
Python爬虫-Ajax网页爬取过程
1、Ajax介绍
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
所以你会发现网站在翻页时url不变的
2、普通网页
我们以起点小说中文网为例,找到推荐排行榜
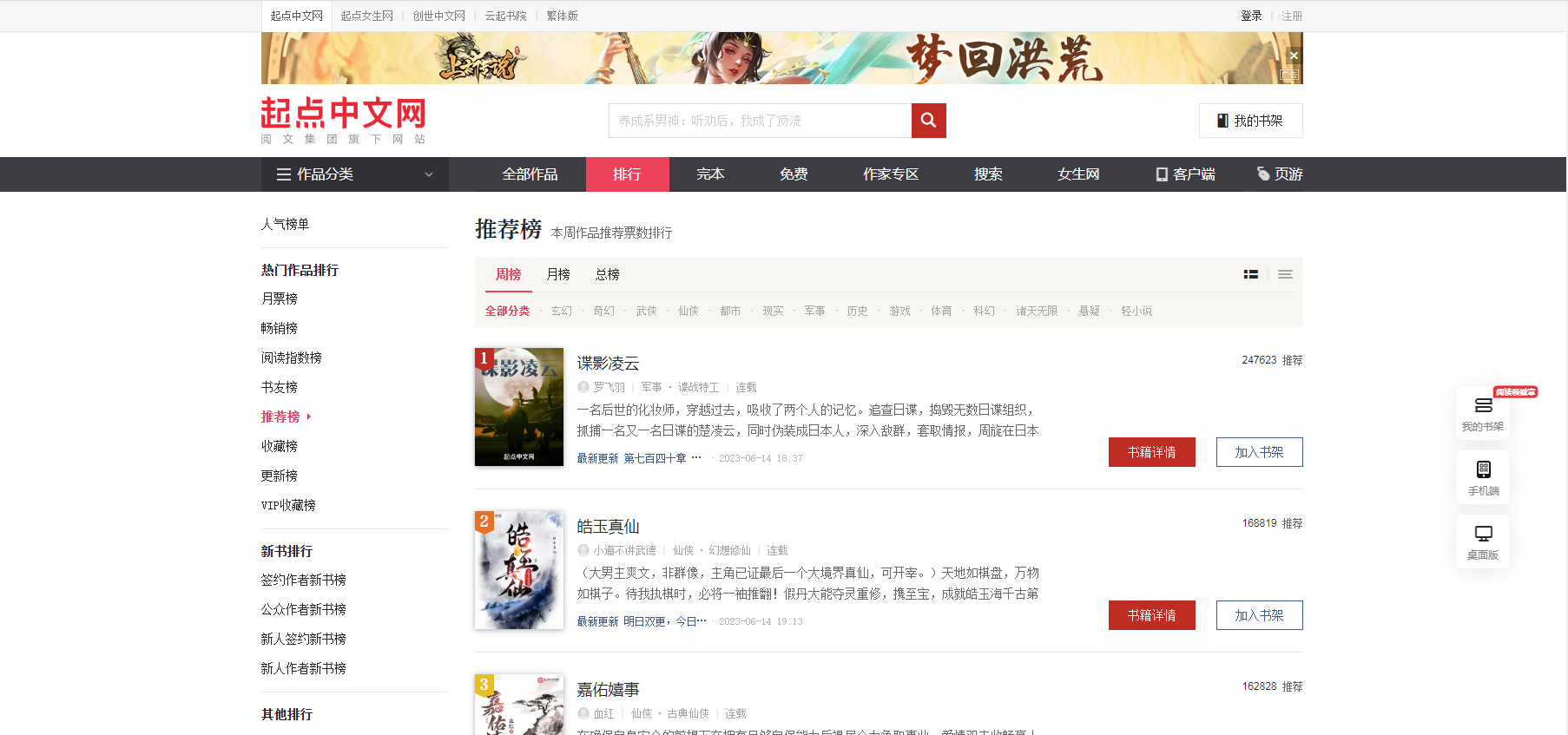
首先我们要爬取该网站内容时需要知道url,此时地址为:https://www.qidian.com/rank/recom/
当我们切换到第二页时,url变成:https://www.qidian.com/rank/recom/page2/
很明显页码是通过page参数进行控制的,通过遍历便能够获得每一页的url。
for i in range(1, 10): # 页数自己随便改
print("正在爬取第"+str(i)+"页数据...")
url = 'https://www.qidian.com/rank/recom/page' + str(i) + '/'
print(url)
2.1、模拟浏览器登录
网页中 右键 -> 检查
找到以下内容,然后在代码中用字典储存,参数都可以写,不局限于这几个
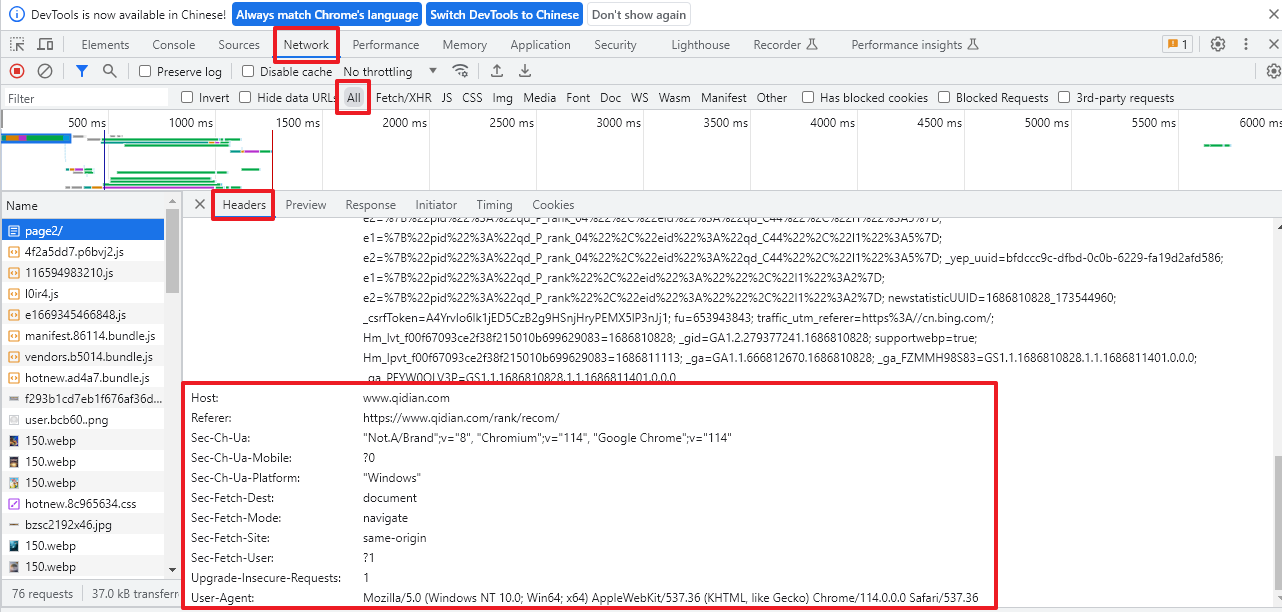
# 模拟浏览器访问
headers={
'Host':'www.qidian.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
2.2、爬取数据
可以通过下面代码爬取排行榜的内容:
import requests
from bs4 import BeautifulSoup
# 模拟浏览器访问
headers={
'Host':'www.qidian.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
def main():
for i in range(1, 10): # 页数自己随便改
try:
print("正在爬取第"+str(i)+"页数据...")
url = 'https://www.qidian.com/rank/recom/page' + str(i) + '/'
print(url)
response = requests.get(url,headers=headers)
response.encoding = "utf-8"
html = response.text
soup = BeautifulSoup(html, 'html.parser')
print(soup.prettify())
except:
pass
if __name__ == '__main__':
main()
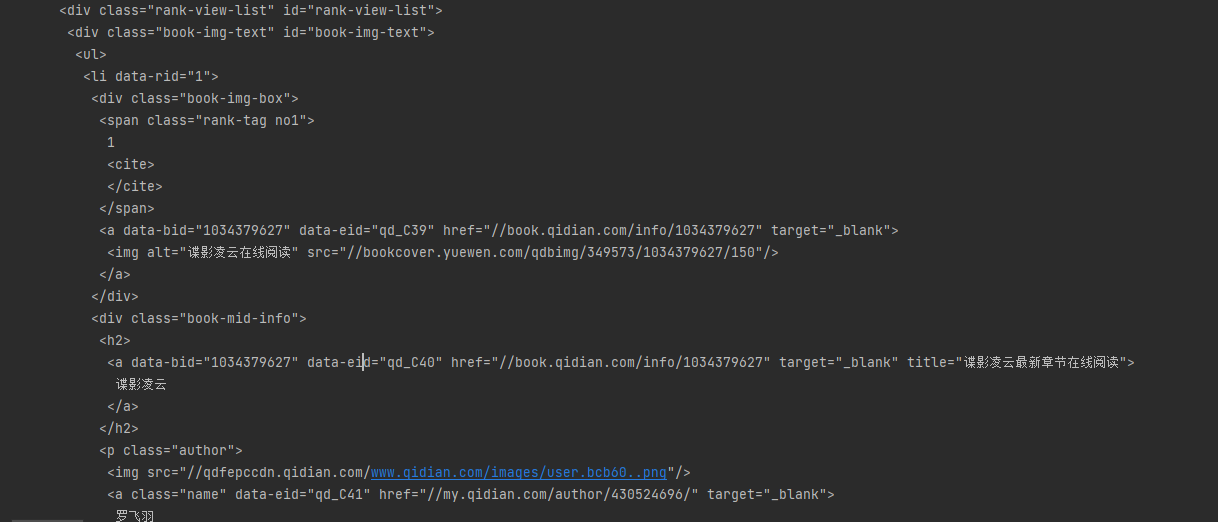
当然,该程序只是将每一页的html打印出来,只能说满足了爬虫的基本条件,后续可以根据自己的需要从中提取出某些字段,比如将所有小说的信息提取出来储存到本地文件中。
3、动态网页
我们以前程无忧网为例,职位搜索选择大数据
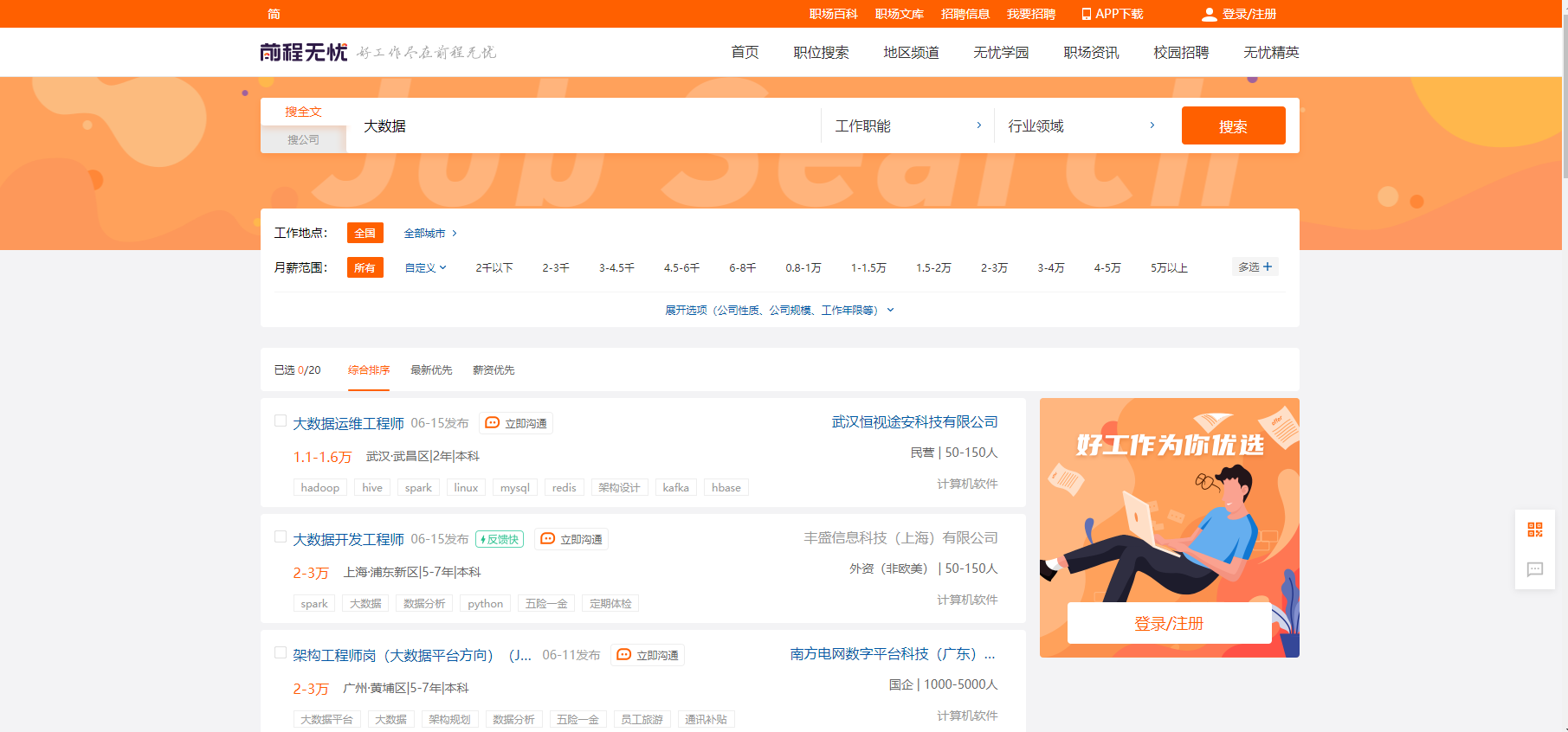
此时地址为:https://we.51job.com/pc/search?keyword=%E5%A4%A7%E6%95%B0%E6%8D%AE&searchType=2&sortType=0&metro=
简化后地址:https://we.51job.com/pc/search?keyword=%E5%A4%A7%E6%95%B0%E6%8D%AE 同样生效
keyword=%E5%A4%A7%E6%95%B0%E6%8D%AE,表示大数据,这个是中文在网页上的编码显示,可以通过修改这个值来改变搜索的职位信息
此时我们手动进行翻页后会发现url完全不变
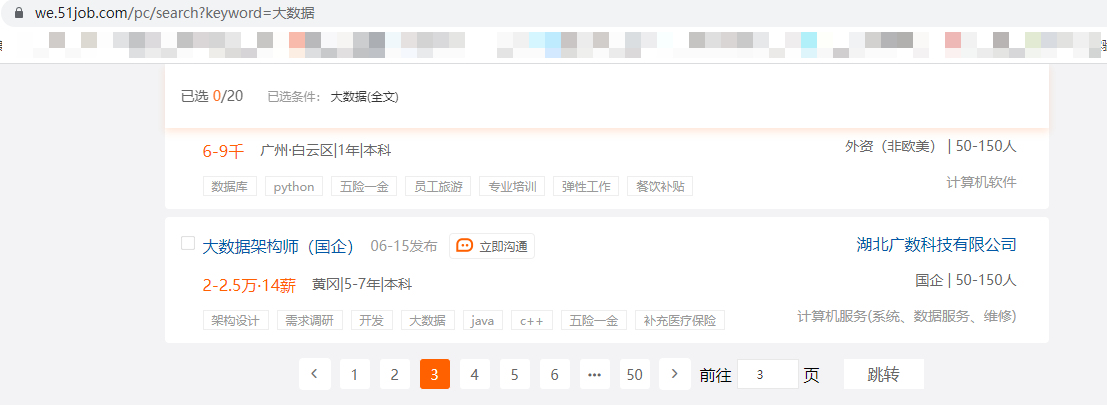
所以就需要用特殊的方法进行分析
3.1、通过浏览器审查元素解析地址
键盘敲 F12 找到以下内容

此时,内容为空白,按F5刷新后,便可看到具体的东西,经过仔细检查,发现下面这个文件里面就隐藏着有用信息
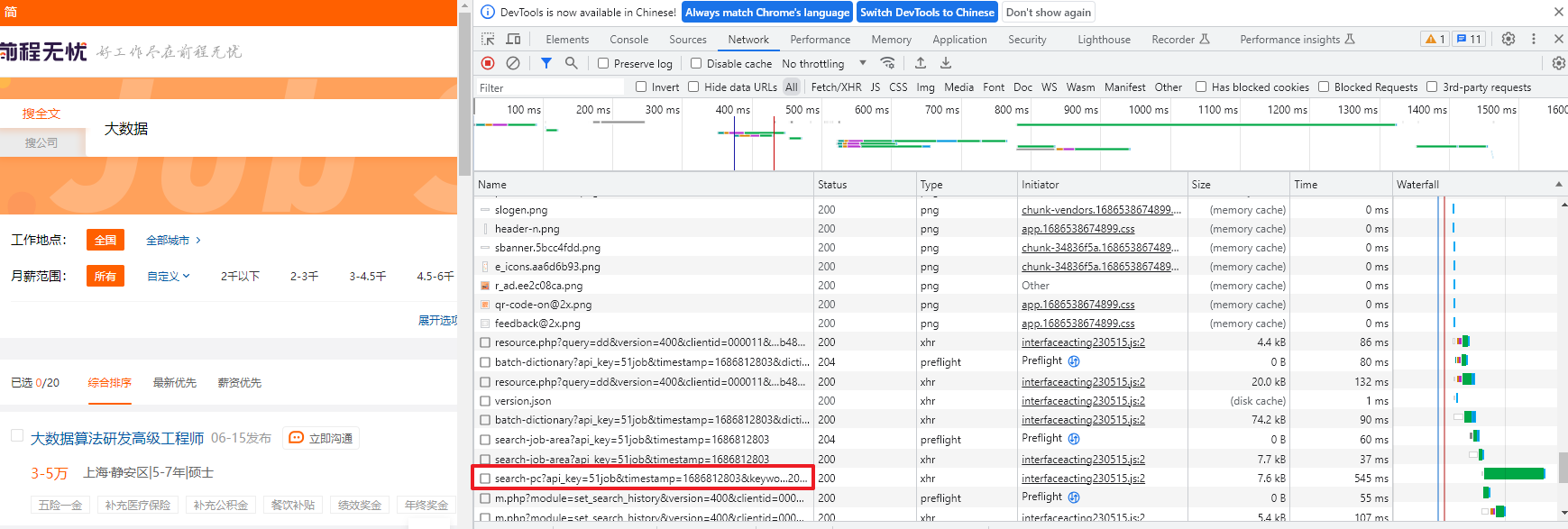
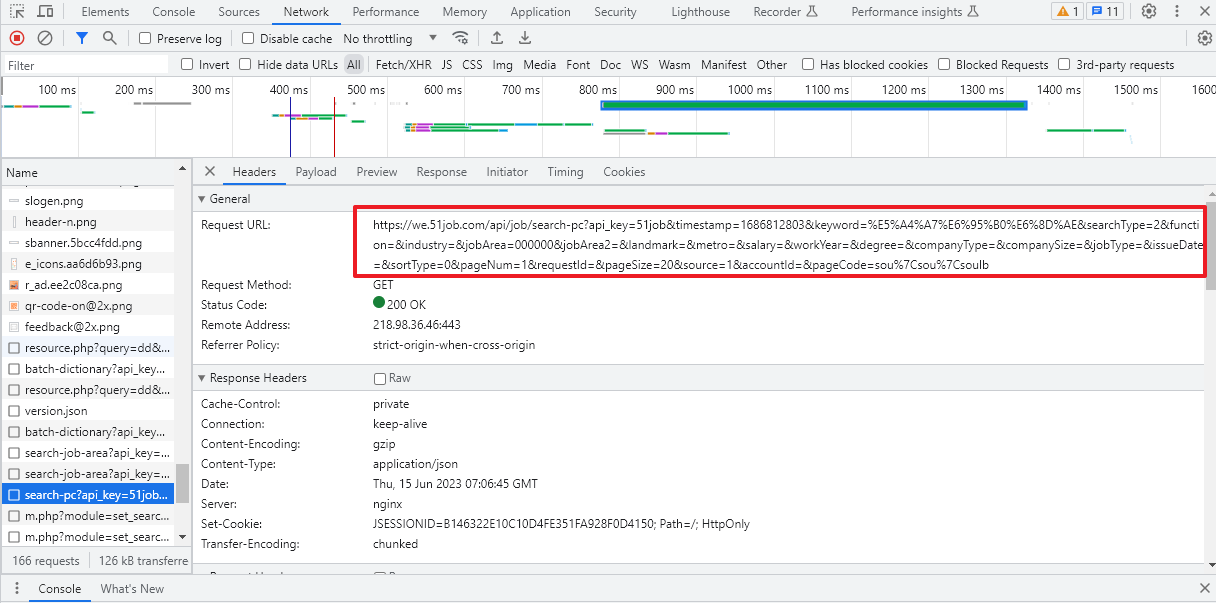
url为:https://we.51job.com/api/job/search-pc?api_key=51job×tamp=1686812803&keyword=%E5%A4%A7%E6%95%B0%E6%8D%AE&searchType=2&function=&industry=&jobArea=000000&jobArea2=&landmark=&metro=&salary=&workYear=°ree=&companyType=&companySize=&jobType=&issueDate=&sortType=0&pageNum=1&requestId=&pageSize=20&source=1&accountId=&pageCode=sou%7Csou%7Csoulb
其中发现职位信息:&keyword=%E5%A4%A7%E6%95%B0%E6%8D%AE,修改这个参数可以爬取不同的职位
页码信息:&pageNum=1,修改此参数可以实现翻页
职位显示数量信息:&pageSize=20,修改此参数可以使得每一页内容更多
通过上述信息,便可以使用代码遍历多个页面的url
for i in range(1, 10): # 页数自己随便改
print("正在爬取第"+str(i)+"页数据...")
url_start = 'https://we.51job.com/api/job/search-pc?api_key=51job'
# 删除×tamp参数,修改&pageSize=500
url_end = '&keyword=%E5%A4%A7%E6%95%B0%E6%8D%AE&searchType=2&function=&industry=&jobArea=000000&jobArea2=&landmark=&metro=&salary=&workYear=°ree=&companyType=&companySize=&jobType=&issueDate=&sortType=0&pageNum=' \
+ str(i) + '&requestId=&pageSize=500&source=1&accountId=&pageCode=sou%7Csou%7Csoulb'
url = url_start + url_end
print(url)
手动点击该url,页面弹窗验证完后显示如下:

3.2、爬取数据
利用之前的方法进行爬取:
import requests
from bs4 import BeautifulSoup
headers={
'Host':'we.51job.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
def main():
for i in range(1, 3): # 页数自己随便改
try:
print("正在爬取第"+str(i)+"页数据...")
url_start = 'https://we.51job.com/api/job/search-pc?api_key=51job'
# 删除×tamp参数,修改&pageSize=500
url_end = '&keyword=%E5%A4%A7%E6%95%B0%E6%8D%AE&searchType=2&function=&industry=&jobArea=000000&jobArea2=&landmark=&metro=&salary=&workYear=°ree=&companyType=&companySize=&jobType=&issueDate=&sortType=0&pageNum=' \
+ str(i) + '&requestId=&pageSize=500&source=1&accountId=&pageCode=sou%7Csou%7Csoulb'
url = url_start + url_end
print(url)
response = requests.get(url, headers=headers)
response.encoding = "utf-8"
html = response.text
soup = BeautifulSoup(html, 'html.parser')
print(soup.prettify())
except:
pass
if __name__ == '__main__':
main()
但是此时爬取内容出现如下情况
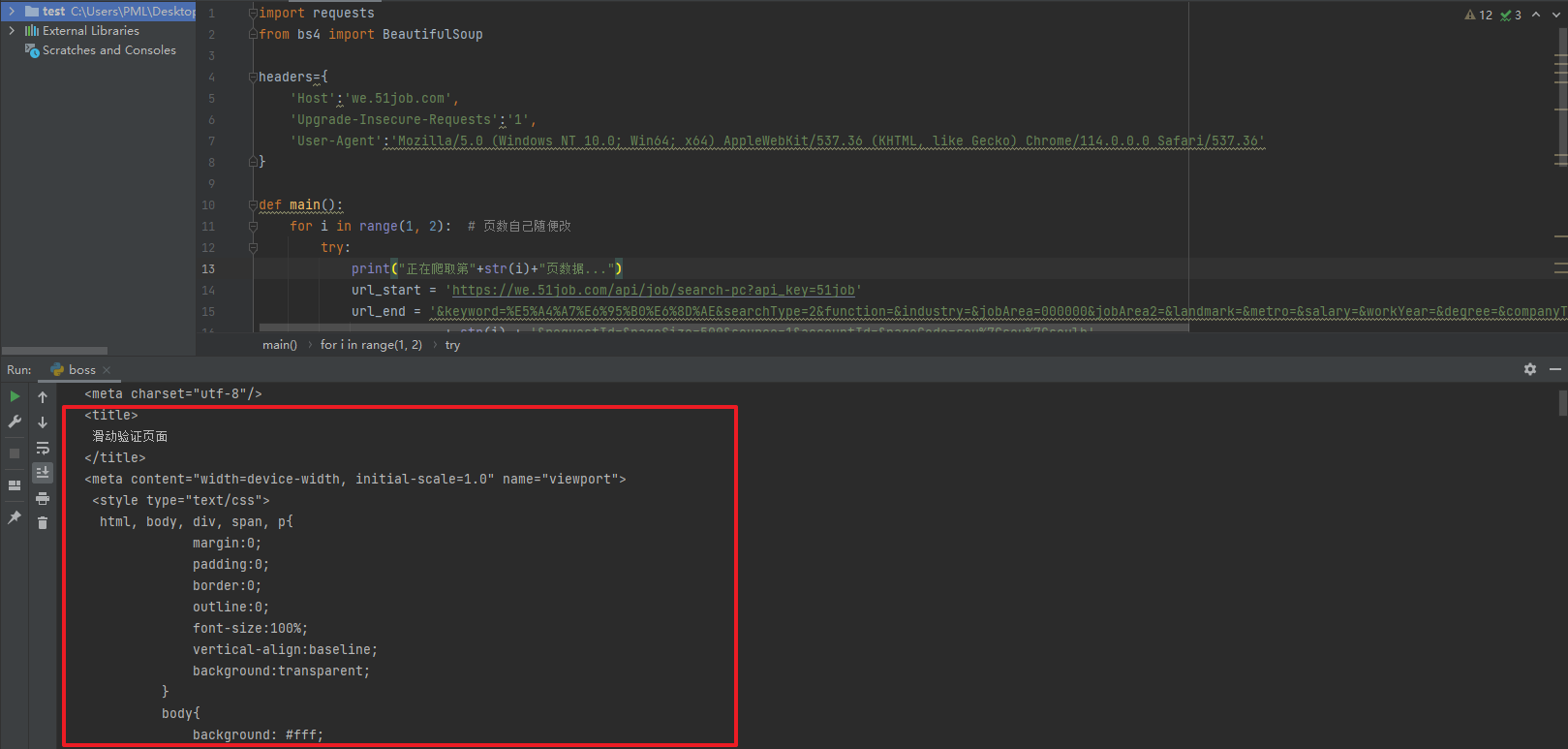
这是因为该页面需要进行访问验证:
解决该问题需要用到Selenium库,Selenium是一个自动化测试工具,也可以用于Web爬取。它可以控制浏览器并模拟人类操作,从而避免被反爬虫检测。

