二十二 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第一步。首先下载,大神者也的倒立文字验证码识别程序
下载地址:https://github.com/muchrooms/zheye
注意:此程序依赖以下模块包
Keras==2.0.1
Pillow==3.4.2
jupyter==1.0.0
matplotlib==1.5.3
numpy==1.12.1
scikit-learn==0.18.1
tensorflow==1.0.1
h5py==2.6.0
numpy-1.13.1+mkl
我们用豆瓣园来加速安以上依赖装如:
pip install -i https://pypi.douban.com/simple h5py==2.6.0
如果是win系统,可能存在安装失败的可能,如果那个包安装失败,就到 http://www.lfd.uci.edu/~gohlke/pythonlibs/ 找到win对应的版本下载到本地安装,如:
pip install h5py-2.7.0-cp35-cp35m-win_amd64.whl
第二步,将者也的,验证码识别程序的zheye文件夹放到工程目录里
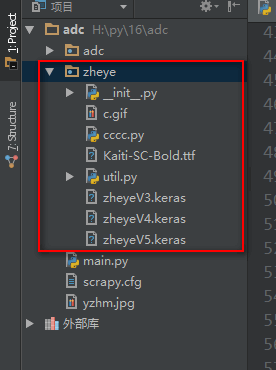
第三步,爬虫实现
start_requests()方法,起始url函数,会替换start_urls
Request()方法,get方式请求网页
url=字符串类型url
headers=字典类型浏览器代理
meta=字典类型的数据,会传递给回调函数
callback=回调函数名称
scrapy.FormRequest()post方式提交数据
url=字符串类型url
headers=字典类型浏览器代理
meta=字典类型的数据,会传递给回调函数
callback=回调函数名称
formdata=字典类型,要提交的数据字段
response.headers.getlist('Set-Cookie') 获取响应Cookies
response.request.headers.getlist('Cookie') 获取请求Cookies

# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re
class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['zhihu.com'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理
def start_requests(self): #起始url函数,会替换start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request(
url='https://www.zhihu.com/#signin',
headers=self.header,
meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数
callback=self.parse
)]
def parse(self, response):
# 响应Cookies
Cookie1 = response.headers.getlist('Set-Cookie') #查看一下响应Cookie,也就是第一次访问注册页面时后台写入浏览器的Cookie
print('后台首次写入的响应Cookies:',Cookie1)
#获取xsrf密串
xsrf = response.xpath('//input[@name="_xsrf"]/@value').extract()[0]
print('获取xsrf密串:' + xsrf)
#获取验证码
import time
t = str(int(time.time()*1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r={0}&type=login&lang=cn'.format(t) #构造验证码请求地址
yield Request(url=captcha_url, #请求验证码图片
headers=self.header,
meta={'cookiejar':response.meta['cookiejar'],'xsrf':xsrf}, #将Cookies和xsrf密串传给回调函数
callback=self.post_tj
)
def post_tj(self, response):
with open('yzhm.jpg','wb') as f: #打开图片句柄
f.write(response.body) #将验证码图片写入本地
f.close() #关闭句柄
#--------------------------------------------者也验证码识别------------------------------------------
from zheye import zheye #导入者也倒立文字验证码识别模块对象
z = zheye() #实例化对象
positions = z.Recognize('yzhm.jpg') #将验证码本地路径传入Recognize方法识别,返回倒立图片的坐标
# print(positions) #默认倒立文字的y坐标在前,x坐标在后
#知乎网要求的倒立文字坐标是x轴在前,y轴在后,所以我们需要定义一个列表来改变默认的,倒立文字坐标位置
pos_arr = []
if len(positions) == 2:
if positions[0][1] > positions[1][1]: #判断列表里第一个元祖里的第二个元素如果大于,第二个元祖里的第二个元素
pos_arr.append([positions[1][1],positions[1][0]])
pos_arr.append([positions[0][1], positions[0][0]])
else:
pos_arr.append([positions[0][1], positions[0][0]])
pos_arr.append([positions[1][1], positions[1][0]])
else:
pos_arr.append([positions[0][1], positions[0][0]])
print('处理后的验证码坐标',pos_arr)
# --------------------------------------------者也验证码识别结束------------------------------------------
if len(pos_arr) == 2:
data = { # 设置用户登录信息,对应抓包得到字段
'_xsrf': response.meta['xsrf'],
'password': '279819',
'captcha': '{"img_size":[200,44],"input_points":[[%.2f,%f],[%.2f,%f]]}' %(
pos_arr[0][0] / 2, pos_arr[0][1] / 2, pos_arr[1][0] / 2, pos_arr[1][1] / 2), #因为验证码识别默认是400X88的尺寸所以要除以2
'captcha_type': 'cn',
'phone_num': '15284816568'
}
else:
data = { # 设置用户登录信息,对应抓包得到字段
'_xsrf': response.meta['xsrf'],
'password': '279819',
'captcha': '{"img_size":[200,44],"input_points":[[%.2f,%f]]}' %(
pos_arr[0][0] / 2, pos_arr[0][1] / 2),
'captcha_type': 'cn',
'phone_num': '15284816568'
}
print('登录提交数据',data)
print('登录中....!')
"""第二次用表单post请求,携带Cookie、浏览器代理、用户登录信息,进行登录给Cookie授权"""
return [scrapy.FormRequest(
url='https://www.zhihu.com/login/phone_num', #真实post地址
meta={'cookiejar':response.meta['cookiejar']}, #接收第传过来的Cookies
headers=self.header,
formdata=data,
callback=self.next
)]
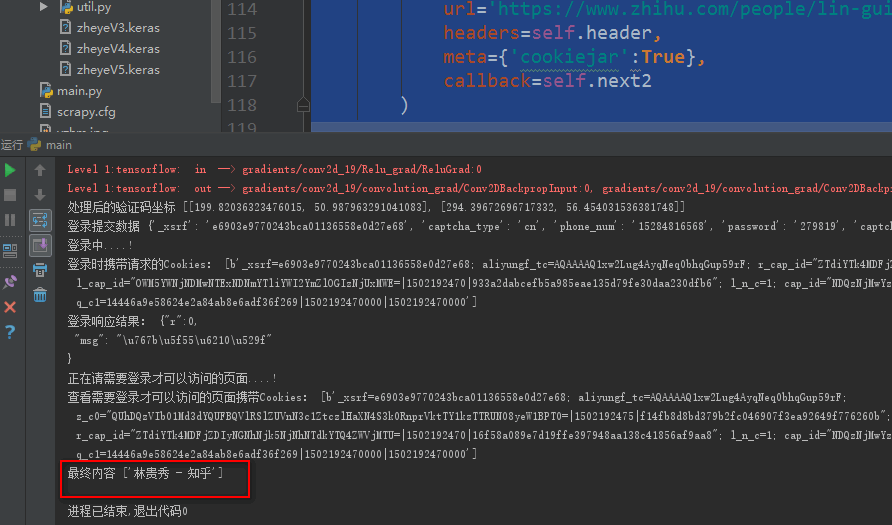
def next(self,response):
# 请求Cookie
Cookie2 = response.request.headers.getlist('Cookie')
print('登录时携带请求的Cookies:',Cookie2)
jieg = response.body.decode("utf-8") #登录后可以查看一下登录响应信息
print('登录响应结果:',jieg)
print('正在请需要登录才可以访问的页面....!')
"""登录后请求需要登录才能查看的页面,如个人中心,携带授权后的Cookie请求"""
yield Request(
url='https://www.zhihu.com/people/lin-gui-xiu-41/activities',
headers=self.header,
meta={'cookiejar':True},
callback=self.next2
)
def next2(self,response):
# 请求Cookie
Cookie3 = response.request.headers.getlist('Cookie')
print('查看需要登录才可以访问的页面携带Cookies:',Cookie3)
leir = response.xpath('/html/head/title/text()').extract() #得到个人中心页面
print('最终内容',leir)
# print(response.body.decode("utf-8"))