
python + 高德地图API实现地图找房
python + 高德地图API实现地图找房
项目简介:根据工作地点信息和58同城爬取的租房信息,通过高德地图进行显示,同时利用高德API自动规划房源到工作地点的通勤路线(公交+地铁)
项目仓库:https://github.com/haohaizhi/58house_spiders
一、数据爬取
# 拉取代码
git clone https://github.com/haohaizhi/58house_spiders.git
完整代码如下:
from bs4 import BeautifulSoup
import requests
import csv
import time
import lxml
def main():
# 1、筛选条件为租金的范围,可自定义修改
# 2、地点不同则网址二级域名不同,如此时南京:nj.58.com 北京:bj.58.com
# 3、因为没有做一些动态切换处理,多次运行可能会触发网址防爬机制,此时需要手动访问该网站进行验证
# 4、使用此程序需要了解一些爬虫基本原理
url = "https://nj.58.com/pinpaigongyu/pn/{page}/?minprice=2000_4000"
# 已完成的页数序号,初时为0
csv_file = open("house.csv", "w", encoding="utf-8")
csv_writer = csv.writer(csv_file, delimiter=',')
for page in range(0,20):
page += 1
print("正在爬取第" + str(page) + "页信息........")
print("URL: ", url.format(page=page))
time.sleep(3)
response = requests.get(url.format(page=page))
response.encoding = 'utf-8'
html = BeautifulSoup(response.text,features="lxml")
# lxml 4.0版本
# html = BeautifulSoup(response.text,features="html.parser")
house_list = html.select(".list > li")
for house in house_list:
house_title = house.select("img")[0]["alt"]
house_url = house.select("a")[0]["href"]
house_info_list1 = house_title.split('-')
# 如果第二列是公寓名或者社区则取第一列作为地址
if "公寓" in house_info_list1[0] or "社区" in house_info_list1[0]:
house_info_list2 = house_info_list1[0].split(' ')
house_info_list2 = house_info_list2[0].replace('【','')
house_info_list2 = house_info_list2.replace('】', '|')
else:
house_info_list2 = house_info_list1[0]
print(house_info_list2 + " " + house_url)
house_location = house_info_list2.replace('|',' ')
house_info_list = house_location.split(' ')
print(house_info_list)
house_url = "https://nj.58.com" + house_url
csv_writer.writerow([house_info_list[1], house_url])
csv_file.close()
if __name__ == '__main__':
main()
根据自身需要进行修改如下url:
# 修改代码中url网址 (地区 价格范围)
# 如: 北京:bj.58.com
# 南京:nj.58.com
# 若想进行更准确的筛选,则需要添加其他参数,具体需要参考58同城
url = "https://nj.58.com/pinpaigongyu/pn/{page}/?minprice=2000_4000"
查看所需数据的标签
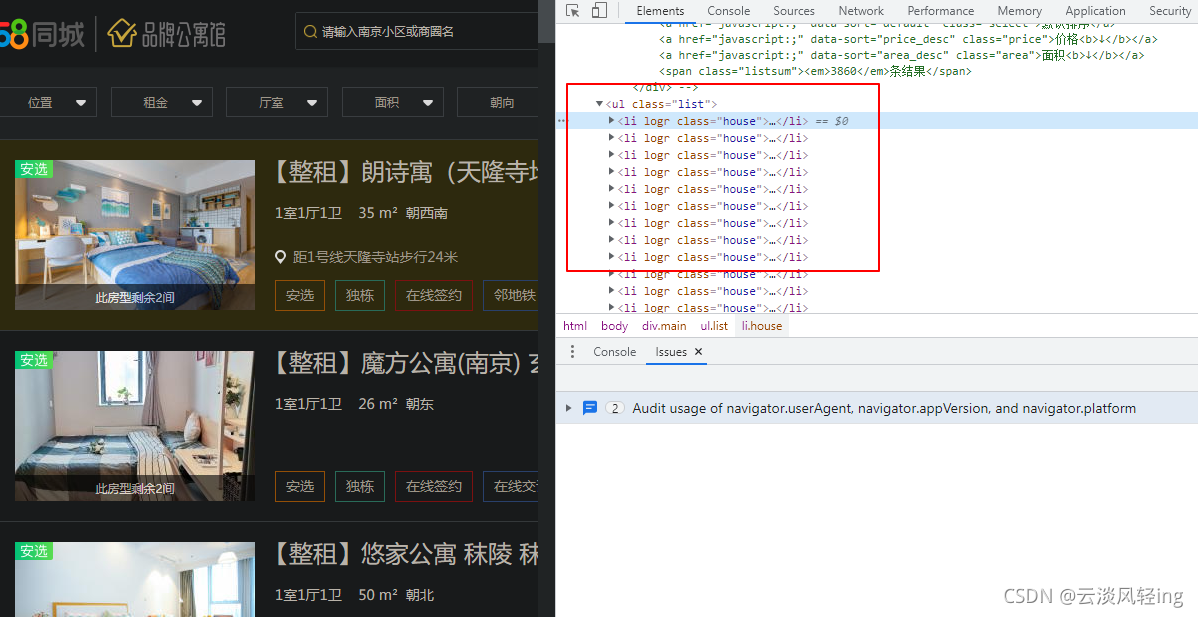
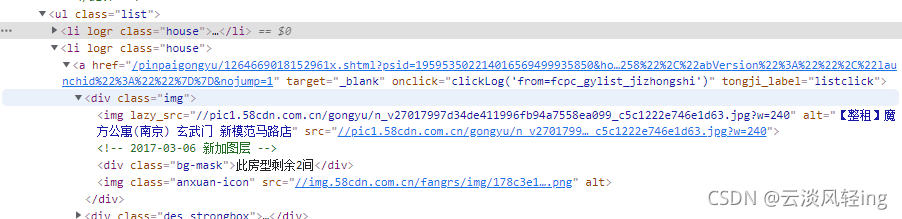
#这几行代码就是从网页源码中获取所需数据,这个用到了BeautifulSoup库的select函数,函数具体用法可上网搜索文档,或者在本项目代码仓库的README中查看
response = requests.get(url.format(page=page))
response.encoding = 'utf-8'
html = BeautifulSoup(response.text,features="lxml")
house_list = html.select(".list > li")
注意:程序运行过程中很大几率会出现中断的情况,基本原因都是爬取网址时出现问题,可能网络波动,可能网站需要人工验证
# 可将部分代码修改成以下方式进行优化
for page in range(0,20):
try:
page += 1
print("正在爬取第" + str(page) + "页信息........")
print("URL: ", url.format(page=page))
time.sleep(3)
response = requests.get(url.format(page=page))
response.encoding = 'utf-8'
html = BeautifulSoup(response.text,features="lxml")
house_list = html.select(".list > li")
for house in house_list:
house_title = house.select("img")[0]["alt"]
house_url = house.select("a")[0]["href"]
house_info_list1 = house_title.split('-')
# 如果第二列是公寓名或者社区则取第一列作为地址
if "公寓" in house_info_list1[0] or "社区" in house_info_list1[0]:
house_info_list2 = house_info_list1[0].split(' ')
house_info_list2 = house_info_list2[0].replace('【','')
house_info_list2 = house_info_list2.replace('】', '|')
else:
house_info_list2 = house_info_list1[0]
print(house_info_list2 + " " + house_url)
house_location = house_info_list2.replace('|',' ')
house_info_list = house_location.split(' ')
print(house_info_list)
house_url = "https://nj.58.com" + house_url
csv_writer.writerow([house_info_list[1], house_url])
except:
pass
csv_file.close()
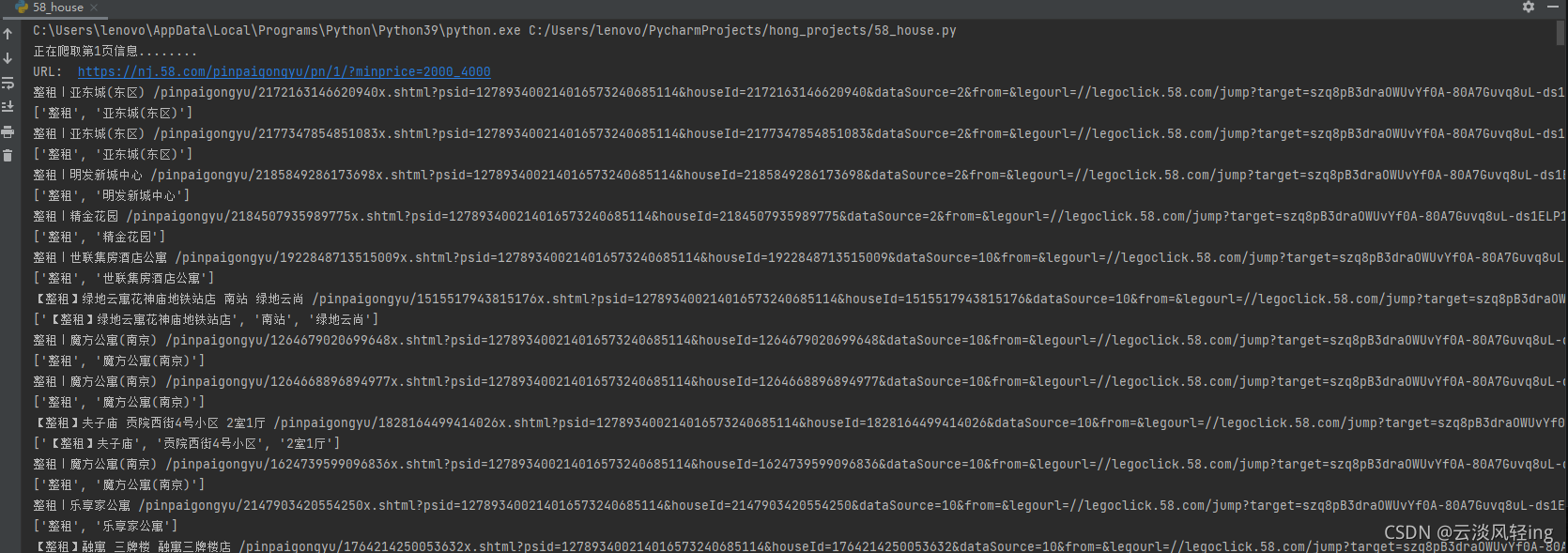

刚开始进行调试时可以先尝试只分析某一页的html源码
# 代码如下
from bs4 import BeautifulSoup
import requests
import csv
import time
import lxml
def main():
url = "https://nj.58.com/pinpaigongyu/pn/1/?minprice=2000_4000"
response = requests.get(url.format(page=page))
response.encoding = 'utf-8'
print(response)
if __name__ == '__main__':
main()
将执行后打印的内容Ctrl + A, Ctrl + C 复制粘贴到临时文件中,如test.txt
然后就可以针对这个临时文件进行后续数据提取的操作,等程序调试的没问题了,在用最最终版的代码
from bs4 import BeautifulSoup
import requests
import csv
import time
import lxml
def main():
csv_file = open("house.csv", "w", encoding="utf-8")
csv_writer = csv.writer(csv_file, delimiter=',')
f = open('./test.txt', 'r')
response = f.read()
f.close()
html = BeautifulSoup(response,features="lxml")
house_list = html.select(".list > li")
for house in house_list:
house_title = house.select("img")[0]["alt"]
house_url = house.select("a")[0]["href"]
house_info_list1 = house_title.split('-')
# 如果第二列是公寓名或者社区则取第一列作为地址
if "公寓" in house_info_list1[0] or "社区" in house_info_list1[0]:
house_info_list2 = house_info_list1[0].split(' ')
house_info_list2 = house_info_list2[0].replace('【','')
house_info_list2 = house_info_list2.replace('】', '|')
else:
house_info_list2 = house_info_list1[0]
print(house_info_list2 + " " + house_url)
house_location = house_info_list2.replace('|',' ')
house_info_list = house_location.split(' ')
print(house_info_list)
house_url = "https://nj.58.com" + house_url
csv_writer.writerow([house_info_list[1], house_url])
csv_file.close()
if __name__ == '__main__':
main()
二、高德地图显示
打开该html文件
初始时坐标中心为北京,输入工作地点并回车后会进行跳转
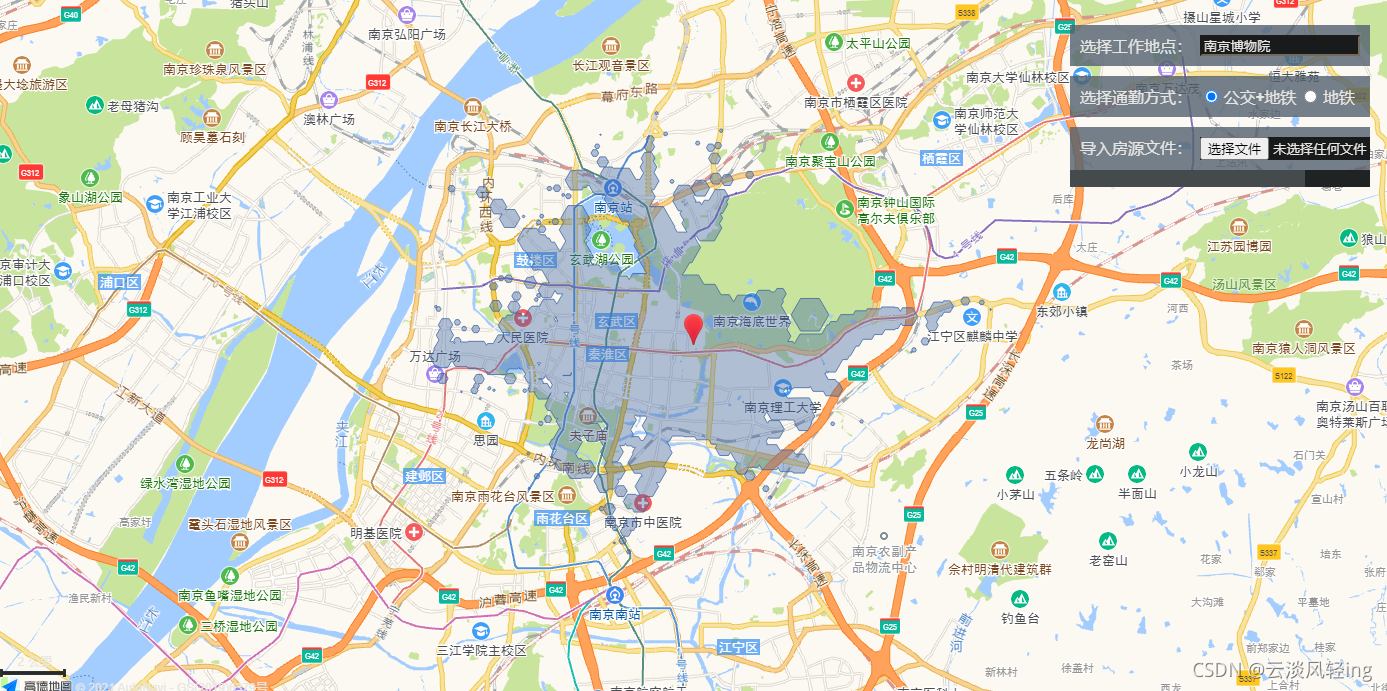
将house.csv文件导入,点击蓝色图标,将自动规划通勤路线
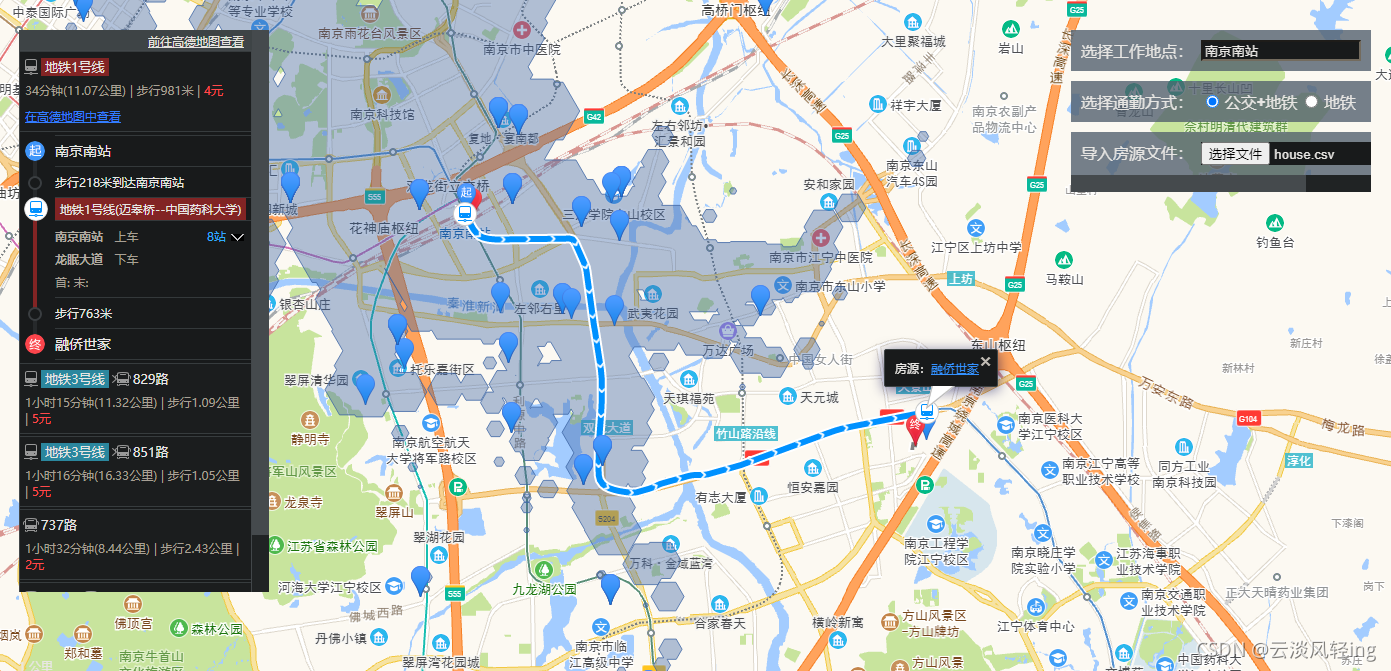
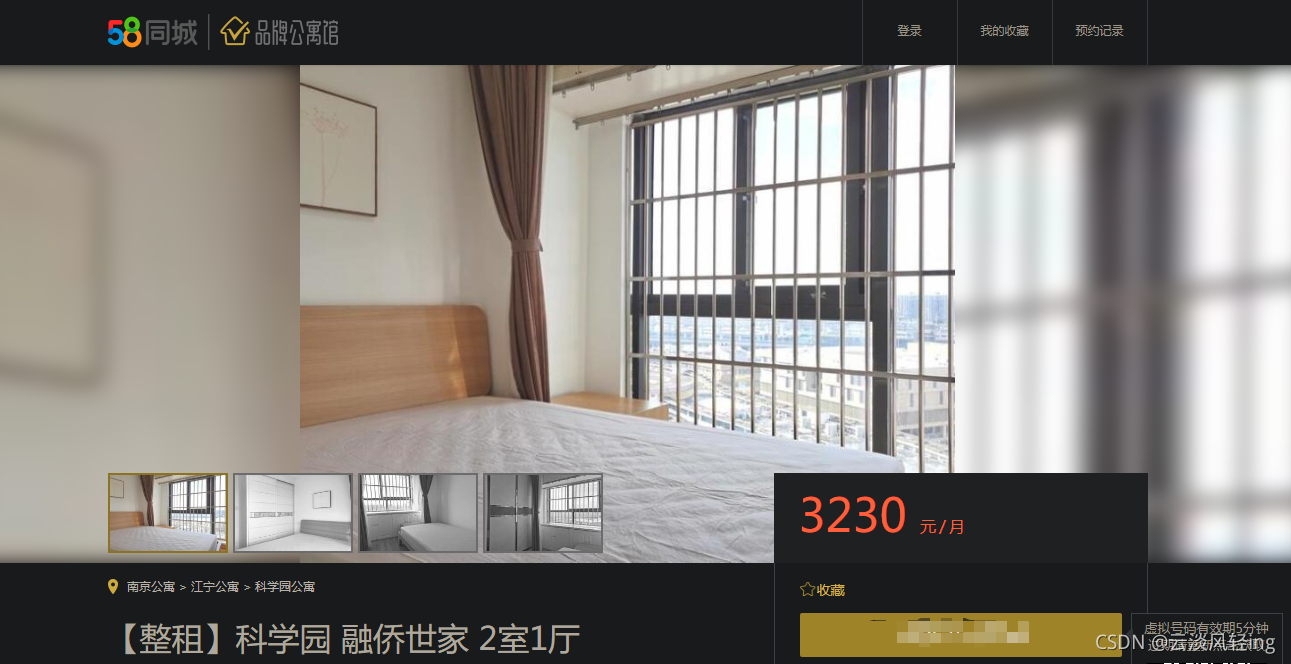
点击房源链接地址后将跳转到指定网址
到此,整个项目已介绍完毕。
已同步发表到个人网站:https://blog.mehoon.com/269.html







【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架