
Python学习第二天
一、模块
使用模块前需在代码最前声明(import)
二、数据类型
1、数字
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
(在Python3中没有long类型)
float(浮点型)
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
2、布尔值
真或假
1 或 0
3、字符串
"hello world"
字符串格式化输出
1 name = "alex" 2 print "i am %s " % name
PS: 字符串是 %s;整数 %d;浮点数%f
字符串常用功能:
- 移除空白
- 分割
- 长度
- 索引
- 切片
4、列表
创建列表:
1 name_list = ['zyx', 'seven', 'eric'] 2 或 3 name_list = list(['zyx', 'seven', 'eric'])
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
5、元组(不可变列表)
创建元组:
1 ages = (11, 22, 33, 44, 55) 2 或 3 ages = tuple((11, 22, 33, 44, 55))
6、字典(无序)
创建字典:
1 person = {"name": "mr.wu", 'age': 18} 2 或 3 person = dict({"name": "mr.wu", 'age': 18})
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
三、数据运算
算数运算:
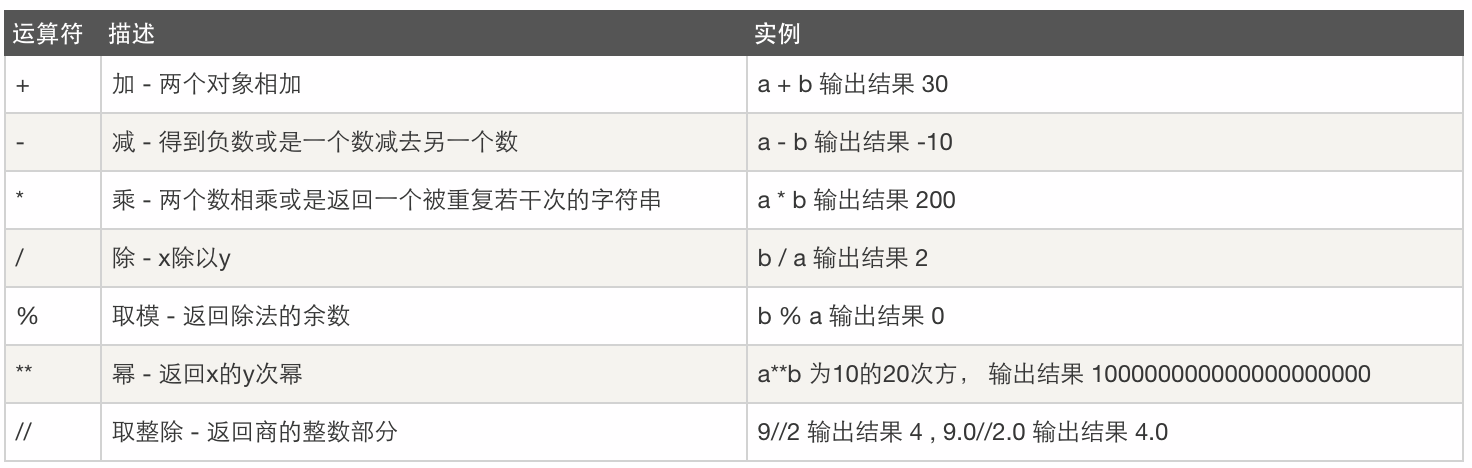
比较运算:

赋值运算:

逻辑运算:

成员运算:

身份运算:

位运算:

四、列表、元组操作
定义列表
1 names = ['Alex',"Tenglan",'Eric']
通过下标访问列表中的元素,下标从0开始计数
1 >>> names[0] 2 'Alex' 3 >>> names[2] 4 'Eric' 5 >>> names[-1] 6 'Eric' 7 >>> names[-2] #还可以倒着取 8 'Tenglan'
切片:取多个元素


1 >>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"] 2 >>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4 3 ['Tenglan', 'Eric', 'Rain'] 4 >>> names[1:-1] #取下标1至-1的值,不包括-1 5 ['Tenglan', 'Eric', 'Rain', 'Tom'] 6 >>> names[0:3] 7 ['Alex', 'Tenglan', 'Eric'] 8 >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样 9 ['Alex', 'Tenglan', 'Eric'] 10 >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写 11 ['Rain', 'Tom', 'Amy'] 12 >>> names[3:-1] #这样-1就不会被包含了 13 ['Rain', 'Tom'] 14 >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个 15 ['Alex', 'Eric', 'Tom'] 16 >>> names[::2] #和上句效果一样 17 ['Alex', 'Eric', 'Tom']
追加
1 >>> names 2 ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的'] 3 >>> names.insert(2,"强行从Eric前面插入") 4 >>> names 5 ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的'] 6 7 >>> names.insert(5,"从eric后面插入试试新姿势") 8 >>> names 9 ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
修改
1 >>> names 2 ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的'] 3 >>> names[2] = "该换人了" 4 >>> names 5 ['Alex', 'Tenglan', '该换人了', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
删除
1 >>> del names[2] 2 >>> names 3 ['Alex', 'Tenglan', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的'] 4 >>> del names[4] 5 >>> names 6 ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的'] 7 >>> 8 >>> names.remove("Eric") #删除指定元素 9 >>> names 10 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', '我是新来的'] 11 >>> names.pop() #删除列表最后一个值 12 '我是新来的' 13 >>> names 14 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy']
扩展
1 >>> names 2 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy'] 3 >>> b = [1,2,3] 4 >>> names.extend(b) 5 >>> names 6 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
拷贝(浅copy)
1 >>> names 2 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3] 3 4 >>> name_copy = names.copy() 5 >>> name_copy 6 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
统计
1 >>> names 2 ['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3] 3 >>> names.count("Amy")
排序&翻转
1 >>> names 2 ['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3] 3 >>> names.sort() #排序 4 Traceback (most recent call last): 5 File "<stdin>", line 1, in <module> 6 TypeError: unorderable types: int() < str() #3.0里不同数据类型不能放在一起排序了,擦 7 >>> names[-3] = '1' 8 >>> names[-2] = '2' 9 >>> names[-1] = '3' 10 >>> names 11 ['Alex', 'Amy', 'Amy', 'Tenglan', 'Tom', '1', '2', '3'] 12 >>> names.sort() 13 >>> names 14 ['1', '2', '3', 'Alex', 'Amy', 'Amy', 'Tenglan', 'Tom'] 15 16 >>> names.reverse() #反转 17 >>> names 18 ['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '3', '2', '1']
获取下标
1 >>> names 2 ['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '3', '2', '1'] 3 >>> names.index("Amy") 4 2 #只返回找到的第一个下标
元组
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
它只有2个方法,一个是count,一个是index
五、字符串操作
特性:不可修改
1 name.capitalize() 首字母大写 2 name.casefold() 大写全部变小写 3 name.center(50,"-") 输出 '---------------------Alex Li----------------------' 4 name.count('lex') 统计 lex出现次数 5 name.encode() 将字符串编码成bytes格式 6 name.endswith("Li") 判断字符串是否以 Li结尾 7 "Alex\tLi".expandtabs(10) 输出'Alex Li', 将\t转换成多长的空格 8 name.find('A') 查找A,找到返回其索引, 找不到返回-1 9 10 format : 11 >>> msg = "my name is {}, and age is {}" 12 >>> msg.format("alex",22) 13 'my name is alex, and age is 22' 14 >>> msg = "my name is {1}, and age is {0}" 15 >>> msg.format("alex",22) 16 'my name is 22, and age is alex' 17 >>> msg = "my name is {name}, and age is {age}" 18 >>> msg.format(age=22,name="ale") 19 'my name is ale, and age is 22' 20 format_map 21 >>> msg.format_map({'name':'alex','age':22}) 22 'my name is alex, and age is 22' 23 24 25 msg.index('a') 返回a所在字符串的索引 26 '9aA'.isalnum() True 27 28 '9'.isdigit() 是否整数 29 name.isnumeric 30 name.isprintable 31 name.isspace 32 name.istitle 33 name.isupper 34 "|".join(['alex','jack','rain']) 35 'alex|jack|rain' 36 37 38 maketrans 39 >>> intab = "aeiou" #This is the string having actual characters. 40 >>> outtab = "12345" #This is the string having corresponding mapping character 41 >>> trantab = str.maketrans(intab, outtab) 42 >>> 43 >>> str = "this is string example....wow!!!" 44 >>> str.translate(trantab) 45 'th3s 3s str3ng 2x1mpl2....w4w!!!' 46 47 msg.partition('is') 输出 ('my name ', 'is', ' {name}, and age is {age}') 48 49 >>> "alex li, chinese name is lijie".replace("li","LI",1) 50 'alex LI, chinese name is lijie' 51 52 msg.swapcase 大小写互换 53 54 55 >>> msg.zfill(40) 56 '00000my name is {name}, and age is {age}' 57 58 59 60 >>> n4.ljust(40,"-") 61 'Hello 2orld-----------------------------' 62 >>> n4.rjust(40,"-") 63 '-----------------------------Hello 2orld' 64 65 66 >>> b="ddefdsdff_哈哈" 67 >>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则 68 True
六、字典操作
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
1 info = { 2 'stu1101': "TengLan Wu", 3 'stu1102': "LongZe Luola", 4 'stu1103': "XiaoZe Maliya", 5 }
字典的特性:
- dict是无序的
- key必须是唯一的,so 天生去重
增加
1 >>> info["stu1104"] = "苍井空" 2 >>> info 3 {'stu1102': 'LongZe Luola', 'stu1104': '苍井空', 'stu1103': 'XiaoZe Maliya', 'stu1101': 'TengLan Wu'}
修改
1 >>> info['stu1101'] = "武藤兰" 2 >>> info 3 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'}
删除
1 >>> info 2 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'} 3 >>> info.pop("stu1101") #标准删除姿势 4 '武藤兰' 5 >>> info 6 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} 7 >>> del info['stu1103'] #换个姿势删除 8 >>> info 9 {'stu1102': 'LongZe Luola'} 10 >>> 11 >>> 12 >>> 13 >>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} 14 >>> info 15 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} #随机删除 16 >>> info.popitem() 17 ('stu1102', 'LongZe Luola') 18 >>> info 19 {'stu1103': 'XiaoZe Maliya'}
查找
1 >>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} 2 >>> 3 >>> "stu1102" in info #标准用法 4 True 5 >>> info.get("stu1102") #获取 6 'LongZe Luola' 7 >>> info["stu1102"] #同上,但是看下面 8 'LongZe Luola' 9 >>> info["stu1105"] #如果一个key不存在,就报错,get不会,不存在只返回None 10 Traceback (most recent call last): 11 File "<stdin>", line 1, in <module> 12 KeyError: 'stu1105'
多级字典嵌套及操作
1 av_catalog = { 2 "欧美":{ 3 "www.youporn.com": ["很多免费的,世界最大的","质量一般"], 4 "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], 5 "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], 6 "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"] 7 }, 8 "日韩":{ 9 "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"] 10 }, 11 "大陆":{ 12 "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"] 13 } 14 } 15 16 av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来" 17 print(av_catalog["大陆"]["1024"]) 18 #ouput 19 ['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
其他
1 #values 2 >>> info.values() 3 dict_values(['LongZe Luola', 'XiaoZe Maliya']) 4 5 #keys 6 >>> info.keys() 7 dict_keys(['stu1102', 'stu1103']) 8 9 10 #setdefault 11 >>> info.setdefault("stu1106","Alex") 12 'Alex' 13 >>> info 14 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} 15 >>> info.setdefault("stu1102","龙泽萝拉") 16 'LongZe Luola' 17 >>> info 18 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} 19 20 21 #update 22 >>> info 23 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} 24 >>> b = {1:2,3:4, "stu1102":"龙泽萝拉"} 25 >>> info.update(b) 26 >>> info 27 {'stu1102': '龙泽萝拉', 1: 2, 3: 4, 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} 28 29 #items 30 info.items() 31 dict_items([('stu1102', '龙泽萝拉'), (1, 2), (3, 4), ('stu1103', 'XiaoZe Maliya'), ('stu1106', 'Alex')]) 32 33 34 #通过一个列表生成默认dict,有个没办法解释的坑,少用吧这个 35 >>> dict.fromkeys([1,2,3],'testd') 36 {1: 'testd', 2: 'testd', 3: 'testd'}
循环dict
1 #方法1 2 for key in info: 3 print(key,info[key]) 4 5 #方法2 6 for k,v in info.items(): #会先把dict转成list,数据里大时莫用 7 print(k,v)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号