搜狗输入法ng版导入细胞词库过程的简要分析
今天有点时间,对deepin/uos上的搜狗输入法ng版导入细胞词库的行为做了一下分析,过程如下:
1.在属性设置界面,用户选择.scel细胞词库文件,输入法对.scel的文件头进行验证,如果是 40 15 00 00 44 43 53 01 01,则验证通过,进行下一步操作。
然而,在Windows下导入txt文件生成的细胞词库的文件头是 40 15 00 00 D2 6D 53 01 01,搜狗输入法ng版会把词库文件以一个随机的名称扔到 ~/.config/cpis/sogou/attachment目录下,然后不管了。
但是却又提示用户导入成功,其实是没有进行导入操作,词库管理列表中也没有,这种操作很容易误导用户。其实使用txt导入的词库文件与官方的词库并没有什么区别,在后面可以使用脚本导入之后,使用上也是与官方词库无异。
2.在输入法对头文件验证通过之后,对词库文件的特定数据区间进行读取,获取属性信息,具体的偏移量如下:
# 词库的偏移区间与意义: 词库来源:0x004-0x005(44 43为官方词库,D2 6D为用户自定义词库) 词库ID(id):0x001C-0x0026 词库生成时间戳(date):0x011C-0x011F 词库词条数量(words):0x124-0x127 词库名称(name):0x130-0x337 词库类别(type):0x338-0x53F 词库备注(remark):0x540-0xD3F 词库示例词(enumernate):0xD40-0x153F
然后将.scel词库文件,以词库id为名称,复制到 ~/.config/cpis/sogou/pcpy/scd,
将词库属性信息添加到词库列表文件 ~/.config/cpis/sogou/pcpy/scd/list.ini。
词库列表文件格式如下:
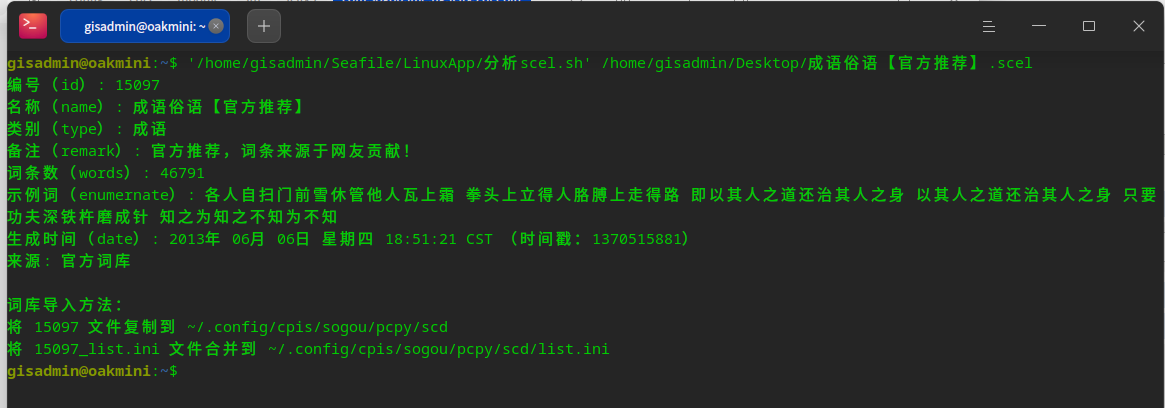
[15097] id = 15097 name = 成语俗语【官方推荐】 type = 成语 remark = 官方推荐,词条来源于网友贡献! enumernate = 各人自扫门前雪休管他人瓦上霜 拳头上立得人胳膊上走得路 即以其人之道还治其人之身 以其人之道还治其人之身 只要功夫深铁杵磨成针 知之为知之不知为不知 words = 46791 date = 1370515881 enabled = true
这样,在输入法的词库管理界面,就可以看到导入的词库,和相关的属性信息了。

对以上的操作进行复现的bash脚本:
#!/bin/bash # parse_scel.sh # 用途:将用户输入的搜狗细胞词库文件,解析词库ID、词库名称、类别、备注、词条数、生成时间、词库来源、示例词并显示。 # 检查输入参数 if [ "$#" -ne 1 ]; then echo "用法: $0 <搜狗细胞词库路径>" exit 1 fi BINARY_FILE="$1" # 检查文件是否存在 if [ ! -f "$BINARY_FILE" ]; then echo "错误: 文件 '$BINARY_FILE' 不存在。请检查文件路径。" exit 1 fi # 提取文件头 HEX_HEADER=$(hexdump -v -s 0 -n 9 -e '1/1 "%02x"' "$BINARY_FILE") # 检查文件头 if [[ "$HEX_HEADER" != "40150000d26d530101" && "$HEX_HEADER" != "401500004443530101" ]]; then echo "$BINARY_FILE 似乎不是搜狗细胞词库,请检查。" exit 1 fi # 读取指定偏移量区间的数据并将其转为 UTF-16LE 的字符串,再转换为 UTF-8 extract_section_utf16le() { local start=$1 local end=$2 # 确保提取的字节数为偶数 local length=$((($end - $start + 1) / 2 * 2)) hexdump -v -s "$start" -n $length -e '1/1 "%02x"' "$BINARY_FILE" | xxd -r -p | iconv -f UTF-16LE -t UTF-8 | tr -d '\0' | tr '\n' ' ' # 转换 UTF-16LE 到 UTF-8,并去除空字符,替换换行符为空格 } # 读取指定偏移量区间的数据,过滤换行符,并将其转为 UTF-16LE 的字符串,再转换为 UTF-8 extract_example_utf16le() { local start=$1 local end=$2 local length=$((($end - $start + 1) / 2 * 2)) # 读取字节,替换 0D 00 20 00 为 20 00,去除换行符,然后转换为 UTF-8(有一些词库的示例词存在换行符) hexdump -v -s "$start" -n "$length" -e '1/1 "%02x"' "$BINARY_FILE" | sed 's/0d002000/2000/g' | xxd -r -p | iconv -f UTF-16LE -t UTF-8 | tr -d '\0' } extract_entry_count() { # 读取 0x124 - 0x127 区间的 4 个字节,并确保转换为小端格式 local hex_count=$(hexdump -v -s 0x124 -n 4 -e '1/1 "%02x"' "$BINARY_FILE") # 确保是偶数长度,去掉最后一个字符(如果是奇数) if [ $(( ${#hex_count} % 2 )) -ne 0 ]; then hex_count="${hex_count:0: -1}" fi # 去除尾部的 "00" 字节 hex_count="${hex_count%%00*}" # 初始化词条数 local entry_count=0 for (( i=0; i<${#hex_count}; i+=2 )); do # 将小端格式转换为十进制数 entry_count=$((entry_count + 0x${hex_count:i:2} * (256 ** (i / 2)))) done # 输出词条数量,去掉前面的空格 echo "$entry_count" } # 提取时间戳并转换为日期时间 timestamp_hex=$(hexdump -v -s 0x011C -n 4 -e '1/4 "%08x"' "$BINARY_FILE") timestamp=$((16#$timestamp_hex)) # 将十六进制转换为十进制 extract_timestamp() { # 显示日期格式和原始时间戳 echo "$(date -d @"$timestamp") (时间戳:$timestamp)" } # 检查词库源类型 extract_library_source() { # 根据前面获取的文件头$HEX_HEADER变量判断词库来源 if [ "$HEX_HEADER" == "40150000d26d530101" ]; then echo "用户自定义词库" elif [ "$HEX_HEADER" == "401500004443530101" ]; then echo "官方词库" fi } # 偏移量区间 (以字节为单位) ID_START=0x001C ID_END=0x0026 NAME_START=0x130 NAME_END=0x337 CATEGORY_START=0x338 CATEGORY_END=0x53F REMARK_START=0x540 REMARK_END=0xD3F EXAMPLE_START=0xD40 EXAMPLE_END=0x153F # 提取信息 dictionary_id=$(extract_section_utf16le $ID_START $ID_END) dictionary_name=$(extract_section_utf16le $NAME_START $NAME_END) dictionary_category=$(extract_section_utf16le $CATEGORY_START $CATEGORY_END) dictionary_remark=$(extract_section_utf16le $REMARK_START $REMARK_END) dictionary_example=$(extract_example_utf16le $EXAMPLE_START $EXAMPLE_END) dictionary_entry_count=$(extract_entry_count) dictionary_timestamp=$(extract_timestamp) library_source=$(extract_library_source) # 输出提取的信息 echo "编号(id): $dictionary_id" echo "名称(name): $dictionary_name" echo "类别(type): $dictionary_category" echo "备注(remark): $dictionary_remark" echo "词条数(words): $dictionary_entry_count" echo "示例词(enumernate): $dictionary_example" echo "生成时间(date): $dictionary_timestamp" echo "来源: $library_source" # 说明: # 词库的偏移区间与意义: # 词库来源:0x004-0x005(44 43为官方词库,D2 6D为用户自定义词库) # 词库ID:0x001C-0x0026 # 词库生成时间戳:0x011C-0x011F # 词库词条数量:0x124-0x127 # 词库名称:0x130-0x337 # 词库类别:0x338-0x53F # 词库备注:0x540-0xD3F # 词库示例词:0xD40-0x153F # 生成搜狗输入法ng版词库列表 id_list.ini create_import_file() { local CWD=$(dirname "$BINARY_FILE") # 获取文件所在的目录 local ini_file_name=""$dictionary_id"_list.ini" local ini_file_path="$CWD/$ini_file_name" # 创建 .ini 文件并写入内容 cat <<EOF > "$ini_file_path" [$dictionary_id] id = $dictionary_id name = $dictionary_name type = $dictionary_category remark = $dictionary_remark enumernate = $dictionary_example words = $dictionary_entry_count date = $timestamp enabled = true EOF # 复制词库文件为 $dictionary_id cp "$BINARY_FILE" "$CWD/$dictionary_id" echo " " echo "词库导入方法:" echo 将 ""$dictionary_id" 文件复制到 "~/.config/cpis/sogou/pcpy/scd"" echo 将 ""$ini_file_name" 文件合并到 "~/.config/cpis/sogou/pcpy/scd/list.ini"" } # 创建词库导入文件 create_import_file
脚本运行截图: