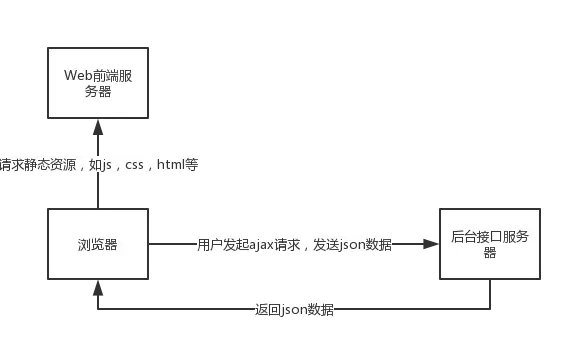
下图是前后端分离模型,通过此模型可更好的理解爬虫破解。
爬虫在爬取数据时,因为获得的不是页面显示的数据,所以无法提取想要的信息。因为前后端分离了,我们向后端服务器发送请求后,返回的不是html源码,而是json数据,由json数据向WEB服务器请求静态资源,WEB服务器再把数据发给浏览器渲染。所以在爬取此类网页时,需要分析json数据,向WEB服务发送请求,就能得到想要的数据。