loadrunner - 集合点
近来跟踪一个项目,发现同事们在执行性能测试时,比较热衷于使用集合点,从概念上认为要得到并发用户就必须设置集合点,认为在执行一个压力测试脚本时,设置了集合点才算是有效的并发用户,没有设置结合点,就认为可能这个就不能准确的代表并发用户数。当前我并反对这个观点,不过却让我有一种疑虑,促使我想更深入的理解并发用户和集合点,我相信大多数进入性能测试研究领域的朋友都应该有疑惑,主要原因我觉得还是由于不能深入理解LoadRunner的实现原理,而且缺乏对系统整个过程的分析,其中这里面涉及到的知识包括网络、协议、中间件、数据库、应用层以及缓冲区和缓存等等,当然还与硬件资源CPU队列和内存等有着千丝万缕的联系。所以说要成为一个优秀的性能测试人员,真还不一个容易的过程,是需要长时间积累和学习的,只有通过大量的项目实践和分析,最后再总结于思想,才有可能成为这个领域的专家,当然也希望真正想把性能测试做好的朋友都能为此将不懈努力,乐于分享和讨论。
先来看一个应用系统的结构图,如下所示:
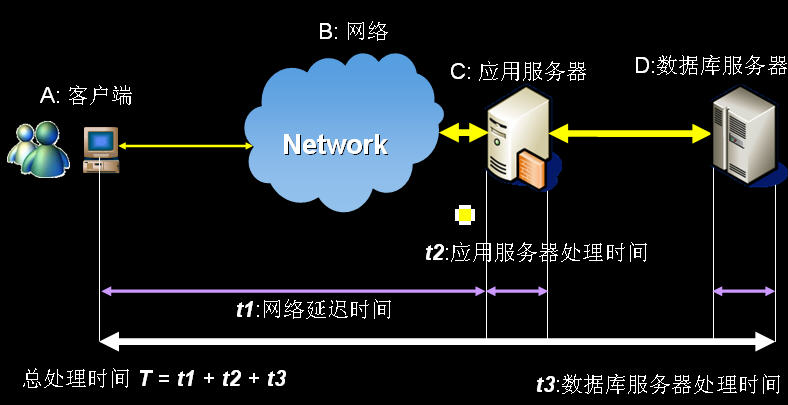
这个图源于小布老师的视频中,比较直观、简洁地反映了一个应用系统的运行过程,其中包括客户端、网络、应用服务器和数据库服务器,其中每一个环节都是在执行性能测试分析中必不可少的元素,结构图中也合理得分析出了响应时间的处理过程,当请求从客户端发出之后到最后返回到客户端,这个过程中每一个环节的处理都有可能最后成为系统运行中的性能瓶颈,所以可见对系统整体结构的理解是何等重要。
接下来我们来看看关于并发用户和集合点的定义:
并发用户:通俗意义上讲就是同时操作的用户,当然这个“同时”可以理解为同一时间段,还可以理解为同一时间点,当然如果说并发就是同一时间点上同时操作的用户,这样理解没有错误,但对于实际情况来讲,是没有严格意义上的并发执行的,就如同进程和线程关系一样,在某一个点严格上讲就只有一个人得到执行的权利。
集合点:用以同步虚拟用户,以便恰好在同一时刻执行任务。这个从概念上来讲,其实也是比较模糊,正因为模糊,使用才值得去深入探讨。对于LoadRunner来说,集合点只是一种策略,而这个策略也会有很多规则,因为实际情况中并非所有用户都会同时到达集合点,上面的那个结构图就能解释这个误解,因为从客户端发出到网络、中间件、应用层再到数据库,这其中的每一个环节都有延时,也就是说不可能所有的用户都能到达所谓的集合点,才开始同时执行操作。
从上面的两个概念的理解来讲,有人就会思考,并发用户和集合点到底有没有关系,这才是关键。当然这个就要看需求是什么了,所以说很多时候我们误用集合点和并发用户,其实根本原因在于对需求的理解,需求本身都没有搞清楚他想实现的场景,得到什么样的结果。当然,我们只能感慨需求并是专业的技术人员,至少我们大多数人碰到的需求都不一定是技术出身,所以他们不明白,我们就不能装忽悠,不然结果就肯定不符合实际了。
通常情况下,我们会得到用户这样的需求“本系统要达到并发用户200”,这种需求从严格意义上来讲是不合格的,因为对于一个系统来说有很多个功能,比如系统登录、注册、查询、删除等等,是要求登录达到200,还是所有功能总共达到200,因为当用户进入系统之后,有些用户在执行注册,有些用户在执行查询,是否可以并行操作,也是所谓的并发,所以说要理解集合点和并发数,从根本上就应该更清晰的理解业务流程,只有把业务分析清楚了,方才可以合理的使用集合点,正确的理解并发用户数。
当然,就我个人来讲,我是很少使用集合点的,因为通过LoadRunner的理解,我认为LoadRunner本身就已经在模拟实现一个并发的过程,而增加集合点设置只是为了并实现严格意义上的所谓的并发,而实际是这个集合点的设置也并非绝对达到了这个目的,结构中的过程就可以证明。
在loadrunner的虚拟用户中,术语concurrent(并发)和simultaneous(同时)存在一些区别,concurrent 是指虚拟场景中参于运行的虚拟用户。而simultaneous与集合点(rendzvous point)关系更密切,是指在同一时刻一起执行某个任务的虚拟用户。
我们来想象一个场景,10名运动员参加长跑比赛,出发点同时起跑,他们是并排奔跑的;跑了N圈之后,因为有体能更强的,有体能稍弱的,他们的队形并排变成了前后。几乎一个跑道就可以供应他们的奔跑(运行),那么其余的9条跑道就是空闲的。
为了充分的利用跑道,可以将跑道的起点设置一个集合点,当所有运动员跑完一圈后在起跑点集合,然后再同时起跑。
运动员可以看作是虚拟用户,跑道可以看作是系统资源。设置集合点可以模式更加真实的并发请求,从而增加对系统的负载。
下面是设置集合点的步骤:
1.在Virtual User Generator 中给测试脚本添加集合点函数
注:本例所用脚本是loadrunner软件自带的basic脚本
确定脚本中加入集合点的位置(在事务开始之前)=》右击insert =》选择集合点Rendezvous


2.保存修改后的脚本,跳转到controller界面中
tools =》 create controller scenario

3.在controller中设置集合点策略
Scenario ==》 Rendezvous


下面来看看这三种策略的含义:
Release when :当所有虚拟用户中的x % 到达集合点进释放,即仅当指定百分比的虚拟用户到达集合点时,才释放虚拟用户。注意:此选项将会干扰场景的计划。如果选择此选项,场景将不按计划运行。
Release when :当所有正在运行的虚拟用户中的x %到达集合点时释放,即仅当场景中指定百分比的、正在运行的虚拟用户到达集合点时,才释放虚拟用户。还有不在运行的虚拟用户? 假如,设置为1分钟启动一个用户,当然会存在因为用户还没启动,所以无法参与集合点。
Release when : 当x 个虚拟用户到达集合点时释放,即仅当指定数量的虚拟用户到达集合点时,才释放虚拟用户。这个很好理解,当我用百分比不太好衡量集合点的虚拟用户数,当然可以设置具体的用户数。
Timeout between Vusers (虚拟用户之间的超时)框中输入一个超时值:假如设置了集合10用户并发,结果9个用户已经集合到位,还剩1个虚拟用户,左等右等就是等不来。那总不能一直等下去吧。设定了个时间,假如30秒还不来,那就不管它了。超时的时长默认是30秒,我们可以根据具体的被测应用进行调整。
4.设置运行场景
run_time setting、Scenario Schedule、Global Schedule。。。
5.开始运行
6.结果分析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号