
第一次个人编程作业
作业描述
| 课程 | https://edu.cnblogs.com/campus/gdgy/cse2021 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/cse2021/homework/12254 |
| 作业目标 | 设计并实现一个论文查重算法,学会使用PSP表格规划任务事件,学会测试代码,学会反思总结,基本掌握一个软件的开发流程 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 10 | 30 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 120 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 10 |
| · Design | · 具体设计 | 20 | 60 |
| · Coding | · 具体编码 | 720 | 1280 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 60 | 120 |
| · Test Repor | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · 合计 | 1135 | 1860 |
二、配置环境
- 使用工具:vscode
- 代码运行环境:node.js(由于学习前端)
三、项目结构

主要执行文件为PaperPass.js,接口函数文件为func.js,单元测试文件为argTest.js和contentTest.js,性能测试文件为programTest.js
四、计算模块接口的设计与实现过程
- 接口有以下三个:
- 把文件内容经过屏蔽干扰等操作转换为字符串:通过
replace方法对逗号、换行等干扰符号进行替换 - 通过莱文斯坦距离算法
levenshteinDistance计算两个字符串的相似度(核心算法) - 计算重复率:通过对每个词的重复率求平均值得到重复率和
toFixed(2)方法保留两位小数
- 借助工具:
nodejieba分词包fs读取文件包
分词包的安装和所需环境配置:https://www.cnblogs.com/melodyecho/p/15311425.html
- 实现过程:
依靠PaperPass.js文件执行,在该文件中调用func.js中的接口
- 第一步:从命令行读取原文文件路径、抄袭文件路径、答案文件路径这三个参数
- 第二步:通过
node.js中fs模块中readFileSync读取文件内容 - 第三步:把原文文件内容与抄袭文件内容通过接口函数转换为字符串
- 第四步:通过
split方法将字符串以句号分句为一个数组 - 第五步:通过
odejieba分词包对数组的每个元素(即每句话)进行分词 - 第六步:通过for循环和接口函数计算两个数组的
levenshteinDistance总和(核心操作) - 第七步:通过接口函数计算重复率
- 第八步:通过
node.js中fs模块中writeFile写入内容到答案文件中
- 核心算法的实现与分析:
- 莱文斯坦距离,又称Levenshtein距离,是编辑距离的一种。指两个字串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括:将一个字符替换成另一个字符,插入一个字符,删除一个字符。

- 实现原理:假设我们可以使用d[i,j]个步骤(可以用一个二维数组保存这个值),表示将串s[1...i]转换为串t[1...j]所需要的最小步骤个数,那么,在最基本的情况下,即在i等于0时,也就是串s为空,那么对应的d[0,j]就是增加j个字符,使得s转化为t,在j 等于0时,也就是说串t为空,那么对应的d[i,0]就是减少i个字符,使得s转为t。
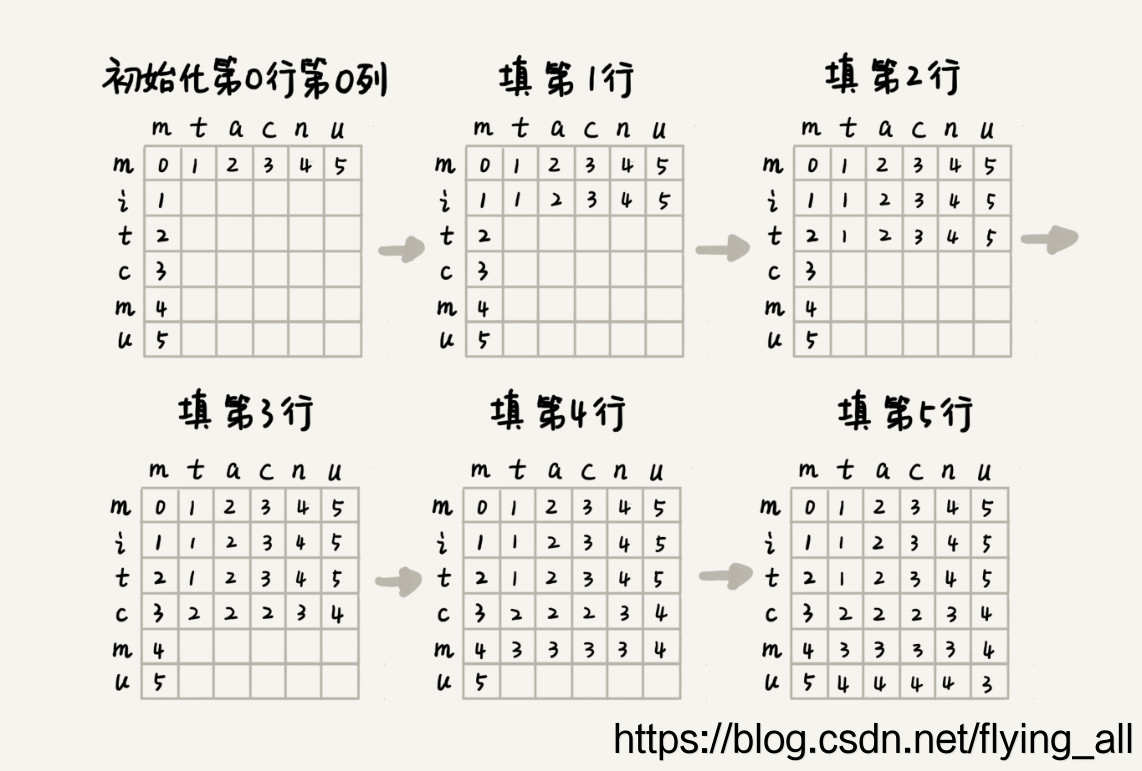
- 总的来说,莱文斯坦距离算法最后得到的是把一个字符串转换到另一个字符串最少操作的步数
- 示例:
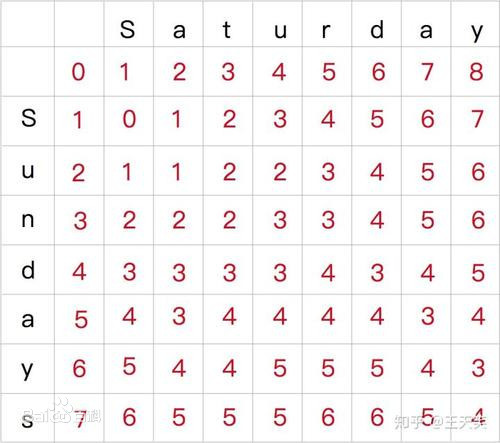
该图中矩阵右下角的值为4,则表示这两个字符串的levenshteinDistance为4
核心算法代码:https://www.cnblogs.com/artwl/archive/2012/04/15/2450624.html
- 核心操作的实现与分析
第一个for循序按照最少的句数来安排对比次数,第二个for循环按照最少的次数来安排对比次数,剩余两个for循环用来加上确定百分比不相似(即levenshteinDistance值就是那些词句的字符串长度)的levenshteinDistance值
五、性能改进
- 运行正常

- 由于
node.js偏前端语言,无法采用VS 2017/JProfiler工具进行性能分析,故采用node.js自身的mocha框架 进行分析,有关mocha的安装与使用:https://blog.csdn.net/fenger_c/article/details/108107492
- 测试原理:使用
node.js中的assert模块,该模块是node.js的内置模块,主要用于断言。如果表达式不符合预期,就会抛出一个错误,mocha框架中包含该模块
测试结果如下:
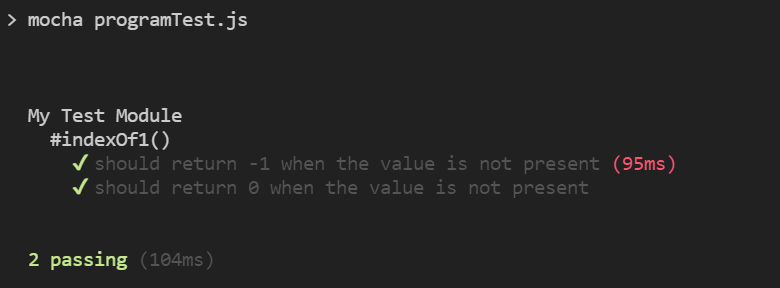
六、单元测试
测试用例包含6个文件,每个文件里包含一个原文文件和3个经过增删改其中一个操作后得到的抄袭文件,以及一个答案文件,总共为24个用例,均会产生相应的结果,如图所示:
单元测试环节中测试了以下两个环节:
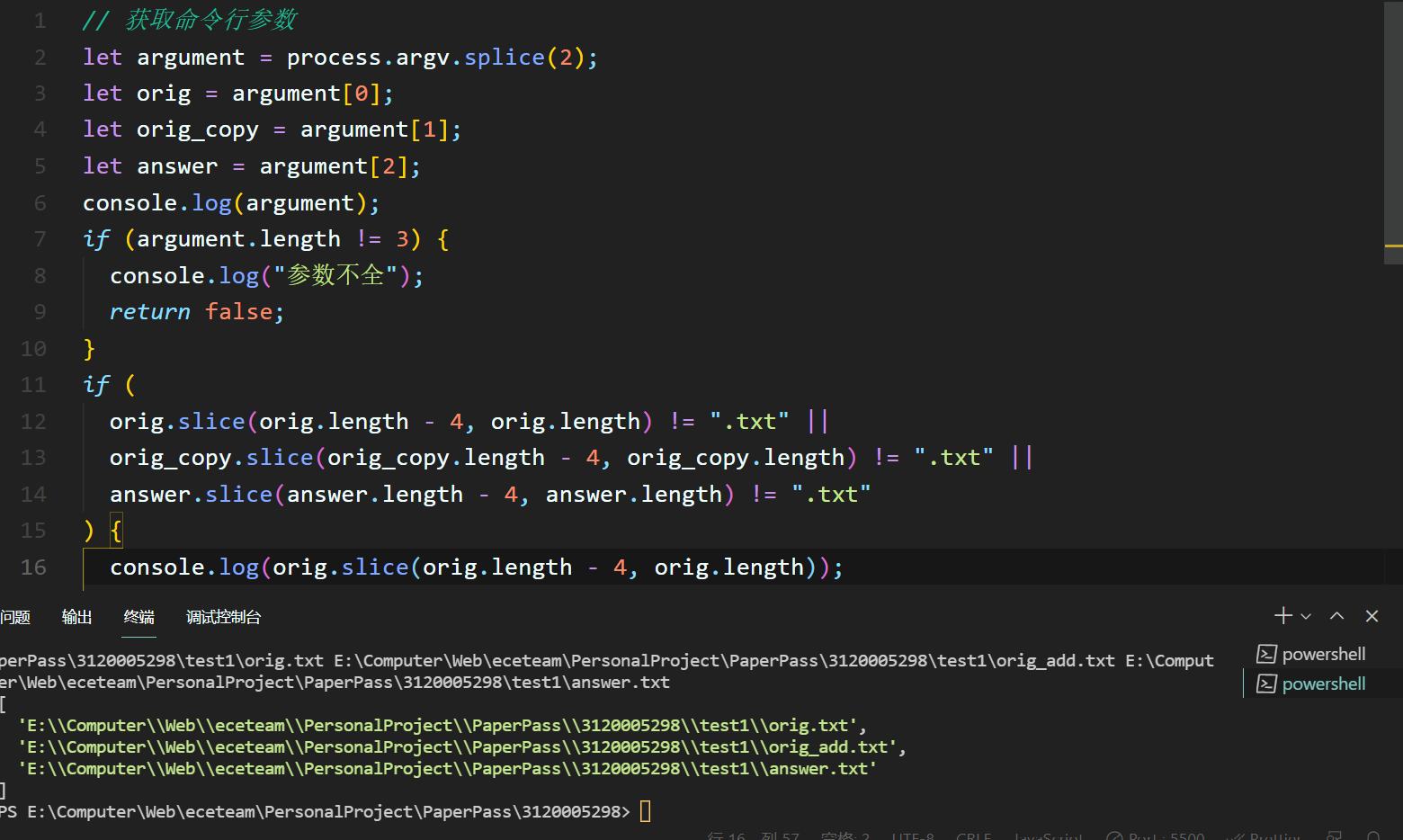
- 读取命令行参数并进行异常情况处理
- 读取文件并将内容换为字符串
第一个环节测试代码和结果:
第二个环节测试代码和结果:
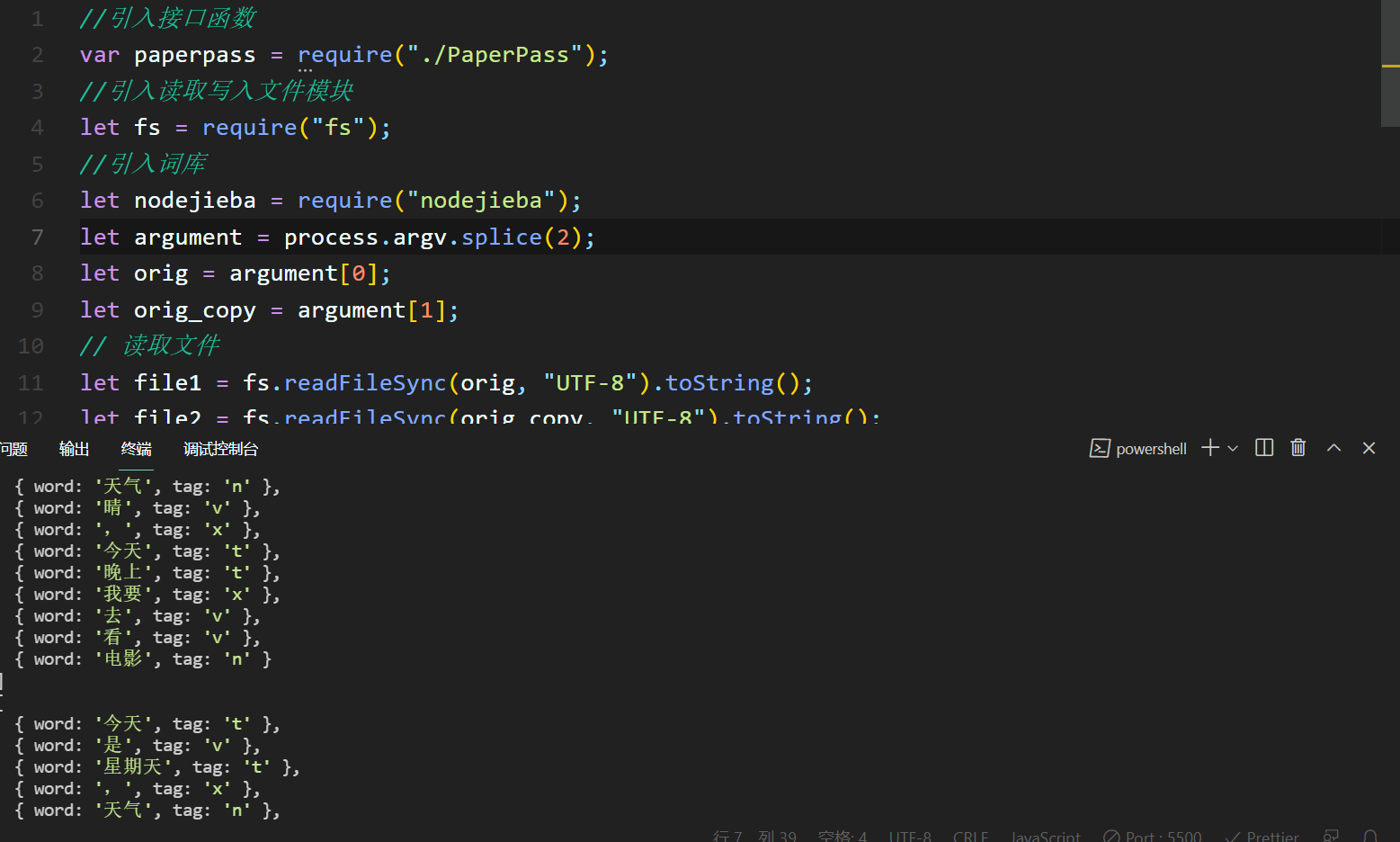
采取的测试用例为test1中的原文和增操作后的抄袭文 - orig.txt: 今天是星期天,天气晴,今天晚上我要去看电影。
- orig_add.txt:今天是星期天,天气晴,今天晚上我要去看电影,我非常的开心与高兴。
七、异常处理说明
- 输入参数个数不正确:需3个参数,原文、抄袭文和答案文的文件绝对路径

- 输入参数格式不正确:文件后缀不能省略

八、结果展示
以test5为例:
orig.txt:

orig_add.txt:

orig_change.txt:

orig_delete.txt:

orig.txt与orig_add.txt:96.47%

orig.txt与orig_change.txt:96.62%

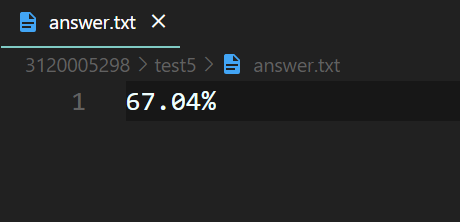
orig.txt与orig_delete.txt:67.04%

answer.txt:
九、总结
经过这次项目的实践,我大概清楚了一个软件开发的基本流程,在此过程中也学习了node.js前端知识,并且将它用在了实践当中,对node.js的认识又加深了一些

 浙公网安备 33010602011771号
浙公网安备 33010602011771号