十六 web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
PhantomJS虚拟浏览器
phantomjs 是一个基于js的webkit内核无头浏览器 也就是没有显示界面的浏览器,利用这个软件,可以获取到网址js加载的任何信息,也就是可以获取浏览器异步加载的信息
下载网址:http://phantomjs.org/download.html 下载对应系统版本
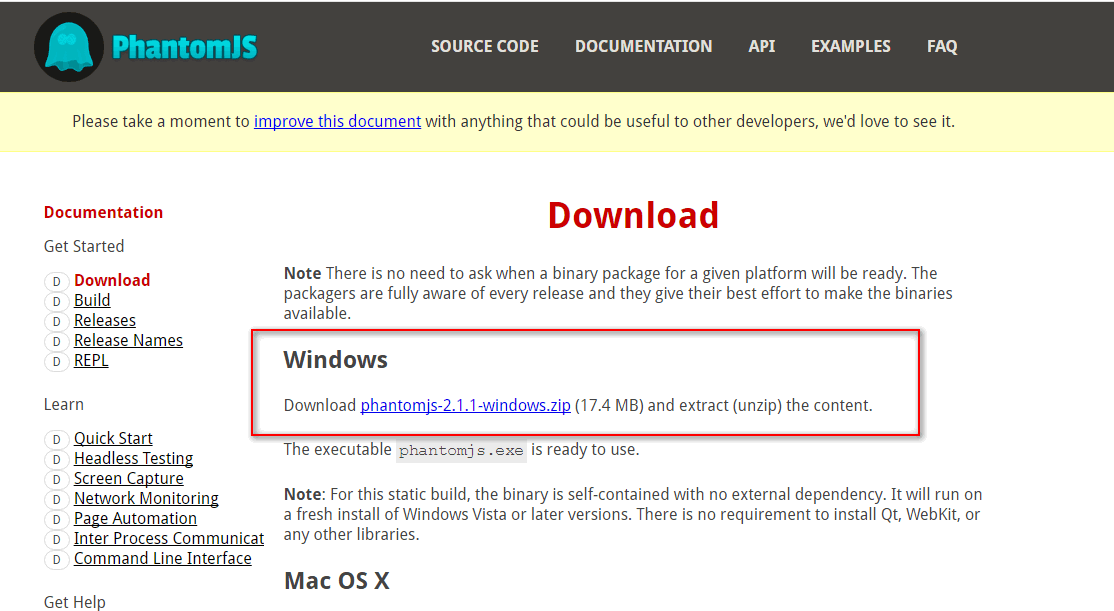
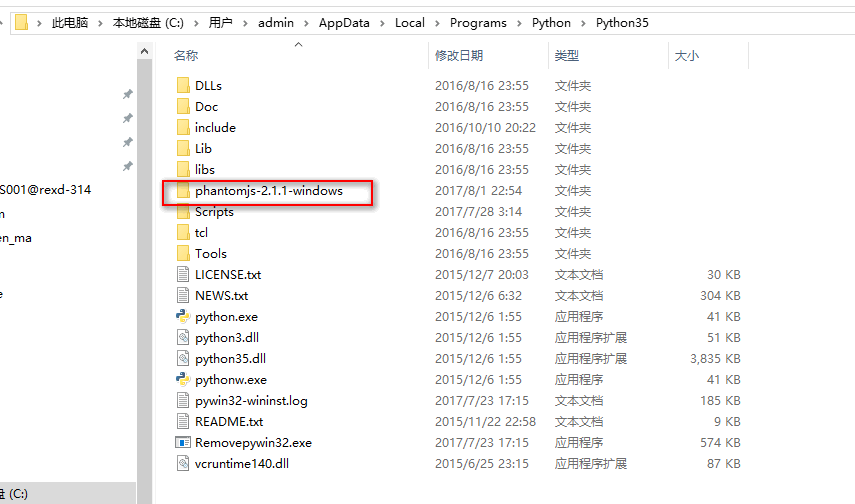
下载后解压PhantomJS文件,将解压文件夹,剪切到python安装文件夹
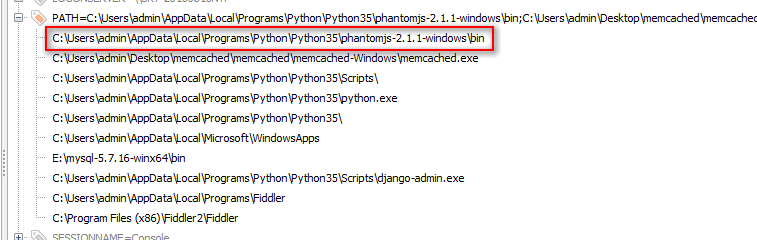
然后将PhantomJS文件夹里的bin文件夹添加系统环境变量
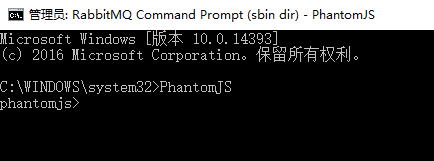
cdm 输入命令:PhantomJS 出现以下信息说明安装成功
selenium模块是一个python操作PhantomJS软件的一个模块
selenium模块PhantomJS软件
webdriver.PhantomJS()实例化PhantomJS浏览器对象
get('url')访问网站
find_element_by_xpath('xpath表达式')通过xpath表达式找对应元素
clear()清空输入框里的内容
send_keys('内容')将内容写入输入框
click()点击事件
get_screenshot_as_file('截图保存路径名称')将网页截图,保存到此目录
page_source获取网页htnl源码
quit()关闭PhantomJS浏览器

#!/usr/bin/env python
# -*- coding:utf8 -*-
from selenium import webdriver #导入selenium模块来操作PhantomJS
import os
import time
import re
llqdx = webdriver.PhantomJS() #实例化PhantomJS浏览器对象
llqdx.get("https://www.baidu.com/") #访问网址
# time.sleep(3) #等待3秒
# llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图保存到此目录
#模拟用户操作
llqdx.find_element_by_xpath('//*[@id="kw"]').clear() #通过xpath表达式找到输入框,clear()清空输入框里的内容
llqdx.find_element_by_xpath('//*[@id="kw"]').send_keys('叫卖录音网') #通过xpath表达式找到输入框,send_keys()将内容写入输入框
llqdx.find_element_by_xpath('//*[@id="su"]').click() #通过xpath表达式找到搜索按钮,click()点击事件
time.sleep(3) #等待3秒
llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图,保存到此目录
neir = llqdx.page_source #获取网页内容
print(neir)
llqdx.quit() #关闭浏览器
pat = "<title>(.*?)</title>"
title = re.compile(pat).findall(neir) #正则匹配网页标题
print(title)
PhantomJS浏览器伪装,和滚动滚动条加载数据
有些网站是动态加载数据的,需要滚动条滚动加载数据
实现代码
DesiredCapabilities 伪装浏览器对象
execute_script()执行js代码
current_url获取当前的url
#!/usr/bin/env python
# -*- coding:utf8 -*-
from selenium import webdriver #导入selenium模块来操作PhantomJS
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities #导入浏览器伪装模块
import os
import time
import re
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap['phantomjs.page.settings.userAgent'] = ('Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0')
print(dcap)
llqdx = webdriver.PhantomJS(desired_capabilities=dcap) #实例化PhantomJS浏览器对象
llqdx.get("https://www.jd.com/") #访问网址
#模拟用户操作
for j in range(20):
js3 = 'window.scrollTo('+str(j*1280)+','+str((j+1)*1280)+')'
llqdx.execute_script(js3) #执行js语言滚动滚动条
time.sleep(1)
llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图,保存到此目录
url = llqdx.current_url
print(url)
neir = llqdx.page_source #获取网页内容
print(neir)
llqdx.quit() #关闭浏览器
pat = "<title>(.*?)</title>"
title = re.compile(pat).findall(neir) #正则匹配网页标题
print(title)