.1/data/tmp
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop03:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/software/hadoop-2.7.1/data/tmp</value>
</property>
</configuration>
-- 插入 --
6. 配置:hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
-- 插入 --
7. 务必要格式化
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -formatt
8. 启动namenode、datanode
[root@hadoop03 sbin]# pwd /software/hadoop-2.7.1/sbin [root@hadoop03 sbin]# hadoop-daemon.sh start namenode starting namenode, logging to /software/hadoop-2.7.1/logs/hadoop-root-namenode-hadoop03.out
9.查看jps
[root@hadoop03 bin]# jps 7153 Jps 6955 NameNode 2414 QuorumPeerMain 7071 DataNode [root@hadoop03 bin]#
10 web页面查看
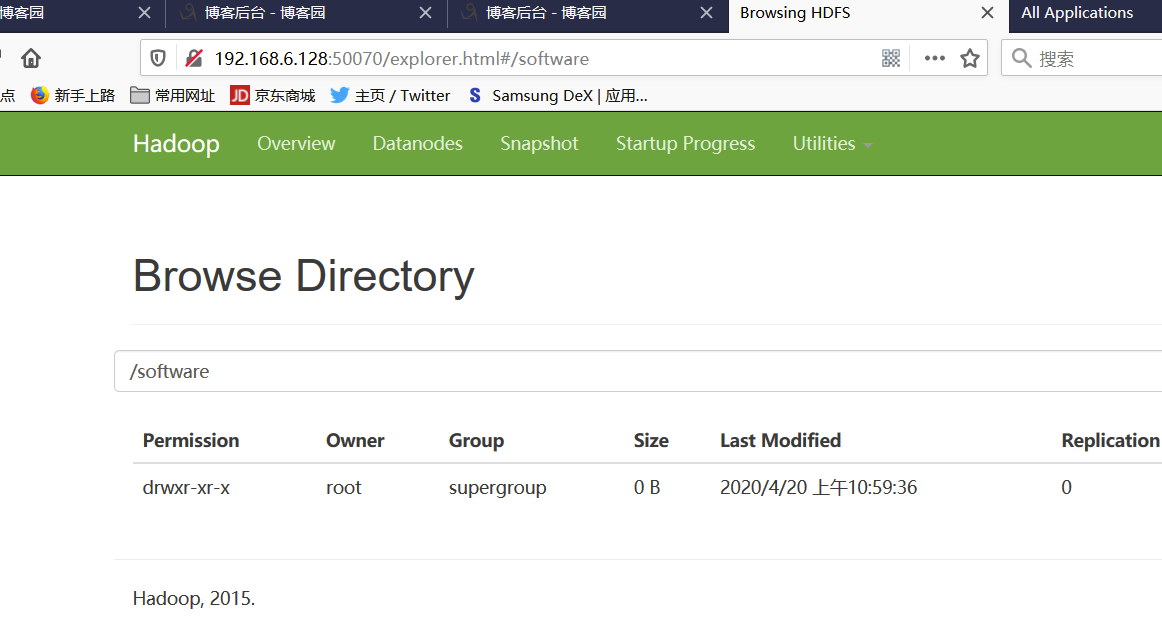
http://192.168.6.128:50070/dfshealth.html#tab-overview
11.创建文件夹
hdfs dfs -mkdir -p /software/testinput

12.查看日志
[root@hadoop03 software]# cd hadoop-2.7.1/logs/ [root@hadoop03 logs]# ls hadoop-root-datanode-hadoop03.log hadoop-root-namenode-hadoop03.out hadoop-root-datanode-hadoop03.out hadoop-root-namenode-hadoop03.out.1 hadoop-root-datanode-hadoop03.out.1 hadoop-root-namenode-hadoop03.out.2 hadoop-root-datanode-hadoop03.out.2 SecurityAuth-root.audit
二、安装yarn
1.编辑yarn-en.sh
[root@hadoop03 hadoop]# echo $JAVA_HOME /software/jdk1.8.0_181/ [root@hadoop03 hadoop]# vim yarn-env.sh
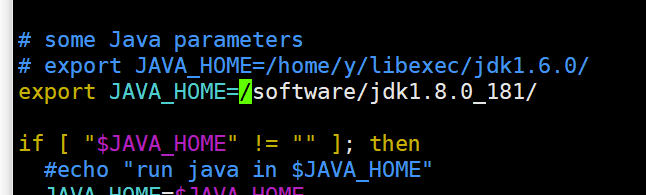
2.配置 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
</configuration>
3. 编辑mapred-env.sh
[root@hadoop03 hadoop]# vim mapred-env.sh
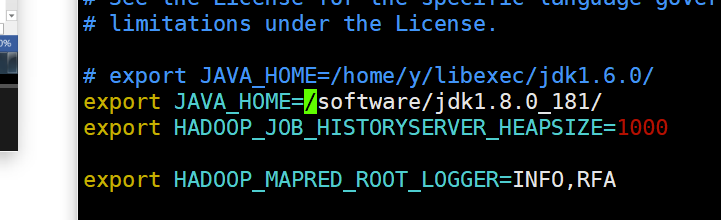
4.
d)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml [atguigu@hadoop101 hadoop]$ mv mapred-site.xml.template mapred-site.xml [atguigu@hadoop101 hadoop]$ vi mapred-site.xml <!-- 指定MR运行在YARN上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
5.启动集群,启动resource manager, nodemanager。
[root@hadoop03 sbin]# yarn-daemon.sh start resourcemanager /software/hadoop-2.7.1/etc/hadoop/hadoop-env.sh:行26: /software/jdk1.8.0_181/: 是一个目录 starting resourcemanager, logging to /software/hadoop-2.7.1/logs/yarn-root-resourcemanager-hadoop03.out /software/hadoop-2.7.1/etc/hadoop/hadoop-env.sh:行26: /software/jdk1.8.0_181/: 是一个目录 [root@hadoop03 sbin]#
[root@hadoop03 sbin]# yarn-daemon.sh start nodemanager /software/hadoop-2.7.1/etc/hadoop/hadoop-env.sh:行26: /software/jdk1.8.0_181/: 是一个目录 starting nodemanager, logging to /software/hadoop-2.7.1/logs/yarn-root-nodemanager-hadoop03.out /software/hadoop-2.7.1/etc/hadoop/hadoop-env.sh:行26: /software/jdk1.8.0_181/: 是一个目录 [root@hadoop03 sbin]#
JPS查看
root@hadoop03 sbin]# jps 8720 NodeManager 8832 Jps 8455 ResourceManager 6955 NameNode 2414 QuorumPeerMain 7071 DataNode [root@hadoop03 sbin]#
查看mapreduce的web界面
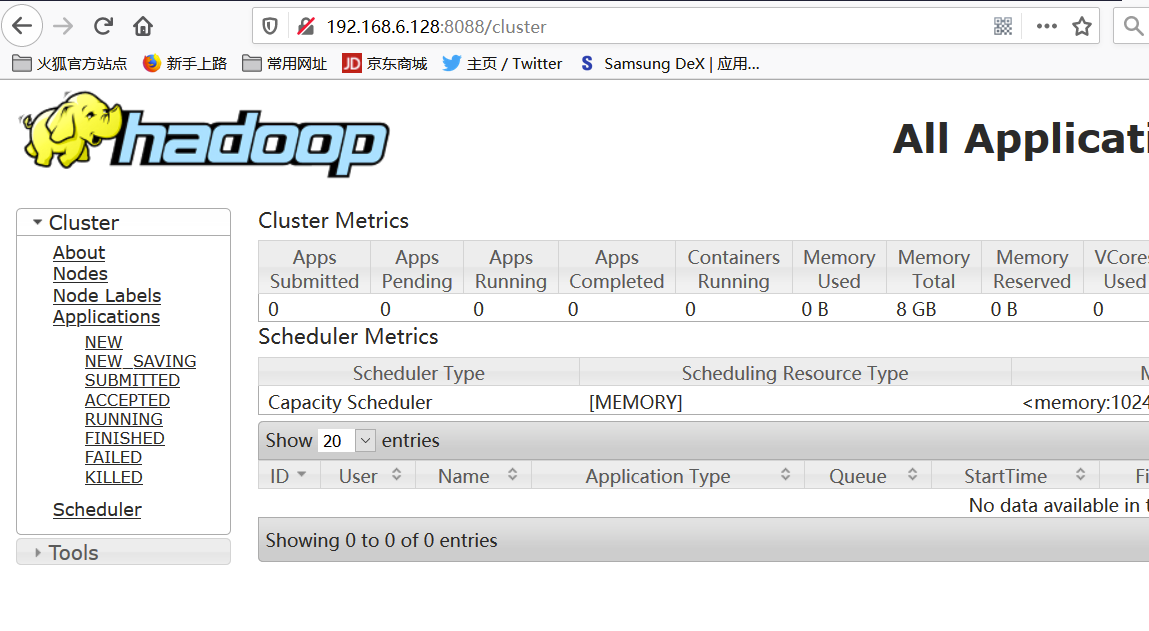
查看HDFS 为50070端口
安装hive注意事项
安装HIVE的时候使用MYSQL做为元数据 ,但是会出现设置mysql密码找不到初始密码的问题 ,这个问题如何解决呢????
如下:
vi /etc/rc.local
sh /sofeware/hadoop-2.7.1/sbin/start-all.sh
#如下两条命令,让他跳过密码这步即可
service mysql start
mysqld_safe --skip-grant-tables &
1.安装
先把文件传到相应的目录上
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/module/
mv hive-env.sh.template hive-env.sh
vi hive-env.sh
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export HIVE_CONF_DIR=/opt/module/hive/conf
2.启动hive
bin/hive
3.安装mysql
原因是,Metastore 默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore 。
rpm -qa|grep mysql
rpm -e --nodeps mysql-libs-5.1.73-7.el6.x86_64
解压mysql
|
1
|
unzip mysql-libs.zip |

rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm
cat /root/.mysql_secret
service mysql start
rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm
mysql -uroot -pbC87GBGvxWr6B5yq登录进来,然后改密码
mysql>SET PASSWORD=PASSWORD('000000');
use mysql;
mysql> select user,host,password from user;
+------+-----------+-------------------------------------------+
| user | host | password |
+------+-----------+-------------------------------------------+
| root | localhost | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B |
| root | hadoop102 | *2AC9F144B30F707154711CBE6076B42263C29327 |
| root | 127.0.0.1 | *2AC9F144B30F707154711CBE6076B42263C29327 |
| root | ::1 | *2AC9F144B30F707154711CBE6076B42263C29327 |
+------+-----------+-------------------------------------------+
4 rows in set (0.00 sec)
修改 user 表,把 Host 表内容修改为%
mysql> update user set host='%' where host='localhost'; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0
删除 root 用户的其他 host
delete from user where Host='hadoop102';
delete from user where Host='127.0.0.1';
delete from user where Host='::1';
在查看下
mysql> select user,host,password from user;
+------+------+-------------------------------------------+
| user | host | password |
+------+------+-------------------------------------------+
| root | % | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B |
+------+------+-------------------------------------------+
1 row in set (0.00 sec)
flush privileges;
安装mysql 驱动connector
tar -zxvf mysql-connector-java-5.1.27.tar.gz
cd mysql-conn
cp /opt/software/mysql-libs/mysql-connector-java-5.1.27/mysql-connector-java-5.1.27-bin.jar /opt/module/apache-hive-1.2.1-bin/lib/
进入到hive的conf目录下 新建一个 hive-site.xml ,别mv .template那个
vi hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>
改完之后应该重启,我遇到的情况都重启了。
测试尝试一下能不能多个hive终端访问,如果可以的话,那么证明ok, 通过使用mysql数据库作为元数据没有问题, 而不是使用系统hive自带的derby数据库作为元数据。

