十二 web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
模拟浏览器登录
start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里的请求
Request()get请求,可以设置,url、cookie、回调函数
FormRequest.from_response()表单post提交,第一个必须参数,上一次响应cookie的response对象,其他参数,cookie、url、表单内容等
yield Request()可以将一个新的请求返回给爬虫执行
在发送请求时cookie的操作,
meta={'cookiejar':1}表示开启cookie记录,首次请求时写在Request()里
meta={'cookiejar':response.meta['cookiejar']}表示使用上一次response的cookie,写在FormRequest.from_response()里post授权
meta={'cookiejar':True}表示使用授权后的cookie访问需要登录查看的页面
获取Scrapy框架Cookies
请求Cookie
Cookie = response.request.headers.getlist('Cookie')
print(Cookie)
响应Cookie
Cookie2 = response.headers.getlist('Set-Cookie')
print(Cookie2)

# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['edu.iqianyue.com'] #爬取域名
# start_urls = ['http://edu.iqianyue.com/index_user_login.html'] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理
def start_requests(self): #用start_requests()方法,代替start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request('http://edu.iqianyue.com/index_user_login.html',meta={'cookiejar':1},callback=self.parse)]
def parse(self, response): #parse回调函数
data = { #设置用户登录信息,对应抓包得到字段
'number':'adc8868',
'passwd':'279819',
'submit':''
}
# 响应Cookie
Cookie1 = response.headers.getlist('Set-Cookie') #查看一下响应Cookie,也就是第一次访问注册页面时后台写入浏览器的Cookie
print(Cookie1)
print('登录中')
"""第二次用表单post请求,携带Cookie、浏览器代理、用户登录信息,进行登录给Cookie授权"""
return [FormRequest.from_response(response,
url='http://edu.iqianyue.com/index_user_login', #真实post地址
meta={'cookiejar':response.meta['cookiejar']},
headers=self.header,
formdata=data,
callback=self.next,
)]
def next(self,response):
a = response.body.decode("utf-8") #登录后可以查看一下登录响应信息
# print(a)
"""登录后请求需要登录才能查看的页面,如个人中心,携带授权后的Cookie请求"""
yield Request('http://edu.iqianyue.com/index_user_index.html',meta={'cookiejar':True},callback=self.next2)
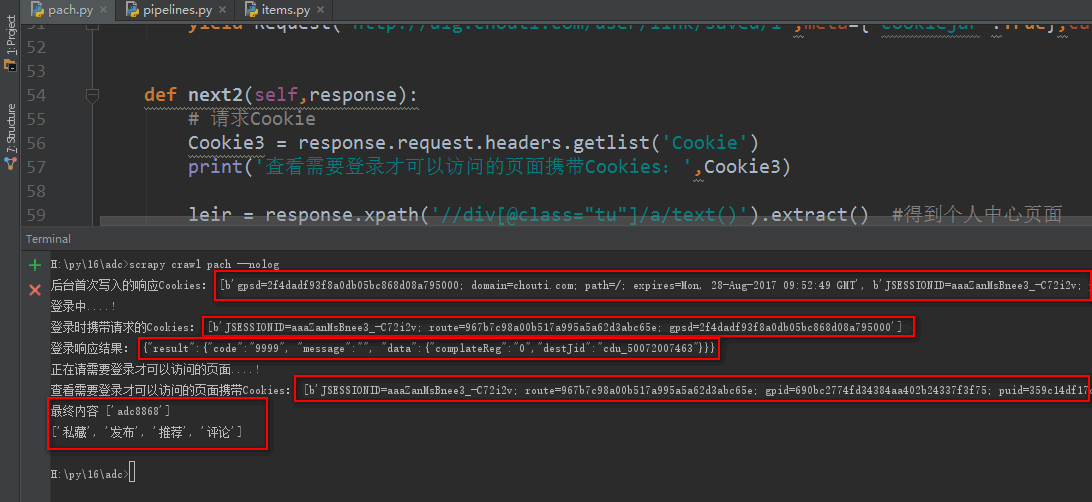
def next2(self,response):
# 请求Cookie
Cookie2 = response.request.headers.getlist('Cookie')
print(Cookie2)
body = response.body # 获取网页内容字节类型
unicode_body = response.body_as_unicode() # 获取网站内容字符串类型
a = response.xpath('/html/head/title/text()').extract() #得到个人中心页面
print(a)
模拟浏览器登录2
第一步、
爬虫的第一次访问,一般用户登录时,第一次访问登录页面时,后台会自动写入一个Cookies到浏览器,所以我们的第一次主要是获取到响应Cookies
首先访问网站的登录页面,如果登录页面是一个独立的页面,我们的爬虫第一次应该从登录页面开始,如果登录页面不是独立的页面如 js 弹窗,那么我们的爬虫可以从首页开始
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re
class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['dig.chouti.com'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理
def start_requests(self):
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request('http://dig.chouti.com/',meta={'cookiejar':1},callback=self.parse)]
def parse(self, response):
# 响应Cookies
Cookie1 = response.headers.getlist('Set-Cookie') #查看一下响应Cookie,也就是第一次访问注册页面时后台写入浏览器的Cookie
print('后台首次写入的响应Cookies:',Cookie1)
data = { # 设置用户登录信息,对应抓包得到字段
'phone': '8615284816568',
'password': '279819',
'oneMonth': '1'
}
print('登录中....!')
"""第二次用表单post请求,携带Cookie、浏览器代理、用户登录信息,进行登录给Cookie授权"""
return [FormRequest.from_response(response,
url='http://dig.chouti.com/login', #真实post地址
meta={'cookiejar':response.meta['cookiejar']},
headers=self.header,
formdata=data,
callback=self.next,
)]
def next(self,response):
# 请求Cookie
Cookie2 = response.request.headers.getlist('Cookie')
print('登录时携带请求的Cookies:',Cookie2)
jieg = response.body.decode("utf-8") #登录后可以查看一下登录响应信息
print('登录响应结果:',jieg)
print('正在请需要登录才可以访问的页面....!')
"""登录后请求需要登录才能查看的页面,如个人中心,携带授权后的Cookie请求"""
yield Request('http://dig.chouti.com/user/link/saved/1',meta={'cookiejar':True},callback=self.next2)
def next2(self,response):
# 请求Cookie
Cookie3 = response.request.headers.getlist('Cookie')
print('查看需要登录才可以访问的页面携带Cookies:',Cookie3)
leir = response.xpath('//div[@class="tu"]/a/text()').extract() #得到个人中心页面
print('最终内容',leir)
leir2 = response.xpath('//div[@class="set-tags"]/a/text()').extract() # 得到个人中心页面
print(leir2)