第 6 章 用户画像系统
用户画像的概念和作用
- 字面上, 用户画像核心作用是对系统的用户进行多维度的信息刻画;
- 深层次, 通过对用户多维度的刻画, 将不同的用户映射到产品所提供的不同服务上, 或映射到同一服务的不同具体形态上;
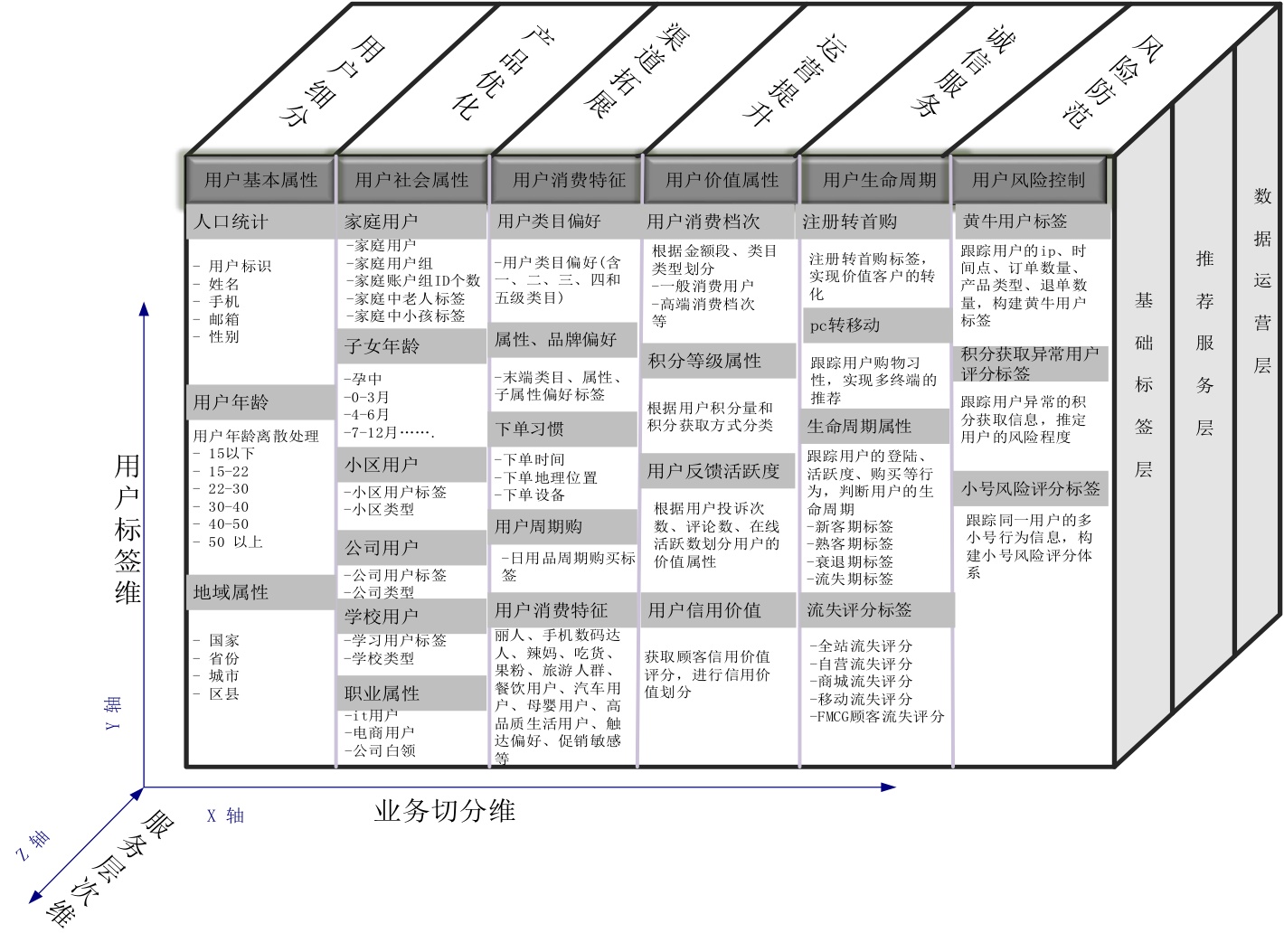
推荐系统的用户画像取上图中可以将用户和系统中物品连接起来的格子;
基于算法二次加工后的画像数据:
- 可读性较差;
- 更强, 更综合的表达能力和连接能力;
- 自主发现, 自主更新以及可用算法持续优化;
- 可捕捉抽象层次更高, 维度更综合的信息;
推荐系统中的用户画像分:
- 显式画像数据, 基于规则生成的, 可读性好的画像;
- 隐式画像数据, 基于算法生成的, 可读性较差的画像;
常用方法: 召回(粗排), 排序;
用户画像的价值准则
- 准则一, 能够建立起用户和物品之间的
有效连接; - 准则二,
细致刻画; 根据画像数据中每个取值平均能够覆盖的用户或物品的多少来判断; - 准则三,
覆盖率; 指一份画像数据能够覆盖到多大比例的用户或物品; - 准则四,
差异化能力; 能否标识出不同用户, 能够映射到不同的物品上;
用户画像的构成要素
物品侧画像
计算用户侧画像的基础
- 对物品基础属性的客观描述
- 基于基础属性进一步计算得到的深层次特征
-
文本数据的结构化信息抽取
在分词和词性标注后, 构造一套针对自己领域和业务的知识图谱以及配套的抽取解析算法, 再根据效果反馈不断调优;
结构化信息抽取流程:
- 知识图谱构建, 要抽取的结构化信息对应的元信息及其结构关系;
- 文本预处理, 分词, 去噪, 归一化等处理;
- 结构数据解析, 映射+合并;
-
非结构化物品标签, 文本类标签数据+行为类标签数据
-
复合类型的物品画像, 对物品的深层次描述, 是基于客观属性以及行为数据, 通过算法深层次加工计算得到的;
- 物品聚类, LDA, 文本主题聚类;
- 向量化表示, word2vec
用户侧画像
大部分是通过用户与物品之间的行为计算得到; (局限性: 局限于历史兴趣范围内, 不能给出用户未曾有过行为的兴趣维度)
输入 = 用户行为序列 + 物品的多维度画像;
输出 = 建立在物品画像基础上, 用户对每个维度画像的兴趣 map;
见文末的用户画像系统架构图
常用用户画像的计算方式:
-
时间衰减法
用户对某个维度的兴趣在行为刚产生时最大, 随着时间不断衰减, 直到可忽略不计;
兴趣的初始最大值, 衰减方式;
\[w_t = w_0 \times e^{-\alpha \times \delta_t} \]\(w_t\) 时间 t 对应的兴趣权重; \(w_0\) 初始兴趣权重, \(\delta_t\) 时刻 t 相比初始时刻过去的时间;
选择指数函数原因:
- 初始衰减快, 后期衰减慢;
- 两个时间点 \(t_1\) 和 \(t_2\) 下兴趣值的关系: \(w_{t_2} = w_{t_1} \times e^{-\alpha \times \delta_{t_2-t_1}}\) , 即只需要存储用户对一个兴趣维度在任意时刻的兴趣值和时间戳, 就可以完成后面任意时刻兴趣值的计算;
\(w_0\) 初期根据业务经验调整;
\(\alpha\), 兴趣的衰减速度, 以"半衰期"计算值, \(0.5x=x \times e^{-\alpha \times \delta_0}\)
时间衰减法的流程:
-
为不同类型的画像和行为设置不同的初值 \(w_0\);
-
当用户对物品产生行为时:
- 取出该物品所有可用维度的画像;
- 根据画像类型和行为类型设置兴趣度初值 \(w_0\), 即重置为最大值;
- 将各维度画像按照兴趣度排序存储在兴趣列表中;
-
每次更新用户的画像兴趣度时, 对所有画像维度的兴趣度进行衰减更新, 更新后低于所设置的阈值就从列表中删除, 并将剩余结果进行排序, 以减少后期读写压力;
-
在使用用户画像时, 首先从存储列表中读取对应维度的画像, 并使用时间差进行时间衰减更新, 然后在下游流程中使用;
缺点:
- 个性化程度不足, 初值 \(w_0\) 和衰减速度 \(\alpha\) 对所有用户都一样;
- 难易实现兴趣度加强, 每次的重置最大值, 导致无法根据前置行为而加强兴趣度;
- 无法体现不同画像维度之间的相互影响;
-
分析模型预测法
将用户对某个维度画像的兴趣投射到具体行为上, 把这个行为产生与否建模成二分类问题;
-
向量(嵌入)表示类画像方法
数据特点: N 维的稠密连续向量, 作为一个整体对待;
函数: 输入是代表用户对象画像历史行为的若干向量表示的画像数据; 输出是一个或多个代表用户当前兴趣的向量;
- 对历史行为对应的向量取一个平均向量作为当前的兴趣向量;
- 对近期不同的行为给与不同的权重, 带权平均; 注意力机制;
用户画像扩展
除了基于历史兴趣给出当前兴趣, 需要一些其他方法对用户兴趣进行发散扩展, 保证推荐具有一定的新鲜度和惊喜度;
- 基于行为的画像关联挖掘
一跳相似度, 如果有大量用户同时访问了两个物品, 基于此计算出两者之间的相似度;
基于行为的相关性算法缺陷:
- 稀疏型严重
- 覆盖率低
- 对冷启动不友好
- 只是记忆发生过的事实, 没有学习到事实背后的根本原因
-
基于知识图谱的相关性计算推理
基于路径的方法
- 精准性
- 多样性
- 可解释性
-
用户画像和排序特征的关系
用户画像的维度都可作为排序特征;
所有的排序特征也可以用作用户画像;
本质都是区别用户和物品的关系;
区别: 用户画像看重可解释性, 排序特征对可解释性要求不高(例如为了降低特征维度, 会对原始特征用 PCA 等方法降维, 降维后可解释性就大打折扣);
用户画像系统的架构演进
组成部分
用户画像系统 = 物品画像 + 基于物品画像使用各种算法生成的用户画像
三个子模块:
- 生产模块, 使用具体算法生产出具体的画像数据, 关注用户画像数据生产的效率, 覆盖率和可扩展性等;
- 传输模块, 对接上下两个模块的数据和流程, 关注衔接是否自然流畅, 能够更好的封装屏蔽两个系统中与业务无关的部分;
- 输出模块, 负责数据对外调用或提供服务的模块, 关注系统的可用性, 数据的新鲜度, 调用的灵活性等;
野蛮生长期
通常每人都会负责生成, 存储, 提供调用以及维护等数据的全生命周期;(起步阶段必要经历, 但是不宜时间过长, 会留下技术债)
存在问题:
- 生效时间不统一
- 使用方式不统一
- 管理升级不统一
统一用户画像系统架构
物品画像系统的架构:
- 数据生产和数据服务功能分离;
- 抽象通用逻辑, 减少冗余, 提高复用性;
- 对新的画像标签数据做到兼容性强和可扩展;
- 提高数据时效性, 尽量实时生成并提供数据;
- 提供不同种类的数据服务;
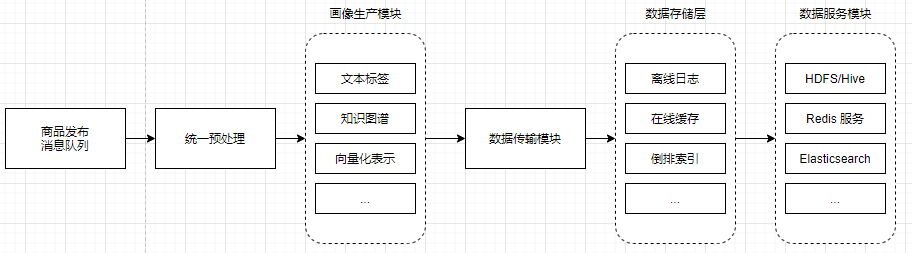
画像生产模块, 统一接收同样格式的输入, 给出同样格式的输出, 即统一的接口实现;
用户画像系统的结构:
- 基于上面物品画像数据和不同的连接算法生成用户画像数据
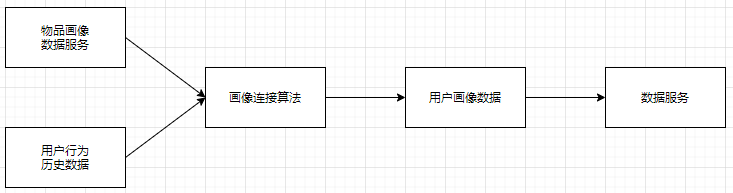
画像算法对于处理的是何种画像数据应该是无感知的;
最后的数据服务模块是必要的, 由于写入的数据并不是可直接使用的数据;
本文仅作为读书笔记使用!

欢迎您扫一扫上面的微信公众号, 订阅我的博客!
博客地址:http://www.cnblogs.com/Memento/
版权声明:Memento所有文章遵循创作共用版权协议,要求署名、非商业、保持一致。在满足创作共用版权协议的基础上可以转载,但请以超链接形式注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号