
协程
二:迭代器
迭代:是一种动作,访问集合元素的一种方式。
迭代器:是一种对象,可以记住遍历位置的一种对象,迭代器只能往前,知道集合中的所有元素被访问完,才会结束。
那么什么东西才能被迭代呢?也就是可以for in
可迭代对象:list tuple dict str
for i in 100: print(i) # 结果 TypeError: 'int' object is not iterable
那我们能不能自己构造一个对象,具有迭代的功能呢?
class Test(object): def __init__(self): self.box = [] def add(self,value): self.box.append(value) t = Test() t.add(1) t.add(2) t.add(3) for i in t: print(i) # 结果 TypeError: 'Test' object is not iterable
结果:也不能进行迭代
那么到底什么东西是可以被迭代的呢?那么我们就要看看可迭代对象的本质是什么?
可迭代对象的本质是:可迭代对象的本质就是可以向我们提供一个这样的中间“人”即迭代器帮助我们对其进行迭代遍历使用。
也就是说可迭代对象,必须具有迭代器。那么我们对上面的类,进行改造,增加__iter__函数,看是否是一个可以被迭代的对象。
from collections import Iterable # 导入迭代对象 class Test(object): def __init__(self): self.box = [] def add(self,value): self.box.append(value) def __iter__(self): pass t = Test() t.add(1) t.add(2) t.add(3) print(isinstance(t,Iterable)) # 判断是否是一个可以迭代对象 for i in t: print(i) # 结果 True TypeError: iter() returned non-iterator of type 'NoneType'
加上__iter__函数后,Test的实例对象就变成了了一个可迭代对象,那么为什么循环的时候报错:iter()返回的非迭代器类型为“NoneType”,也就是说__iter__函数里面的返回值有问题。
那么我们来看iter()函数
demo = [1,2,3] demo_iter = iter(demo) print(demo_iter.__next__()) print(next(demo_iter)) print(next(demo_iter)) print(next(demo_iter))
# 结果
1
2
3
StopIteration
iter(可迭代对象)函数的参数是一个可迭代对象,然后可以调用next(iter(可迭代对象))或者 iter().__next__()方法来获取可迭代对象里面的元素,元素获取结束后,再继续获取报错。
iter(可迭代对象)返回的是可迭代对象的迭代器,使用next(迭代器)函数可以通过迭代器,取出元素。
iter()函数实际上就是调用了可迭代对象的__iter__方法。也就是说明,可迭代对象的__iter__方法返回值是一个迭代器。
那我们给__iter__函数的返回值为一个可迭代对象,是不是就能够进行循环了呢?
from collections import Iterable # 导入迭代器 class Test(object): def __init__(self): self.box = [] def add(self,value): self.box.append(value) def __iter__(self): return self.box t = Test() t.add(1) t.add(2) t.add(3) for i in t: print(i) # 结果 TypeError: iter() returned non-iterator of type 'list' 更加印证了,__iter__返回值是一个迭代器,而不是迭代对象
__iter_返回值必须是一个迭代器
迭代器:一个实现了__iter__方法和__next__方法的对象,就是迭代器。迭代器也是一个对象
class Test(object): def __init__(self): self.box = [] def add(self,value): self.box.append(value) def __iter__(self): # 返回迭代器对象,self的作用是让迭代器对象可以取到self.box myiterator = MyIterator(self) return myiterator class MyIterator(): def __init__(self,myiterable): self.myiterable = myiterable # 用来记录位置 self.position = 0 def __next__(self): """循环的时候,循环器就是调用的这个方法""" if self.position < len(self.myiterable.box): item = self.myiterable.box[self.position] self.position += 1 return item # 保证循环结束后可以停止,要不会一直返回None raise StopIteration def __iter__(self): pass t = Test() t.add(1) t.add(2) t.add(3) for i in t: print(i) # 结果 1 2 3
那么for in 的本质是什么呢?
其实for的本质是 先通过iter()获取迭代器,然后通过 调用调用next方法从迭代器中取返回值,item
上面的循环都是从迭代器从可迭代对象里面通过index取对应的元素,那么如果我们不是从可迭代对象里面取值,而是直接在迭代器里面的运算值,那么会是怎样呢?
下面的例子是迭代器版的费布拉切数列数列的n项
class FibIterator(): def __init__(self,count): self.n1 = 0 self.n2 = 1 self.p = 0 self.count = count def __iter__(self): pass def __next__(self): if self.p < self.count: item = self.n1 self.n1,self.n2 = self.n2,self.n1 + self.n2 self.p += 1 return item raise StopIteration f = FibIterator(10) for i in range(10): print(next(f)) 0 1 1 2 3 5 8 13 21 34
改进迭代器
class Test(): def __init__(self): self.box = list() self.n = 0 def __iter__(self): # 这里必须返回self,循环的时候先从iter中取self,也就是迭代器,不传self,会报错,iterator:None-Type return self def __next__(self): if self.n < len(self.box): item = self.box[self.n] self.n += 1 return item raise StopIteration def add(self,value): self.box.append(value) t = Test() t.add(1) t.add(2) t.add(3) # print(next(t)) # print(next(t)) # print(next(t)) # print(next(t)) for i in t: # i 其实就是每次next(t)的返回值,也就是item print(i) # 结果 1 2 3
总结:迭代器一定是可迭代对象,因为具有iter()和next()方法,可迭代对象不一定是迭代器,因为只具有iter()方法。
生成器:迭代器可以通过next()方法取到返回值,但是这不能满足现实需求,因为每一次迭代的状态需要我们自己记录,也就是 +=1 操作,或者斐波那契中的 item=self.n1 这都要我们自己记录,
很不方便,尤其是在菲波那切数列例子中:
item = self.n1 # 记录当前的状态 self.n1,self.n2 = self.n2,self.n1 + self.n2 self.p += 1 # 下一次迭代的条件
这里我们就引入一个特殊的迭代器,就是生成器,来看看生成器是怎么简化迭代器的代码的
def fib(count): n1 = 0 n2 = 1 p = 0 while p < count: item = n1 n1,n2 = n2,n1+n2 p += 1 yield item raise StopIteration f = fib(5) # f 生成器对象 for i in f: print(i) # 结果 0 1 1 2 3 RuntimeError: generator raised StopIteration
一个函数:只要有了yield就变成了生成器,可以循环 for i in f,可以next(f),不用再创建 __iter__()和__next__()函数了。
对上面的生成器进行分析
def fib(count): n1 = 0 n2 = 1 p = 0 while p < count: item = n1 n1,n2 = n2,n1+n2 p += 1 print("函数暂停了,yield给外界的值是:%d" % item) yield item
raise StopIteration f = fib(5) print(next(f)) print(next(f)) # 结果 函数暂停了,yield给外界的值是:0 0 函数暂停了,yield给外界的值是:1 1
总结:生成器执行的起点是yield处,yield会让生成器暂停,当调用next(生成器对象),生成器继续启动,遇到yield继续暂停。
yield---暂停功能。
next()---激活生成器,让生成器继续运行。
下面有一个重要的激活方式 send,send和next不同,send可以传入一个值,这个值可以通过seng激活生成器获得。
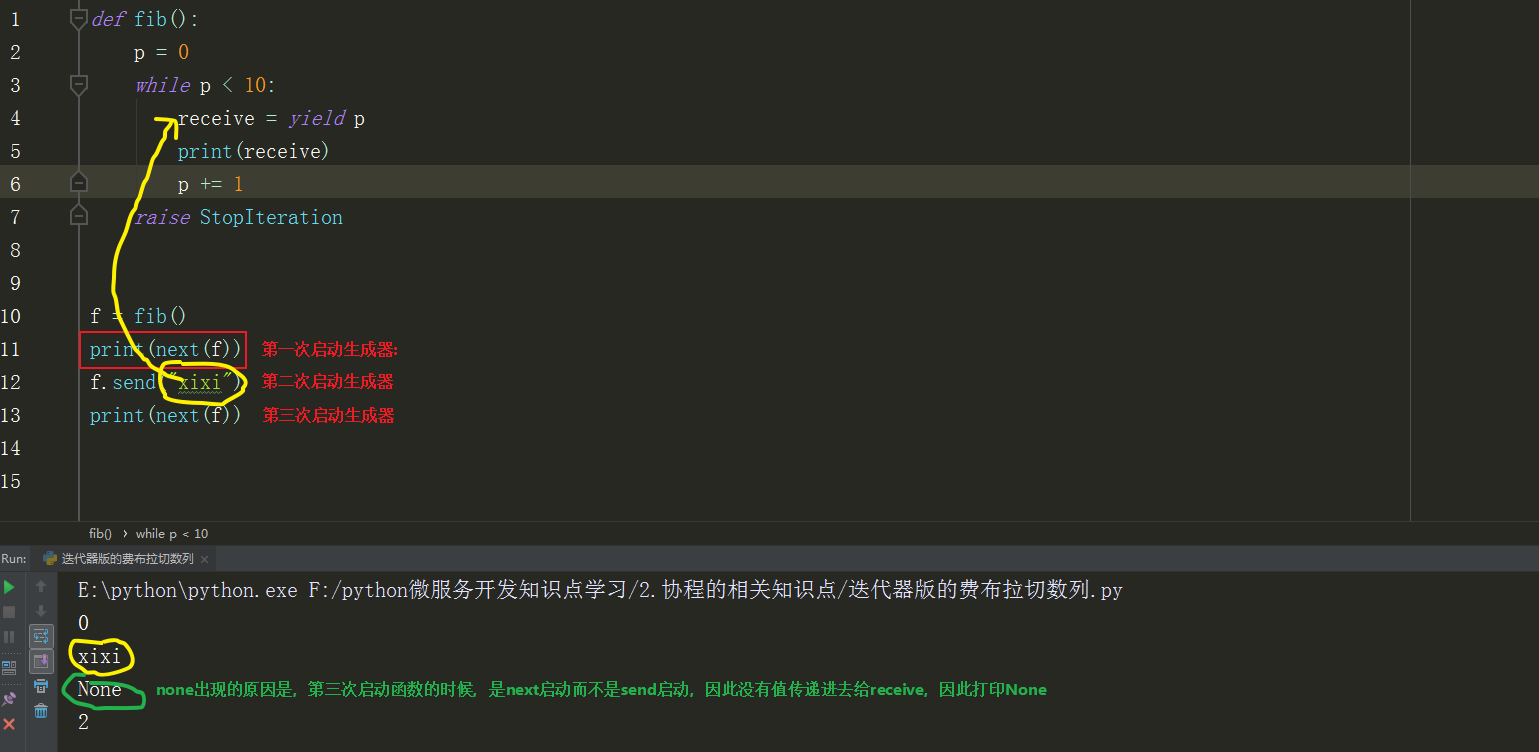
感觉send启动生成器很鸡肋,那么我们到底要这么send有什么具体的用处呢?
有一个例子,是动态求平均值
探讨迭代器里面yield的作用
import time def func1(): for i in range(11): # yield 作用是为了进行任务切换,切换的出发点是阻塞 # 5. 进入迭代器,遇到yield,迭代器暂停 10 继续遇到yield,迭代器暂停 yield # 9. 继续启动了迭代器,执行yield后面的内容,打印 print('这是我第%s次打印啦' % i) time.sleep(1) def func2(): # 3.进入函数内部 g = func1() # 4. 启动了 func1迭代器 next(g) # 6. 因为迭代器暂停,进入循环 for k in range(10): # 7. 打印 11 因为迭代器暂停,继续执行打印 print('哈哈,我第%s次打印了' % k) time.sleep(1) # 8. 继续启动迭代器 next(g) #不写yield,下面两个任务是执行完func1里面所有的程序才会执行func2里面的程序,有了yield,我们实现了两个任务的切换+保存状态 # 1. 遇到func1(),但是因为里面有yield,func1就不是一个函数了,而是一个迭代器,需要用next(func1)来启动,所以这一步就不执行 func1() # 2. func2()是一个正常的函数,调用函数 func2() 哈哈,我第0次打印了 这是我第0次打印啦 哈哈,我第1次打印了 这是我第1次打印啦 哈哈,我第2次打印了 这是我第2次打印啦 哈哈,我第3次打印了 这是我第3次打印啦 哈哈,我第4次打印了 这是我第4次打印啦 哈哈,我第5次打印了 这是我第5次打印啦 哈哈,我第6次打印了 这是我第6次打印啦 哈哈,我第7次打印了 这是我第7次打印啦 哈哈,我第8次打印了 这是我第8次打印啦 哈哈,我第9次打印了 这是我第9次打印啦
知识点一:函数里面有yield就不是一个函数了,而是一个迭代器,启动方式可以用next(函数名) 进行启动,启动后,进入迭代器内部,当执行遇到yield的地方,停止了,此时yield会保留执行的上下文,保存状态,然后重要的是,切换功能,切换到调用next(函数名)的地方,继续执行后面的代码。此时迭代器,处于暂停状态,一直到遇到next(函数名),才会继续启动迭代器,然后执行迭代器,yield后面的代码
# TODO

 浙公网安备 33010602011771号
浙公网安备 33010602011771号