
软工作业2:个人项目-论文查重
软工作业2:个人项目-论文查重
GitHub 链接:MyGitHub
| 这个作业属于哪个课程 | 22级计科2班 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业目标 | 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率 |
课程信息
- 课程: 计科22级2班 - 广东工业大学
- 作业要求: 作业要求
- 目标: 完成个人项目-论文查重;学会写单元测试
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 250 | 300 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 30 |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 | 15 | 10 |
| Coding Standard | 代码规范 | 15 | 10 |
| Design | 具体设计 | 30 | 60 |
| Coding | 具体编码 | 30 | 60 |
| Code Review | 代码复审 | 15 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 15 | 60 |
| Reporting | 报告 | 60 | 60 |
| Test Report | 测试报告 | 30 | 60 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 660 | 740 |
二、基本思路

海明距离(Hamming distance)
定义:在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。
在信息编码中,两个合法代码对应位上编码不同的位数称为码距,又称海明距离。在一个有效编码集中,任意两个码字的海明距离的最小值称为该编码集的海明距离。举例如下:10101和00110从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。
几何意义:
n位的码字可以用n维空间的超立方体的一个顶点来表示。两个码字之间的海明距离就是超立方体两个顶点之间的一条边,而且是这两个顶点之间的最短距离。
作用:用于编码的检错和纠错
本次作业选用文章间的差距转化为海明距离的计算,以计算出文章间的相似度。
具体实现:
public static String getHash(String str) {
try {
MessageDigest messageDigest = MessageDigest.getInstance("MD5");
return new BigInteger(1, messageDigest.digest(str.getBytes(StandardCharsets.UTF_8))).toString(2);
} catch (Exception ignore) {
return str;
}
}
public static String getSimHash(String str) {
if (str.length() < 66) {
System.out.println("输入文本过短");
}
int[] weight = new int[128];
List<String> keywordList = HanLP.extractKeyword(str, str.length());
int size = keywordList.size();
int i = 0;
for (String keyword : keywordList) {
StringBuilder hash = new StringBuilder(getHash(keyword));
if (hash.length() < 128) {
int distance = 128 - hash.length();
hash.append("0".repeat(Math.max(0, distance)));
}
for (int j = 0; j < weight.length; j++) {
if (hash.charAt(j) == '1') {
weight[j] += (10 - (i / (size / 10)));
} else {
weight[j] -= (10 - (i / (size / 10)));
}
}
i++;
}
StringBuilder simHash = new StringBuilder();
for (int k : weight) {
if (k > 0) {
simHash.append("1");
} else simHash.append("0");
}
return simHash.toString();
}
public static String readTxt(String txtPath) {
StringBuilder str = new StringBuilder();
String strLine;
// 将 txt文件按行读入 str中
File file = new File(txtPath);
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream(file);
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, StandardCharsets.UTF_8);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
// 字符串拼接
while ((strLine = bufferedReader.readLine()) != null) {
str.append(strLine);
}
// 关闭资源
inputStreamReader.close();
bufferedReader.close();
fileInputStream.close();
} catch (IOException ignore) {
}
return str.toString();
}
public static void writeTxt(String str,String txtPath){
File file = new File(txtPath);
FileWriter fileWriter;
try {
fileWriter = new FileWriter(file, true);
fileWriter.write(str, 0, str.length());
fileWriter.write("\r\n");
// 关闭资源
fileWriter.close();
} catch (IOException ignore) {
}
}
public static int getHammingDistance(String simHash1, String simHash2){
if(simHash1.length()!=simHash2.length())
return -1;
int distance=0;
System.out.println("str1的simHash值:"+simHash1);
System.out.println("str2的simHash值:"+simHash2);
for (int i=0;i<simHash1.length();i++){
if(simHash1.charAt(i)!=simHash2.charAt(i))
distance++;
}
System.out.println("海明距离为:"+distance);
return distance;
}
private static double getSimilarity(int distance){
return 1-distance/128.0;
}
public static double getSimilarity(String str1,String str2){
String simHash = getSimHash(str1);
String simHash1 = getSimHash(str2);
int hammingDistance = getHammingDistance(simHash, simHash1);
return getSimilarity(hammingDistance);
}
结果实现:


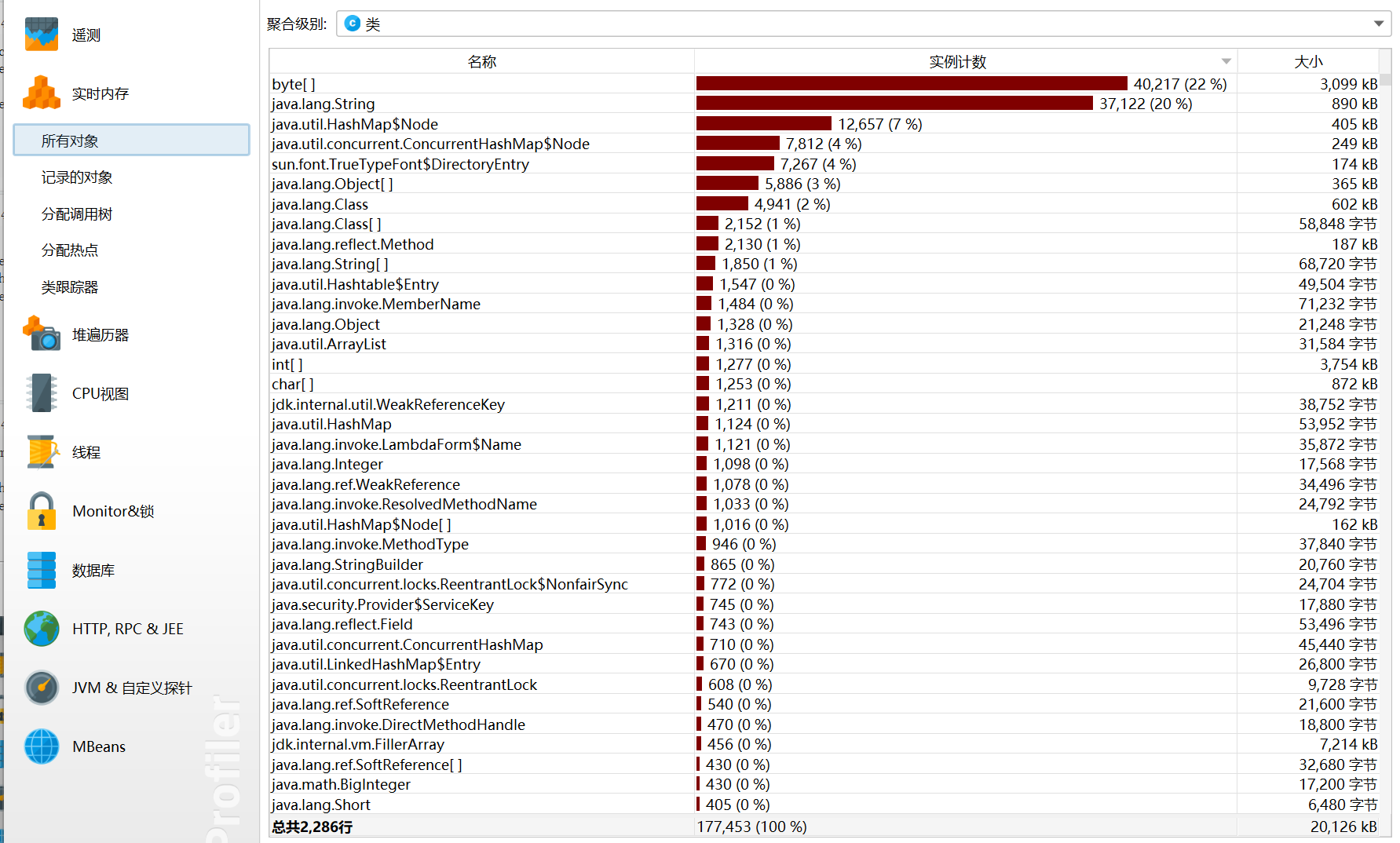
性能分析:
![]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号