CTF编码知识点
计算机中的数据都是按字节存储。一个字节(Byte)由8个二进制位组成(bit)。(组成范围是0~255(2^8)) 一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。为什么需要编码呢,
我们知道,所有的信息最终都表示为一个二进制的字符串,每一个二进制位(bit)有0和1两种状态。当我们需要把字符'A'存入计算机时,应该对应哪种状态呢,存储时,我们可以将字符'A'用01000010(这个随便编的)二进制字符串表示,存入计算机;读取时,再将01000010还原成字符'A'。那么问题来了,存储时,字符'A'应该对应哪一串二进制数呢,是01000010?或者是10000000 11110101?说白了,就是需要一个规则。这个规则可以将字符映射到唯一一种状态(二进制字符串),这就是编码。而最早出现的编码规则就是ASCII编码,在ASCII编码规则中,字符'A'既不对应01000010,也不对应1000 0000 11110101,而是对应01000001(不要问为什么,这是规则)。下面介绍的编码方式就是我们的规则。
1.ASCII编码
http://c.biancheng.net/c/ascii/
总共128个字符,一个字符占一个字节。使用该编码方式时二进制、十进制和十六进制表示字符的方式都在该链接的ASCII表中有所体现。
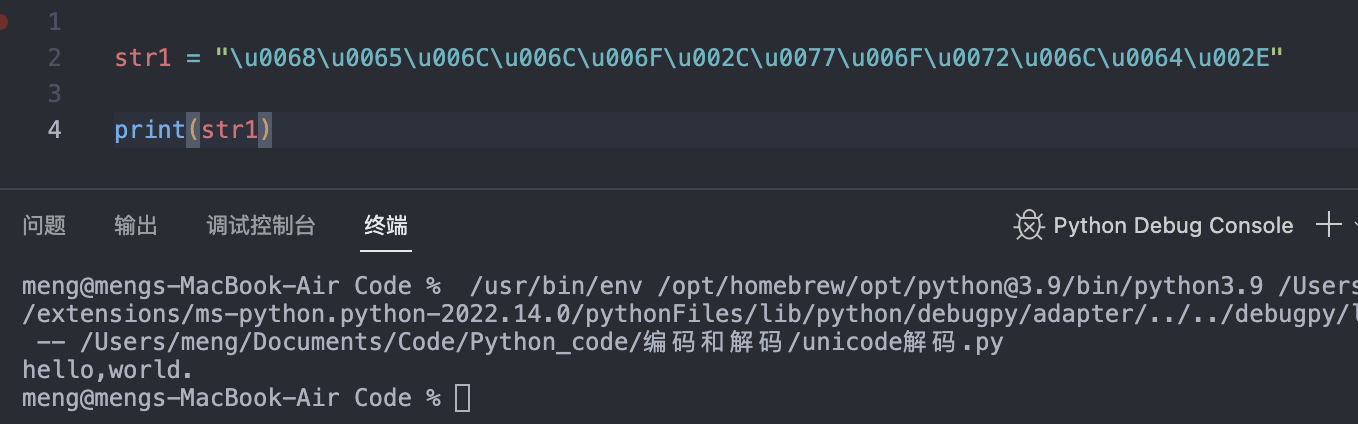
2.Unicode编码
它用两个字节来编码一个字符,字符编码一般用十六进制来表示。共用四种编码方式如下:
&#x [hex]:hello,world.
&# [Decimal]:hello,world.
\u [hex]:\U0068\U0065\U006C\U006C\U006F\U002C\U0077\U006F\U0072\U006C\U0064\U002E
\u+ [hex]:\U+0068\U+0065\U+006C\U+006C\U+006F\U+FF0C\U+0077\U+006F\U+0072\U+006C\U+0064\U+002E
下面是常用编码方式和解码方式。
3.UTF-8
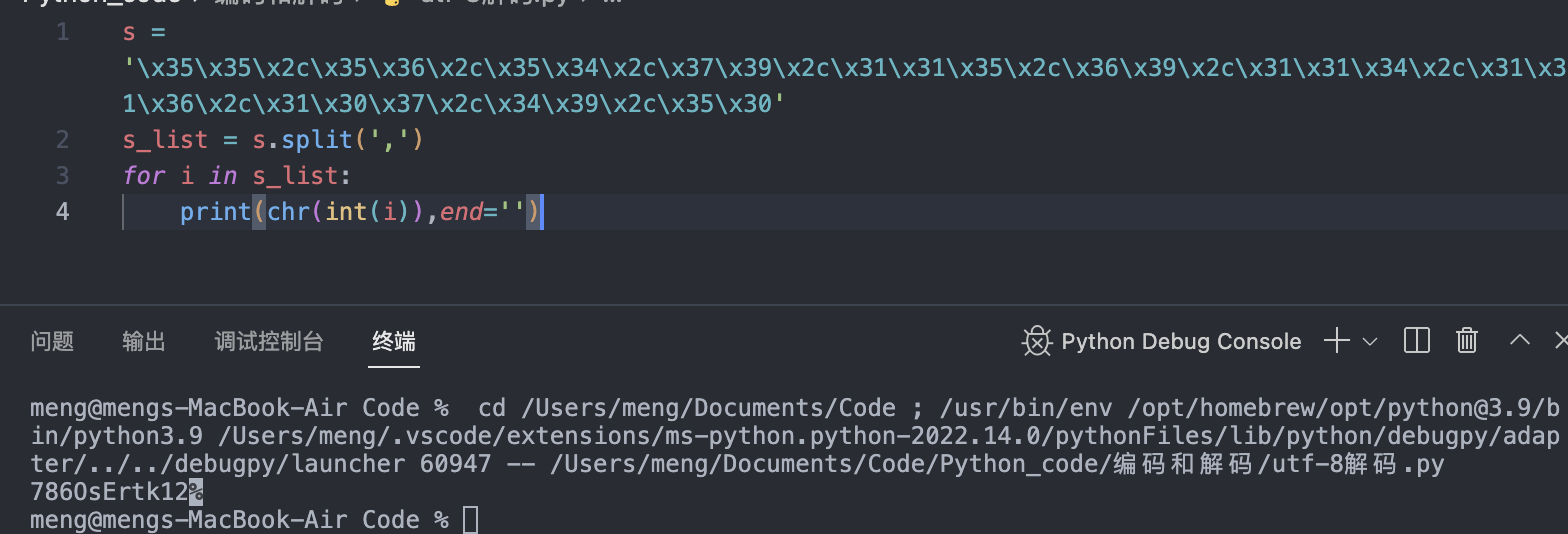
常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。对于英文字符来说UTF-8与ASCII的编码结果无异。此外,UTF-8、UTF-16、UTF-32都是针对Unicode的再一次编码。下面是常用编码方式和解码方式。
4.URL编码
url编码又叫百分号编码,是统一资源定位(URL)编码方式。URL地址(常说网址)规定了常用地数字,字母可以直接使用,另外一批作为特殊用户字符也可以直接用(/,:@等),剩下的其它所有字符必须通过%xx编码处理。如空格字符,ascii码是32,对应16进制是‘20’,那么urlencode编码结果是:%20。
5.Hex编码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号