分布式架构:概述一
一:什么是分布式
互联网架构的两个特点:高并发和海量数据存储。
详解见:https://www.cnblogs.com/zhy-1992/p/9233789.html
1.任务分解
以电商平台为例子:将整个系统分为多个子系统,用户系统(部署在服务器A)、商品系统(部署在服务器B)、订单系统(部署在服务器C)、交易系统(部署在服务器D)、物流系统(部署在服务器E)
2.节点通信
每个子系统都是一个节点,节点之间通过通信进行数据交换。
3.与集群的区别
集群:将整个电商平台系统,部署在不同的服务器,不对整个系统进行划分。保证系统的高可用。
二:电商平台的架构发展
1.架构一

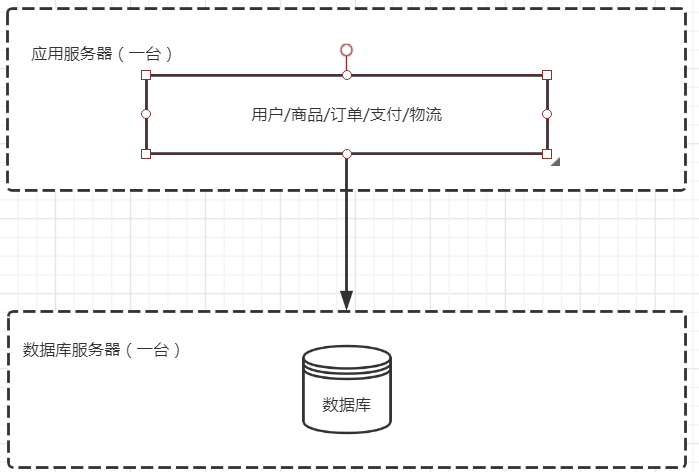
用户量上去之后,单机负载出现了性能瓶颈,服务器会出现性能问题,这时候可以考虑将数据库单独独立出来。
二:架构二,数据库服务器和应用服务器分离
3:架构三,对应用服务器进行拆分(应用服务器做集群)
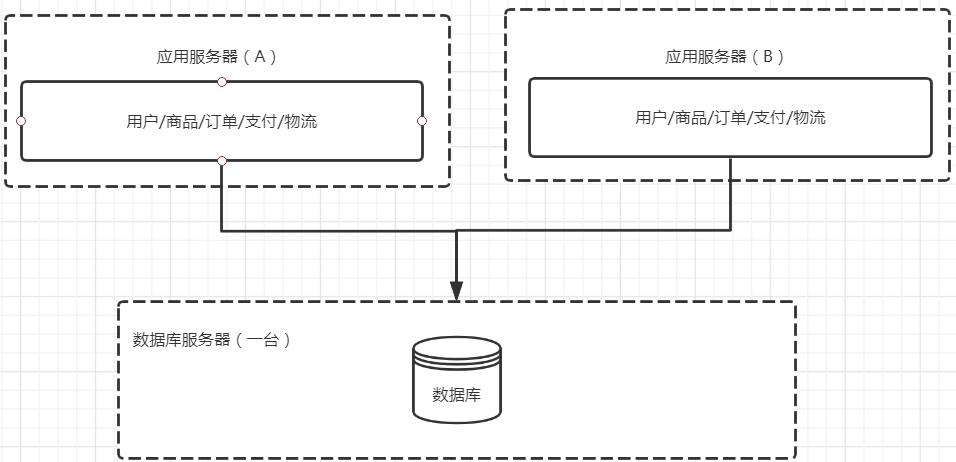
问题一:session怎么保持状态
问题二:前端的请求怎么做请求转发
4:结构四:增加负载均衡器(硬件负载均衡器或软件协议负载均衡),保证前端转发

通过负载均衡和应用服务器集群的搭配,可以解决高并发流量访问的问题,但是随着高并发流量的访问,数据库的压力就越来越大。
5:结构五:数据库的读写分离
电商系统的数据库分析,28原则,20%是数据库的写,80%是数据库的读,因此可以做数据库的读写分离
以mysql为例,支持master-sliver模式,具体讲解见:https://www.cnblogs.com/jirglt/p/3549047.html,可以做数据库同步(主从同步机制)。
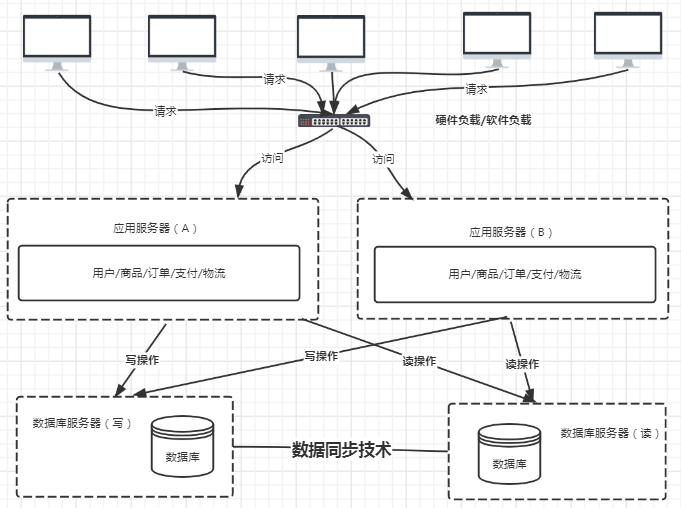
问题一:数据库读写分离怎么做?
问题二:数据库数据同步怎么做?同步不及时怎么办?
问题三:数据库路由怎么做?mycat
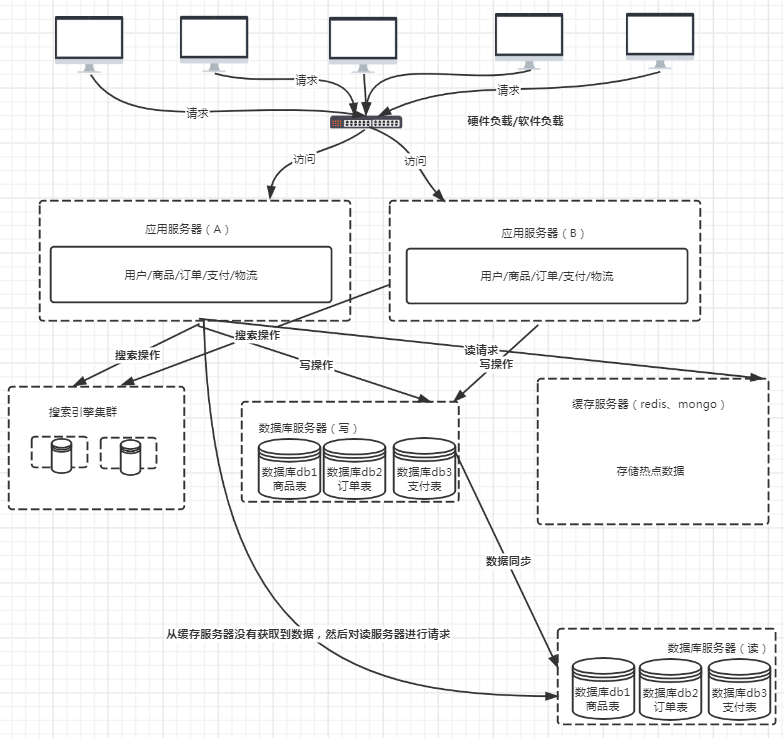
6:结构六:
电商平台最多的是搜索操作,mysql的like模糊查询可以实现,但是数据量大的时候,like查询也会有很多的问题,怎么办?
搜索引擎集群

问题一:搜索引擎的索引数据怎么同步?实时增量同步还是全局定时同步?
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
7. 结构七:访问量继续增高
三板斧:缓存、引流、降级
缓存机制:对读操作,进行缓存进制处理

应用层也可以做一些缓存,例如内存缓存,不一定要放在服务器上,比如 GuavaCache(Java的技术)。页面级缓存,前端CDN缓存
8:结构八:继续优化数据库
数据库的瓶颈:IO瓶颈、单表最大存储数据量
单表数据量建议:500万-1000万之间
数据库的水平和垂直拆分,分库分表(根据业务进行)
分库结构(垂直拆分)
数据量特别大的表,每一个表单独放入一个,database里面,而不是过去的所有表放入一个database里面,这就是表的分库,同步就应该对应用层进行拆分(垂直拆分)
下面对应用层进行垂直拆分

假如:订单服务里面有需要获取用户信息的需求,一般就写sql语句,直接获取用户的信息,但是要是其他服务里面也需要获取用户信息呢,每个服务里面都写查询用户的sql吗?那么会出现太多的冗余代码?而且用户服务和订单服务之间并没有进行通信和数据交互,如何实现让不同的服务之间能够通过通信,进行数据传递呢?
分表结构(水平拆分)
# TODO

 浙公网安备 33010602011771号
浙公网安备 33010602011771号