
MegEngine 端上训练:让 AI 懂你,更能保护你
作者:Lenny | 旷视科技 MegEngine intern
刷购物 App 频频被“种草”、指纹识别一次比一次稳准快、美颜相机 get 你的喜好一键 P 图……
在智能手机上,利用 AI 算法进行个性化推荐能大幅度提升用户的体验。然而,想让 AI 更懂你,很多应用都需要将用户数据进行模型训练,饭馆推荐背后是推荐系统、指纹识别是利用过往数据自动优化模型、聪明的美颜相机背后是对用户行为的分析。
在这种情况下,如何让 AI 算法更精准地理解用户喜好又能保证用户数据安全呢?一个直观的想法就是直接在手机上进行模型训练,这样既避免了数据传输可能带来的泄露风险,又能不断提升模型性能。MegEngine 既可以在 GPU 上进行训练,又可以在移动设备上进行推理,那两者结合一下,是不是可以在移动设备上进行训练呢?答案是肯定的。
那么接下来,就来看一下如何在 MegEngine 里面进行端上训练吧~
仍然是老规矩,拿 Mnist 数据集来进行试手,模型选用 LeNet。在我们的内部测试中,调用端上训练接口的代码可以直接在手机上运行,并且效果和通用的 Python 训练接口完全对齐。
回顾在 Pytorch、Tensorflow 等框架建立训练流程时候做的事情,我们可以发现主要包括:
- 搭建模型;
- 添加 Loss 与 Optimizer;
- 导入数据集;
- 设置学习率、训练轮数等超参数并训练。
搭建模型
模型的搭建其实是构造前向计算图的一个过程,通过调用算子,获取与输入相对应的输出。
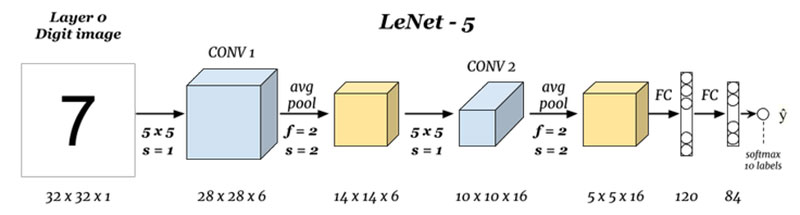
从 LeNet 的模型结构容易得知,我们需要调用 2 次卷积算子,2 次池化算子,1 次 Flatten 算子,2 次矩阵乘算子,以及若干次四则运算的算子。
在 MegEngine 中,算子只是负责执行运算的一个“黑盒子”,我们需要提前设置好参数,然后将参数与数据一起“喂”给算子。如下图所示,数据永远是逐层进行传递的,且其 Layout 会被自动计算,而参数则需要我们手动进行设置。

对于 LeNet 这种前馈神经网络,我们只需要将前面算子的输出与下一组参数链接到下一个算子,就可以将计算过程连接起来。
由于此处代码比较冗长,这里给出一个简化版的代码示例。可以看出,其实和调用通用的 Python 接口写法差别不大,甚至是一一对应的,比如opr::Convolution对应nn.Conv2d, opr::MatrixMul对应nn.Linear,只是由于 C++ 语言特性和 Python 不同,所以写起来会有一些差异。
SymbolVar symbol_input =
opr::Host2DeviceCopy::make(*graph, m_input); // 初始化输入数据
SymbolVar symbol_conv =
opr::Convolution::make(symbol_input, symbol_conv_weight, conv_param); // symbol_weighs[0] 即我们提前设置好的卷积 filter 权重
symbol_conv = opr::relu(symbol_conv + symbol_conv_bias); //加偏置之后激活
SymbolVar symbol_maxpool =
opr::Pooling::make(symbol_conv, pooling_param)
.reshape({batchsize, fc_shape[0]}); //池化之后进行展平
SymbolVar symbol_fc =
opr::MatrixMul::make(symbol_maxpool, symbol_fc_weight) +
symbol_fc_bias;
symbol_fc1= opr::relu(symbol_fc); //通过矩阵乘运算构造全连接层
通过这种方式,我们即可以将算子、数据与参数进行组合,构建出我们需要的前向计算图。
调用 Loss 与 Optimizer
现在 MegEngine 中已经在 C++层面对 Loss 和 Optimizer 进行了封装,下面我们以 Mnist 数据集训练中的交叉熵损失以及 SGD 优化器为例讲解。
在 MegEngine 中,一切推理与训练实际上都是在一张计算图上进行,而 Loss 与 Optimizer 本质上不过是将构造计算图的一部分任务封装了起来以供用户直接调用,而无需重复“造轮子”。例如,我们最熟悉的均方误差中,实际上是调用一次减法算子之后再调用一次乘方算子。
明白了这一点之后,我们只需要继续上一步,在我们的模型输出后面调用 Loss 的 API 并进行拼接就可以,代码非常简单,和 Pytorch 中训练十分相似。
CrossEntopyLoss loss_func; // 先定义一个损失函数的实例,这里选取交叉熵损失
SymbolVar symbol_loss = loss_func(symbol_fc, symbol_label); // 将模型输出与标签作为输入,调用损失函数
这时,我们得到的symbol_loss就是我们训练过程中的损失。
与调用 Loss API 类似,我们也可以很轻松地调用优化器插入到已有计算图中。
SGD optimizer = SGD(0.01f, 5e-4f, .9f); //实例化 SGD 优化器并设置参数
SymbolVarArray symbol_updates =
optimizer.make_multiple(symbol_weights, symbol_grads, graph); // 将 Optimizer 插入到计算图中
这样一来,在反向传播之后,梯度就会被 Optimizer 进行处理并更新模型参数。
导入数据集
既然模型参数是我们手动定义,那肯定会注意到一个问题就是我们的数据集怎么转化成参与计算图计算的数据呢?
这个当然 MegEngine 已经准备好了办法,可以通过继承一个接口并实现其中的get_item与size方法,并将这个类的实例输入到 DataLoader 中,那么就可以完成数据集的转换啦~
我们要继承的接口定义如下。咦,这里平时用 Pytorch 的小伙伴肯定已经闻到了熟悉的味道。
class IDataView {
public:
virtual DataPair get_item(int idx) = 0;
virtual size_t size() = 0;
virtual ~IDataView() = default;
};
话不多说直接上一个示例,这里只示意如何继承接口并得到 DataLoader,如果有兴趣看具体实现的小伙伴可以去关注 MegEngine~
class MnistDataset : public IDataView {
public:
MnistDataset(std::string dir_name); // 初始化数据集,指定数据集存放路径
void load_data(Mode mode, std::string dir_name); //读取 Mnist 数据集,存到 dataset 列表中。
DataPair get_item(int idx); // 实现接口
size_t size(); //实现接口
protected:
std::vector<DataPair> dataset;
};
// 实例化上面定义的数据集类
auto train_dataset = std::make_shared<MnistDataset>(dataset_dir);
// 用这个实例来获取对应的 DataLoader
auto train_dataloader =
DataLoader(train_dataset, batchsize);
训练
既然完成了各个步骤,那么接下来的事情就是让训练跑起来~这里也是给出简单的伪代码示例。唔……这里使用 Pytorch 的小伙伴看了也会感到非常熟悉,也就是循环每个 epoch,每个 epoch 中又循环每组数据与标签,不同的是在这里我们不需要在循环中调用 Loss 与 Optimizer,因为前面已经构造好了完整的计算图,这里只需要执行我们编译后的计算图即可。
func = graph->compile(); // 编译计算图
for (int epoch = 0; epoch < epochs; epoch++) {
for (size_t i = 0; i < train_dataloader.size(); i++) {
data = train_dataloader.next(); // 从 DataLoader 中获取数据
func->execute(); // 执行计算图
}
}
通过我的以身试法 (x),发现在端上训练可以达到用 Pytorch 以及 MegEngine 的 Python 训练接口训练的相同准确率~到这里我们的验证即获成功!
看到这里,相信你已经了解了如何在 MegEngine 中进行端上训练了,那么 Loss 和 Optimizer 又到底是什么样的接口呢?
Loss 与 Optimizer 的封装
有的时候,我们会遇到需要封装自己需要的 Loss 和 Optimizer 的情况,这时候了解 Loss 和 Optimizer 的 API 就显得比较重要。
Loss 的接口十分简单,可以归结为如下所示:
class ILoss {
public:
virtual mgb::SymbolVar operator()(mgb::SymbolVar symbol_pred,
mgb::SymbolVar symol_label) = 0;
virtual ~ILoss() = default;
};
只要输入预测值和标签值两个计算节点,能对应输出一个计算节点即可,这里细心的小伙伴可能已经注意到 SymbolVar 就是前面构建前向计算图的时候用到的类,这也是为什么说 Loss 的本质就是帮助你在计算图中插入一段计算过程。
Optimizer 的接口也很简明,可以归结为下面的代码:
class IOptimizer {
public:
virtual mgb::SymbolVarArray make_multiple(
mgb::SymbolVarArray symbol_weights,
mgb::SymbolVarArray symbol_grads,
std::shared_ptr<mgb::cg::ComputingGraph> graph) = 0;
virtual mgb::SymbolVar make(
mgb::SymbolVar symbol_weight, mgb::SymbolVar symbol_grad,
std::shared_ptr<mgb::cg::ComputingGraph> graph) = 0;
virtual ~IOptimizer() = default;
};
class Optimizer : public IOptimizer {
public:
mgb::SymbolVarArray make_multiple(
mgb::SymbolVarArray symbol_weights,
mgb::SymbolVarArray symbol_grads,
std::shared_ptr<mgb::cg::ComputingGraph> graph); // 注意这里并不是纯虚函数
virtual mgb::SymbolVar make(
mgb::SymbolVar symbol_weight, mgb::SymbolVar symbol_grad,
std::shared_ptr<mgb::cg::ComputingGraph> graph) = 0;
virtual ~Optimizer() = default;
};
与 Loss 类似,这里我们也是输入计算节点,然后对应输出一个计算节点。值得注意的是 Optimizer 分为了两部分,一部分是纯粹的接口IOptimizer,另一部分是继承了这个接口的抽象类Optimizer。事实上,由于很多情况下,我们习惯于用一个数组或列表来存放我们的参数与得到的梯度,这时候由于静态语言的限制,不能直接将这种情况归并到单一输入的情况中,但是实际上只要我们实现了Make接口,输入是数组的情况也自然会得到解决。但是考虑到接口与类应当进行分离的理念,这里进行了抽离,变成了一个接口、一个抽象类,且抽象类中包含了对数组输入的情况 (make_multiple接口)的默认实现。
倘若需要添加一个自定义的 Loss 或 Optimizer,只需要继承相应的接口或抽象类并实现即可。
例如对均方误差 MSE 的实现:
mgb::SymbolVar MSELoss::operator()(
mgb::SymbolVar symbol_pred, mgb::SymbolVar symol_label) {
return opr::pow(symbol_pred - symol_label, symbol_pred.make_scalar(2));
}
总结与展望
看到这里,也许你会充满好奇,也许你会一脸嫌弃……
端上训练作为一个尚在探索中的方向,现在的确和已有的训练、推理框架没法比较,但 MegEngine 提供端上训练的功能会在你需要的时候为你提供一种选择。在这样一个手机越来越占据人们生活的时代,以及人们对服务质量的需求不断提高的时代,想必端上训练会有用武之地。
当前 MegEngine 端上训练的主要问题与下一步可能的改进点有:
- 模型的构建过程当前比较原始,可以进一步的封装出类似
nn.module的模块。 - 有时候手里已经有了带有计算图信息的某个权重文件,不希望再次搭建计算图,而是直接读取现有的计算图并插入训练过程,可以提供类似的 API
- 在 C++ 侧进行数据的读取会比较麻烦
欢迎大家来尝试使用 MegEngine 搭建端上训练应用,也欢迎大家能指出当前 MegEngine 中端上训练存在的不足以便我们改进,也可以来提 PR 一起解决问题~
MegEngine cpp Training Example
GitHub:旷视天元 MegEngine
欢迎加入 MegEngine 技术交流 QQ 群:1029741705

 浙公网安备 33010602011771号
浙公网安备 33010602011771号