
Elastic-Job-Lite 源码分析 —— 作业分片策略
摘要: 原创出处 http://www.iocoder.cn/Elastic-Job/job-sharding-strategy/ 「芋道源码」欢迎转载,保留摘要,谢谢!
本文基于 Elastic-Job V2.1.5 版本分享
🙂🙂🙂关注微信公众号:【芋道源码】有福利:
- RocketMQ / MyCAT / Sharding-JDBC 所有源码分析文章列表
- RocketMQ / MyCAT / Sharding-JDBC 中文注释源码 GitHub 地址
- 您对于源码的疑问每条留言都将得到认真回复。甚至不知道如何读源码也可以请教噢。
- 新的源码解析文章实时收到通知。每周更新一篇左右。
- 认真的源码交流微信群。
1. 概述
本文主要分享 Elastic-Job-Lite 作业分片策略。
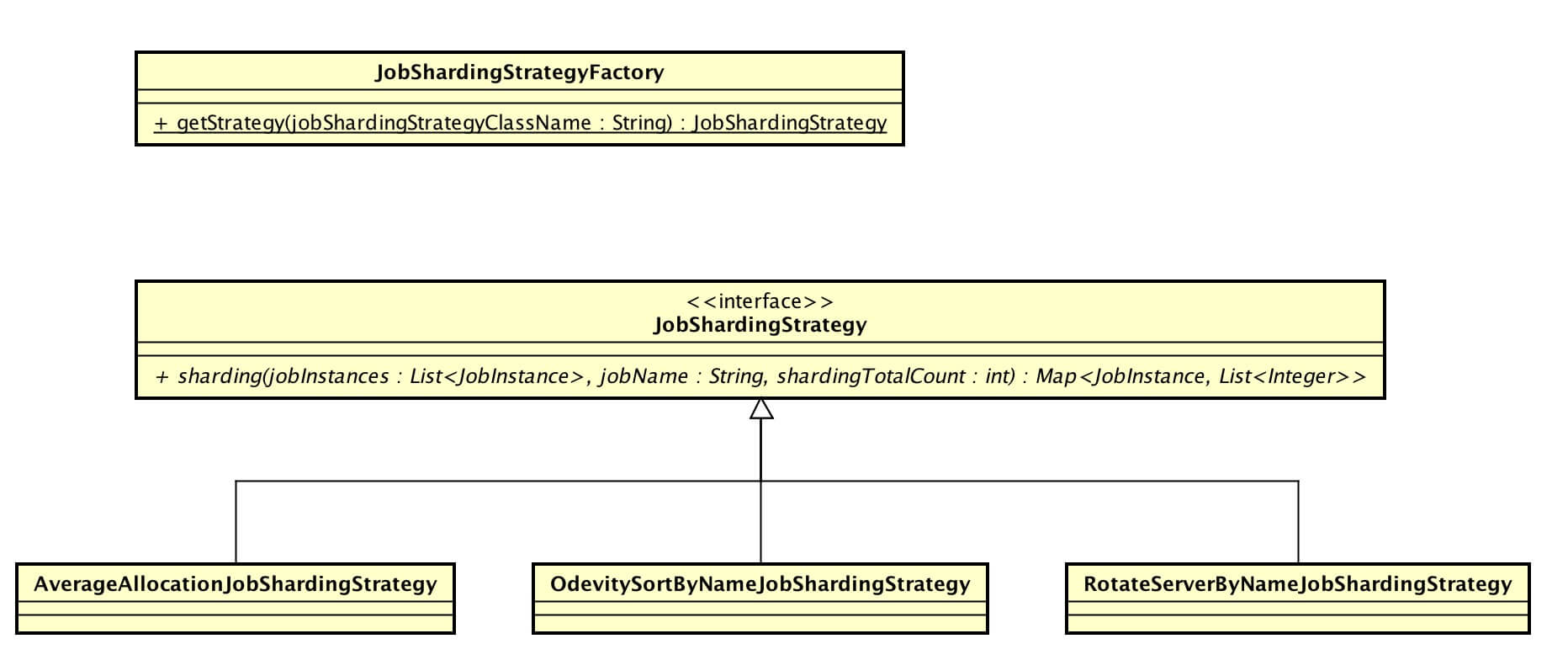
涉及到主要类的类图如下( 打开大图 ):
你行好事会因为得到赞赏而愉悦
同理,开源项目贡献者会因为 Star 而更加有动力
为 Elastic-Job 点赞!传送门
2. 自带作业分片策略
JobShardingStrategy,作业分片策略接口。分片策略通过实现接口的 #sharding(...) 方法提供作业分片的计算。
|
public interface JobShardingStrategy {
Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount);
}
|
Elastic-Job-Lite 提供三种自带的作业分片策略:
- AverageAllocationJobShardingStrategy:基于平均分配算法的分片策略。
- OdevitySortByNameJobShardingStrategy:根据作业名的哈希值奇偶数决定IP升降序算法的分片策略。
- RotateServerByNameJobShardingStrategy:根据作业名的哈希值对作业节点列表进行轮转的分片策略。
2.1 AverageAllocationJobShardingStrategy
AverageAllocationJobShardingStrategy,基于平均分配算法的分片策略。Elastic-Job-Lite 默认的作业分片策略。
如果分片不能整除,则不能整除的多余分片将依次追加到序号小的作业节点。如:
如果有3台作业节点,分成9片,则每台作业节点分到的分片是:1=[0,1,2], 2=[3,4,5], 3=[6,7,8]
如果有3台作业节点,分成8片,则每台作业节点分到的分片是:1=[0,1,6], 2=[2,3,7], 3=[4,5]
如果有3台作业节点,分成10片,则每台作业节点分到的分片是:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]
代码实现如下:
|
public final class AverageAllocationJobShardingStrategy implements JobShardingStrategy {
public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) {
// 不存在 作业运行实例
if (jobInstances.isEmpty()) {
return Collections.emptyMap();
}
// 分配能被整除的部分
Map<JobInstance, List<Integer>> result = shardingAliquot(jobInstances, shardingTotalCount);
// 分配不能被整除的部分
addAliquant(jobInstances, shardingTotalCount, result);
return result;
}
}
|
-
调用
#shardingAliquot(...)方法分配能被整除的部分。能整除的咱就不举例子。如果有 3 台作业节点,分成 8 片,被整除的部分是前 6 片 [0, 1, 2, 3, 4, 5],调用该方法结果:1=[0,1], 2=[2,3], 3=[4,5]。private Map<JobInstance, List<Integer>> shardingAliquot(final List<JobInstance> shardingUnits, final int shardingTotalCount) {Map<JobInstance, List<Integer>> result = new LinkedHashMap<>(shardingTotalCount, 1);int itemCountPerSharding = shardingTotalCount / shardingUnits.size(); // 每个作业运行实例分配的平均分片数int count = 0;for (JobInstance each : shardingUnits) {List<Integer> shardingItems = new ArrayList<>(itemCountPerSharding + 1);// 顺序向下分配for (int i = count * itemCountPerSharding; i < (count + 1) * itemCountPerSharding; i++) {shardingItems.add(i);}result.put(each, shardingItems);count++;}return result;} -
调用
#addAliquant(...)方法分配能不被整除的部分。继续上面的例子。不能被整除的部分是后 2 片 [6, 7],调用该方法结果:1=[0,1] + [6], 2=[2,3] + [7], 3=[4,5]。private void addAliquant(final List<JobInstance> shardingUnits, final int shardingTotalCount, final Map<JobInstance, List<Integer>> shardingResults) {int aliquant = shardingTotalCount % shardingUnits.size(); // 余数int count = 0;for (Map.Entry<JobInstance, List<Integer>> entry : shardingResults.entrySet()) {if (count < aliquant) {entry.getValue().add(shardingTotalCount / shardingUnits.size() * shardingUnits.size() + count);}count++;}}
如何实现主备
通过作业配置设置总分片数为 1 ( JobCoreConfiguration.shardingTotalCount = 1 ),只有一个作业分片能够分配到作业分片项,从而达到一主N备。
2.2 OdevitySortByNameJobShardingStrategy
OdevitySortByNameJobShardingStrategy,根据作业名的哈希值奇偶数决定IP升降序算法的分片策略。
作业名的哈希值为奇数则IP 降序.
作业名的哈希值为偶数则IP 升序.
用于不同的作业平均分配负载至不同的作业节点.
如:
- 如果有3台作业节点, 分成2片, 作业名称的哈希值为奇数, 则每台作业节点分到的分片是: 1=[ ], 2=[1], 3=[0].
- 如果有3台作业节点, 分成2片, 作业名称的哈希值为偶数, 则每台作业节点分到的分片是: 1=[0], 2=[1], 3=[ ].
实现代码如下:
|
public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) {
long jobNameHash = jobName.hashCode();
if (0 == jobNameHash % 2) {
Collections.reverse(jobInstances);
}
return averageAllocationJobShardingStrategy.sharding(jobInstances, jobName, shardingTotalCount);
}
|
-
从实现代码上,仿佛和 IP 升降序没什么关系?答案在传递进来的参数
jobInstances。jobInstances已经是按照 IP 进行降序的数组。所以当判断到作业名的哈希值为偶数时,进行数组反转(Collections#reverse(...))实现按照 IP 升序。下面看下为什么说jobInstances已经按照 IP 进行降序:// ZookeeperRegistryCenter.javapublic List<String> getChildrenKeys(final String key) {try {List<String> result = client.getChildren().forPath(key);Collections.sort(result, new Comparator<String>() {public int compare(final String o1, final String o2) {return o2.compareTo(o1);}});return result;} catch (final Exception ex) {RegExceptionHandler.handleException(ex);return Collections.emptyList();}} -
调用
AverageAllocationJobShardingStrategy#sharding(...)方法完成最终作业分片计算。
2.3 RotateServerByNameJobShardingStrategy
RotateServerByNameJobShardingStrategy,根据作业名的哈希值对作业节点列表进行轮转的分片策略。这里的轮转怎么定义呢?如果有 3 台作业节点,顺序为 [0, 1, 2],如果作业名的哈希值根据作业分片总数取模为 1, 作业节点顺序变为 [1, 2, 0]。
分片的目的,是将作业的负载合理的分配到不同的作业节点上,要避免分片策略总是让固定的作业节点负载特别大,其它工作节点负载特别小。这个也是为什么官方对比 RotateServerByNameJobShardingStrategy、AverageAllocationJobShardingStrategy 如下:
AverageAllocationJobShardingStrategy的缺点是,一旦分片数小于作业作业节点数,作业将永远分配至IP地址靠前的作业节点,导致IP地址靠后的作业节点空闲。如:
OdevitySortByNameJobShardingStrategy则可以根据作业名称重新分配作业节点负载。
如果有3台作业节点,分成2片,作业名称的哈希值为奇数,则每台作业节点分到的分片是:1=[0], 2=[1], 3=[]
如果有3台作业节点,分成2片,作业名称的哈希值为偶数,则每台作业节点分到的分片是:3=[0], 2=[1], 1=[]
实现代码如下:
|
public final class RotateServerByNameJobShardingStrategy implements JobShardingStrategy {
private AverageAllocationJobShardingStrategy averageAllocationJobShardingStrategy = new AverageAllocationJobShardingStrategy();
public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) {
return averageAllocationJobShardingStrategy.sharding(rotateServerList(jobInstances, jobName), jobName, shardingTotalCount);
}
private List<JobInstance> rotateServerList(final List<JobInstance> shardingUnits, final String jobName) {
int shardingUnitsSize = shardingUnits.size();
int offset = Math.abs(jobName.hashCode()) % shardingUnitsSize; // 轮转开始位置
if (0 == offset) {
return shardingUnits;
}
List<JobInstance> result = new ArrayList<>(shardingUnitsSize);
for (int i = 0; i < shardingUnitsSize; i++) {
int index = (i + offset) % shardingUnitsSize;
result.add(shardingUnits.get(index));
}
return result;
}
}
|
- 调用
#rotateServerList(...)实现作业节点数组轮转。 - 调用
AverageAllocationJobShardingStrategy#sharding(...)方法完成最终作业分片计算。
3. 自定义作业分片策略
可能在你的业务场景下,需要实现自定义的作业分片策略。通过定义类实现 JobShardingStrategy 接口即可:
|
public final class OOXXShardingStrategy implements JobShardingStrategy {
public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) {
// 实现逻辑
}
}
|
实现后,配置实现类的全路径到 Lite作业配置( LiteJobConfiguration )的 jobShardingStrategyClass 属性。
作业进行分片计算时,作业分片策略工厂( JobShardingStrategyFactory ) 会创建作业分片策略实例:
|
public final class JobShardingStrategyFactory {
public static JobShardingStrategy getStrategy(final String jobShardingStrategyClassName) {
if (Strings.isNullOrEmpty(jobShardingStrategyClassName)) {
return new AverageAllocationJobShardingStrategy();
}
try {
Class<?> jobShardingStrategyClass = Class.forName(jobShardingStrategyClassName);
if (!JobShardingStrategy.class.isAssignableFrom(jobShardingStrategyClass)) {
throw new JobConfigurationException("Class '%s' is not job strategy class", jobShardingStrategyClassName);
}
return (JobShardingStrategy) jobShardingStrategyClass.newInstance();
} catch (final ClassNotFoundException | InstantiationException | IllegalAccessException ex) {
throw new JobConfigurationException("Sharding strategy class '%s' config error, message details are '%s'", jobShardingStrategyClassName, ex.getMessage());
}
}
}
|

