MegEngine 使用小技巧:Profiler使用手册
0.写在前面
“xx,R 那边反应多机训练速度慢,你看一下什么情况”
“xxx,为什么 MGE 更新之后,xxx 网络训练变慢了,你看一下”
这是组内日常对话
然后有人日常背锅
组员的状态是:提性能,提性能,还是 TMD 提性能
据不完全统计,有 80% 的性能问题其实是因为训练代码写的不够好,让 MGE 有力使不出来
包括但不限于以下情况
1)没开 fast_run
2)频繁使用 numpy 进行同步
3)没有用 make_allreduce_cb,让计算通信串行
4)。。。
次数多了,就发现这玩意太花时间了,而且每次的步骤都千篇一律,为啥一定要我来做,所以写这篇文章进行总结,方便大家也方便自己
1.Profiler 介绍
首先我们要认识 Profiler 这个东西
简单来说,Profiler 以时间轴的形式记录了所有算子的运行时间
通过 Profile 结果,我们可以很快的发现这段代码为什么跑的慢
是做了多余的工作?还是计算资源的浪费?或者是算子本身的性能很差,需要替换成别的算子
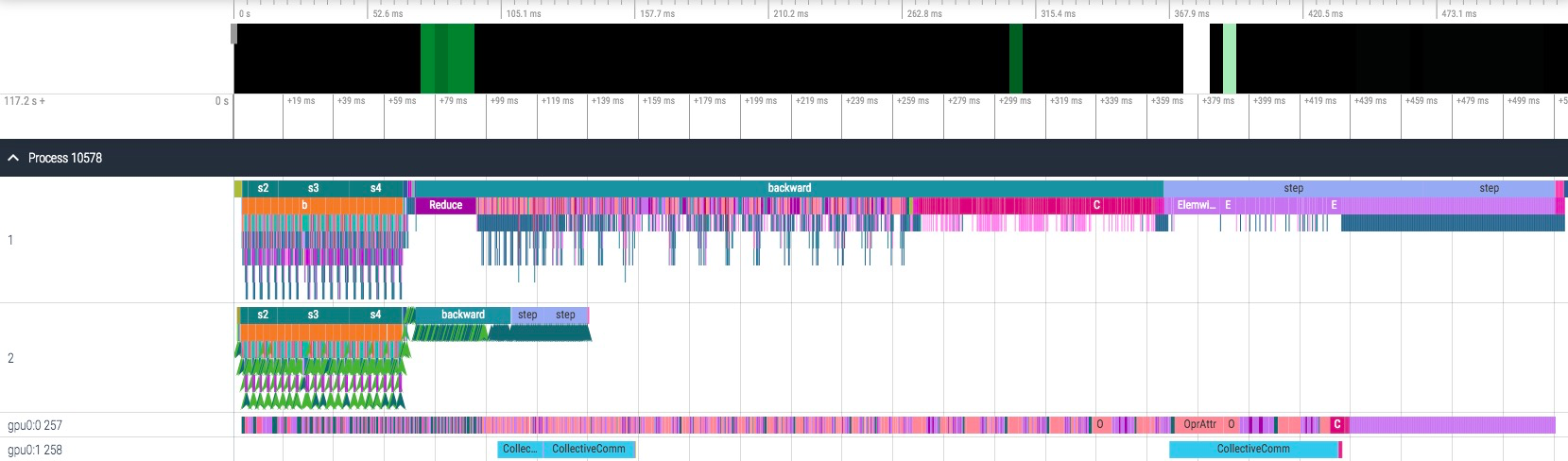
这是一个简单的 profile 结果展示
大部分情况下我们只关注 gpu thread,每一个 gpu thread 对应一个 cuda stream,上面都是运行在这个 cuda stream 上的算子
2.使用方式
PS:静态图的统计信息还不够完善(受到图优化影响),profile 结果相对动态图的不够友好
from megengine.utils.profiler import profile, Profiler
# 装饰器写法
@profile()
def train_step(data, label, *, optimizer, gm, model)
with gm:
logits = model(data)
loss = F.loss.cross_entropy(logits, label)
gm.backward(loss)
optimizer.step().clear_grad()
return loss
# with 写法
# 训练过程中最好只有一个profiler实例,因为profiler会在析构时自动dump出结果,如果有多个实例的话每个iter都会dump,非常慢
profiler = Profiler()
def train_step(data, label, *, optimizer, gm, model)
with profiler:
with gm:
logits = model(data)
loss = F.loss.cross_entropy(logits, label)
gm.backward(loss)
optimizer.step().clear_grad()
return loss
⚠️注意,profiler 默认会在析构的时候导出 profile 结果,也可以手动调用 profiler.dump 方法手动 dump
参数说明:
Profiler 的构造函数支持如下参数:
- path: profile 数据的存储路径,默认为当前路径下的 profile 文件夹.
- format: 输出数据的格式,默认为 chrome_timeline.json ,是 Chrome 支持的一种标准格式,以时间线的形式展现 profiling 结果. 可选项还有 有 memory_flow.svg ,以时间x地址空间的形式展示内存使用情况.
- formats: 若需要的输出格式不止一种,可以在 formats 参数里列出.
- sample_rate: 若该项不为零,则每隔 n 个 op 会统计一次显存信息,分析数据时可以绘制显存占用曲线,默认为 0.
- profile_device: 是否记录 gpu 耗时,默认为 True.
- with_scopes: 是否额外记录 functional/ tensor method 等 python API 对应的 scope, 默认为 False.
- with_backtrace: 是否记录 op/event 对应的 python 调用栈, 默认为 False, 开启会使记录数据文件体积变大.
scope 使用介绍
我们会自动在 module 的 forward 还有 backward 以及 step 步骤中加入 scope,scope 会在 host thread 上显示,能看出 op 属于哪一个 module 的什么阶段
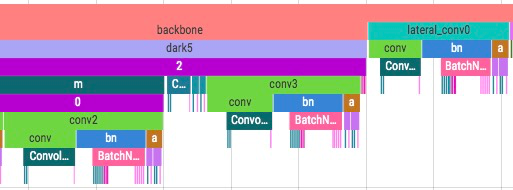
也可以自己加上 scope
from megengine.utils.profiler import Profiler, scope
def main()
with Profiler():
x = Tensor(1)
with scope("Add"):
y = x+1
with scope("Mul"):
z = x*3
默认情况下 profiler 只会记录 module forward, backward, step 三类 scope, 用户可以在构造 Profiler 对象时传入参数 with_scopes = True 额外记录 functional, tensor method 等 api 调用对应的 scope。
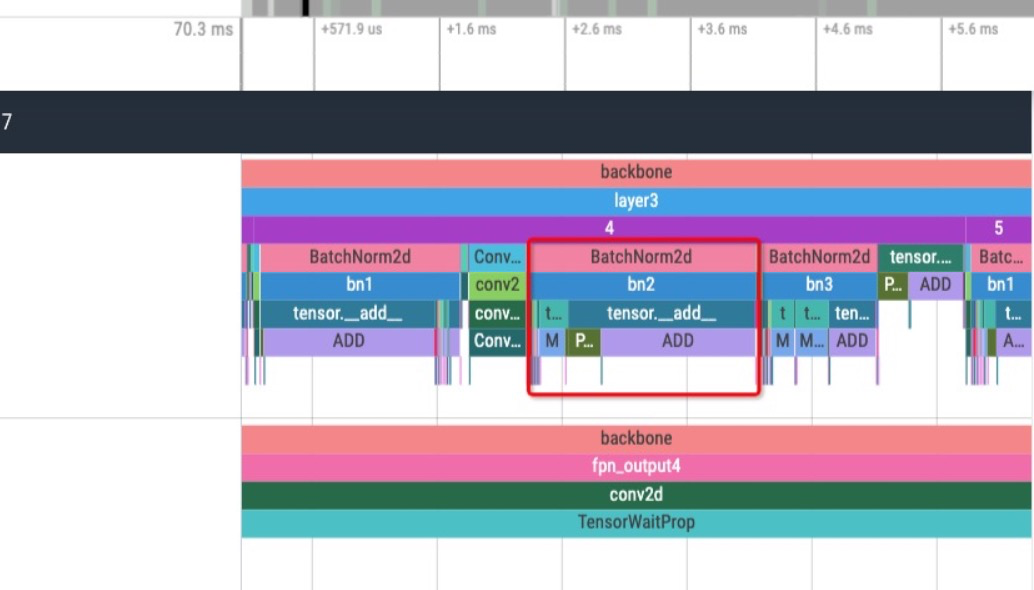
开启 with_scopes 选项后额外记录了 BatchNorm2d Module 内部调用的 functional / tensor method API 调用 scope
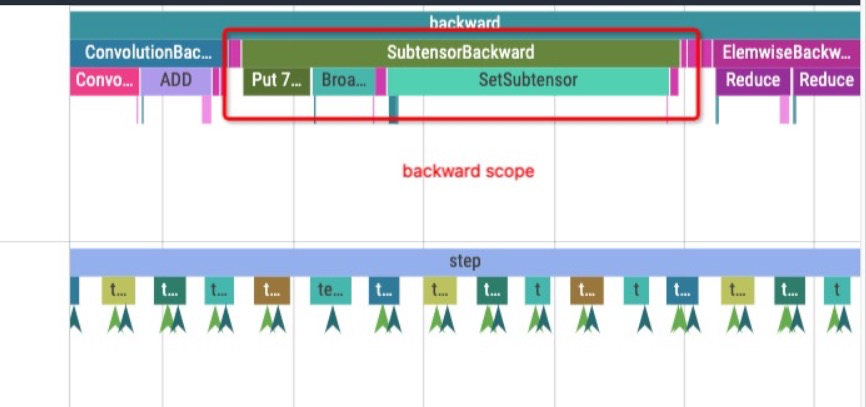
开启 with_scopes 选项后额外记录了 backward scope, 该 scope 用于记录反向计算序列对应的前向算子, 可用于查找反向计算中有性能问题的算子是由哪种算子前向计算产生。下图 scope 表示 Broadcast, SetSubtensor 等算子是由 Subtensor 反向计算产生的。
3.可视化显示
推荐使用 perfetto 查看 profile 结果,也可以用 Chrome 开发者模式(F12)的 Performance 模块查看 timeline 格式文件,也可以用 chrome://tracing/ 进行查看
以下介绍的都是基于 perfetto 的操作方式
1)统计
可以选中一段连续的时间段,查看这一个时间段的统计结果
下方会显示事件统计结果,可以看到事件实际占用时间(Wall duration)(可以结合总时间算出空闲时间),可以按照总占用时间排序,也可以按照平均时间排序

2)依赖关系
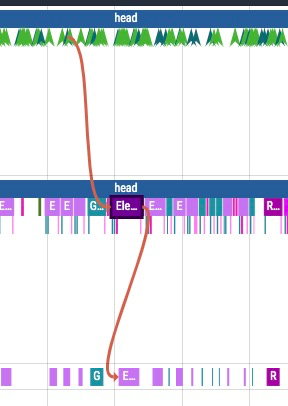
在 host thread上,op 会记录对应的 input和output 以及相应的依赖关系,可以依据箭头找到 input 依赖的上一个 op,也可以通过下方 flow event 点击移动到上一个或者下一个


我们还能找到 op 对应的 host 时间和 gpu 时间,点击 op 可以看到在不同 thread(cpu,gpu)占用的时间
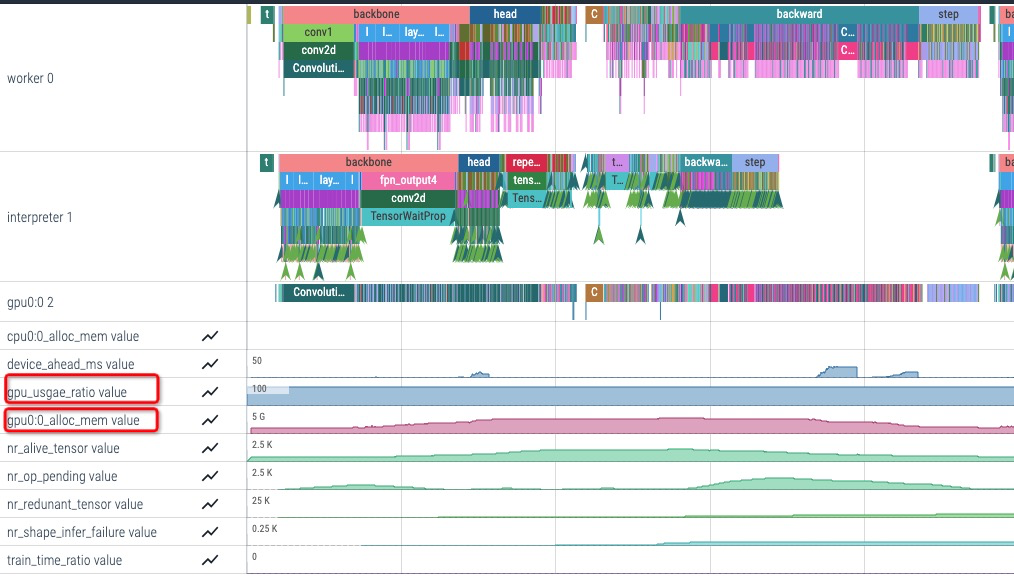
3)查看显存使用, gpu 利用率等指标
profiler 除了记录时间算子执行时间外,还会记录一些与显存和性能相关的指标。gpu_usage_ratio 记录程序执行平均的 gpu 利用率(gpu 执行 kernel 时间占总时间的比例),gpu_usage_ratio 低说明程序 host 侧是瓶颈 。gpux:x alloc_mem_value 记录了gpux 显存使用量随时间的变化的曲线, 需要把 sample_rate 设置为大于 0 的整数(sampe rate 代表每隔 n 个 op 记录一次显存使用量)
4)放大缩小
可以拖动上方时间轴的起始和结束点来修改起始点和结束点,也可以通过放大缩小手势进行放大缩小
中间竖线上面的灰色小方块就是可以拖动的点


4.常见调试技巧(附使用例子
1)多余计算
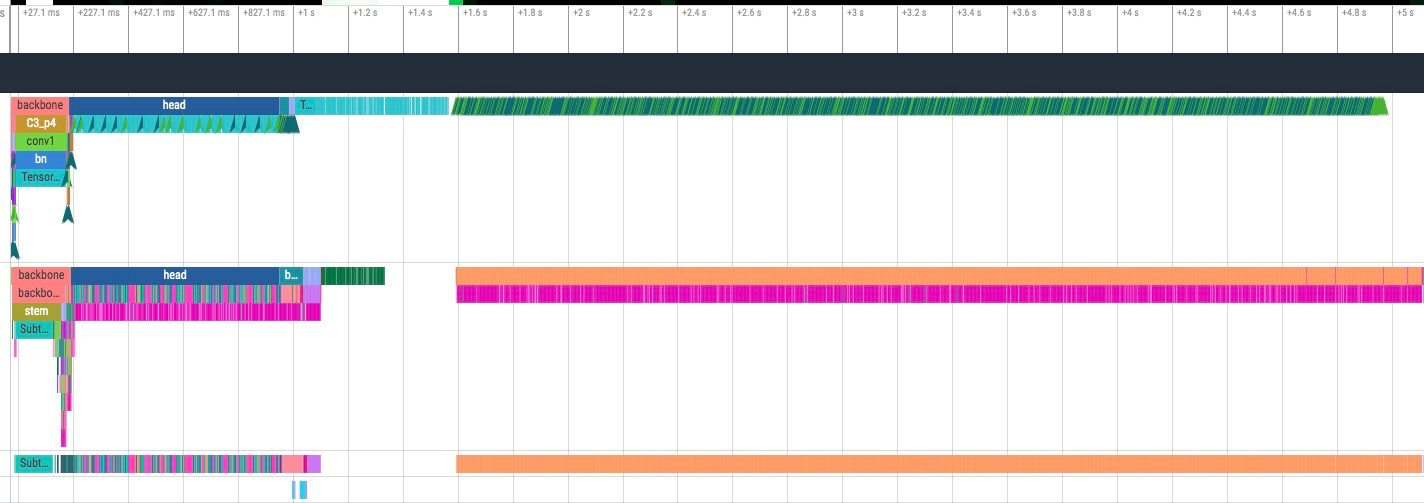
yolox 例子,forward,backward,step 运行完成了,但是后面多出了很多的 reshape 操作(一般认为 reshape 无实际计算,所以基本看作是浪费
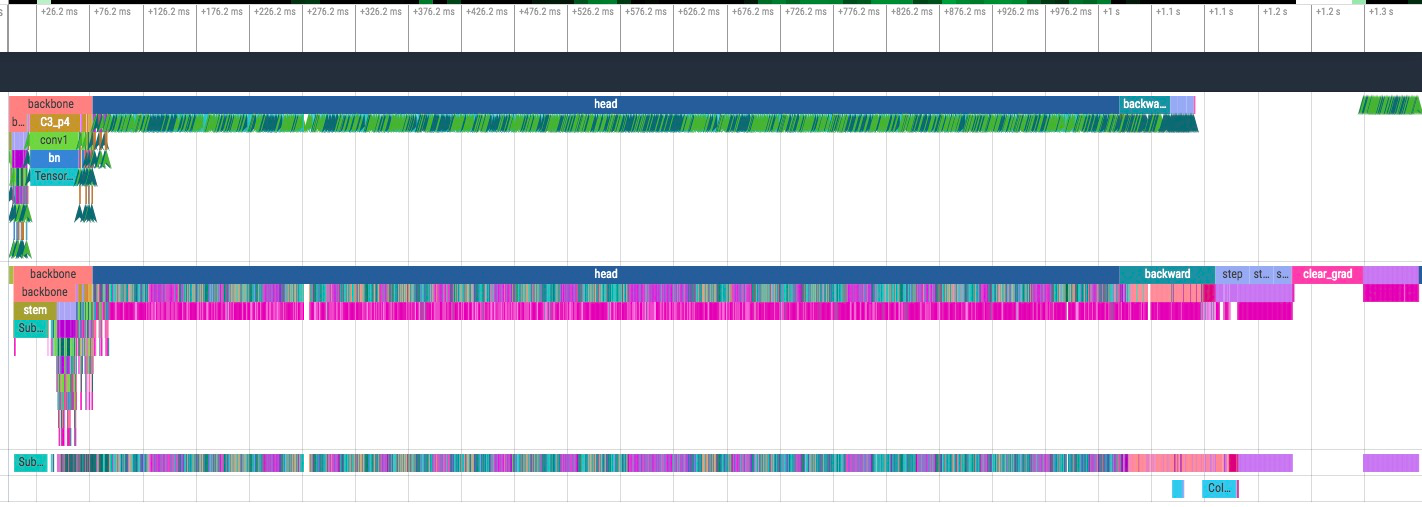
找到原因后结果如下(5s->1.3s)
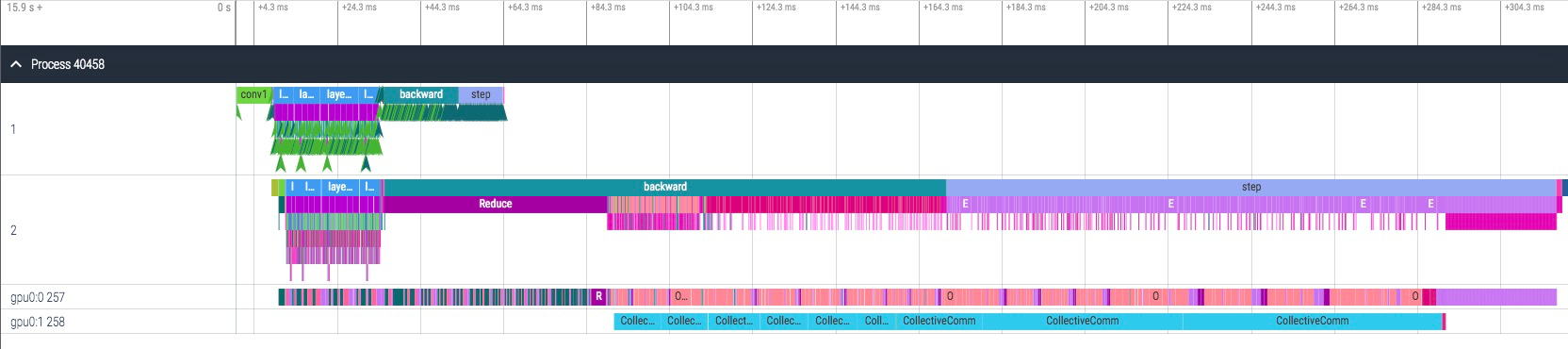
2)计算通信串行(请认准 make_allreduce_cb)
allreduce 通信在 gpu0:1,如果发现通信在 gpu0:0 那就是用错了
3)host 性能慢,gpu 利用率不高
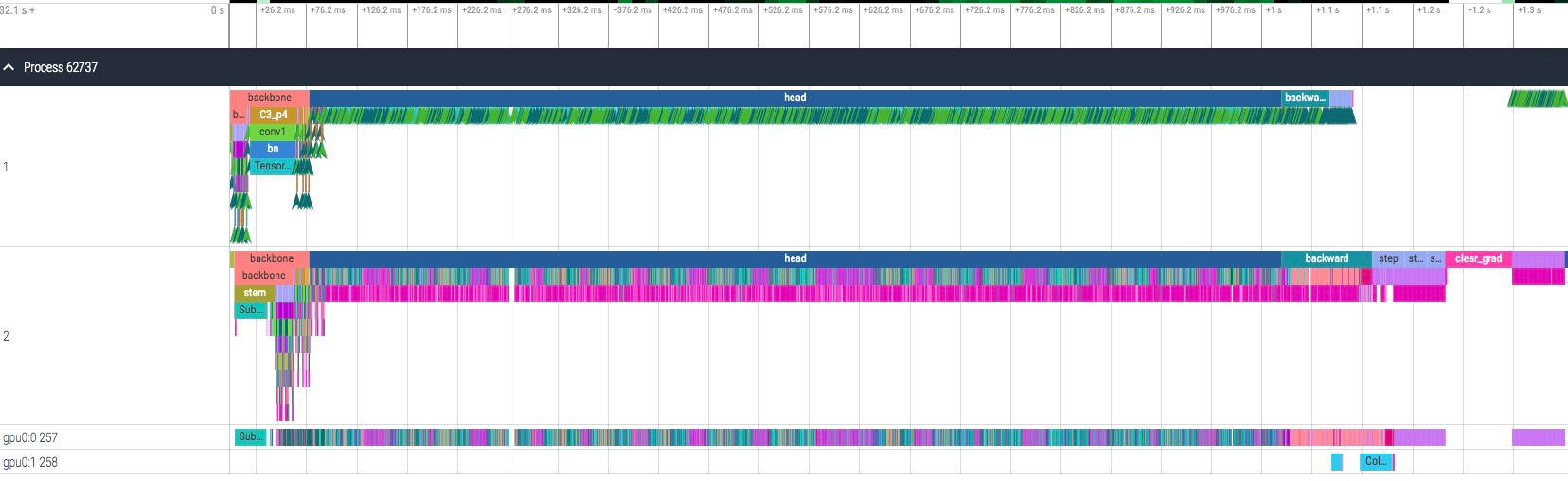
cpu 时间和 gpu 时间基本上一致,很可疑
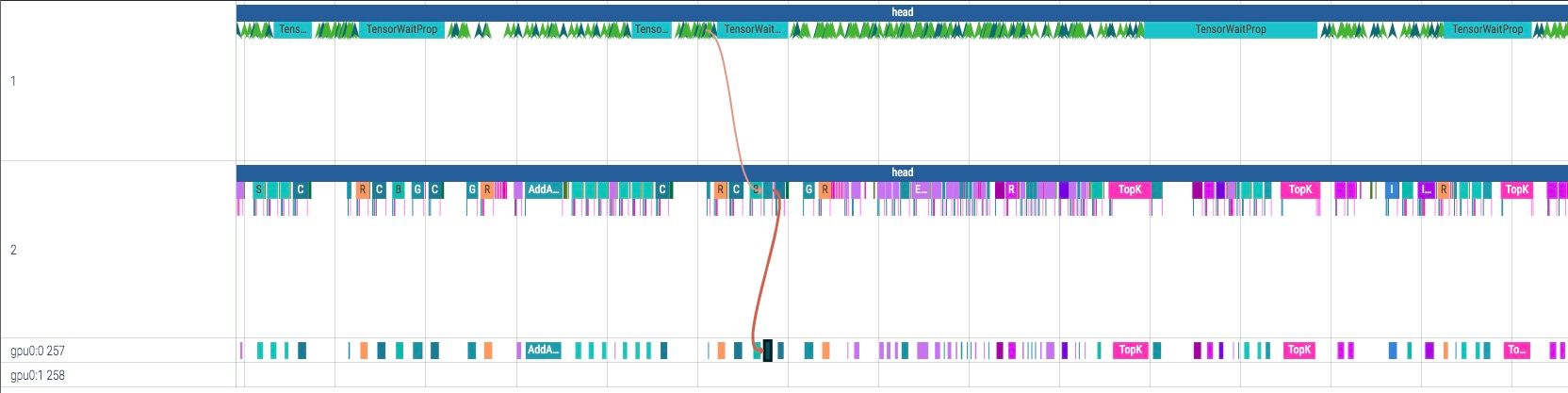
放大仔细看,gpu 运行时间中有很多空隙,而且点击对应 op 查看依赖关系,可以看出中间的空隙时间是在等待 host 进行 launch cuda kernel
4)使用 backtrace 记录功能查找性能瓶颈部分对应源码
上述示例介绍了如何从 profile 结果中发现性能异常的部分, profiler 提供了 backtrace 调用栈记录功能, 方便用户找到异常部分对应的训练代码源码。backtrace 记录会记录算子的 dispatch/kernel 执行,TensorWaitProperty 等事件对应的 python 调用栈。
可以在构造 Profiler 对象时通过传入 with_backtrace = True 开启调用栈记录功能。 开启该选项后 profiler 保存数据文件体积会增大。
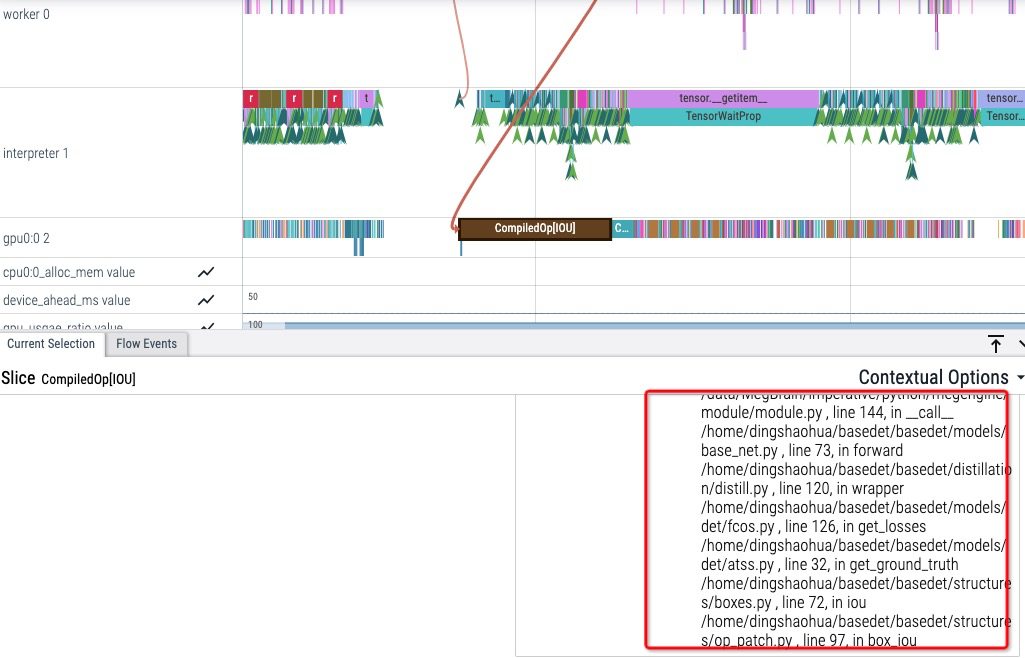
用户可以在 perfetto UI 界面上点击 op 查看其对应的源码。
下图 profiler 结果中 CompiledOp[IOU] 算子执行时间较长, 通过记录的 backtrace 可以发现该算子是检测模型计算 loss 部分调用的。
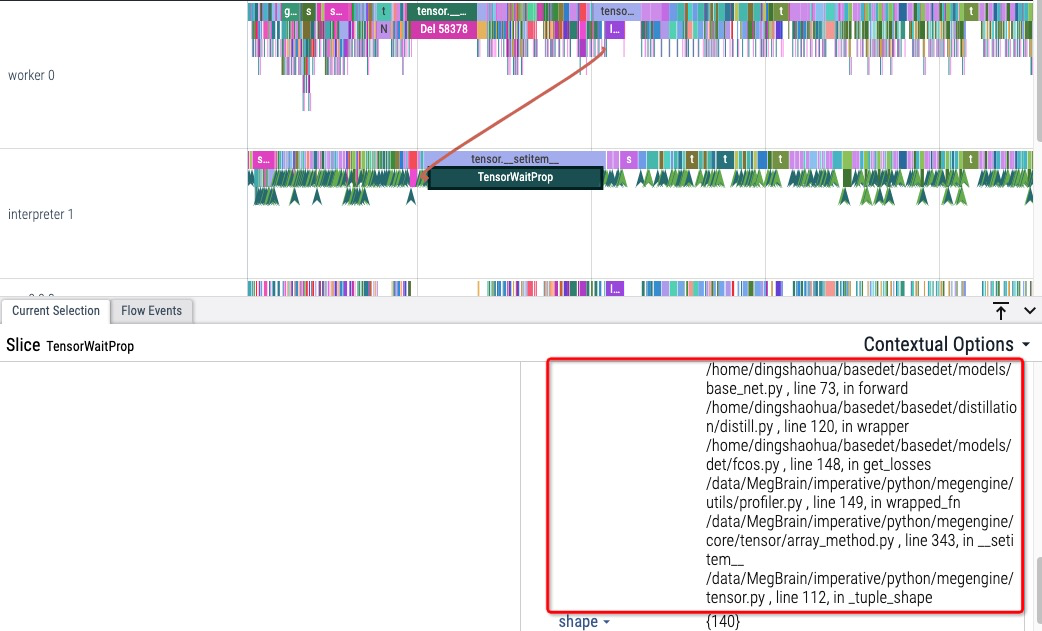
下图中 interpreter 线程中某个 TensorWaitProp 占用时间很长,可能会拖慢 host 执行速度,导致 gpu 空闲。
(TensorWaitProp 可能是由 tensor.shape, tensor.numpy() 等方法调用产生的, 会让 host 侧等待 device 执行,以获取 Tensor 的 value 或 shape 属性)
通过调用栈可以发现该事件是由 basedet 检测模型 get_ground_truth 方法中的某个 getitem 产生的 ( __getitem__中使用了 tensor shape 属性触发了 host 侧的 sync)。
附
更多 MegEngine 信息获取,您可以:查看文档和 GitHub 项目,或加入 MegEngine 用户交流 QQ 群:1029741705。欢迎参与 MegEngine 社区贡献,成为 Awesome MegEngineer,荣誉证书、定制礼品享不停。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号