Mysql实现企业级数据库主从复制架构实战
背景
数据库常遇到的问题
一、性能问题
1、向上拓展 scale up :针对单台服务器,提高服务器的硬件性能,比如:内存,cpu等,个体本身 容易达到极限
2、向外拓展 scale out :多台服务器形成集群,共同完成一件事情
二、可用性问题
数据库高可用技术说明
企业级数据库高可用架构图

Mysql主从架构技术说明
主从复制架构图

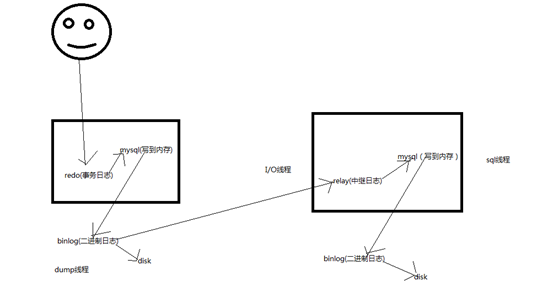
数据库复制特性
Mysql复制解决的问题
(4) 高可用性和容错性 High availabilityand failover
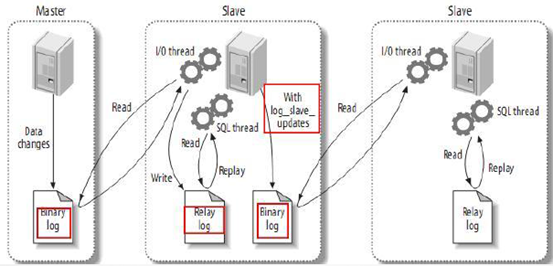
Mysql复制如何工作
Mysql的复制功能主要有3个步骤:
(1) 主服务器(master)将改变记录到二进制日志(binarylog)中(这些记录叫做二进制日志事件,binary log events)
(2) 从服务器(slave)将主服务器master的binary logevents拷贝到它的中继日志(relay log)
(3) slave重做中继日志中的事件,将改变反映它自己的数据。
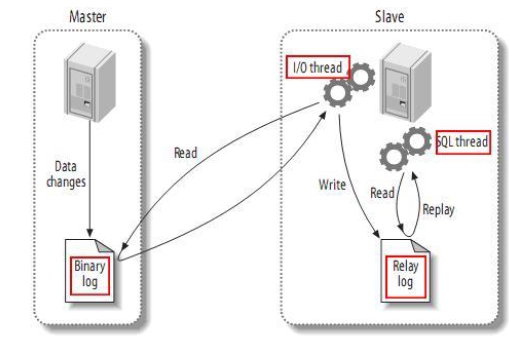
I/O线程:将master数据库二进制日志拉到slave数据库上,并将二进制日志写到中继日志,写完之后,他会睡眠并等待master数据库二进制日志更新,一旦更新,就会写入slave数据库的中继日志中
SQL线程:读取中继日志的事件,并在数据库中执行,写入到内存中,使slave数据库的数据与master数据库中的数据一致
Mysql实现企业级数据库主从复制架构实战
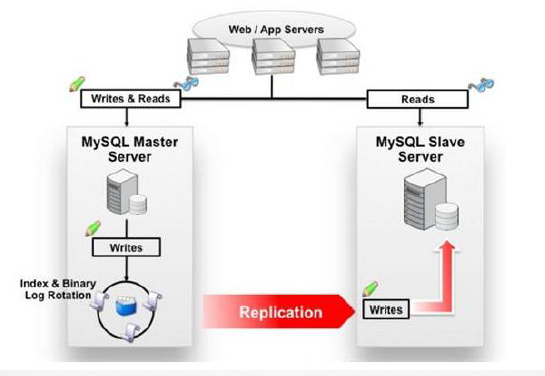
注意:slave数据库只能是可读的,不能是可写的,如果改变了slave数据库的数据,master不能从slave数据库上同步数据,导致主从数据库数据不一致。
实战演练
一、环境准备
centos系统服务器2台、一台用户做Mysql主服务器,一台用于做Mysql从服务器,都在同一个网段中,配置好yum源、防火墙关闭、各节点时钟服务同步、各节点之间可以通过主机名互相通信
二、准备步骤:
1、iptables -F && setenforce 清空防火墙策略,关闭selinux
2、拿两台服务器都使用yum方式安装Mysql服务,要求版本一致
三、实现步骤:
1、配置master主服务器
对master进行配置,包括打开二进制日志,指定唯一的servr ID。例如,在配置文件加入如下值
server-id=1 #配置server-id,让主服务器有唯一ID号(让从服务器知道他的主服务器是谁)
log-bin=mysql-bin #打开Mysql日志,日志格式为二进制
skip-name-resolve#关闭名称解析,(非必须)
2.创建复制帐号
在Master的数据库中建立一个备份帐户:每个slave使用标准的MySQL用户名和密码连接master
。进行复制操作的用户会授予REPLICATION SLAVE权限。(给从服务器授权,让他能从主服务器拷贝二进制日志)
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO slave@'192.168.10.%' IDENTIFIED BY 'magedu';
3.查看主服务器状态
在Master的数据库执行show master status,查看主服务器二进制日志状态

4、配置slave从服务器
对slave进行配置,打开中继日志,指定唯一的servr ID,设置只读权限。在配置文件加入如下值
server-id=2 #配置server-id,让从服务器有唯一ID号
relay_log = mysql-relay-bin #打开Mysql日志,日志格式为二进制
log_bin = mysql-bin #开启从服务器二进制日志
log_slave_updates = 1 #使得更新的数据写进二进制日志中
然后重启数据库服务
5.启动从服务器复制线程
让slave连接master,并开始重做master二进制日志中的事件。
CHANGE MASTER TO MASTER_HOST='192.168.10.190',
MASTER_LOG_FILE='mysql-bin.000001',
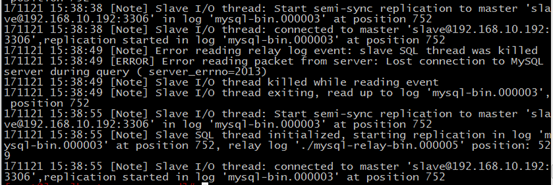
6、查看从服务器状态
可使用SHOW SLAVE STATUS\G查看从服务器状态,如下所示,也可用show processlist \G查看前复制状态:
Slave_IO_Running: Yes #IO线程正常运行
Slave_SQL_Running: Yes #SQL线程正常运行
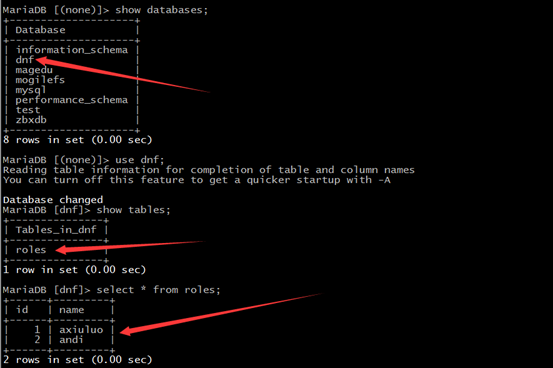
7.测试


在从服务器上
四、添加新slave服务器
假如master已经运行很久了,想对新安装的slave进行数据同步,甚至它没有master的数据。
实现主从从架构
就是在从服务器也开启二进制日志,然后从的从I/O线程再将从的二进制日志给拷贝过来写入到自己的relay log中,然后sql线程再读取relay log中的事件,在数据库中执行,写入到内存中。
Mysql复制过滤器
仅复制有限一个或几个数据库相关的数据,而非所有;由复制过滤器进行;
从服务器的SQL THREAD仅重放关注的数据库或表相关的事件,并将其应用于本地;
企业常见数据库架构
一、单一master和多slave
单一master和多slave架构图

(1) 不同的slave扮演不同的作用(例如使用不同的索引,或者不同的存储引擎);
(2) 用一个slave作为备用master,只进行复制;#主服务器挂了之后,可在从服务器执行
1> 在备机上执行STOP SLAVE 和RESET MASTER
二、互为主从Master-Master(Master-Master in Active-Active Mode)

Master-Master复制的两台服务器,既是master,又是另一台服务器的slave。这样,任何一方所做的变更,都会通过复制应用到另外一方的数据库中。
即:在两台服务器上既执行master的操作又执行slave的操作(注意:两台数据库都必须是可写的)
互为主从复制过程
互为主从:两个节点各自都要开启binlog和relay log;
对于某些唯一性的字段,可以通过设置自增长ID来实现,自增长ID的数据,代表这个表中存在一条唯一的记录;而自增长id是肯定不会重复的;
create table userInfo (id int PRIMARY KEY AUTO_INCREMENT,name varchar(50) NOT NULL);
两边插入数据看数据增长
insert into userInfo(name) value('xiao'),('da'),('lao');
定义一个节点使用奇数id
auto_increment_increment=2 #表示自增长字段每次递增的量
auto_increment_offset=1 #表示自增长字段从那个数开始
配置:
2、均启用binlog和relay log; read only = 0(因为互为主从,所以必须是可写的)
3、存在自动增长id的表,为了使得id不相冲突,需要定义其自动增长方式;
实验:数据库互为主从复制步骤
1.修改mysql配置文件
2.创建复制帐号
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO slave@'192.168.10.%' IDENTIFIED BY 'magedu';
3.启动从服务器复制线程
让slave连接master,并开始重做master二进制日志中的事件。
CHANGE MASTER TO MASTER_HOST='192.168.10.190',
MASTER_LOG_FILE='mysql-bin.000001',
4、查看从服务器状态
可使用SHOW SLAVE STATUS\G查看从服务器状态,如下所示,也可用show processlist \G查看前复制态:
Slave_IO_Running: Yes #IO线程正常运行
Slave_SQL_Running: Yes #SQL线程正常运行
两台数据库服务器都显示如上结果就ok
5.创建表,设置ID为自增长,两边插入数据看数据增长
create table userinfo (id int PRIMARY KEY AUTO_INCREMENT,name varchar(20) NOT NULL);
insert into userinfo (name) values('ni'),('wo'),('ta');
然后查看表,因为是自增长id,从1开始,步长为2,所以添加的数据id为1,3,5

然后在另一台数据库服务器插入数据,因为是自增长id,从2开始,步长为2,所以新添加的数据id为6,8,10

排错:当配置文件中配置中继日志格式不小心配置错了,或者让slave连接master,执行sql语句不小心写错了,都有可能导致start slave;报错,此时可以show slave status\G;会出现一大串信息,里面会提示错误。找到错误以后,重置slave,reset slave;重新设置,然后再start slave;
注意:mysql的错误日志非常重要,可以提供错误信息,从而找到错误原因。
互为主从容易导致数据不一致,此时我们可以用两个实例来互为主从
1.可以用数据缓存,常见的memcache
2.数据库本身有很多缓存机制,可使用对应的缓存策略
3.对数据来说,竟可能使用索引
4.对请求而言,可以实现读写分离,对读请求负载均衡
5.对大数据库或者表,可根据业务逻辑进行分库分表
6.多有的优化,尽可能网内存中存放
半同步复制
异步复制(Asynchronous replication)
全同步复制(Fully synchronous replication)
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。需要有超时时间。
半同步复制(Semisynchronous replication)
半同步复制
支持多种插件:/usr/lib64/mysql/plugins/
mysql> INSTALL PLUGIN plugin_name SONAME 'shared_library_name';
主节点:
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
MariaDB [mydb]> SHOW GLOBAL VARIABLES LIKE 'rpl_semi%';
+------------------------------------+-------+
+------------------------------------+-------+
| rpl_semi_sync_master_enabled | OFF |
| rpl_semi_sync_master_timeout | 10000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_no_slave | ON |
+------------------------------------+-------+
MariaDB [mydb]> SET GLOBAL rpl_semi_sync_master_enabled=ON/1;
从节点:
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
MariaDB [mydb]> SHOW GLOBAL VARIABLES LIKE 'rpl_semi%';
+---------------------------------+-------+
+---------------------------------+-------+
| rpl_semi_sync_slave_enabled | OFF |
| rpl_semi_sync_slave_trace_level | 32 |
+---------------------------------+-------+
MariaDB [mydb]> STOP SLAVE IO_THREAD;
MariaDB [mydb]> SET GLOBAL rpl_semi_sync_slave_enabled = ON ;
MariaDB [mydb]> SHOW GLOBAL VARIABLES LIKE 'rpl_semi%';
MariaDB [mydb]> START SLAVE IO_THREAD;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号