C语言进阶
1、C语言的精髓--指针
指针就是地址,在一定程度上可以把数组名就看成一个特殊的指针,指针也就是一个变量而已,指针全名指针变量。
(1)指针数组
指针数组,是个数组,里边放的东西都是指针。char *p[2]={"china","linux"};
仔细来说,从运算符优先级来看,[]的优先级比*高,所以p先和[]结合。所以这就是个数组,再与指针结合,所以叫指针数组。
二重指针可以指向指针数组。
(2)数组指针
数组指针,是个指针,指向数组的指针.
int a[2][5]={0};
int (*p)[5]=a; //指向二维数组
int b[2][3][4] = {0}; // 多维数组
int(*q)[3][4] = b;
这里指针是在()中放着,())和[]优先级都是最高的,结合性是从左向右,所以先与*结合,这是个指针,然后与[]结合,就是指针数组。
(3)函数指针
int (*p)(int a,char b);// 函数指针p指向返回值类型为int的,两个参数为int和char的函数
使用方法如下,
p(a,b);
或者
(*p)(a,b);
void *类型可以指向任何一个类型的指针
void (*signal(int sig, void (*func) (int))) (int)
signal仍然是一个函数,他返回一个函数指针,这个指针指向的函数没有返回值,只有一个int类型的参数
(4)二维数组
a[5][7];//用指针访问就是*(*(p+5)+7)
int (*p)[7]=a;
(5)字符数组与指向字符串指针的问题
其中char *p="linux" 这种情况字符串Linux只存在于只读数据段中(rodata),所以p所指向的内容不可以被更改,如*(p+1)=a;这是实现不了的,但是可以更改指针p 指向的地址,例如p="mengchao",但是这里的p="mengchao"这段话放在子函数中是不可以的,字符串mengchao是存在于栈中,子函数结束就被释放了,不能够达到改变的目的。可以使用二重指针来实现。
char p[]="linux" 这个是字符数组,相当于初始化数组,可以更改内容,如p[1]='a';* 这里Linux存在于栈上
所以有的字符串操作函数例如char *strcat(char *dst,char const *src);前面的参数dst,需要修改,只能传数组,不能直接传一个字符串,因为字符串不可改变
所以想修改字符串,请将他放在字符数组中。 另外关于这个程序
char c = 'a';
char *p = &c;
char *q = "china";
printf("%p\n",p); //006DFEE7
printf("%c\n",*p); //a
cout << *p << endl; //a
printf("%p\n",q); //004B9024
printf("%s\n",q); //china
cout << q << endl; //china
cout << *q << endl; //c
这里想插一句关于strlen和sizeof的区别。比如我们定义char buf[100]={"helloworld"}; strlen(buf);就是里边字符串的长度,而sizeof(buf);就是数组长度100.
一定程度上可以认为一级指针与一维数组名等价,二级指针与指针数组名等价,数组指针与二维数组名等价。而二级指针和二维数组名没有一毛钱关系。
(6)数组名
数组名可以看成是首元素的首地址,也可以当成一个整体来看。数组名是常量,才可以唯一的确定数组元素的起始地址。设有一维数组int a[5]:
a[1] = *(a+1); //a代表首元素首地址,加1跨度为int大小为4
**对一维数组名和二维数组名引用(取地址)**对一维数组名进行引用会将使其升级为二维数组名。
(&a+1)//这个东西加1,加的大小是整个数组的大小,是20.
二维数组名解引用,降维为一维数组名。二维数组名是首元素首地址,设有int a[4][3],则
*(a+1) //代表的是二维数组的第二维
a[1][2] = *(*(a+1)+2)
注意下面的问题
*p++:等同于:*p; p += 1;先运算再++
解析:由于*和++的运算优先级一样,且是右结合。故*p++相当于*(p++),p先与++结合,然后p++整体再与*结合。前面陈述是一种最常见的错误,很多初学者也是这么理解的。但是,因为++后置的时候,本身含义就是先运算后增加1(运算指的是p++作为一个整体与前面的*进行运算;增加1指的是p+1),所以实际上*p++符号整体对外表现的值是*p的值,运算完成后p再加1.
【注意】是运算后p再加1,而不是p所指向的变量*p再加1
*++p:等同于 p += 1; *p;先++再运算
解析:由于++在p的前面,++前置的含义是,先加1,得到一个新的p(它的值是原来p的值加1)。然后这个新的p再与前面的*结合.
【总结】无论是*p++还是*++p,都是指针p += 1,即p的值+1,而不是p所指向的变量*p的值+1。
++前置与++后置,只是决定了到底是先p += 1,还是先*p。++前置表示先p += 1,再*p。++后置表示先*p,在p += 1;
--前置与--后置的的分析方法++前置与++后置的一样。
2、进程空间
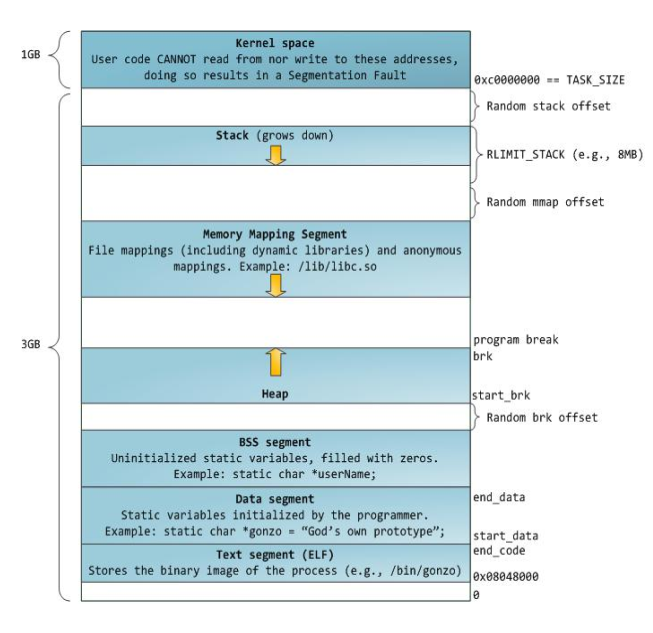
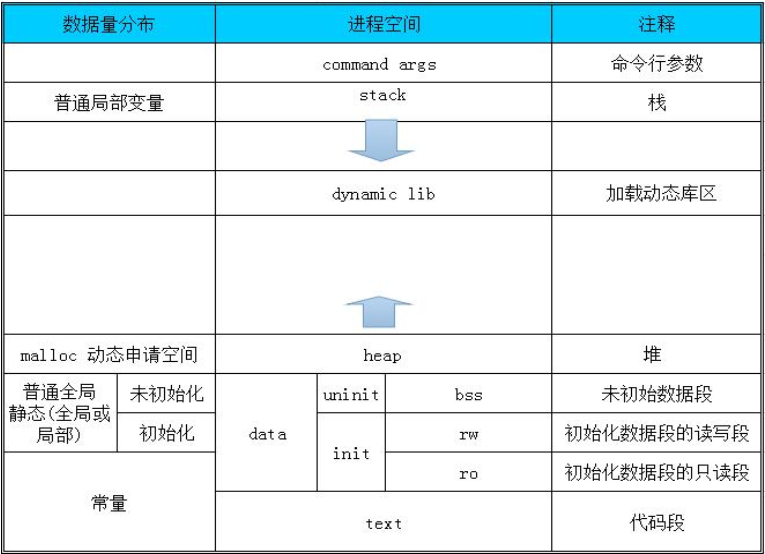
全局变量:不初始化的默认为0,放在.bss段,初始化为0的也放在.bss段
初始化为非0的全局变量放在.data段中,生命周期全局
局部变量放在栈上,当调用结束,生命周期结束
3、结构体
《道德经》 曰:"一生二,二生三,三生万物"。结构体用关键字 struct 定义,表达出多个不同变量在一起的类型。我们由此可以使用struct自定义几乎所有想要的类型。
结构体的定义:
struct student
{
char name[30];
char sex;
int age;
float high;
}stu1;//这里定义了一个变量stu1
struct student stu2;//这里定义了一个变量stu2
这种定义出来的结构体类型在定义变量时必须跟着struct,就像struct student stu1;一样,我们引入typedef,避免这种情况。
typedef struct student
{
char name[30];
char sex;
int age;
float high;
}STUDENT;//将struct student类型重命名为STUDENT
STUDENT stu, stu2;//使用STUDENT替换struct student定义变量
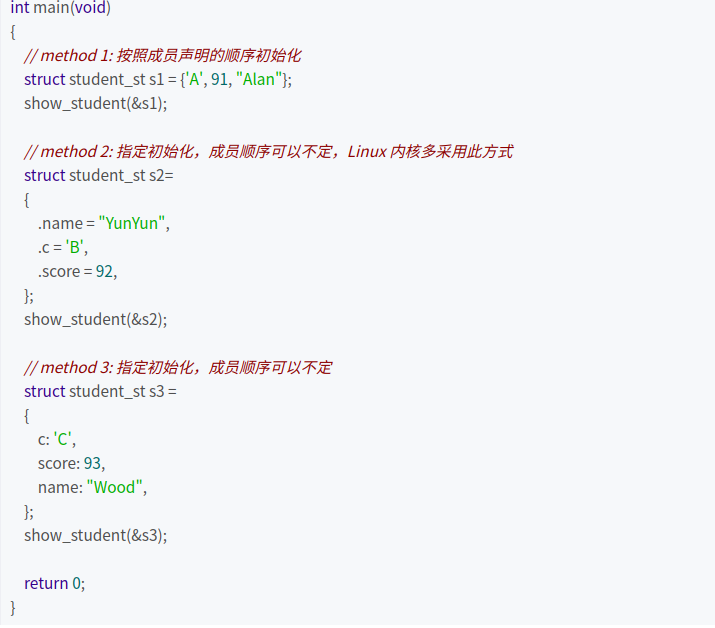
结构体变量初始化及成员访问
定义的结构体变量用点成员运算符(.)访问成员变量,比如stu.sex就这样访问成员变量。如果是结构体类型的指针变量则使用->访问成员变量。STUDENT stu; stu->sex = 'x';初始化大概有三种方法。
结构体大小
设计内存对齐
struct Date
{
char a;
int b;
int64_t c;
char d;
};
Date data [2][10];
结构体所占的内存大小 a.整体所占的内存大小应该是结构中成员类型最大的整数倍,此处最大的类型是int_64t,占8个字节。即最后所占字节的总数应该是8的倍数,不足的补足 b.数据对齐原则-内存按结构体成员的先后顺序排列,当排到该成员变量时,其前面所有成员已经占用的空间大小必须是该成员类型大小的整数倍,如果不够,则前面的成员占用的空间要补齐,使之成为当前成员类型的整数倍。假设是地址是从0开始,结构体中第一个成员类型char型占一个字节,则内存地址0-1,第二成员从2开始,int型所占内存4个字节根据原则b,第一个成员所占内存补齐4的倍数,故第一个成员所占内存:1+3=4;第二个成员占5-8.第三个成员占8个字节,满足原则b,不需要补齐,占9-16第四个成员占一个字节,占17.故总内存为1+3+4+8+1=17个字节,但根据原则1总字节数需是8的倍数,需将17补齐到24.故此结构体总字节数为:24字节
4、一些关键字的详解
inline
在c/c++中,为了解决一些频繁调用的小函数大量消耗栈空间(栈内存)的问题,特别的引入了inline修饰符,表示为内联函数。栈空间就是指放置程序的局部数据(也就是函数内数据)的内存空间。 inline的使用是有所限制的,inline只适合涵数体内代码简单的涵数使用,不能包含复杂的结构控制语句例如while、switch,并且不能内联函数本身不能是直接递归函数(即,自己内部还调用自己的函数)。 inline函数仅仅是一个对编译器的建议,所以最后能否真正内联,看编译器的意思,它如果认为函数不复杂,能在调用点展开,就会真正内联,并不是说声明了内联就会内联,声明内联只是一个建议而已。
inline函数的定义放在头文件中
其次,因为内联函数要在调用点展开,所以编译器必须随处可见内联函数的定义,要不然就成了非内联函数的调用了。所以,这要求每个调用了内联函数的文件都出现了该内联函数的定义。 因此,将内联函数的定义放在头文件里实现是合适的,省却你为每个文件实现一次的麻烦。 声明跟定义要一致:如果在每个文件里都实现一次该内联函数的话,那么,最好保证每个定义都是一样的,否则,将会引起未定义的行为。如果不是每个文件里的定义都一样,那么,编译器展开的是哪一个,那要看具体的编译器而定。所以,最好将内联函数定义放在头文件中。
注:之所以定义放在头文件中,是因为inline是在编译阶段展开的,并不是连接源文件。
static
static别的东西不想说,就说static在修饰局部变量的时候,函数结束此时局部变量并不会被释放,并且修饰的局部变量的值是一直保存的,类似于全局变量,但是还是只能在这个函数内才能访问
const
const又叫常变量,修饰的变量一般不能被更改。但是在C语言中这是假的,通过定义一个指针,修改指针指向的内存依旧可以更改const修饰的变量。在C++中才是真正的const,无法修改。 const一般出现在参数列表中,意味着这个变量在函数中并不会被修改,是输入型参数。
volatile
这个volatile,英文名易变的。因为访问寄存器要比访问内存单元快的多,所以编译器一般都会作减少存取内存的优化,但有可能会读脏数据。当要求使用volatile声明变量值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。 精确地说就是,遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问;如果不使用valatile,则编译器将对所声明的语句进行优化。
5、多文件编程
一个简单的例子 全局变量最好声明为 static,只在当前文件中可见,不要对外暴露;如果必须对外暴露,可以使用宏定义代替,请看下面的代码。 main.c 源码:
#include <stdio.h>
#include <conio.h>
#include "module.h"
int main()
{
int n1 = 1, n2 = 100;
printf("从%d 加到%d 的和为%ld [By %s]", n1, n2, sum(n1, n2), OS);
getch();
return 0;
}
module.c 源码:如果使用了头文件中的宏定义,这里也是需要包含头文件的
#include <stdio.h>
#include "module.h"
long sum(int fromNum, int endNum)
{
int i;
long result = 0;
// 参数不符合规则,返回 -1
if(fromNum<0 || endNum<0 || endNum<fromNum){
return -1;
}
for(i=fromNum; i<=endNum; i++){
result += i;
}
// 返回大于等于 0 的值
return result;
}
module.h 源码:
#ifndef __MODULE_H_
#define __MODULE_H_
// 用宏定义来代替全局变量
#define OS "Windows 7"
// 也可以省略 extern;不过为了程序可读性,建议写上
extern long sum(int, int);
#endif
多个.c文件的时候,也可以只用一个.h头文件,然后都包含以下这个.h文件
6、文件操作
https://www.cnblogs.com/wuqianling/p/5340719.html这篇文章写的就不错。
主要是文件操作分为二进制文件和文本文件,fopen打开的时候设置打开模式,返回值问FILE*类型的一个文件指针。通过这个文件指针就可以访问这个文件。
7、编码规范
for while等关键字和括号之间留出一个空格,突出关键字,for后哪怕只有一行也写{} 注释的双斜线之后要有一个空格,突出注释 函数名和类使用大驼峰命名法首个单词大写,变量使用小驼峰命名法第一个字母小写 类和函数写完之后要空一行 分号、逗号前边不空格,后边留空格。双目运算符两边留空格
作者: mengchao
出处:https://www.cnblogs.com/meng-chao/p/14060560.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!