爬虫作业
2018-12-06 18:39 梦小白、 阅读(185) 评论(0) 收藏 举报import requests import json try: r=requests.get('https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1544091382936') r.raise_for_status() r.encoding='utf-8' results=json.loads(r.text)['data'] except: print("网络连接失败") else: mw='' for mv in results: mw+=str(mv["StudentNo"])+","+mv["RealName"]+","+mv["DateAdded"].replace("T"," ")+","+mv["Title"]+","+mv["Url"]+"\n" with open ('hwlist.csv','w') as f: f.write(mw)
第一部分:
请分析作业页面,爬取已提交作业信息,并生成已提交作业名单,保存为英文逗号分隔的csv文件。文件名为:hwlist.csv
第一部分需要用到requests库,pip安装时出现错误,IDLE中没有requests库,所以用了sypder进行爬取。
利用了搜狗自带的开发者工具进行网页链接的复制。

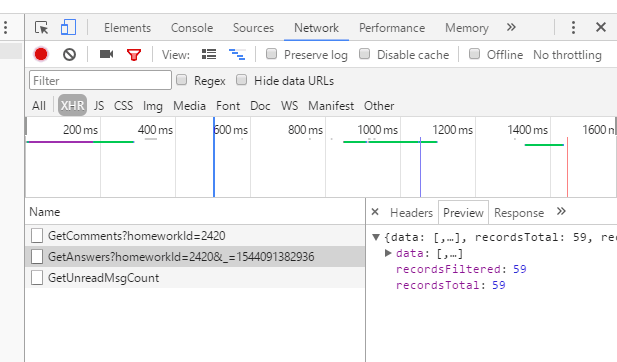
爬取结果如图
使用的开发者工具如图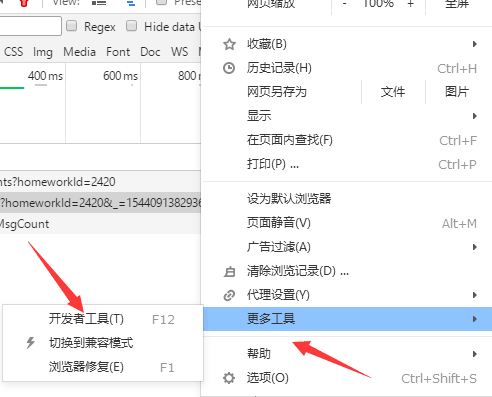

 浙公网安备 33010602011771号
浙公网安备 33010602011771号