AWK基础讲解及grep用法
一、AWK
如下图awk命令是一个比较完整的整个流程
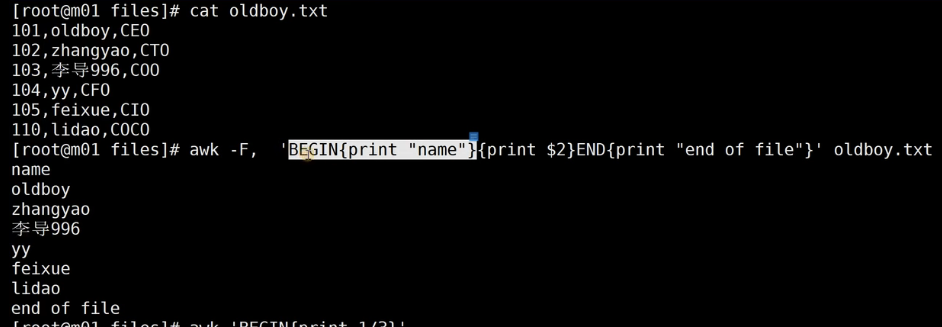
-F :表示指定分隔符号相当于内置变量NS(分隔符号一般利用双引号或者单引号括起来)
BEGIN{}:表示一开始awk要处理内容(不是必要的)
END{}:表示awk最后要处理内容(不是必要的)
$2:表示取出第二列
最后是我们要处理的文本
补充:awk语句要写在 '' 单引号之内
不过一般情况下都是直接
-F' ' '{print $1}'
没有啥begin,end再看一个示例: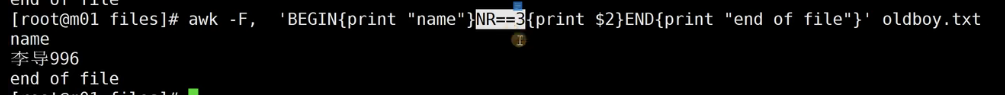
花括号外面的表示条件,而这里的NR是内置变量,意思是行数,表示第几行。
取出数据以后如果有点乱可以加上 |column -t
例如:
ls -l | awk -F',' '{print $1,$5}' | column -t内建变量
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 各文件分别计数的行号 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | 一条记录的字段的数目 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出字段分隔符,默认值与输入字段分隔符一致。 |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
二、grep用法
1.过滤不想要的数据,过滤后的数据中不含有hithub或meng。
|grep -v "hithub\|meng"
