

数据可视化 matplotlib
数据可视化
数据可视化指的是通过可视化表示来探索的数据,它与数据挖掘紧密相关,而数据挖掘指的是使用代码来探索数据集的规律和关联。
在基因研究、天气研究、政治经济分析等众多领域,大家都使用python来完成数据秘密集型工作。数据科学家使用python编写了一系列令人印象深刻的可视化和分析工具。最流行的工具之一是matplotlib,他是一个数学绘图库。我们将使用它来制作简单的图表。
1.安装matplotlib
在Linux环境安装matplotlib
yum install python3-matplotlib
在Windows环境安装matplotlib
win + r 进入cmd框 python -m pip install matplotlib
pychmon安装matplotlib
参考 https://blog.csdn.net/Lemostic/article/details/81676603
测试matplotlib
首先使用python或或者python3启动一个终端,再尝试导入matplotlib
C:\Users\86153>python >>> import matplotlib >>>
如果没有出现任何错误消息,就说明你的系统安装了matplotlib。
matplotlib画廊
要超看使用matplotlib可制作的各种图表,请访问https://matplotlib.org/的示例画廊,单机画廊中的图标,就可以查看用于生成图表的代码。
2.绘制简单的折线图
参数
.plot(squ) #该函数尝试根据这些数据绘制出有意义的图形。 .show() #打开matplotlib查看器,并显示绘制的图形。 .title() #给图表指定标签题 //为每条轴设置标题,fontsize指定图表中文字的大小 .xlabel() .ylabel() .tick_params() #设置刻度标记样式大小 .scatter() 要绘制单个点,并向它传递一对x和y坐标,他将在指定位置绘制一个点。 .savefig() #要让程序自动将图表保存到文件中
1.绘制简单的折线图
使用matplotlib绘制一个简单的折线图,在对其进行定制,以实现信息更丰富的数据可视化。我们将使用平方数序列1,4,9,16和25来绘制这个图表。
import matplotlib.pyplot as pyplot #先导入pyplot模块,并给他指定pyplot。 squ = [1,4,9,16,25] #创建列表存放平均数 pyplot.plot(squ) #该函数尝试根据这些数据绘制出有意义的图形。 pyplot.show() #打开matplotlib查看器,并显示绘制的图形。
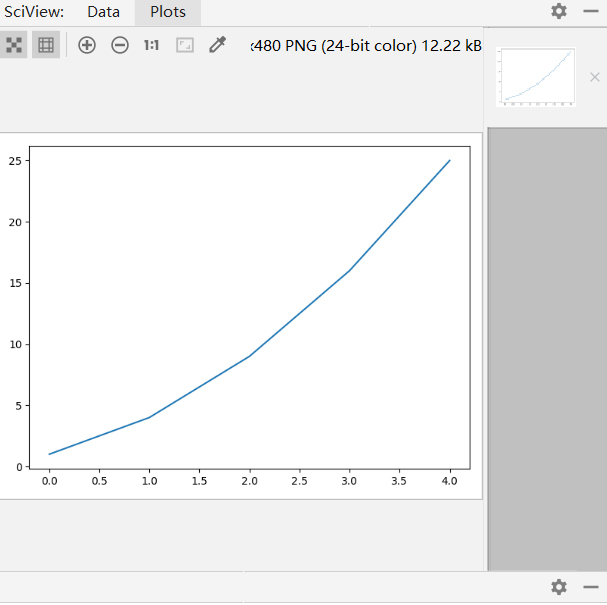
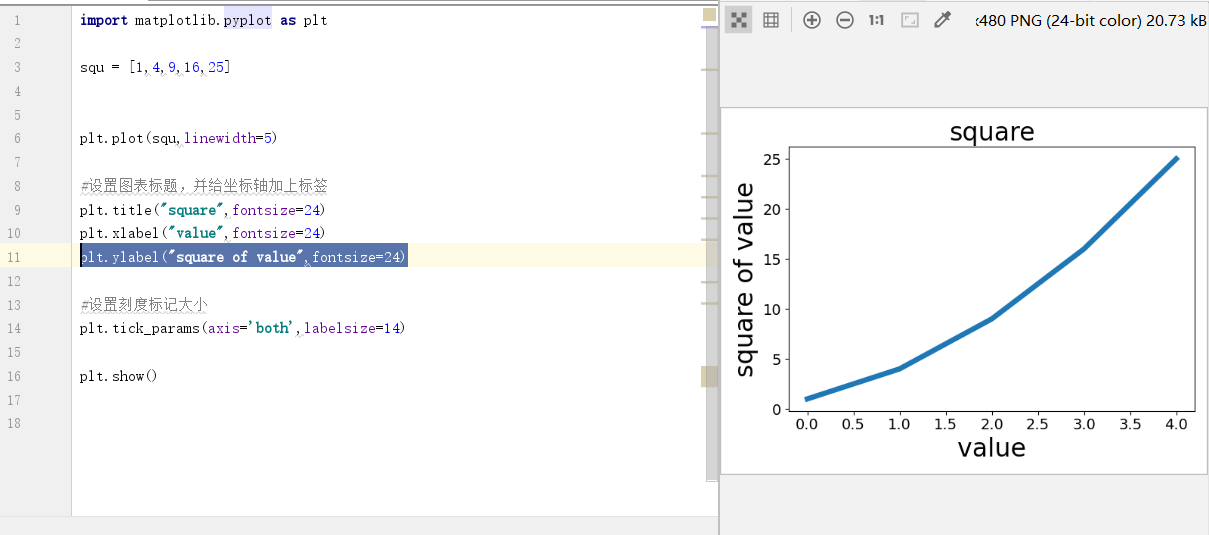
2.修改标签文字和线条粗细
import matplotlib.pyplot as plt squ = [1,4,9,16,25] plt.plot(squ,linewidth=5) #参数linewidth决定了plot()绘制的线条的粗细 #设置图表标题,并给坐标轴加上标签 plt.title("square",fontsize=24) #给图表指定标签题,fontsize指定图表中文字的大小 #为每条轴设置标题,fontsize指定图表中文字的大小 plt.xlabel("value",fontsize=24) plt.ylabel("square of value",fontsize=24) #设置刻度标记样式大小(其中指定的实参将影响x轴与y轴上的刻度(axis='both'),并将刻度标记的字号设置成14.) plt.tick_params(axis='both',labelsize=14) plt.show()
3.校正数据
图形更容易阅读后,我们发现没有正确的绘制数据:折线图的终点指出4.0的平方为25!
当你想plot()提供一系列数字时,他假设第一个数据点对应的x坐标为0.但是我们第一个点对应的x值为1。为改变这种默认行为,我们可以给plot()同时提供输入值和输出值。
import matplotlib.pyplot as plt input_values = [1,2,3,4,5] #提供输入值 squ = [1,4,9,16,25] plt.plot(input_values,squ,linewidth=5) #使用输入值 #设置图表标题,并给坐标轴加上标签 plt.title("square",fontsize=24) plt.xlabel("value",fontsize=24) plt.ylabel("square of value",fontsize=24) #设置刻度标记大小 plt.tick_params(axis='both',labelsize=14) plt.show()
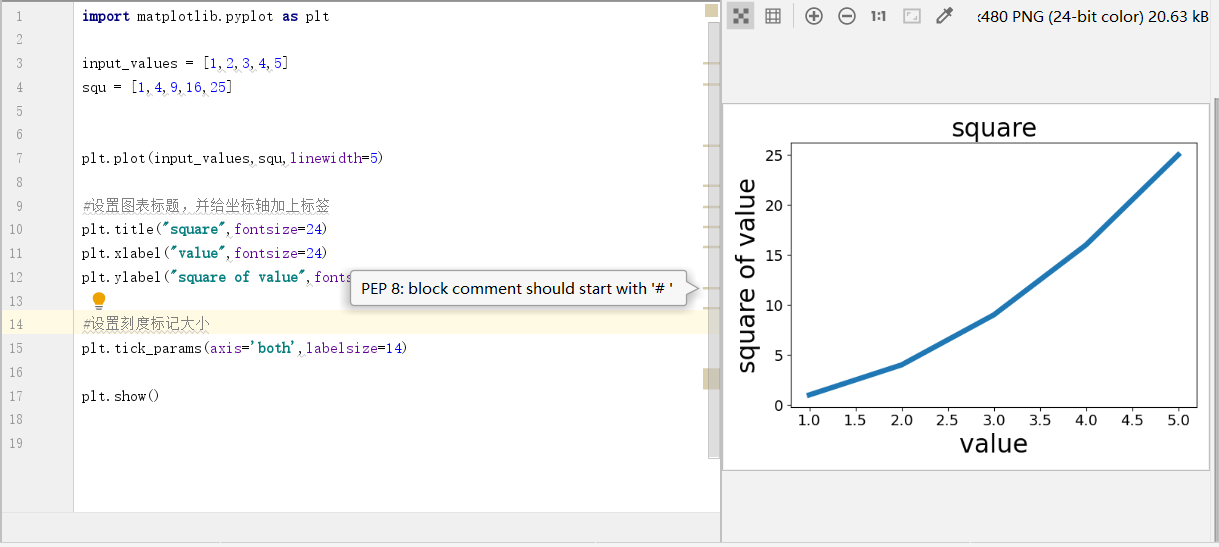
现在plot()将正确的绘制数据,因为我们同时提供了输入值和输出值,它无需对输出值的生成方式作出假设。
使用plot()时可指定各种实参,还可以使用众多函数对图形进行定制。
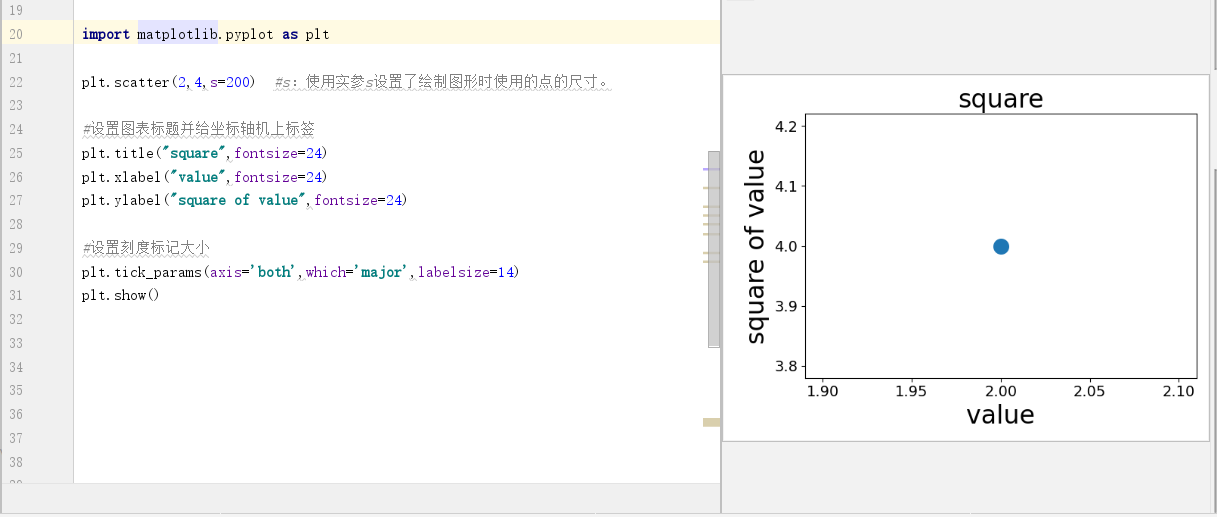
4.使用scatter()绘制散点图并设置其样式
有时候,需要绘制散点图并设置各个数据点的样式。绘制大型数据集时,你还可以对每个点都设置同样的样式,再使用不同的样式选择重新绘制某些点,以突出他们。
要绘制单个点,可以使用函数scatter(),并向它传递一对x和y坐标,他将在指定位置绘制一个点。
import matplotlib.pyplot as plt plt.scatter(2,4,s=200) #s:使用实参s设置了绘制图形时使用的点的尺寸。 #设置图表标题并给坐标轴机上标签 plt.title("square",fontsize=24) plt.xlabel("value",fontsize=24) plt.ylabel("square of value",fontsize=24) #设置刻度标记大小 plt.tick_params(axis='both',which='major',labelsize=14) plt.show()
5.使用scatter()绘制一系列点
要绘制一系列点,可想scatter()传递两个分别包含x值和y值的列表。
import matplotlib.pyplot as plt x_value = [1,2,3,4,5] #要计算其平方值的数字 y_vlaue = [1,4,9,16,25] #包含x列每个数字的平方值 #将这些列表传递给scatter()时,,matplotlib一次从每个列表中读取一个值来绘制一个点。 #要绘制的点的坐标分别为(1,1)(2,4)(3,9)等。 plt.scatter(x_value,y_vlaue,s=100) #s:使用实参s设置了绘制图形时使用的点的尺寸。 #设置图表标题并给坐标轴机上标签 plt.title("square",fontsize=24) plt.xlabel("value",fontsize=24) plt.ylabel("square of value",fontsize=24) #设置刻度标记大小 plt.tick_params(axis='both',which='major',labelsize=14) plt.show()

6.自动计算数据
手工计算列表要包含的值可能效率低下,需要绘制的点很多时尤其如此。可以不必手工计算包含点坐标的列表,而让python循环来替我们完成这种计算。
绘制1000个点
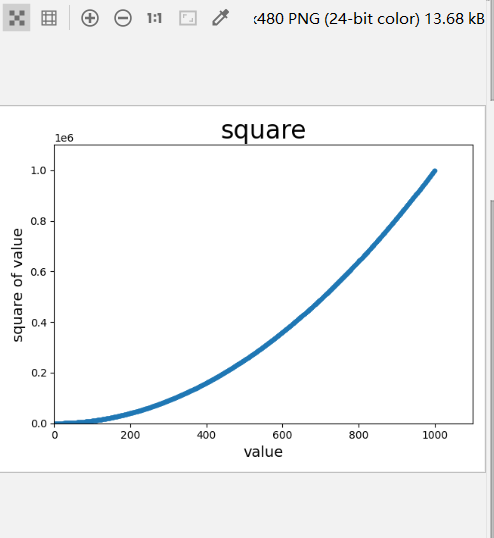
import matplotlib.pyplot as plt x_value = list(range(1,1001)) y_value = [x**2 for x in x_value] print(y_value[-1]) plt.scatter(x_value,y_value,s=10) #设置图表标题并给坐标轴机上标签 plt.title("square",fontsize=24) plt.xlabel("value",fontsize=14) plt.ylabel("square of value",fontsize=14) #设置每个坐标轴的取值范围 plt.axis([0,1100,0,1100000]) plt.show()
我们先创建一个包含x值的列表,其中包含数字1-1000。使用列表生成式计算y的列表,它遍历x值(for x in x_value),计算其平方值(x**2),并将结果存储到列表y_value中,然后,将输入列表和输出列表传递给scatter()。
由于这个数据集比较大,我们将点设置得较小,并使用函数axis()指定了每一个坐标轴的取值范围。函数axis()要求提供四个值:x和y坐标轴的最小值和最大值。
7.删除数据点的轮廓
matplotlib允许你给散点图中的各个点指定颜色。默认为蓝色点和黑色轮廓,在散点图包含的数据点不多时效果很好。但绘制很多点时,黑色轮廓可能会黏在一起。要删除数据点的轮廓,可调用scatter()时传递实参edgecolor='none'
plt.scatter(x_value,y_value,edgecolors='none',s=200)
测试没看出来区别
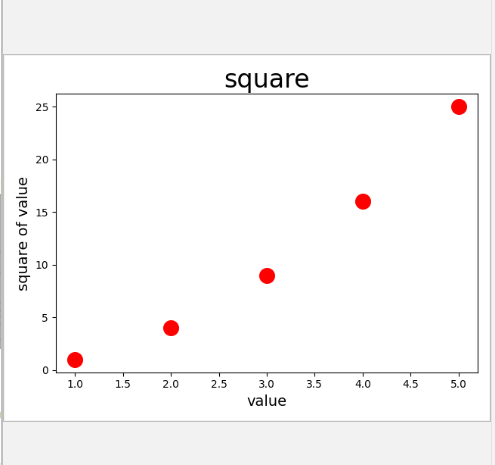
8.自定义颜色
要修改数据点的颜色,可向scatter()传递参数c,并将其设置为要使用的颜色的名称
plt.scatter(x_value,y_value,c='red',s=200)
还可以使用RGB颜色模式自定义颜色。要指定自定义颜色,可传递参数c,并将其设置为一个元组,将其包含三个0~1之间的小数值,他们分别代表红色、绿色和蓝色分量。
创建一个淡蓝点组成的散图
plt.scatter(x_value,y_value,c=(0,0,0.8),s=200)
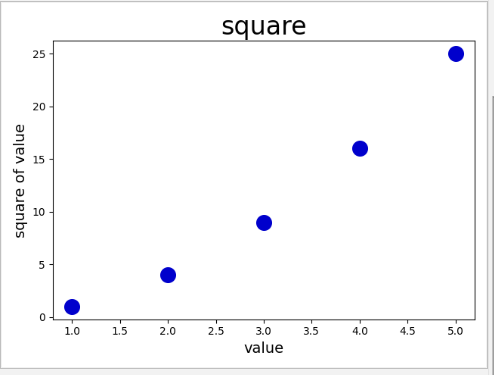
值越接近0,指定的颜色越深,值越接近1,指定的颜色越浅
9.使用颜色映射
颜色映射是一系列颜色。他们从起始颜色渐变到结束颜色。在可视化中,颜色映射用于突出数据的规律,例如,可能用较浅的颜色来显示较小的值,并使用较深的颜色来显示较大的值。
模块pyplot内置了一组颜色映射。要使用这些颜色映射,你需要告诉python该如何设置数据集汇中每个点的颜色。
根据Y值来设置其颜色
import matplotlib.pyplot as plt x_value = list(range(1,1001)) y_value = [x**2 for x in x_value] plt.scatter(x_value,y_value,c=y_value,cmap=plt.cm.Reds,s=40) #设置图表标题并给坐标轴机上标签 plt.title("square",fontsize=14) plt.xlabel("value",fontsize=14) plt.ylabel("square of value",fontsize=14) #设置每个坐标轴的取值范围 plt.axis([0,1100,0,1100000]) plt.show()
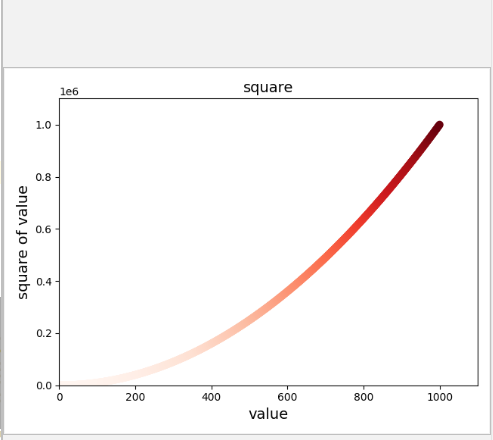
我们将参数c设置成一个y值列表,并使用参数cmap告诉pyplot使用哪个颜色映射。这些代码将y值较小的点显示为浅红色,并将y值较大的点显示为深蓝色。
注意:要了解python中所有的颜色映射,请访问http://matplotlib.org ,单击Examples,找到color,再找到colormap
官方文档颜色
https://matplotlib.org/stable/gallery/color/colormap_reference.html#sphx-glr-gallery-color-colormap-reference-py import numpy as np import matplotlib.pyplot as plt cmaps = [('Perceptually Uniform Sequential', [ 'viridis', 'plasma', 'inferno', 'magma', 'cividis']), ('Sequential', [ 'Greys', 'Purples', 'Blues', 'Greens', 'Oranges', 'Reds', 'YlOrBr', 'YlOrRd', 'OrRd', 'PuRd', 'RdPu', 'BuPu', 'GnBu', 'PuBu', 'YlGnBu', 'PuBuGn', 'BuGn', 'YlGn']), ('Sequential (2)', [ 'binary', 'gist_yarg', 'gist_gray', 'gray', 'bone', 'pink', 'spring', 'summer', 'autumn', 'winter', 'cool', 'Wistia', 'hot', 'afmhot', 'gist_heat', 'copper']), ('Diverging', [ 'PiYG', 'PRGn', 'BrBG', 'PuOr', 'RdGy', 'RdBu', 'RdYlBu', 'RdYlGn', 'Spectral', 'coolwarm', 'bwr', 'seismic']), ('Cyclic', ['twilight', 'twilight_shifted', 'hsv']), ('Qualitative', [ 'Pastel1', 'Pastel2', 'Paired', 'Accent', 'Dark2', 'Set1', 'Set2', 'Set3', 'tab10', 'tab20', 'tab20b', 'tab20c']), ('Miscellaneous', [ 'flag', 'prism', 'ocean', 'gist_earth', 'terrain', 'gist_stern', 'gnuplot', 'gnuplot2', 'CMRmap', 'cubehelix', 'brg', 'gist_rainbow', 'rainbow', 'jet', 'turbo', 'nipy_spectral', 'gist_ncar'])] gradient = np.linspace(0, 1, 256) gradient = np.vstack((gradient, gradient)) def plot_color_gradients(cmap_category, cmap_list): # Create figure and adjust figure height to number of colormaps nrows = len(cmap_list) figh = 0.35 + 0.15 + (nrows + (nrows-1)*0.1)*0.22 fig, axs = plt.subplots(nrows=nrows, figsize=(6.4, figh)) fig.subplots_adjust(top=1-.35/figh, bottom=.15/figh, left=0.2, right=0.99) axs[0].set_title(cmap_category + ' colormaps', fontsize=14) for ax, name in zip(axs, cmap_list): ax.imshow(gradient, aspect='auto', cmap=plt.get_cmap(name)) ax.text(-.01, .5, name, va='center', ha='right', fontsize=10, transform=ax.transAxes) # Turn off *all* ticks & spines, not just the ones with colormaps. for ax in axs: ax.set_axis_off() for cmap_category, cmap_list in cmaps: plot_color_gradients(cmap_category, cmap_list) plt.show()

10.自动保存图表
要让程序自动将图表保存到文件中,可将对plt.show()的调用替换为对plt.savefig()的调用:
plt.savefig('C:\\Users\86153\Desktop\MEG.png',bbox_inches='tight')
第一个实参指定要以什么样的文件保存文件,以及文件路径,如果不写文件路径,泽保存在py文件所在的文件的目录中;
第二个参数指定将图表多余的空白区域裁减掉。如果要保留图表周围多余的空白区域,可省略这个实参。
练习
数字的三次方成为立方,绘制一个图形,显示前五个数的立方
import matplotlib.pyplot as plt x_value = [1,2,3,4,5] y_value = [x*x*x for x in x_value] plt.plot(x_value,y_value,linewidth=5,color='m') # plt.scatter(x_value,y_value,c=y_value,cmap=plt.cm.Reds) plt.title("biaoti",fontsize=24) plt.xlabel("value",fontsize=19) plt.ylabel("y-value",fontsize=19) plt.axis([1,6,0,150]) plt.show()
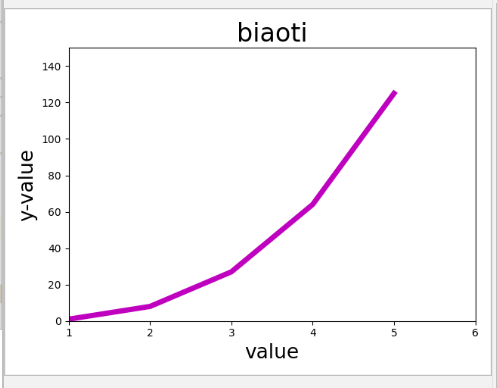
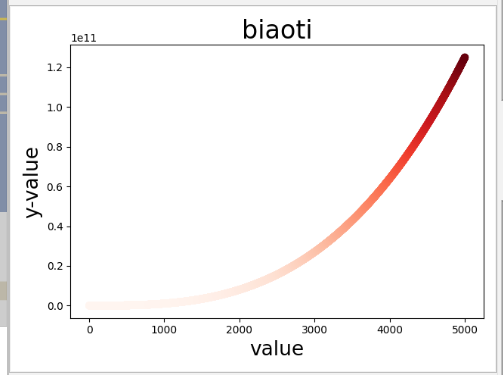
数字的三次方成为立方,绘制一个图形,显示前5000个整数的立方值。
import matplotlib.pyplot as plt x_value = list(range(1,5001)) y_value = [x*x*x for x in x_value] plt.scatter(x_value,y_value,s=40,c=y_value,cmap=plt.cm.Reds) # plt.scatter(x_value,y_value,c=y_value,cmap=plt.cm.Reds) plt.title("biaoti",fontsize=24) plt.xlabel("value",fontsize=19) plt.ylabel("y-value",fontsize=19) # plt.axis([1,6,0,150]) plt.show()
模拟骰子出现的次数
模拟摇骰子
from random import randint class Die(): """表示一个骰子的类""" def __init__(self,num=6): self.num = num def roll(self): """返回一个位于1和骰子面数之间的随机值""" return randint(1,self.num)
数据可视化
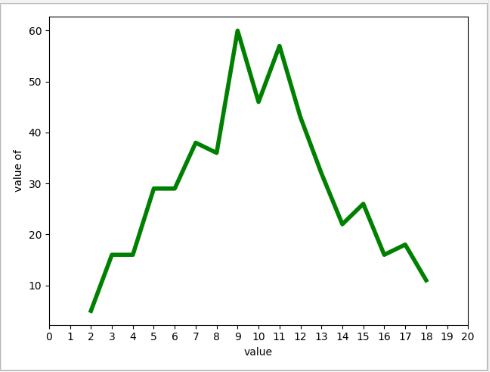
#使用matplotlib模拟掷骰子 import matplotlib.pyplot as plt from pygalwww import Die from matplotlib.pyplot import MultipleLocator as mult #创建一个6面骰子和一个10面骰子 die_1 = Die(8) die_2 = Die(10) #掷几次骰子,并将掷出来的点数存储在一个列表中 results = [ die_1.roll() + die_2.roll() for i in range(500)] #每次产生的点数相加 #会出现的点数 max_result = die_1.num + die_2.num x_freq = [i for i in range(2,max_result+1)] #结果分析,计算都会有哪些值出现 y_freq = [results.count(i) for i in range(2,max_result+1)] #结果分析,统计每个点数出现的次数 #数据可视化 plt.plot(x_freq,y_freq,linewidth=4,c='green') print(x_freq) plt.xlabel("value") plt.ylabel("value of") #把x轴间隔设置为1,并存在变量里面 x_major = mult(1) #ax为两条坐标轴的实例 ax = plt.gca() #把x轴的主刻度设置为1的倍数 ax.xaxis.set_major_locator(x_major) plt.xlim(0,20) # plt.ylim(0,100) plt.show()
3.随机漫步
我们将使用python来生成随机漫步数据,在使用matplotlib以引人瞩目的方式将这些数据呈现出来。随机漫步是这样行走得到的路径:每次行走都完全是随机的,没有明确的方向,结果是由一系列随机决策决定的。可以这样认为,随机漫步就是蚂蚁在晕头转向的情况下,每次都眼随机的方向前行所经过的路径。
参数
.figure() #用于指定图表的宽度、高度、分辨率和背景色。 figsize=(x,y) #绘图窗口的尺寸,单位是英寸 dpi=xxx #分辨率 //隐藏坐标轴 .xticks([]) #去掉x轴 .yticks([]) #去掉y轴 .axis('off') #去掉坐标轴
随机漫步scatter()
1.1创建rand()类
为模拟随机漫步,我们将创建一个名为rand的类,它随机地选择前进方向。这个类需要三个属性,其中一个是存储随机漫步次数的数量,其他两个是列表,分别存储随机漫步经过的每个点的x和y坐标。
rand类只包含两个方法:init()和fill_walk(),其后者计算随机漫步经过的所有点。
//创建类,选择方向 from random import choice #调用随机数模块 #创建类 class Rand(): """一个生成随机漫步数据的类""" def __init__(self,num=50000): """初始化随机漫步的属性""" self.num = num #漫步的次数 #所有随机漫步都始于(0,0) self.x_value = [0] self.y_value = [0] #选择方向 def fill_walk(self): """计算随机漫步包含的所有点""" #不断漫步,直到列表达到指定的长度,退出漫步 while len(self.x_value) < self.num: #决定前进方向以及沿这个方向前进的距离 x_dir = choice([1,-1]) #向左-1 向右1 x_dis = choice([0,1,2,3,4]) #移动几个距离 x_step = x_dir * x_dis y_dir = choice([1,-1]) y_dis = choice([0,1,2,3,4]) y_step = y_dir * y_dis #拒绝原地踏步 if x_step == 0 and y_step == 0: continue #计算下一个点的x和y值 next_x = self.x_value[-1] + x_step next_y = self.y_value[-1] + y_step self.x_value.append(next_x) self.y_value.append(next_y) #为获得漫步中下一个点x值,我们将x_step和y_value中的最后一个值相加,与y值也是同理。获得下一个点的x值和y值,我们将他们分别附加到列表的末尾。 //绘制图表 import matplotlib.pyplot as plt #创建一个rand实例,并将其包含的点都绘制出来 rw = Rand() rw.fill_walk() #设置绘图窗口的尺寸 plt.figure(figsize=(10,6)) #给点着色 point = list(range(rw.num)) plt.scatter(rw.x_value,rw.y_value,c=point,cmap=plt.cm.Blues,s=1) #突出起点和终点 plt.scatter(0,0,c='green',s=100) plt.scatter(rw.x_value[-1],rw.y_value[-1],c='red',s=100) #隐藏坐标轴 plt.xticks([]) #去掉x轴 plt.yticks([]) #去掉y轴 plt.axis('off') #去掉坐标轴 plt.show()

建立一个循环,这个循环不断循环,直到漫步包含所需数量的点。这个方法的主要部分告诉python如何模拟四种漫步决定:向右走还是向左走,沿指定的方向走多远,向上还是向下走,沿选定方向走多远。
分子运动 plot()
分子运动:模拟花粉在水滴表面的运动轨迹。
重构了随机漫步代码
from random import choice #创建类 class Rand(): """一个生成随机漫步数据的类""" def __init__(self,num=5000): """初始化随机漫步的属性""" self.num = num def get_step(self): """用于确定漫步的距离和方向""" # 所有随机漫步都始于(0,0) value = [0] while len(value) < self.num: # 决定前进方向以及沿这个方向前进的距离 dir = choice([1, -1]) dis = choice([0, 1, 2, 3, 4, 5, 6, 7, 8]) step = dir * dis # 计算下一个点的x和y值 next_x = value[-1] + step value.append(next_x) return value def fill_walk(self): """计算随机漫步包含的所有点""" x_step = self.get_step() y_step = self.get_step() self.x_step = x_step self.y_step = y_step import matplotlib.pyplot as plt #创建一个rand实例,并将其包含的点都绘制出来 rw = Rand() rw.fill_walk() #设置绘图窗口的尺寸 plt.figure(figsize=(10,6)) #给点着色 point = list(range(rw.num)) # plt.scatter(rw.x_value,rw.y_value,c=point,cmap=plt.cm.Blues,s=1) plt.plot(rw.x_step,rw.y_step,linewidth=3) #突出起点和终点 plt.scatter(0,0,c='green',s=100) plt.scatter(rw.x_step[-1],rw.y_step[-1],c='red',s=100) #隐藏坐标轴 plt.xticks([]) #去掉x轴 plt.yticks([]) #去掉y轴 plt.axis('off') #去掉坐标轴 plt.show()

4.1.使用pygal模拟掷骰子
本节,我们将使用python可视化包pygal来生成可缩放的矢量图形文件。对于需要在尺寸不同的屏幕上显示的图表,这很有用,因为他们将自动缩放,以适合观看者屏幕。
我们将对掷骰子的结果进行分析。掷6面的常规骰子时,可能会出现的结果为1-6点,且出现每种结果的可能性相同。为确定哪些点数出现的可能性最大,我们将生成一个表示掷骰子结果的数据集,并根据结果绘制出一个图形。
在数学领域,常常利用掷骰子来解释各个数据分析,但他在赌场和其他博弈场景中也得到了
2.安装pygal
Linux和OS x系统中,应执行
pip install --user pygal
在Windows系统中
python -m pip install --user pygal
你可能需要使用命令pip3而不是pip,如果这还是不管用,可能需要删除标志 --user。
2.1pygal画廊
要了解使用pygal可创建什么样的图表,请查看图表类型画廊,访问:http://www.pygal.org/ ,单击documentation,再单击chart types。每个实例都包含源代码。
2.2 模拟一个掷骰子
创建Die类,模拟骰子出点数
from random import randint class Die(): """表示一个骰子的类""" def __init__(self,num=6): self.num = num def roll(self): """返回一个位于1和骰子面数之间的随机值""" return randint(1,self.num)
数据处理
import pygal from pygalwww import Die #创建一个D6 die = Die() #掷几次骰子,并将结果存储在一个列表中 results = [] #存放每次掷骰子的点数 for i in range(1000): #掷N次骰子 result = die.roll() #每次产生的点数 results.append(result) #将产生的点数存入列表 # print(results) #结果分析 freq = [] #统计每个点数出现的次数 for value in range(1,die.num+1): #range出会出现的点数 fre = results.count(value) #count:统计在列表中出现的次数 freq.append(fre) #将统计出来的次数存入列表中。 # print(freq) #对比结果可视化 hist = pygal.Bar() #创建条形图,创建的一个实例 hist.title = "Results of rolling." #用于标示直方图的字符串 hist.x_labels = ['1','2','3','4','5','6'] #轴x的值 hist.x_title = 'Result' #轴x的标题 hist.y_title = "Frequency of Result" #轴y的标题 hist.add('D6',freq) #将一系列值添加到图标中(向它传递要给添加的值指定的标签,还有一个列表,其中包含将出现在图标中的值。) hist.render_to_file('die_visual.svg') #将这个图表渲染为一个SVG文件,这种文件名称必须为.svg。
要查看生成的直方图,最简单的方式就是使用web浏览器。
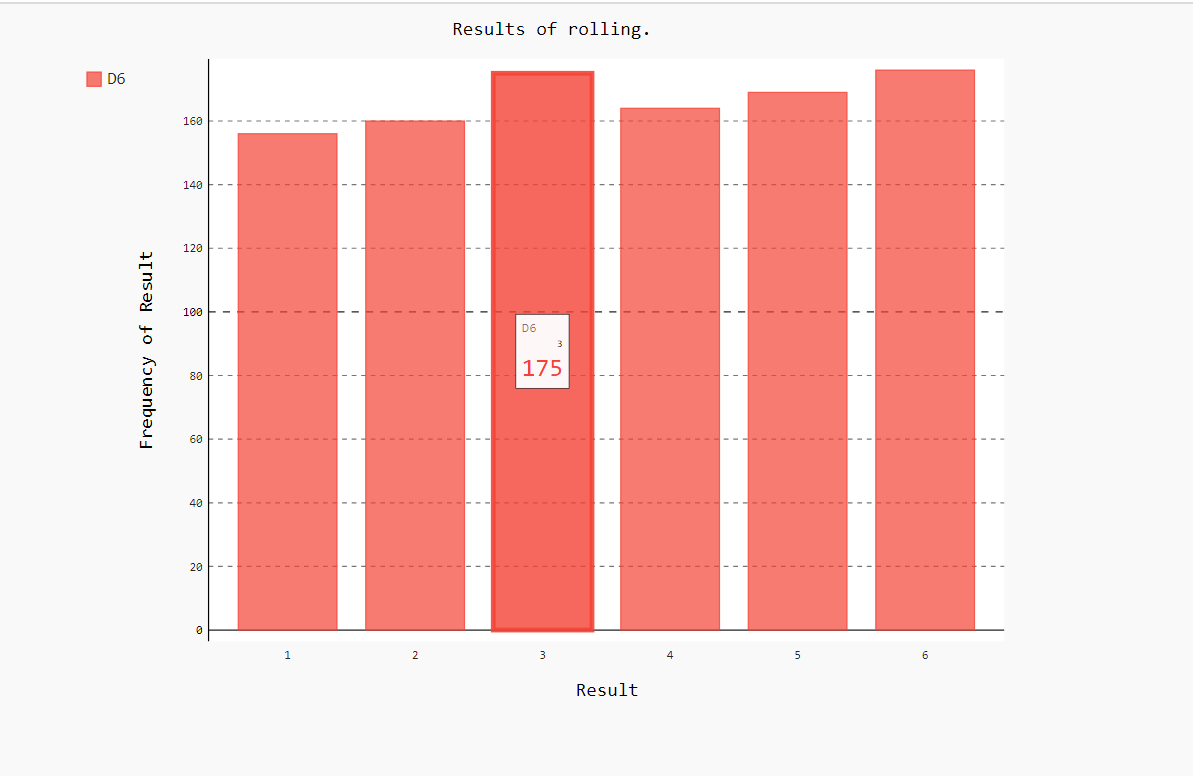
注意:pygal让这个图更具有交互性:如果你将鼠标指向该图中任何条形,将看到与之相关联的数据。在同一个图标中绘制多个数据集时,这项功能显得特别有用。
2.3同时掷两个骰子
同时掷两个骰子时,得到的点数更多,结果分布也不同。下面修改代码,创建两个D6骰子,以模拟同时掷两个骰子的情况。每次掷骰子时,我们都将两个骰子的点数相加,并将结果存储。
创建Die类,模拟骰子出点数
from random import randint class Die(): """表示一个骰子的类""" def __init__(self,num=6): self.num = num def roll(self): """返回一个位于1和骰子面数之间的随机值""" return randint(1,self.num)
数据处理
import pygal from pygalwww import Die #创建两个D6骰子 die_1 = Die() die_2 = Die() #掷几次骰子,并将结果存储在一个列表中 results = [] #存放每次掷骰子的点数 for i in range(1000): #掷N次骰子 result = die_1.roll() + die_2.roll() #每次产生的点数相加 results.append(result) #将产生的点数存入列表 # print(results) print(len(results)) #结果分析 freq = [] #统计每个点数出现的次数 max_result = die_1.num + die_2.num #会出现的点数 for value in range(2,max_result+1): #range出会出现的点数 fre = results.count(value) #count:统计在列表中出现的次数 freq.append(fre) #将统计出来的次数存入列表中。 print(freq) #对比结果可视化 hist = pygal.Bar() #创建条形图,创建的一个实例 hist.title = "Results of rolling." #用于标示直方图的字符串 hist.x_labels = ['2','3','4','5','6','7','8','9','10','11','12'] #轴x的值 hist.x_title = 'Result' #轴x的标题 hist.y_title = "Frequency of Result" #轴y的标题 hist.add('D6 + D6',freq) #将一系列值添加到图标中(向它传递要给添加的值指定的标签,还有一个列表,其中包含将出现在图标中的值。) hist.render_to_file('die_visual.svg') #将这个图表渲染为一个SVG文件,这种文件名称必须为.svg。
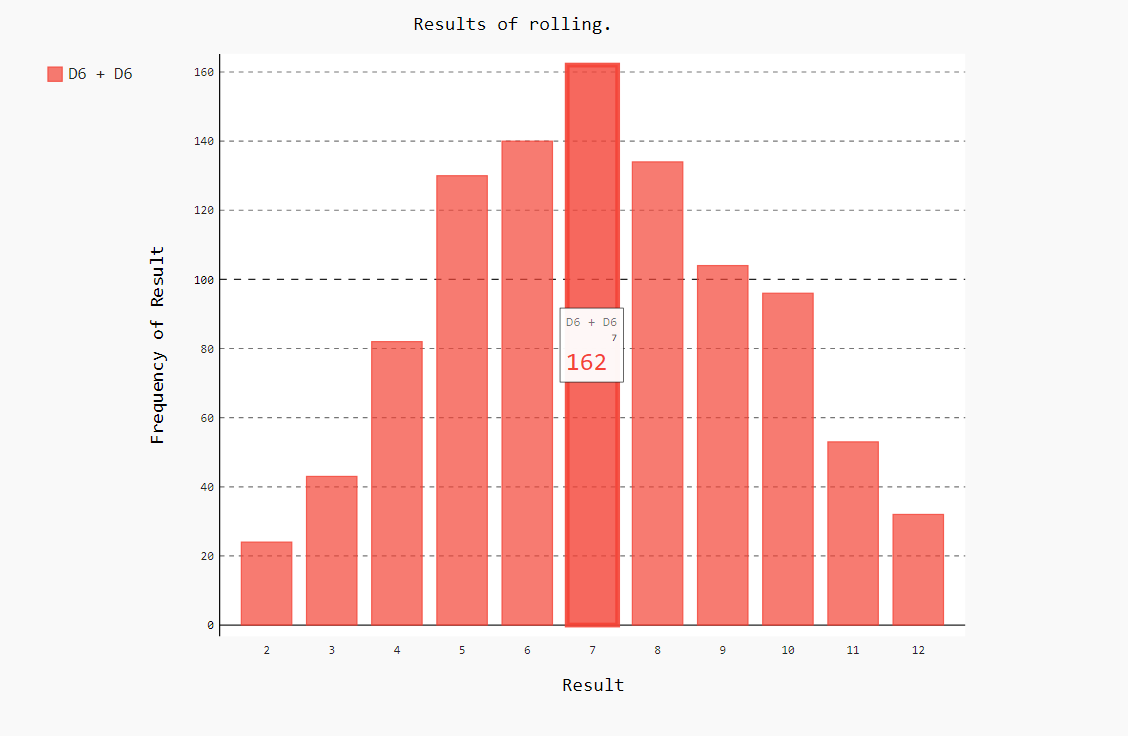
两个骰子买7看来不是没有道理的~~
2.4同时掷两个面数不同的骰子
创建一个6面骰子和一个10面骰子,看掷出结果如何
创建骰子
数据生成
import pygal from pygalwww import Die #创建一个6面骰子和一个10面骰子 die_1 = Die() die_2 = Die(10) #掷几次骰子,并将结果存储在一个列表中 results = [] #存放每次掷骰子的点数 for i in range(5000): #掷N次骰子 result = die_1.roll() + die_2.roll() #每次产生的点数相加 results.append(result) #将产生的点数存入列表 # print(results) print(len(results)) #结果分析 freq = [] #统计每个点数出现的次数 max_result = die_1.num + die_2.num #会出现的点数 for value in range(2,max_result+1): #range出会出现的点数 fre = results.count(value) #count:统计在列表中出现的次数 freq.append(fre) #将统计出来的次数存入列表中。 print(freq) #对比结果可视化 hist = pygal.Bar() #创建条形图,创建的一个实例 hist.title = "Results of rolling." #用于标示直方图的字符串 hist.x_labels = ['2','3','4','5','6','7','8','9','10','11','12','13','14','15','16'] #轴x的值 hist.x_title = 'Result' #轴x的标题 hist.y_title = "Frequency of Result" #轴y的标题 hist.add('D6 + D10',freq) #将一系列值添加到图标中(向它传递要给添加的值指定的标签,还有一个列表,其中包含将出现在图标中的值。) hist.render_to_file('die_visual.svg') #将这个图表渲染为一个SVG文件,这种文件名称必须为.svg。
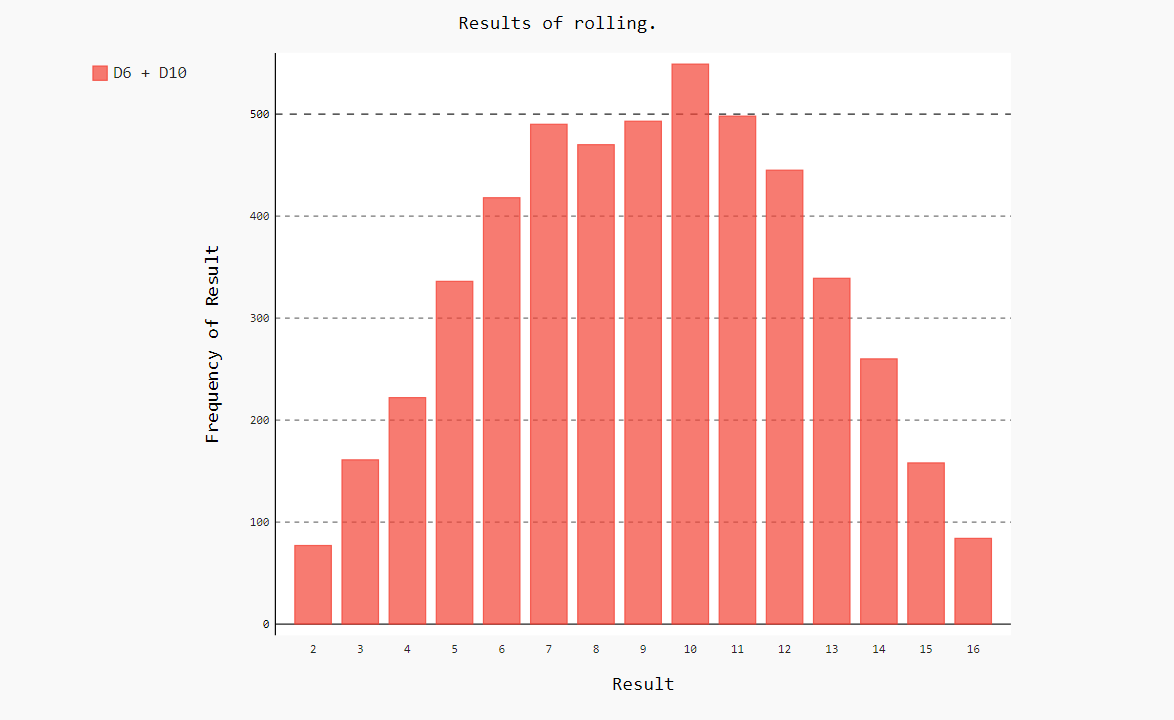
为创建D10骰子,我们在创建第二个die实例时传递了实参10,将循环次数从1000次修改为了5000次。
通过使用pygal来模拟掷骰子的结果,能够非常自由地探索这种现象,只需几分钟,就可以掷各种骰子多次。
将for循环优化为列表解析,优化hist.x_labels值的为自动生成。优化hist.add的名称自动生成
import pygal from pygalwww import Die #创建一个6面骰子和一个10面骰子 die_1 = Die(8) die_2 = Die(8) #掷几次骰子,并将掷出来的点数存储在一个列表中 results = [ die_1.roll() + die_2.roll() for i in range(500)] #每次产生的点数相加 #结果分析,统计每个点数出现的次数 max_result = die_1.num + die_2.num #会出现的点数 freq = [results.count(i) for i in range(2,max_result+1)] #对比结果可视化 hist = pygal.Bar() #创建条形图,创建的一个实例 hist.title = "Results of rolling." #用于标示直方图的字符串 hist.x_labels = [i for i in range(2,max_result+1)] #轴x的值 hist.x_title = 'Result' #轴x的标题 hist.y_title = "Frequency of Result" #轴y的标题 hist.add(f'D{die_1.num} + D{die_2.num}',freq) #将一系列值添加到图标中(向它传递要给添加的值指定的标签,还有一个列表,其中包含将出现在图标中的值。) hist.render_to_file('die_visual.svg') #将这个图表渲染为一个SVG文件,这种文件名称必须为.svg。
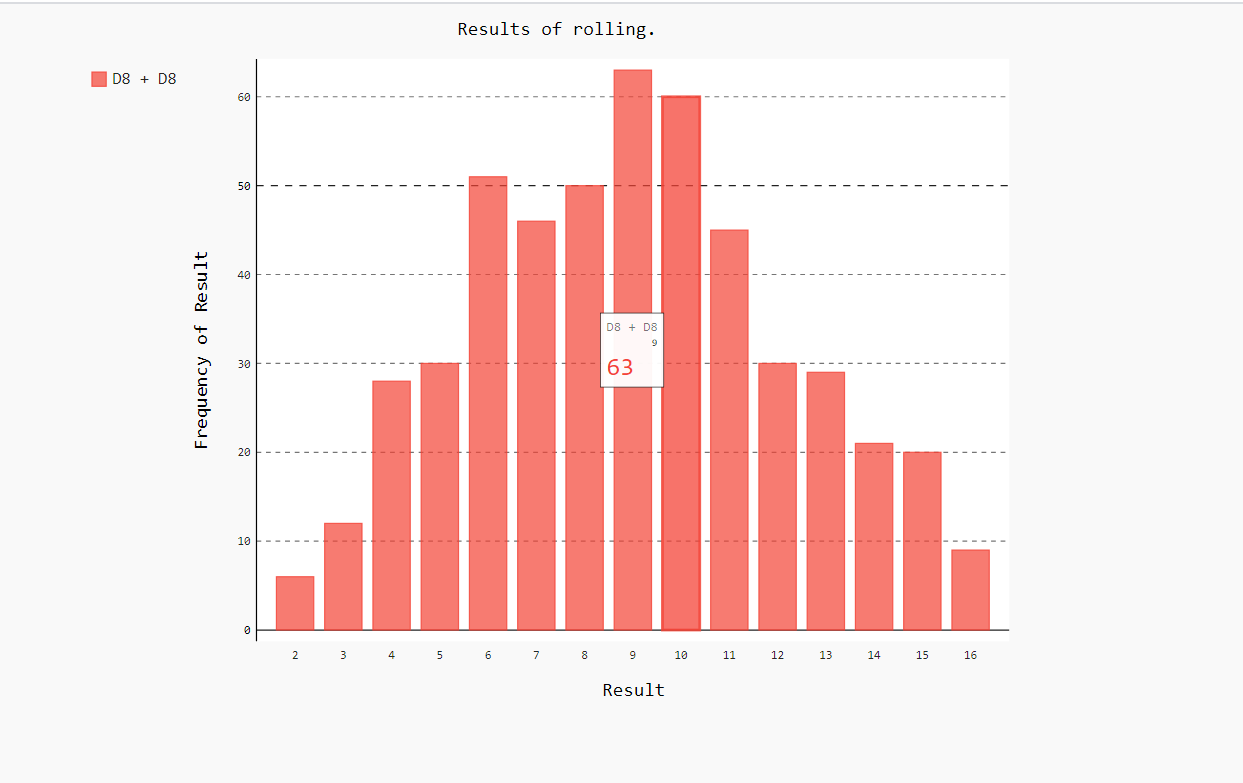
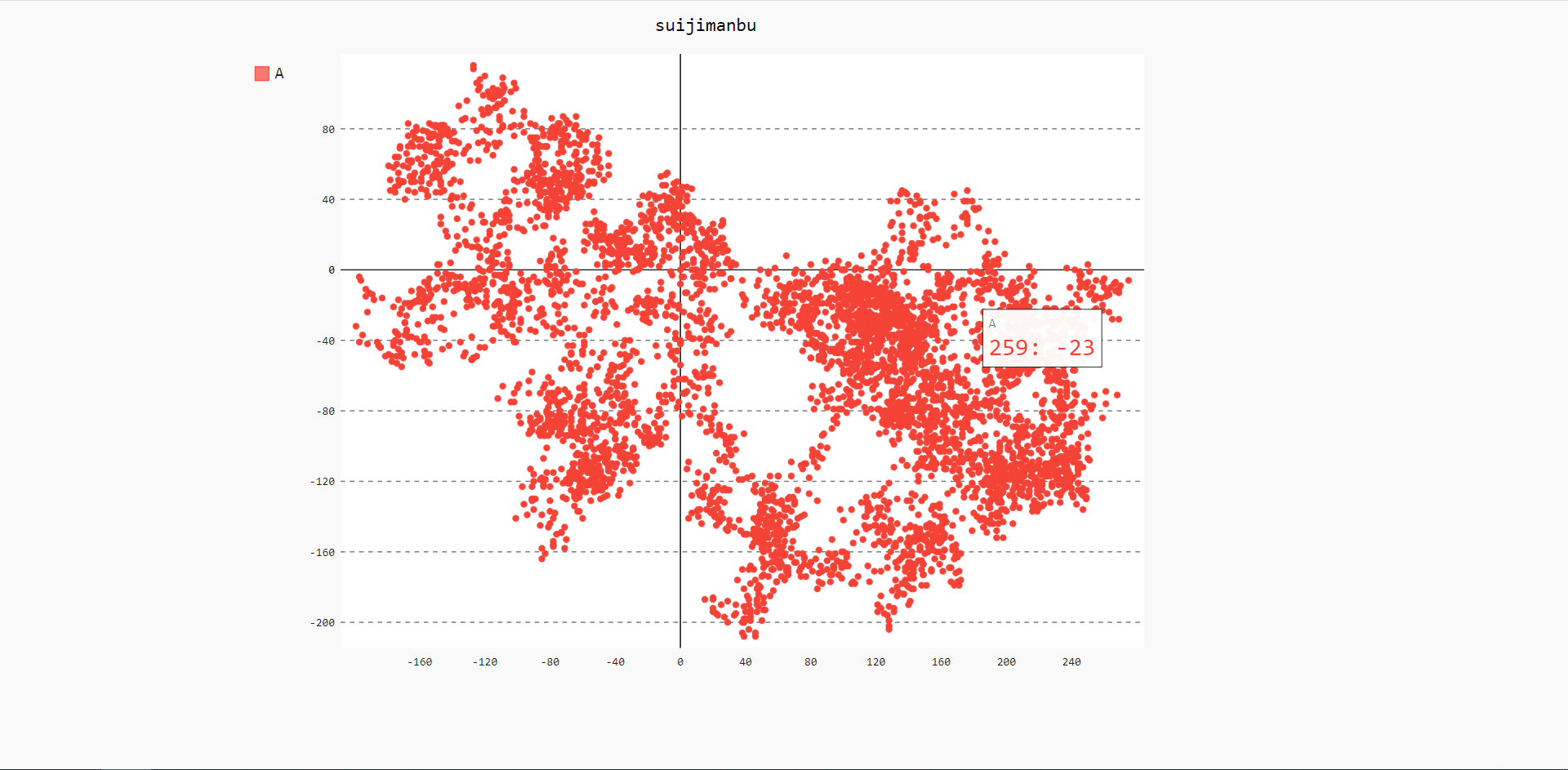
模拟随机漫步
from random import choice #创建类 class Rand(): """一个生成随机漫步数据的类""" def __init__(self,num=5000): """初始化随机漫步的属性""" self.num = num def get_step(self): """用于确定漫步的距离和方向""" # 所有随机漫步都始于(0,0) value = [0] while len(value) < self.num: # 决定前进方向以及沿这个方向前进的距离 dir = choice([1, -1]) dis = choice([0, 1, 2, 3, 4, 5, 6, 7, 8]) step = dir * dis # 计算下一个点的x和y值 next_x = value[-1] + step value.append(next_x) return value def fill_walk(self): """计算随机漫步包含的所有点""" x_step = self.get_step() y_step = self.get_step() self.x_step = x_step self.y_step = y_step #初始化数据 import pygal #生成漫步类 py = Rand() py.fill_walk() #x轴和y轴生成元组 add_all = [(0,0)] for i in range(1,py.num): add_all.append((py.x_step[i],py.y_step[i])) #实例化XY类,参数stroke=False说明我们不需要绘制折线,只要点 xy_chart = pygal.XY(stroke=False) #把我们图表的标题设置好 xy_chart.title = 'suijimanbu' #把点的标签,横纵坐标设置好 xy_chart.add('A', add_all) xy_chart.render_to_file('C:\\Users\\MEG\\Desktop\\Python\\bar_chart.svg')
5.下载数据
本章将从网上下载数据,并对这些数据进行可视化。我们将访问并可视化的数据以常见格式存储的数据:CSV和JSON。
5.1 JSON格式
下载json格式的交易收盘价数据,并使用模块json来处理他们。使用pygal对收盘价格数据进行可视化,以探索价格变化的周期性。
1.1 下载收盘价数据
附件
1.2 提取相关数据
import json #将数据加载到一个列表中 filename = 'btc_close_2017.json' with open(filename) as f: f = f.read() btc_data = json.loads(f) #打印每一天的信息 for btc in btc_data: date = btc['date'] #日期 month = btc['month'] #月份 week = btc['week'] #周数 weekday = btc['weekday'] #周几 close = btc['close'] #收盘价格 print(f"{date} {month}月 {week}周 星期:{weekday},收盘价格 {close}元") 结果: 2017-01-01 01月 52周 星期:Sunday,收盘价格 6928.6492元 2017-01-02 01月 1周 星期:Monday,收盘价格 7070.2554元 .... 2017-12-11 12月 50周 星期:Monday,收盘价格 110642.88元 2017-12-12 12月 50周 星期:Tuesday,收盘价格 113732.6745元
1.3 绘制收盘价折线图
import json #将数据加载到一个列表中 filename = 'btc_close_2017.json' with open(filename) as f: f = f.read() btc_data = json.loads(f) #创建5个列表,分别存储日期和收盘价 dates = [] months = [] weeks = [] weekdays = [] close = [] #打印每一天的信息,并转换为int()类型 for btc in btc_data: dates.append(btc['date']) #日期 months.append(int(btc['month'])) #月份 weeks.append(int(btc['week'])) #周数 weekdays.append(btc['weekday']) #周几 close.append(int(float(btc['close']) )) #收盘价格,python不能直接将包含小数点的字符串'22.332'转换为整数。为消除这种错误需要先将字符串转换为浮点数(float),再将浮点数转换为整数(int) # print(len(months)) #绘制收盘折线图 import pygal line_chart = pygal.Line(x_label_rotation=20,show_minor_x_labels=False) line_chart.title = '收盘价(¥)' line_chart.x_labels = dates N = 20 #x轴坐标每隔20天显示一次 line_chart.x_labels_major = dates[::N] line_chart.add('收盘价',close) line_chart.render_to_file('D:\\python资料\\30s\\代码\\数据可视化\\收盘价折线图(¥).svg')
在创建line实例时,分别设置了x_label_rotation与show_minor_x_labels作为初始化参数。x_label_rotation=20让x轴上的日期标签顺时针旋转20°,show_minor_x_labels=false则告诉图形不用显示所有的x轴标签。设置了图形的标题和x轴标签之后,我们配置x_lable_major属性,让x轴坐标每隔20天显示一次,这样x轴就不会显得非常拥挤了
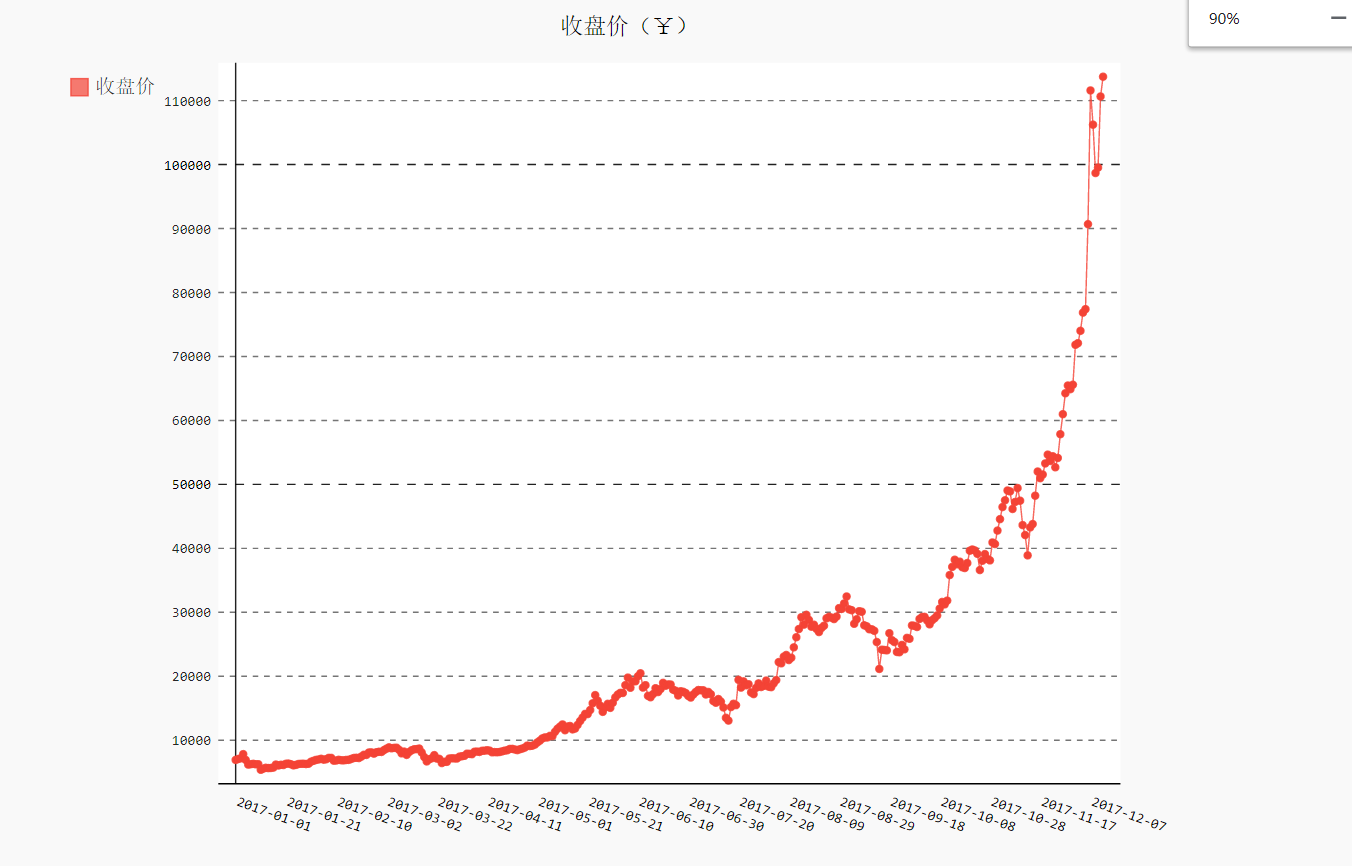
1.4 时间序列特征初探
进行时间序列分析总是期望发展趋势、周期性和噪声,从而能够描述事实、预测未来、做出决策。从收盘价的折线图可以看出,2017年的总体趋势是非线性的,而且增长幅度不断增大。不过,在每个季度末似乎有一些相似的波动。尽管这些波动被增长的趋势掩盖了,不过其中也许有周期性。未来验证周期性的假设,需要首先将非线性的趋势消除。
对数变换是常用的处理方法之一。用python标准库的数学模块math来处理。,math中有许多常用的数学函数,这里用以10为底的对数函数math.log10计算收盘价,日期仍然保持不变。这种方式成为半对数变换。
import json #将数据加载到一个列表中 filename = 'btc_close_2017.json' with open(filename) as f: f = f.read() btc_data = json.loads(f) #创建5个列表,分别存储日期和收盘价 dates = [] months = [] weeks = [] weekdays = [] close = [] #打印每一天的信息,并转换为int()类型 for btc in btc_data: dates.append(btc['date']) #日期 months.append(int(btc['month'])) #月份 weeks.append(int(btc['week'])) #周数 weekdays.append(btc['weekday']) #周几 close.append(int(float(btc['close']) )) #收盘价格,python不能直接将包含小数点的字符串'22.332'转换为整数。为消除这种错误需要先将字符串转换为浮点数(float),再将浮点数转换为整数(int) # print(len(months)) #绘制收盘折线图 import pygal import math line_chart = pygal.Line(x_label_rotation=20,show_minor_x_labels=False) line_chart.title = '收盘价(¥)' line_chart.x_labels = dates N = 20 #x轴坐标每隔20天显示一次 line_chart.x_labels_major = dates[::N] close_log = [math.log10(_) for _ in close] line_chart.add('收盘价',close_log) line_chart.render_to_file('D:\\python资料\\30s\\代码\\数据可视化\\收盘价折线图(¥).svg')
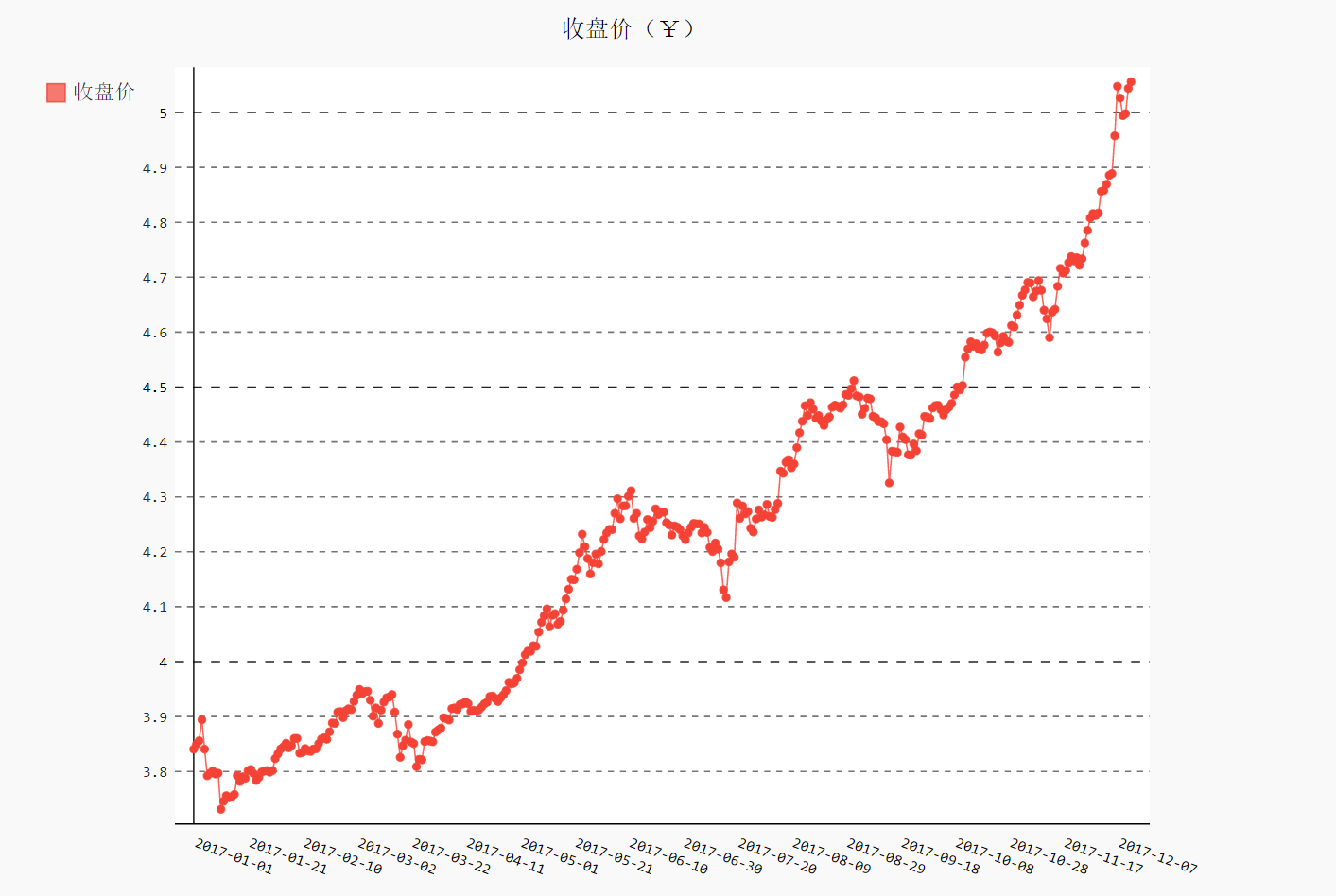
使用对数变换剔除非线性趋势之后,整体上涨的趋势更接近线性增长。收盘价在每个季度末似乎有显著的周期性,都出现了剧烈的波动。
1.5 收盘价均值
绘制2017年前11个月的日均值,前49周的日均值,以及每周中隔天的日均值。
代码详细解析文档 https://blog.csdn.net/pythonxiaohei/article/details/100101290
import json #将数据加载到一个列表中 filename = 'btc_close_2017.json' with open(filename) as f: f = f.read() btc_data = json.loads(f) #创建5个列表,分别存储日期和收盘价 dates = [] months = [] weeks = [] weekdays = [] close = [] #打印每一天的信息,并转换为int()类型 for btc in btc_data: dates.append(btc['date']) #日期 months.append(int(btc['month'])) #月份 weeks.append(int(btc['week'])) #周数 weekdays.append(btc['weekday']) #周几 close.append(int(float(btc['close']) )) #收盘价格,python不能直接将包含小数点的字符串'22.332'转换为整数。为消除这种错误需要先将字符串转换为浮点数(float),再将浮点数转换为整数(int) # print(len(months)) #绘制收盘折线图 import pygal import math from itertools import groupby line_chart = pygal.Line(x_label_rotation=20,show_minor_x_labels=False) line_chart.title = '收盘价(¥)' line_chart.x_labels = dates N = 20 #x轴坐标每隔20天显示一次 line_chart.x_labels_major = dates[::N] close_log = [math.log10(_) for _ in close] line_chart.add('收盘价',close_log) line_chart.render_to_file('D:\\python资料\\30s\\代码\\数据可视化\\收盘价折线图(¥).svg') def draw(x_data,y_data,title,y_legend): xy_map = [] #创建一个空列表 for x,y in groupby(sorted(zip(x_data,y_data)),key=lambda _:_[0]): y_list = [v for _,v in y] xy_map.append([x,sum(y_list) / len(y_list)]) #xy_map=[[1, 6285.870967741936], [2, 7315.714285714285]]类似于这样的值 x_unique,y_mean = [*zip(*xy_map)] line_chart = pygal.Line() line_chart.title = title line_chart.x_labels = x_unique line_chart.add(y_legend,y_mean) line_chart.render_to_file(title+'.svg') return line_chart #收盘价月日均值 idx_month = dates.index('2017-12-01') line_chart_month = draw(months[:idx_month],close[:idx_month],'收盘价月日均值','月日均值') line_chart_month #收盘价周日均值 idx_week = dates.index('2017-12-11') line_chart_week = draw(weeks[1:idx_week],close[1:idx_week],'收盘价周日均值','周日均值') line_chart_week #收盘价星期均值 idx_weeks = dates.index('2017-12-11') wd = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'] weekdays_int = [ wd.index(w) +1 for w in weekdays[1:idx_weeks]] print(weekdays_int) line_chart_weekday = draw(weekdays_int,close[1:idx_weeks],'收盘价星期均值','星期均值')
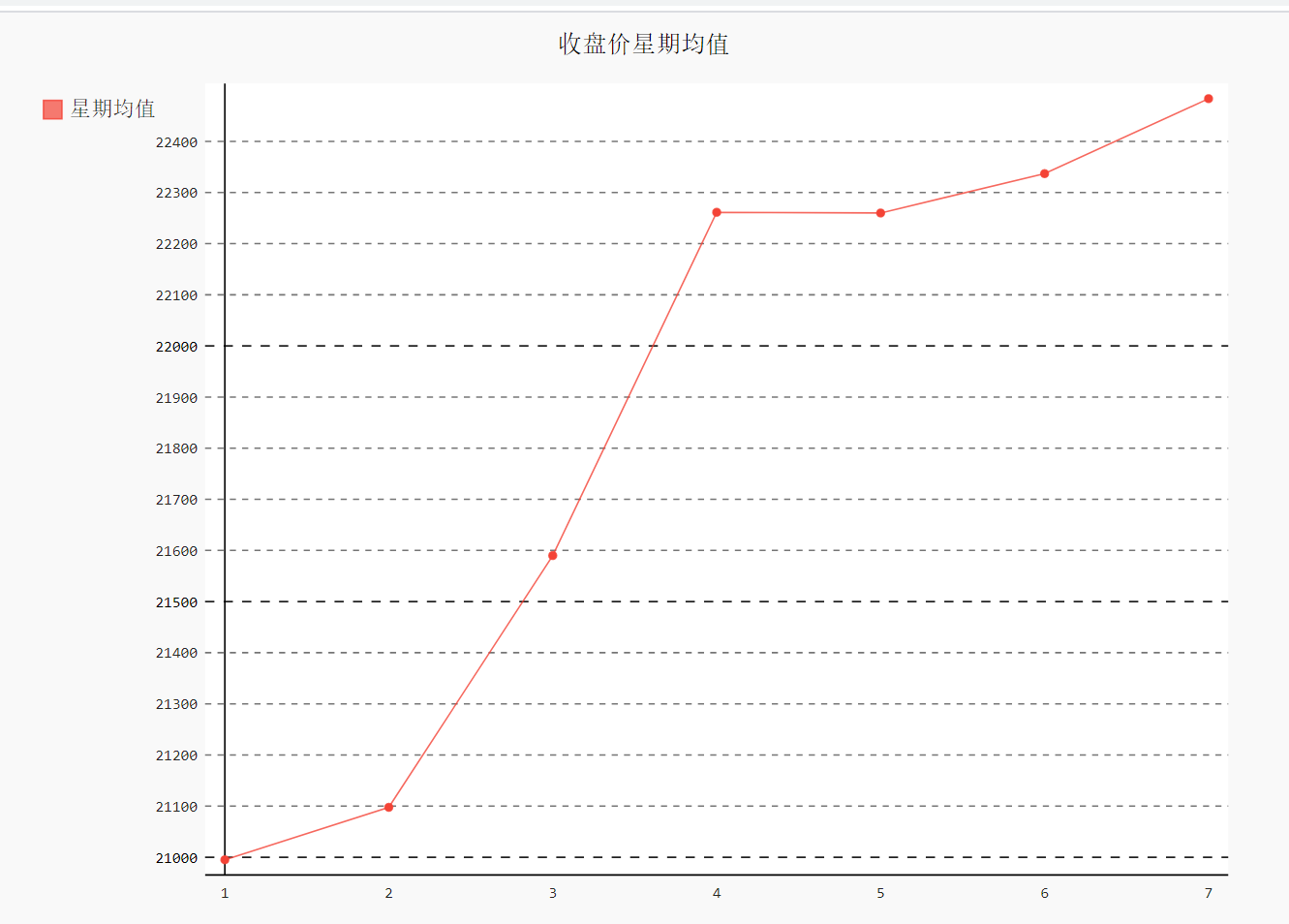
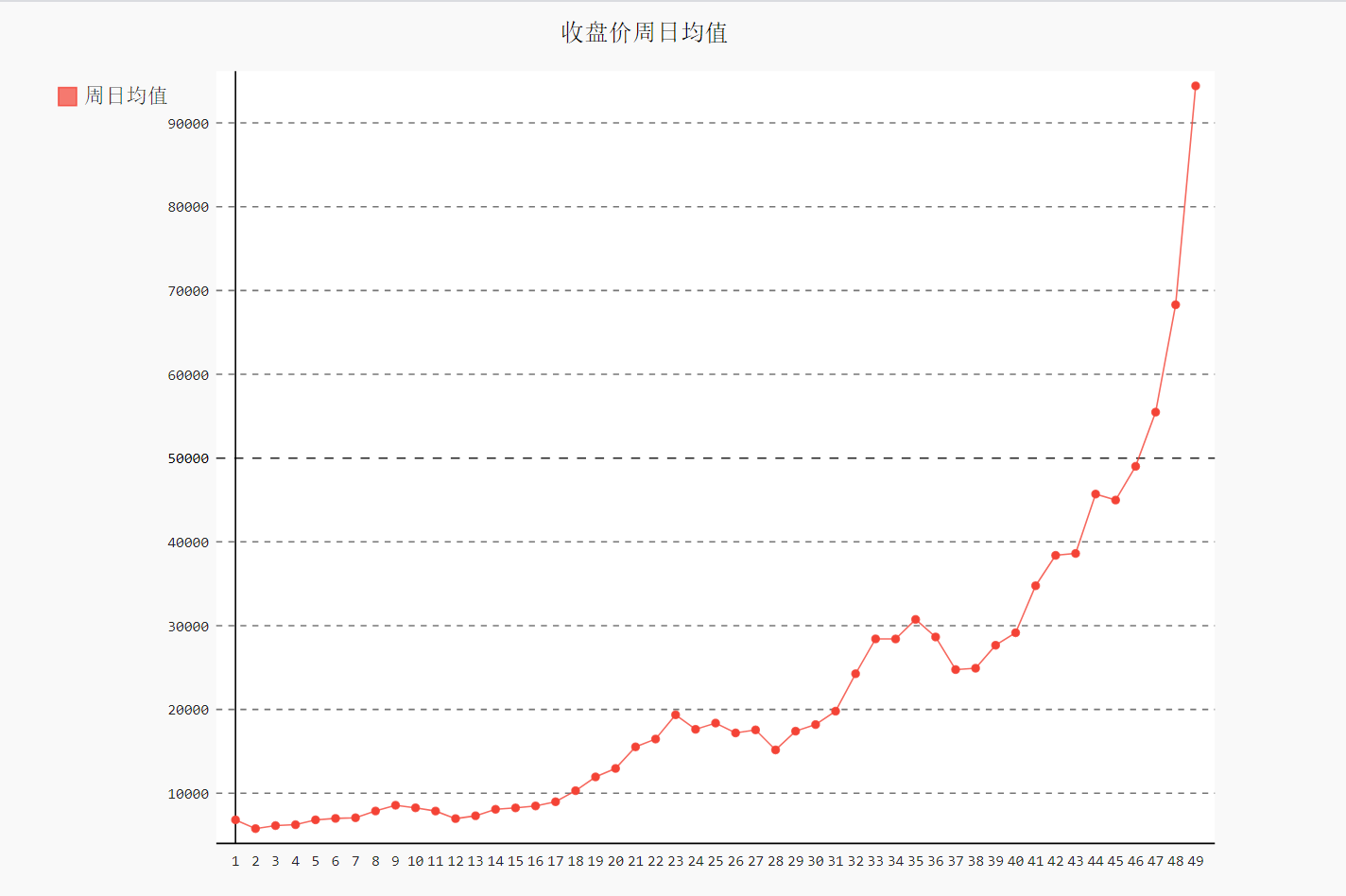
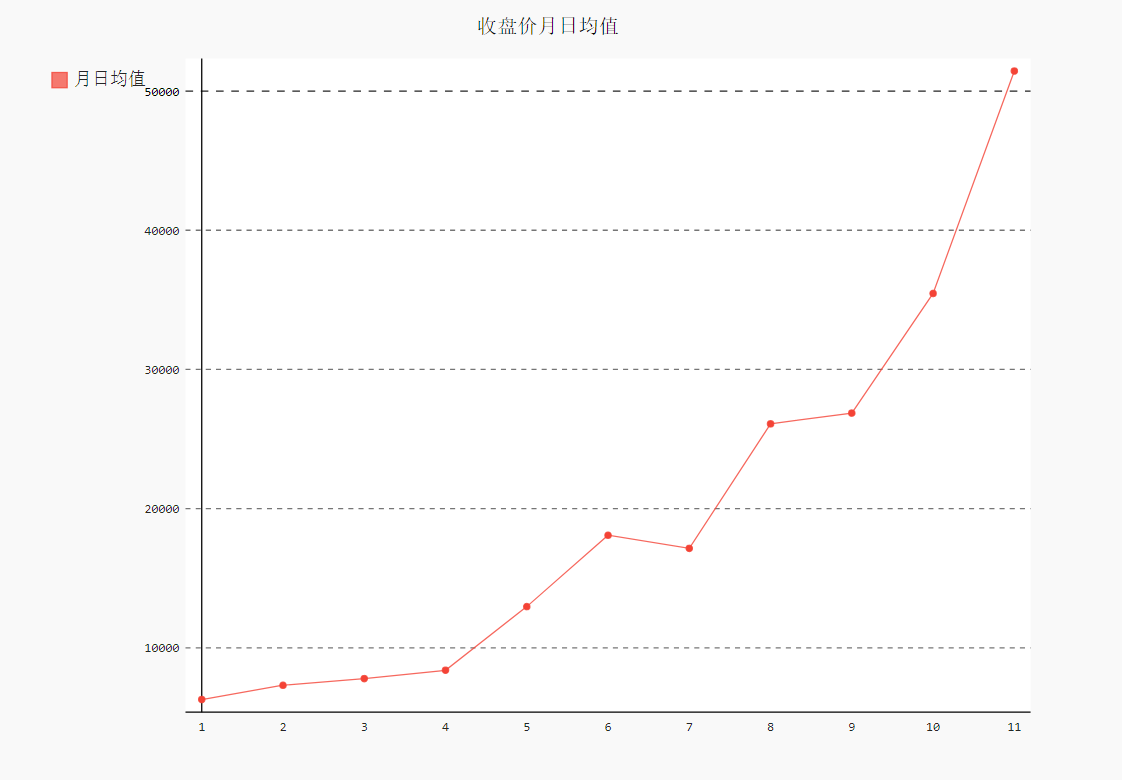
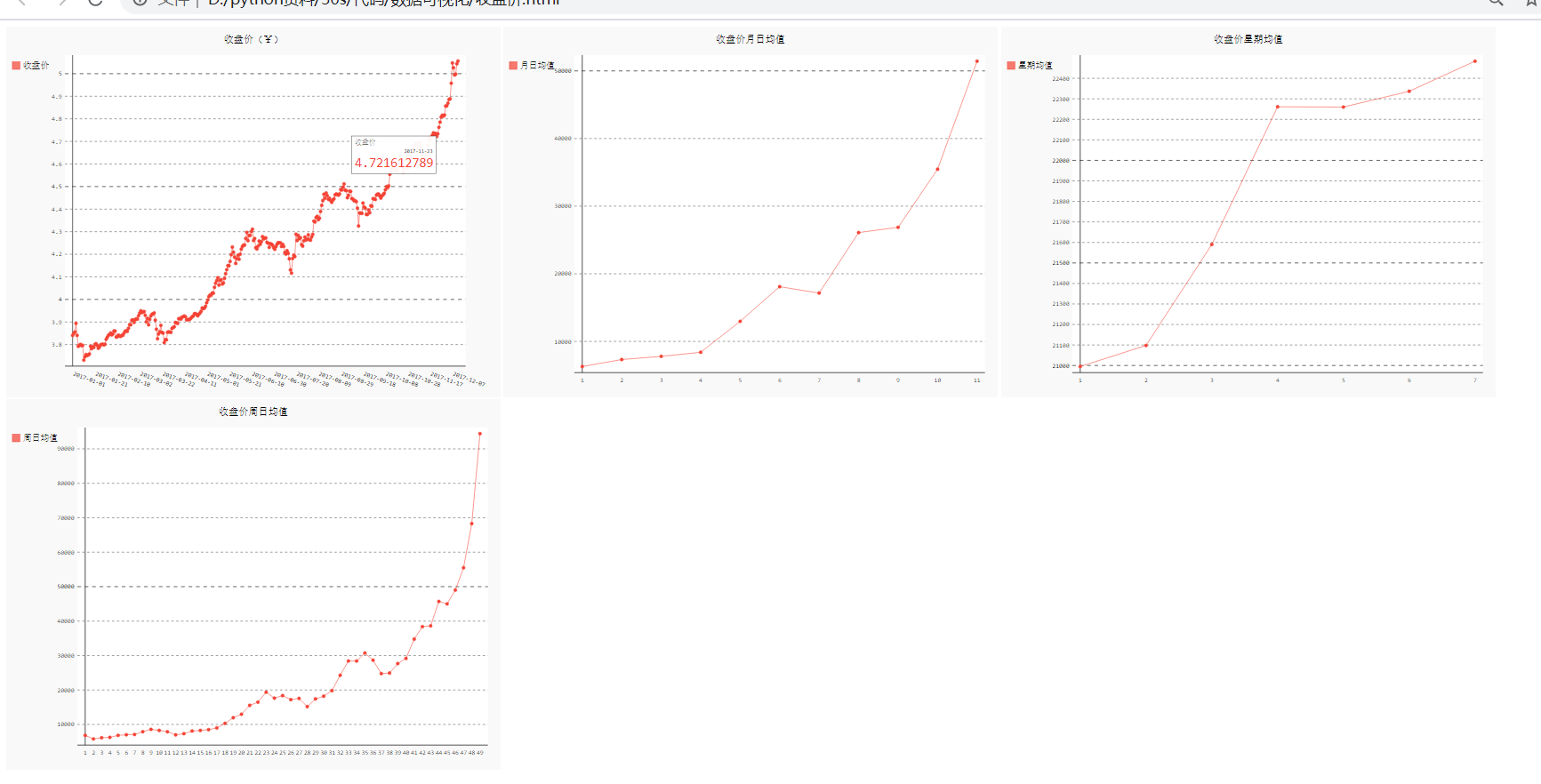
1.6 收盘价数据仪表盘
with open('收盘价.html','w',encoding='utf8') as file: file.write('<html><head><title>收盘价</title><metacharset="utf8"></head><boby>\n') for svg in ['收盘价折线图(¥).svg','收盘价月日均值.svg','收盘价星期均值.svg','收盘价周日均值.svg']: file.write(' <object type="image/svg+xml" data="{0}" height=500></object>\n'.format(svg)) file.write('</boby></html>')
5.2.CSV文件格式
要在文件文件中存储数据,最简单的方式时将数据作为一系列以逗号分隔的值(CSV)写入文件。这样的文件称为CSV文件。
CSV文件对于人类来说阅读起来比较麻烦,但程序可轻松地提取并处理其中的值,这有助于加快数据分析的过程。
其文件以纯文本形式存储表格数据(数字和文本),文件的每一行都是一个数据记录。
1.1分析CSV文件头
CSV模块包含在python标准库中,可用于分析CSV文件中的数据行。
filename = 'sitka_weather_07-2014.csv' #存储文件变量名 with open(filename) as f: #将结果文件对象存储在f中 reader = csv.reader(f) #使用csv读取文件对象 header_row = next(reader) #使用next()获取文件第一行,运行一次next()调用一行数据 print(header_row) #打印出next()拿出来的第一行数据 结果:['AKDT', 'Max TemperatureF', ......', ' CloudCover', ' Events', ' WindDirDegrees']
注意:文件头的格式并非总是一致的,空格和单位可能出现在奇怪的地方。这些在原始数据文件中很常见,但不会带来任何问题。
1.2打印文件头及其位置
为了让文件头数据更容易理解,将列表中的每个文件头及其位置都打印出来
import csv filename = 'sitka_weather_07-2014.csv' #存储文件变量名 with open(filename) as f: #将结果文件对象存储在f中 reader = csv.reader(f) #使用csv读取文件对象 header_row = next(reader) #使用next()获取文件第一行,运行一次next()调用一行数据 for index,column in enumerate(header_row): #对列表调用了enumerate()来获取每个元素的索引及其值。 print(index,column) 结果: 0 AKDT 1 Max TemperatureF 2 Mean TemperatureF .... 21 Events 22 WindDirDegrees
1.3提取数据并读取数据
知道需要那些列中的数据后,首先读取每天的最高气温
import csv #从文件中获取最高气温 filename = 'sitka_weather_07-2014.csv' #存储文件变量名 with open(filename) as f: #将结果文件对象存储在f中 reader = csv.reader(f) #使用csv读取文件对象 header_row = next(reader) #使用next()获取文件第一行,运行一次next()调用一行数据 highs = [] #创建一个列表,存放文件第二列的数据 for row in reader: high = int(row[1]) #取出每个循环的第二列的数据,并将转换为int类型 highs.append(high) #将数据存放highs列表。 print(highs) 结果: [64, 71, 64, 59, 69, 62, 61, 55, 57, 61, 57, 59, 57, 61, 64, 61, 59, 63, 60, 57, 69, 63, 62, 59, 57, 57, 61, 59, 61, 61, 66]
阅读器对象从起停留的地方继续往下读取CSV文件,每次都自动返回当前所处位置的下一行。由于我们已经读取了文件头行,这个循环将从第二行开始--从这行开始包含的是实际数据。
1.4 绘制气温图表
为了可视化这些气温数据,我们首先使用matplotlib创建一个显示每日最高气温的简单图形。
import csv #从文件中获取最高气温 filename = 'sitka_weather_07-2014.csv' #存储文件变量名 with open(filename) as f: #将结果文件对象存储在f中 reader = csv.reader(f) #使用csv读取文件对象 header_row = next(reader) #使用next()获取文件第一行,运行一次next()调用一行数据 highs = [int(row[1]) for row in reader] #从文件中获取最高气温 from matplotlib import pyplot as plt #根据数据绘制图形 fig = plt.figure(dpi=128,figsize=(10,6)) plt.plot(highs,c='red') #将最高气温传递给plot,plot生成图,并设置颜色(红色为最高气温) #设置图形的格式 plt.title("Daily high july 2014",fontsize=24) #设置标题 plt.xlabel('date',fontsize=16) #设置X轴 plt.ylabel('Temperature(F)',fontsize=16) plt.tick_params(axis='both',which='major',labelsize=15) plt.show()

1.5 在图表中添加日期
提取日期和最高气温
import csv from matplotlib import pyplot as plt from datetime import datetime #从文件中获取日期和最高气温 filename = 'sitka_weather_07-2014.csv' #存储文件变量名 with open(filename) as f: #将结果文件对象存储在f中 reader = csv.reader(f) #使用csv读取文件对象 header_row = next(reader) #使用next()获取文件第一行,运行一次next()调用一行数据 #存储日期和最高气温 dates,highs = [],[] for row in reader: current_date = datetime.strptime(row[0],"%Y-%m-%d") dates.append(current_date) #获取日期 highs.append(int(row[1])) #获取最高气温 #根据数据绘制图形 fig = plt.figure(dpi=128,figsize=(10,6)) plt.plot(dates,highs,c='red') #将最高气温传递给plot,plot生成图,并设置颜色(红色为最高气温) #设置图形的格式 plt.title("Daily high july 2014",fontsize=24) #设置标题 plt.xlabel('date',fontsize=16) #设置X轴 fig.autofmt_xdate() #绘制斜的日期标签 plt.ylabel('Temperature(F)',fontsize=16) plt.tick_params(axis='both',which='major',labelsize=15) plt.show()
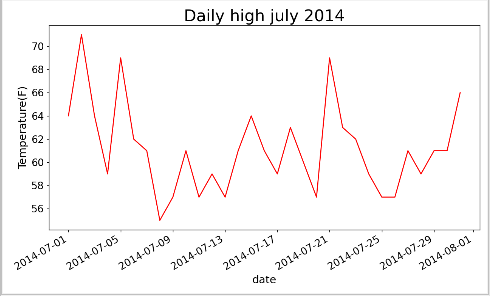
1.6 覆盖更长时间
添加更多数据,生成一副更复杂的天气图
import csv from matplotlib import pyplot as plt from datetime import datetime #从文件中获取日期和最高气温 filename = 'sitka_weather_2014.csv' #存储文件变量名 with open(filename) as f: #将结果文件对象存储在f中 reader = csv.reader(f) #使用csv读取文件对象 header_row = next(reader) #使用next()获取文件第一行,运行一次next()调用一行数据 #存储日期和最高气温 dates,highs = [],[] for row in reader: current_date = datetime.strptime(row[0],"%Y-%m-%d") dates.append(current_date) #获取日期 highs.append(int(row[1])) #获取最高气温 #根据数据绘制图形 fig = plt.figure(dpi=128,figsize=(10,6)) plt.plot(dates,highs,c='red') #将最高气温传递给plot,plot生成图,并设置颜色(红色为最高气温) #设置图形的格式 plt.title("Daily high - 2014",fontsize=24) #设置标题 plt.xlabel('date',fontsize=16) #设置X轴 fig.autofmt_xdate() #绘制斜的日期标签 plt.ylabel('Temperature(F)',fontsize=16) plt.tick_params(axis='both',which='major',labelsize=15) plt.show()
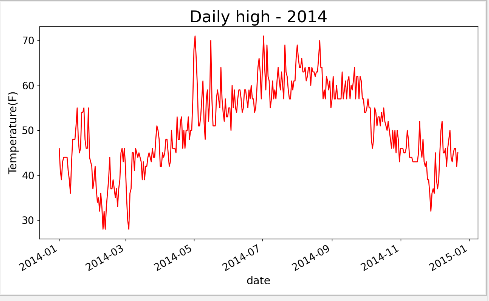
1.7 再绘制一个数据系列
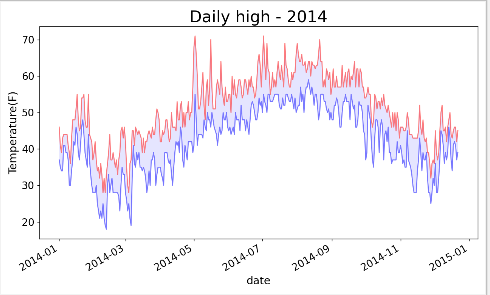
从文件中获取最低气温,并给图表区着色
import csv from matplotlib import pyplot as plt from datetime import datetime #从文件中获取日期和最高气温,最低气温 filename = 'sitka_weather_2014.csv' #存储文件变量名 with open(filename) as f: #将结果文件对象存储在f中 reader = csv.reader(f) #使用csv读取文件对象 header_row = next(reader) #使用next()获取文件第一行,运行一次next()调用一行数据 #存储日期和最高气温 dates,highs,lows = [],[],[] for row in reader: current_date = datetime.strptime(row[0],"%Y-%m-%d") dates.append(current_date) #获取日期 highs.append(int(row[1])) #获取最高气温 lows.append(int(row[3])) #获取最低气温 #根据数据绘制图形 fig = plt.figure(dpi=128,figsize=(10,6)) plt.plot(dates,highs,c='red',alpha=0.5) #将最高气温传递给plot, plt.plot(dates,lows,c='blue',alpha=0.5) #将最低气温传递给plot,alpha指定颜色的透明度 plt.fill_between(dates,highs,lows,facecolor='blue',alpha=0.1) #区域填充色 #设置图形的格式 plt.title("Daily high - 2014",fontsize=24) #设置标题 plt.xlabel('date',fontsize=16) #设置X轴 fig.autofmt_xdate() #绘制斜的日期标签 plt.ylabel('Temperature(F)',fontsize=16) plt.tick_params(axis='both',which='major',labelsize=15) plt.show()
alpha:指定颜色透明度,alpha值为0表示完全透明,1(默认值)表示完全不透明 fill_between():传递给一个x值系列,还需要传递两个y值。实参facecolor制定了填充区域的颜色
1.8 错误检查
收集的数据信息,可能会出现丢失,未能收集部分或者全部其应该收集的数据。缺失数据可能会引发异常,如果不妥善处理,可能会导致程序崩溃。
import csv from matplotlib import pyplot as plt from datetime import datetime #从文件中获取日期和最高气温,最低气温 filename = 'death_valley_2014.csv' #存储文件变量名 with open(filename) as f: #将结果文件对象存储在f中 reader = csv.reader(f) #使用csv读取文件对象 header_row = next(reader) #使用next()获取文件第一行,运行一次next()调用一行数据 #存储日期和最高气温 dates,highs,lows = [],[],[] for row in reader: #try数据正常,则运行else,去添加数据。try捕获到异常,执行except,打印错误消息后,循环将接着处理下一行数据。 try: current_date = datetime.strptime(row[0],"%Y-%m-%d") high = int(row[1]) low = int(row[3]) except ValueError: print(current_date,'missing data') else: dates.append(current_date) #获取日期 highs.append(high) #获取最高气温 lows.append(low) #获取最低气温 #根据数据绘制图形 fig = plt.figure(dpi=128,figsize=(10,6)) plt.plot(dates,highs,c='red',alpha=0.5) #将最高气温传递给plot, plt.plot(dates,lows,c='blue',alpha=0.5) #将最低气温传递给plot,alpha指定颜色的透明度 plt.fill_between(dates,highs,lows,facecolor='blue',alpha=0.1) #区域填充色 #设置图形的格式 plt.title("Daily high - 2014",fontsize=24) #设置标题 plt.xlabel('date',fontsize=16) #设置X轴 fig.autofmt_xdate() #绘制斜的日期标签 plt.ylabel('Temperature(F)',fontsize=16) plt.tick_params(axis='both',which='major',labelsize=15) plt.show() 打印: 2014-02-16 00:00:00 missing data #捕获出来的异常数据
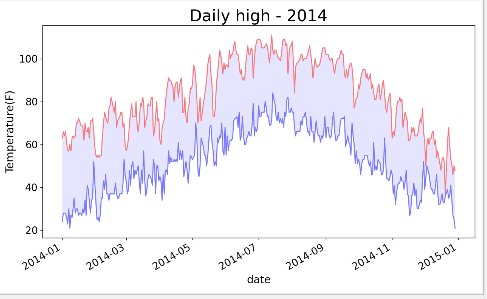
使用的很多数据集都可能缺失数据、数据格式不正确或者数据本身不正确。对于这样的情形,可以使用try-exceot-else代码来处理数据缺失的问题。有些情况下需要使用continue来跳过一些数据,或者使用remove()或del将已提取的数据删除。可采取任何管用的方法,只要能进行精确而有意义的可视化就好。
6.使用API
使用web应用编程接口(API)自动请求网站的特定信息而不是整个网页,在对这些信息进行可视化。由于这样编写的程序始终使用最新的数据来生成可视化,因此即便数据瞬息万变,它呈现出来的信息也都是最新的。
1.1 web API
web API是网站的一部分,用于与使用非常具体的URL请求特定信息的程序交互。这种请求称为API调用。请求的数据将以易于处理的格式(JSON或CSV)返回。依赖于外部数据源的大多数应用程序都依赖于API调用,如集成社交媒体网站的应用程序。
1.2 使用API调用请求数据
GitHub的API让你能够通过API调用来请求各种信息。
API样式
https://api.github.com/search/repositories?q=language:python&sort=stars { "total_count": 6740320, #GitHub中python项目个数 "incomplete_results": false, #false表示请求是成功的(并非完整的),倘若GitHub无法全面处理该API,它返回的值将为True "items": [ #包含GitHub上最受欢迎的python项目的详细信息 { "id": 83222441, "node_id": "MDEwOlJlcG9zaXRvcnk4MzIyMjQ0MQ==", "name": "system-design-primer", "full_name": "donnemartin/system-design-primer", "private": false, "owner": { "login": "donnemartin", "id": 5458997, "node_id": "MDQ6VXNlcjU0NTg5OTc=",
这个调用返回GitHub当前托管了多少个python项目,还有有关最受欢迎的python仓库信息。
api.github.com:将请求发送到GitHub网站中响应API调用的部分
search/repositories:让API搜索GitHub上所有的仓库。
? 支出我们要传递的一个实参
q:表示查询,等号让我们能够指定查询。
language:python: 指出只想获取主要语言为python的仓库信息。
&sort=stars :将项目按其获得的星级进行排序。
6.2.安装requests
requests包让程序能够轻松的向网站请求信息以及检查返回的响应。
1.1 安装requests
pip install --user requests
2 处理API响应
执行API 嗲用并处理结果,找出GITHUB上星级最高的python项目
import requests #执行API调用并存储响应 url = 'https://api.github.com/search/repositories?q=language:python&sort=stars' #API调用的URL r = requests.get(url) #使用requests.get()执行调用,将响应数据存储在r中,为JSON格式 print("status code:",r.status_code) #返回网站调用状态码(200表示响应成功) #将API响应存储在一个变量中 respnse = r.json() #将返回数据反序列化,为一个python字典类型。 print(respnse.keys()) #处理结果 结果: status code: 200 dict_keys(['total_count', 'incomplete_results', 'items']) #响应字典包含的三个键
3 处理响应字典
import requests #执行API调用并存储响应 url = 'https://api.github.com/search/repositories?q=language:python&sort=stars' #API调用的URL r = requests.get(url) #使用requests.get()执行调用,将响应数据存储在r中,为JSON格式 print("status code:",r.status_code) #返回网站调用状态码(200表示响应成功) #将API响应存储在一个变量中 respnse = r.json() #将返回数据反序列化,为一个python字典类型。 print(respnse.keys()) #处理结果 print("python项目数量:",respnse['total_count']) #打印GitHub中共包含多少个python个仓库 #探索有关仓库信息 repo_dicts = respnse['items'] print("返回的仓库数量",len(repo_dicts)) #打印GitHub返回的仓库数量 #研究第一个仓库 repo_dict = repo_dicts[0] #获取第一个仓库数据 print("\nkes:",len(repo_dict)) #键值数量 for key in sorted(repo_dict.keys()): #按字母排序打印仓库中key的名称 print(key) 结果: status code: 200 dict_keys(['total_count', 'incomplete_results', 'items']) python项目数量: 6740525 python仓库数量 30 kes: 74 archive_url archived
4.概述最受欢迎的仓库
打印API调用返回的每个仓库的特定信息。
import requests #执行API调用并存储响应 url = 'https://api.github.com/search/repositories?q=language:python&sort=stars' #API调用的URL r = requests.get(url) #使用requests.get()执行调用,将响应数据存储在r中,为JSON格式 print("status code:",r.status_code) #返回网站调用状态码(200表示响应成功) #将API响应存储在一个变量中 respnse = r.json() #将返回数据反序列化,为一个python字典类型。 print(respnse.keys()) #处理结果 print("python项目数量:",respnse['total_count']) #打印GitHub中共包含多少个python个仓库 #探索有关仓库信息 repo_dicts = respnse['items'] print("最受欢迎的仓库",len(repo_dicts)) #打印GitHub最受欢迎的仓库 print("\n概述最受欢迎的仓库") for repo in repo_dicts: print("\n名称:",repo['name']) print('所有者:',repo['owner']['login']) print('星级:',repo['stargazers_count']) print('URL:',repo['html_url']) print('描述:',repo['description'])
打印每个项目的名称,所有者,星级,在GitHub上的URL以及描述
结果
status code: 200 dict_keys(['total_count', 'incomplete_results', 'items']) python项目数量: 6740774 最受欢迎的仓库 30 概述最受欢迎的仓库 名称: system-design-primer 所有者: donnemartin 星级: 121718 URL: https://github.com/donnemartin/system-design-primer 描述: Learn how to design large-scale systems. Prep for the system design interview. Includes Anki flashcards. 名称: public-apis 所有者: public-apis 星级: 111036 URL: https://github.com/public-apis/public-apis 描述: A collective list of free APIs for use in software and web development. 名称: Python 所有者: TheAlgorithms 星级: 100179 URL: https://github.com/TheAlgorithms/Python 描述: All Algorithms implemented in Python 名称: Python-100-Days 所有者: jackfrued 星级: 99704 URL: https://github.com/jackfrued/Python-100-Days 描述: Python - 100天从新手到大师 ....
监视API的速率限制
#大多数API都存在速率限制,既你在特定时间内可执行的请求数存在限制。github限制 https://api.github.com/rate_limit //访问结果 { "resources": { "core": { "limit": 60, "remaining": 60, "reset": 1613921532, "used": 0 }, "graphql": { "limit": 0, "remaining": 0, "reset": 1613921532, "used": 0 }, "integration_manifest": { "limit": 5000, "remaining": 5000, "reset": 1613921532, "used": 0 }, "search": { #API速率限制 "limit": 10, #每分钟请求数 "remaining": 9, #剩余请求数 "reset": 1613917986, #配额将重置的Unix时间或新纪元时间 "used": 1 } }, "rate": { "limit": 60, "remaining": 60, "reset": 1613921532, "used": 0 } }
5.使用pygal可视化仓库
创建一个交互式条线图:线条的盖度表示项目获得了多少颗星。单机条形将进入项目在GitHub上的主页。
import requests import pygal from pygal.style import LightColorizedStyle as LCS ,LightenStyle as LS #执行API调用并存储响应 url = 'https://api.github.com/search/repositories?q=language:python&sort=stars' #API调用的URL r = requests.get(url) #使用requests.get()执行调用,将响应数据存储在r中,为JSON格式 print("status code:",r.status_code) #返回网站调用状态码(200表示响应成功) #将API响应存储在一个变量中 respnse = r.json() #将返回数据反序列化,为一个python字典类型。 print(respnse.keys()) #处理结果 print("python项目数量:",respnse['total_count']) #打印GitHub中共包含多少个python个仓库 #探索有关仓库信息 repo_dicts = respnse['items'] names,plot_stars = [],[] #存储项目名称及星级 for repo in repo_dicts: names.append(repo['name']) # value存放星数,label存放项目描述 plot_dict = { 'value':repo['stargazers_count'], 'label':str(repo['description']), #转换为str原因:取到的数据有一处None,chart.add无法使用空值,所以将控制转换为字符串'None',表示有值 'xlink':repo['html_url'], #pygal根据xlink相关的URL将每个条形都转换为活跃的连接。单机图标中的任何条形时,都将在浏览器中打开一个新的标签页 } plot_stars.append(plot_dict) print(plot_stars) #可视化 my_style = LS('#333366',base_style=LCS) #使用LightenStyle定义一种样式,并将其基色设置成深蓝色,传递实参base_style,以使用LightColorizedStyle类 #创建一个配置对象 my_config = pygal.Config() #创建config类,定制其属性 my_config.x_label_rotation = 45 #让标签绕X轴旋转45度 my_config.show_legend = False #隐藏图例 my_config.title_font_size = 24 #设置标题图表字体大小 my_config.label_font_size = 14 #副标题字体大小 my_config.major_label_font_size = 18 #主标签的字体大小 my_config.truncate_label = 15 #将较长的项目名称缩短为15个字符 my_config.show_y_guides = False #隐藏图标中的水平线 my_config.width = 1000 #设置自定义宽度,让图表更充分的抵用浏览器中的可用空间 chart = pygal.Bar(my_config,style=my_style) #创建条形图,通过my_config作为第一个实参,传递进去所有设置属性 chart.title = 'most-starred python projects on github' chart.x_labels = names #x轴属性名称 chart.add('',plot_stars) #标签,接收列表【星数和描述】 chart.render_to_file('D:\\python资料\\30s\\代码\\数据可视化\\API\\python_repos.svg')
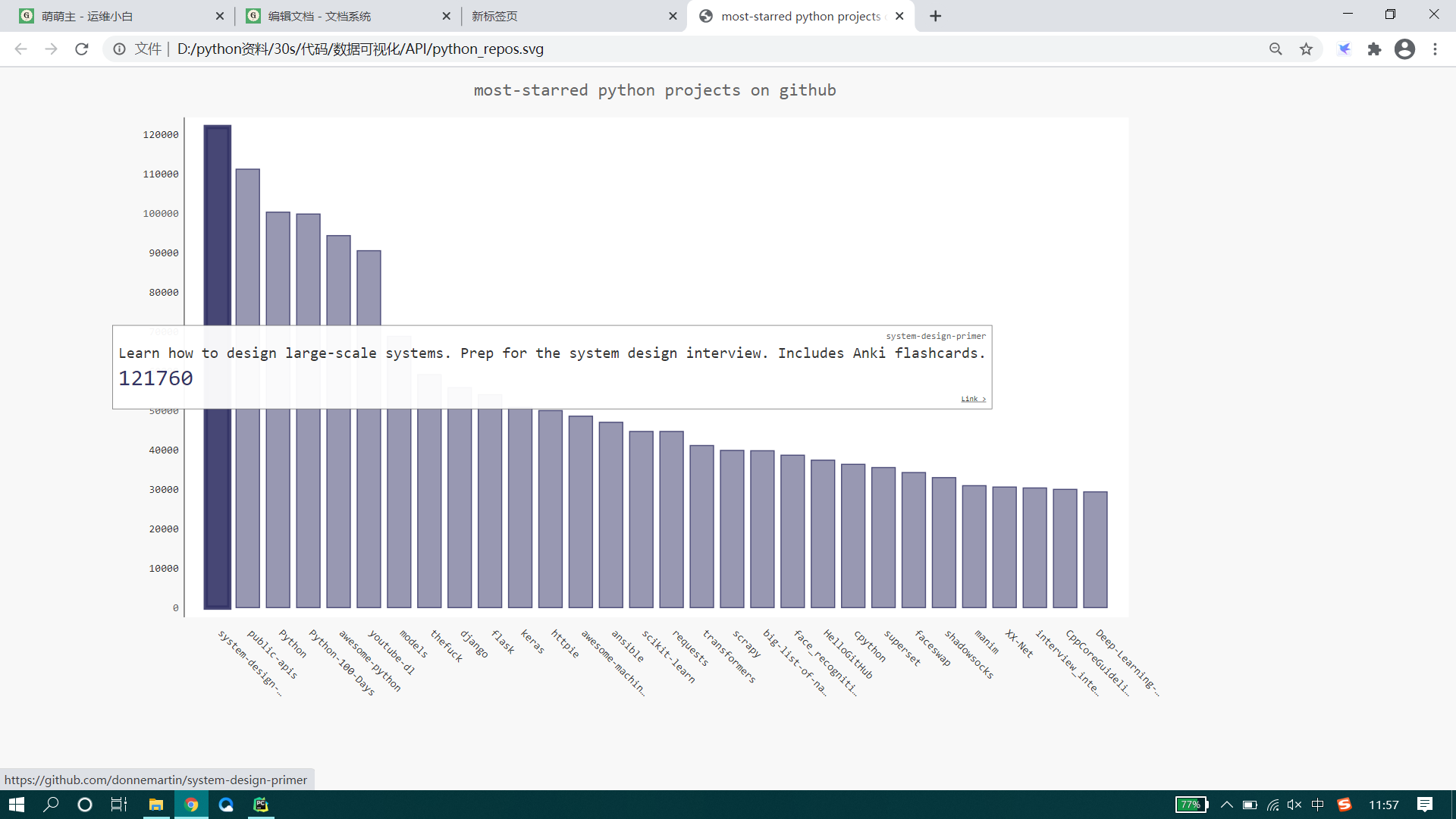
点击图标就会跳转到GitHub上相应的仓库中



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏