
全局图优化:提升 MegEngine 模型推理性能的又一神器
作者:陈思旭 | 旷视 MegEngine 架构师
3 分钟快速上手
效果对比
对深度学习框架来讲,模型的推理性能是用户关注的重要指标。其中一个高度影响性能的因素是 Tensor 的 Layout Format(例如 NCHW、NHWC等等),如何正确选择 Layout Format 将会高度影响最终的推理性能。
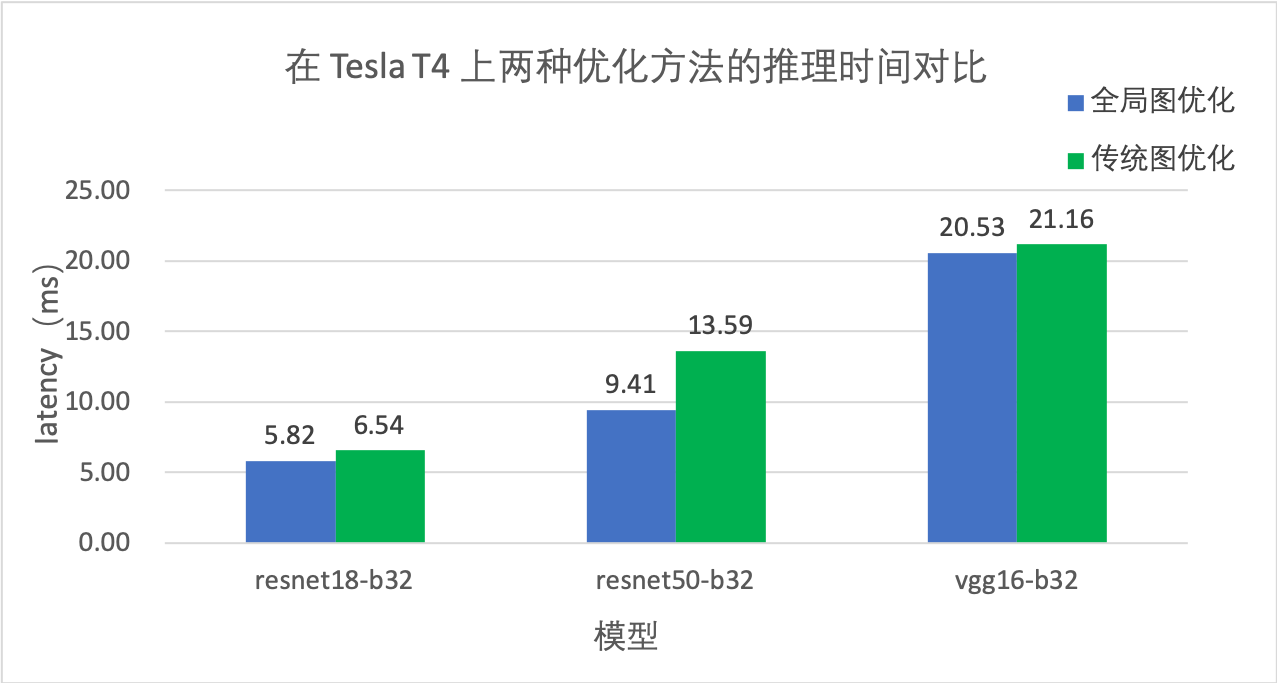
MegEngine 参考了阿里巴巴工程师陈元凯提出的 GPU 推理中的数据格式全局优化算法,并进一步扩展到 CPU,提供了一种从整体上优化 Tensor Format 选择,提升模型整体推理性能的方案 —— 全局图优化。在 int8 模型上,经过全局图优化和 MegEngine 原 Format 优化方法(以下称为传统图优化)的推理时间表现对比如下图:
使用方法
源代码级别使用全局图优化可以参照 MegEngine 自带的可执行程序 load_and_run 中的用法,如果只关注利用 load_and_run 测试模型性能,需要使用的参数有:
--layout-transform [cuda|cpu]:为计算图开启全局图优化,并指定优化的目标设备。--layout-transform-dump dump_path:指定全局图优化后的计算图存储的文件路径。
开启全局图优化的同时也可以开启其他的优化选项如 Fast Run 等等。使用方法如下:
load_and_run model.mge --layout-transform cuda --layout-transform-dump model_opt.mge
load_and_run model_opt.mge
对底层技术原理解析感兴趣的同学,欢迎继续往下读~~ 😄
全局图优化解决的问题
在神经网络中,Tensor 通常是多维数组,而计算机的数据存储只能是线性的,因此有许多不同的数据存储格式可以将 Tensor 存储在计算机内存中。通常 Tensor 都是以 NCHW 的数据格式(Format)存储的,W 是什么数字都有可能,但硬件的体系结构设计往往希望数据能更整齐一些(比如4对齐或32对齐)才能更充分的发挥设备的计算性能,因此许多高性能计算库都采用了不同的 Format 来实现算子。
MegEngine 支持多种主流深度学习推理平台,包括 CUDA,ARM,X86 等等,不同平台的架构存在巨大的差异,因此在通常情况下 NCHW Format 都不能达到最优的访存性能。为了解决这一问题,MegEngine 提供了多种 Format 的算子实现,各 Format 的特性见用户指南。不同平台上适用的 Format 不同,如在 NVDIA 的 GPU 设备上,可以使用 NCHW4,NCHW32,CHWN4 等等。
常见的思路是:让用户指定要使用的 Format,依靠传统图优化,将计算图中所有运算(如卷积)的 Input Tensor 都统一转换为用户指定的 Format(这一过程称作 Layout 转换)。
有哪些 layout 适合当前平台,选哪个 layout 性能更优往往没什么有效的决策方法。除此之外,传统图优化可能会带来多次 Layout 转换,这会引入很多额外的内存重排的开销,而用户在选择 Format 时并不会考虑这些额外开销。总的来讲,目前传统图优化面临如下问题:
- 性能问题:用户无法确定哪种 Format 的性能更好,可能存在负优化。
- 局部性问题:没有考虑额外引入的 Layout 转换开销。
- 扩展性问题:每添加一种 Format,就需要添加一种 Layout 转换方法。
为了解决上述传统图优化存在的问题,MegEngine 引入了全局图优化,在选择 Format 时充分考虑 Layout 转换引入的额外开销,自动选择最合适的 Format,做到让用户对 Format 不感知。
全局图优化原理
全局图优化的本质是解决计算图中 Tensor Format 选择问题,为计算图中的算子(Operator)选择各自合适的 Layout,从而使整张计算图推理性能达到最优,它的核心是一个动态规划算法。
流程
全局图优化的整体流程如下:

- 从计算图中提取特定算子构成的连通子图,全局图优化作用在连通子图上。
- 特定算子包括 Convolution 类算子,Elemwise 类算子,CV 类算子,Pooling 算子。
- 收集子图中的算子在各 Layout 下的性能数据,以及不同 Layout 之间转换的开销数据,利用以上数据构造 Layout 选择问题。
- 以上数据都是通过在目标设备上实际执行算子获得的。
- 求解 Layout 选择问题,求得子图中各算子应选择的 Layout。
- 替换子图中的各算子 Layout 为上一步求得的 Layout,将子图接入到计算图中。
全局图优化策略的重点就在如何求解 Layout 选择问题,这部分采用了基于动态规划的全局图优化算法,下面是算法介绍。
算法
在介绍全局图优化算法前先简单说明两个概念:
- \(\text{Op}\):计算节点。一个算子就是一个计算节点。
- \(\text{Var}\):数据节点。\(\text{Op}\) 的输入、输出 Tensor。
下图表示拓扑排序后计算图的一部分,它由多个 \(\text{Op}\) 构成,\(\text{Op}\) 之间通过 \(\text{Var}\) 相连,连接两个 \(\text{Op}\) 的 \(\text{Var}\) 既是上一个 \(\text{Op}\) 的输出,又是下一个 \(\text{Op}\) 的输入,例如图中 \(\text{Var}_2\) 既是 \(\text{Op}_1\) 的输出,又是 \(\text{Op}_3\) 的输入。
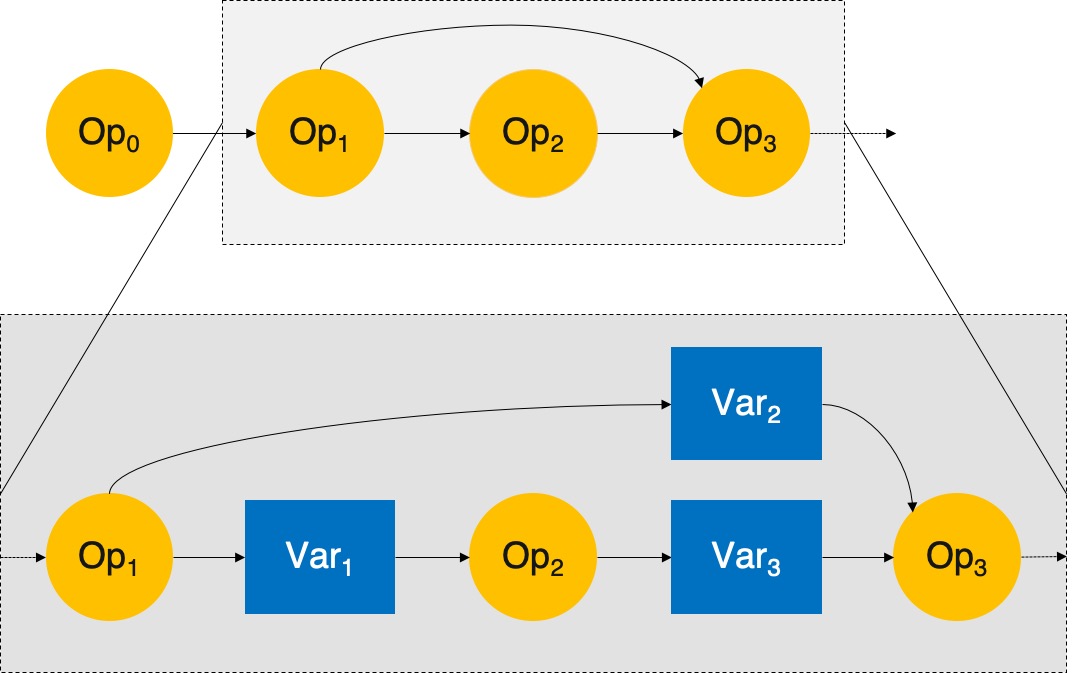
全局图优化算法要求得的解是连通子图达到最优性能时子图中每个 \(\text{Op}\) 应选择的 Layout。为了方便介绍算法我们约定以下符号的含义:
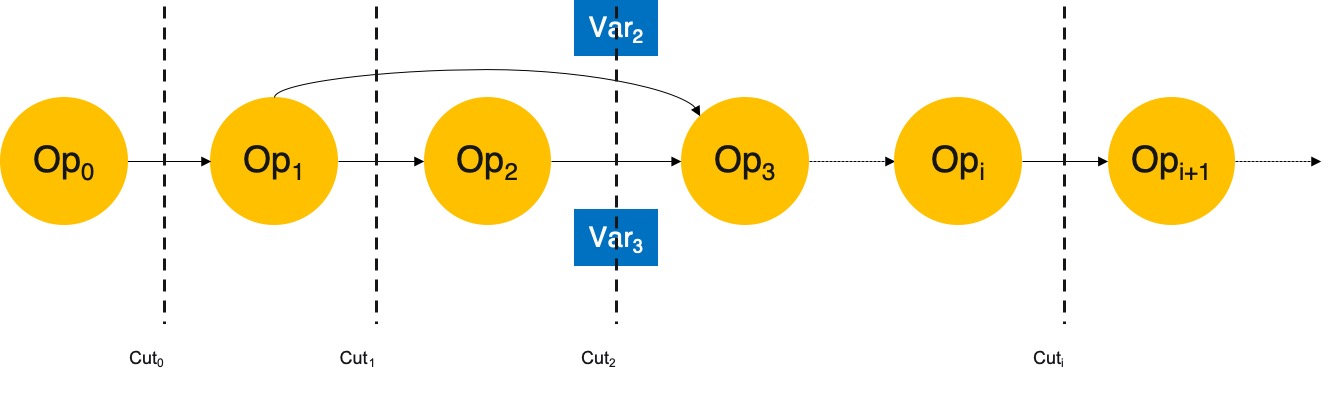
- \(\text{Cut}_n\):在 \(\text{Op}_n\) 和 \(\text{Op}_{n+1}\) 之间将计算图划分成左、右两部分,两部分通过一些 \(\text{Var}\) 相连。
- 如下图,\(\text{Cut}_2\) 有两个输出,分别为 \(\text{Var}_2\) 和 \(\text{Var}_3\),\(\text{Cut}_2\) 的左、右两部分即通过这两个 \(\text{Var}\) 相连。
- \(\text{State}_n^k\):表示连接 \(\text{Cut}_n\) 两部分的 \(\text{Var}\) 所处的状态为 \(\text{k}\)。
- 如 \(\text{Var}_2\) 和 \(\text{Var}_3\) 的 Format 分别为 \(\text{f}_1\) 和 \(\text{f}_2\),\((\text{f}_1,\text{f}_2)\) 就是 \(\text{Cut}_2\) 的其中一种状态。
- 假设连接 \(\text{Cut}_n\) 两部分的 \(\text{Var}\) 数为 \(\text{N}\),每个 \(\text{Var}\) 有 \(\text{M}\) 种 Format,则 \(\text{Cut}_n\) 的状态总数为 \(\text{M}^N\)。
- \(\text{O}_k^n\):表示 \(\text{Op}_n\) 在 \(\text{State}_{n-1}^k\) 下的耗时。
- \(\text{V}_{s->k}^n\):表示 \(\text{Cut}_n\) 从 \(\text{State}_n^s\) 转换到 \(\text{State}_n^k\) 的耗时。即连接 \(\text{Cut}_n\) 两部分的所有 \(\text{Var}\) 从状态 \(\text{s}\) 转换为状态 \(\text{k}\) 的耗时。
- \(\text{T}_k^n\):\(\text{Cut}_n\) 在 \(\text{State}_n^k\) 下的最短耗时。
- 可以理解为在指定 \(\text{Op}_n\) 输出 \(\text{Var}\) 状态为 \(\text{k}\) 的情况下 \(\text{Cut}_n\) 的最短耗时。
- \(\text{T}_n\):表示 \(\text{Cut}_n\) 的最短耗时。即 \(\text{Cut}_n\) 在所有 \(\text{State}\) 下最短耗时中的最小值。
-
\[\text{T}_n = \min_{\text{all state k}}(\text{T}_k^n) \]
-
在全局图优化流程第二步中已经收集到了连通子图中各 \(\text{Op}\) 在各 Layout 下的性能数据 \(\text{O}_k^n\),以及 \(\text{Var}\) Layout 转换的开销数据 \(\text{V}_{s->k}^n\)。那么接下来开始推导状态转移方程。
在 \(\text{Cut}_0\) 处,由于 \(\text{Op}_0\) 为第一个 \(\text{Op}\),因此 \(\text{T}_k^0\) 等于 \(\text{Op}_0\) 在 \(\text{State}^k\) 下的耗时。
-
\[\text{T}_k^0 = \text{O}_k^0 \]
-
\[\text{T}_0 = \min_{\text{all state k}}(\text{T}_k^0) \]
在 \(\text{Cut}_1\) 处,\(\text{T}_k^1\) 应该等于 \(\text{Cut}_0\) 的最短耗时 \(\text{T}_0\) 加 \(\text{Op}_1\) 在 \(\text{State}_0^k\) 下的耗时 \(\text{O}_k^1\),除此之外还要加上 \(\text{Op}_0\) 和 \(\text{Op}_1\) 处于不同 \(\text{State}\) 时 \(\text{Cut}_0\) 的 \(\text{State}\) 转换耗时 \(\text{V}_{s->k}^0\)。
-
\[\text{T}_k^1 = \min_{\text{all state s}}(\text{T}_s^0+\text{V}_{s\to k}^0)+\text{O}_k^1 \]
-
\[\text{T}_1 = \min_{\text{all state k}}(\text{T}_k^1) \]
延伸到 \(\text{Cut}_{i+1}\),可以得到状态转移方程:
-
\[\text{T}_k^{i+1} = \min_{\text{all state s}}(\text{T}_s^i+\text{V}_{s\to k}^i)+\text{O}_k^{i+1} \]
\(\text{Cut}_{i+1}\) 的最短耗时:
-
\[\text{T}_{i+1} = \min_{\text{all state k}}(\text{T}_k^{i+1}) \]
已知 \(\text{T}_k^0\),\(\text{V}_{s\to k}^i\),\(\text{O}_k^i\),假设一共有 \(\text{n}\) 个 \(\text{Cut}\)。根据以上方程,首先求得全局最优解 \(\text{Cut}_n\) 的最短耗时 \(\text{T}_n\),从而可以确定使 \(\text{T}_n\) 达到最小值的 \(\text{State}\) x,此时可以确定 \(\text{Op}_n\) 应选择的 Layout。接下来根据状态转移方程确定使 \(\text{T}_x^n\) 达到最小值的 \(\text{State}\) y,此时可以确定 \(\text{Op}_{n-1}\) 应选择的 Layout,依此类推。可以根据状态转移方程从最后一个 \(\text{Cut}\) 往前回溯,从而确定每个 \(\text{Op}\) 应选择的 Layout。至此问题得到解决。
假设有 \(\text{K}\) 个 \(\text{Cut}\),连接 \(\text{Cut}\) 两部分的最大 \(\text{Var}\) 数为 \(\text{N}\),每个 \(\text{Var}\) 有 \(\text{M}\) 种 Format,那么算法复杂度为 \(\text{O}(\text{KM}^N)\)。如果模型比较复杂 \(\text{N}\) 很大,\(\text{State}\) 数 \(\text{M}^N\) 呈指数增长,会导致算法运行时间非常长。因此为了降低算法复杂度,对 \(\text{State}\) 进行了剪枝。
剪枝
假设 \(\text{Cut}_n\) 由 \(\text{m}\) 个 \(\text{Var}\) 相连 \((v_1,v_2,...,v_m)\),\(\text{Cut}_n\) 从 \(\text{State}_n^i\) 转到 \(\text{State}_n^j\) 的代价记做 \(\text{Distance(i, j)}\)。
-
\[\text{Distance(i, j)} = \sum_{k=1}^m \text{V}_{i\to j}(v_k) \]
\(\text{T}_i^n\) 表示 \(\text{Cut}_n\) 处于 \(\text{State}_n^i\) 的最短耗时,当 \(\text{T}_i^n\) < \(\text{T}_j^n\) 时,如果 \(\text{T}_i^n\) 加 \(\text{Cut}_n\) 从 \(\text{State}_n^i\) 转到 \(\text{State}_n^j\) 的耗时仍然比 \(\text{T}_j^n\) 短,那么可以认为 \(\text{State}_n^j\) 是没有用的,可以将 \(\text{State}_n^j\) 剪枝掉。由此可以得出剪枝的原则:
-
\[\text{Distance(i, j)} < \text{T}_j^n - \text{T}_i^n \]
工程实践
通过全局图优化算法可以解决传统图优化存在的性能问题和局部性问题,但是上面提到的传统图优化的扩展性问题似乎并没有得到解决。因此全局图优化策略中除了实现算法以外还做了一些额外的工作。
数据格式转换器
由于 MegEngine 提供了众多的 Format,如 NCHW、NHWC、NCHW4、CHWN4等等。假设有 \(\text{N}\) 种 Format,那么理论上就应该维护 \(\text{O}(\text{N}^2)\) 个 Layout 转换算法,这样的成本是不可接受的。
考虑到 Layout 转换都可以通过 MegEngine 基础算子 reshape 和 transpose 拼接而成,因此我们设计了数据格式转换器利用 reshape 和 transpose 完成所有的 Layout 转换工作。下面是一个通过 reshape 和 transpose 算子完成 Layout 转换的例子。
为方便描述约定 Layout 表示格式,如 NCHW4 是在 Channel 维度进行了 Channel / 4 的拆分,表示为 (N, C//4, H, W, C%4)。
例:假设新增 NCHW16,如何将 NCHW4 转换为 NCHW16 呢?
- layout0 = (N, C//4, H, W, C%4)
- layout1 = (N, C//16, H, W, C%16)
- reshape 对 layout0 切分 C 维度:(N, C//4//4, C//4%4, H, W, C%4)
- transpose 调整维度位置:(N, C//4//4, H, W, C//4%4, C%4)
- reshape 合并最后两个维度:(N, C//16, H, W, C%16) = layout1
有了数据格式转换器当增加新的 Format 时无需再手写对应的 Layout 转换算法,传统图优化存在的扩展性问题在全局图优化中也得到了解决。
总结
从性能角度讲,全局图优化相比传统图优化能够带来更大的收益。由于 MegEngine 支持 int8 的 Format 较多,因此在 int8 模型上的加速效果尤为显著。
使用全局图优化的前提要求是需要有能真实设备进行 profiling 才能做出正确决策,因此在这一点上还不能够完美的替代掉传统图优化。当能够满足这个条件时,全局图优化的使用方法更轻松也性能更优,是一个更好的选择。
附:
GitHub:MegEngine 天元 (欢迎 star~
Gitee:MegEngine/MegEngine
欢迎加入 MegEngine 技术交流 QQ 群:1029741705

 浙公网安备 33010602011771号
浙公网安备 33010602011771号