

MASM常用伪指令
汇编源码总存在着两种指令:
1、Masm在编译阶段在生成Obj文件时控制生成结果的指令(Directives),本身并不会被CPU执行;
2、计算机指令(Instructions),这种会直接生成由CPU执行的代码。
常用的伪指令如下:
1、.8086、.80186、.80286、80286P、.80386、.80386P等CPU伪指令:
指定masm生成的代码的兼容等级,intel cpu基本都是向下兼容的(新CPU可以执行旧CPU的指令代码)。8086指生成的可执行文件,指含有8086、8087和8088代码,不含80186及之后的代码。intel 从80286开始,CPU有2种工作模式:实模式(Real Mode)和保护模式(Protected Mode)。80286P指可以生成保护模式代码,80286则不能生成保护模式的代码。
2、Title伪指令:
指程序的名称,并不需要跟代码或执行文件的名称一致,只是用于调试的时候标记代码的名称,即lst或crf等文件中标志名称,便于区别。
3、.Model memorymodel,内存模型:
内存模型的值可以是:Tiny、Small、Medium、Compact、Large和Huge,内存模型伪指令:
《汇编语言》基本都是完整段声明(full segment definitions)方式,但简单段声明方式是masm5之后支持的主要方式,除了可以声明内存模型外,通过简单段声明方式,可以更好的与高级语言(C、Pascal等)进行相互调用。
Tiny主要是为了支持com文件格式,数据(data)和代码(code)都只能在一个64K的段中。
Small,数据(data)和代码(code)都只能在一个64K的段中。所有数据和代码的引用都只能是near。
Medium,数据只能在一个64K的段中,代码(code)可以超过64K。因此代码引用可以用far,数据只能用near。
Compact,与Medium正好相反。代码(code)只能在一个64K的段中,数据(data)可以超过64K。因此数据引用可以用far,代码只能用near。
但数据段中的数组(Array)不能超过64K。
Large,数据(data)和代码(code)都可以超过64K,即数据和代码都可以用far。
Huge,基本同Large,不同的是Array可以超过64K。
为什么会有内存模型这样的东西呢,一方面,程序的这样组织跟8086系列CPU的寻址方式相匹配;再则,如果程序或数据在同一段中(即数据的引用为near或short),无论是内存占用和执行速度都比far的快,因为段寄存器不用变更。这在当时的硬件条件下是很重要的,随着80286的诞生,分段的内存模型就被抛弃了。
☆如果.386伪指令在.Model之前定义,则masm将生成32bit的段;如果相反,则跟进内存模型生成相应的段。
4、简单段声明伪指令:
简单的段声明有以下伪指令(方括号表示可选项):.Stack[size]、.Code[name]、.Data、.Data?、.Fardata[name]、.Fardata?[name]、.Const,?表示未初始化。
使用简单段声明方式,段的默认名称和所属组与内存模型相关联,具体如下表:
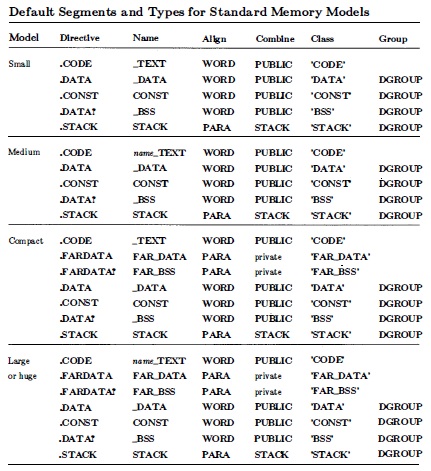
☆对于Small和Comapt内存模型,自动生成的assume为:assume cs:_TEXT,ds:DGROUP,ss:DGROUP
☆对于medium、large和huge内存模型为:assume cs:name_TEXT,ds:DGROUP,ss:DGROUP
☆对于使用了.386,默认的对齐类型(align type)为DWORD。
未完待续



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)