


十 web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
Scrapy框架安装
1、首先,终端执行命令升级pip: python -m pip install --upgrade pip
2、安装,wheel(建议网络安装) pip install wheel
3、安装,lxml(建议下载安装)
4、安装,Twisted(建议下载安装)
5、安装,Scrapy(建议网络安装) pip install Scrapy
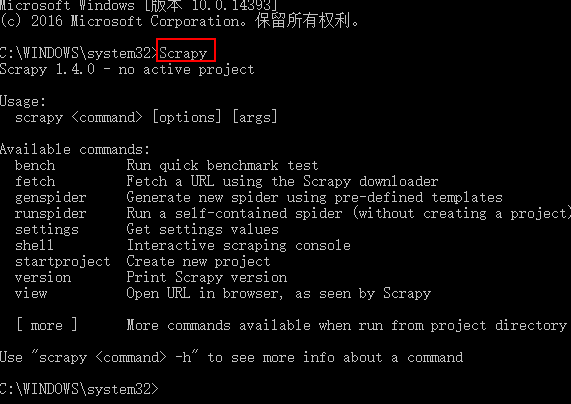
测试Scrapy是否安装成功
Scrapy框架指令
scrapy -h 查看帮助信息
Available commands:
bench Run quick benchmark test (scrapy bench 硬件测试指令,可以测试当前服务器每分钟最多能爬多少个页面)
fetch Fetch a URL using the Scrapy downloader (scrapy fetch http://www.iqiyi.com/ 获取一个网页html源码)
genspider Generate new spider using pre-defined templates ()
runspider Run a self-contained spider (without creating a project) ()
settings Get settings values ()
shell Interactive scraping console ()
startproject Create new project (cd 进入要创建项目的目录,scrapy startproject 项目名称 ,创建scrapy项目)
version Print Scrapy version ()
view Open URL in browser, as seen by Scrapy ()
创建项目以及项目说明
scrapy startproject adc 创建项目
项目说明
目录结构如下:
├── firstCrawler
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg

项目指令
项目指令是需要cd进入项目目录执行的指令
scrapy -h 项目指令帮助
Available commands:
bench Run quick benchmark test
check Check spider contracts
crawl Run a spider
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version (scrapy version 查看scrapy版本信息)
view Open URL in browser, as seen by Scrapy (scrapy view http://www.zhimaruanjian.com/ 下载一个网页并打开)
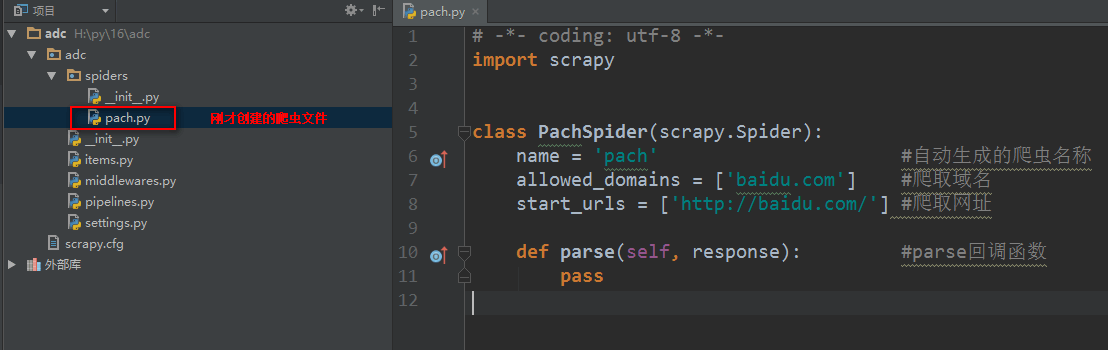
创建爬虫文件
创建爬虫文件是根据scrapy的母版来创建爬虫文件的
scrapy genspider -l 查看scrapy创建爬虫文件可用的母版
Available templates:母版说明
basic 创建基础爬虫文件
crawl 创建自动爬虫文件
csvfeed 创建爬取csv数据爬虫文件
xmlfeed 创建爬取xml数据爬虫文件
创建一个基础母版爬虫,其他同理
scrapy genspider -t 母版名称 爬虫文件名称 要爬取的域名 创建一个基础母版爬虫,其他同理
如:scrapy genspider -t basic pach baidu.com
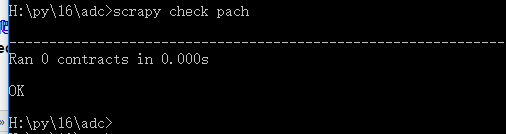
scrapy check 爬虫文件名称 测试一个爬虫文件是否合规
如:scrapy check pach
scrapy crawl 爬虫名称 执行爬虫文件,显示日志 【重点】
scrapy crawl 爬虫名称 --nolog 执行爬虫文件,不显示日志【重点】


