

dataFrames格式的数据是表格形式的,mysql数据库中的数据也是表格形式的,二者可以很方便的读取存储
安装依赖的包
pip install pandas
pip install sqlalchemy
pip install pymysql
使用方法
第一步:建立mysql数据库的连接
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format("username", "password", "host", "port", "db数据库名") engine = create_engine(connect_info)
第二步:读取存储数据库
此步使用的engine为第一步创建的数据库连接
1、读取数据库中的内容【read_sql】
import pandas pandas.read_sql("sql语句", engine)
2、存储dataFrame数据到数据库中【to_sql】
df.to_sql(name='table表名', con=engine, if_exists='append', index=False, dtype={'IterationId': sqlalchemy.types.Integer(), 'title': sqlalchemy.types.NVARCHAR(length=255) } )
方法说明:
df:dataFrame格式的数据,可以通过DataFrame()方法创建一个该对象
pandas.DataFrame({"ID": [], "标题": []})
name:存储到的表名
con:第一步创建的数据库链接
if_exists:
fail:如果表存在,什么也不做
replace:如果表存在,drop掉表,重新创建一个表,插入数据
append:如果表不存在,创建表插入数据;如果表存在,原表追加数据存储
dtype:表字段对应过去的类型,例子举了整形和字符两种;(列不指定类型的话会用默认类型,但是如果类型不匹配会抛错)
注意点:
1、to_sql的源数据,列名必须和数据库里对应;且不能比数据库中列名多
如果缺少列名,会直接填充缺省值
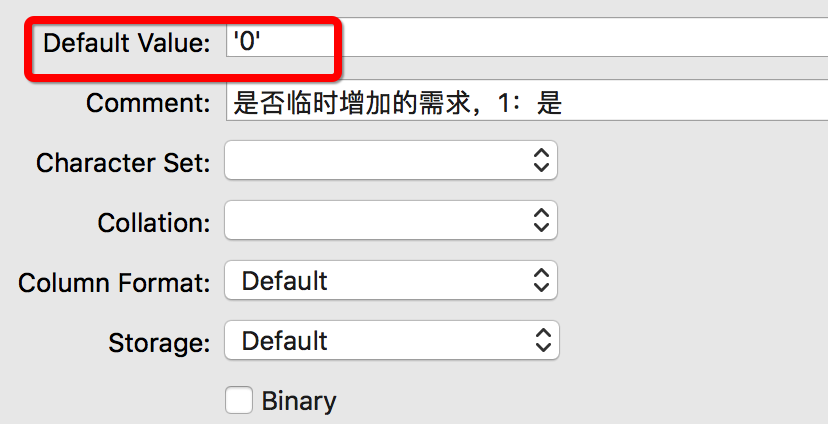
2、缺省的列,要有默认值
存储到sql的列信息可以为空,但前提是数据库表字段写了默认值;或者类似id这种自增主键允许为空


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异