深入理解混合精度训练:从 Tensor Core 到 CUDA 编程
作者:陈振寰 | 旷视科技 MegEngine 架构师
背景
近年来,自动混合精度(Auto Mixed-Precision,AMP)技术在各大深度学习训练框架中作为一种使用简单、代价低廉、效果显著的训练加速手段,被越来越广泛地应用到算法研究中。然而大部分关于混合精度训练的文章一般停留在框架接口介绍、如何避免 FP16 类型带来的精度损失以及如何避免出现 NaN 等基础原理和使用技巧方面,对于将深度学习框架视为黑盒工具的研究员来说确实足够了,但是如果想要再往下多走一步,了解一点更底层的加速细节,那么 GPU 显卡架构、CUDA 编程里的一个个专业名词就很容易让缺乏背景知识的人摸不着头脑。
本文会以混合精度训练背后涉及的 Tensor Core 为起点,结合代码实例,帮助读者对框架层面使用 Tensor Core 进行训练加速的细节乃至 CUDA 编程有一些基本的认识。
Tensor Core 原理
首先还是简单介绍一下 混合精度 和 Tensor Core 是什么。混合精度是指在底层硬件算子层面,使用半精度(FP16)作为输入和输出,使用全精度(FP32)进行中间结果计算从而不损失过多精度的技术,而不是网络层面既有 FP16 又有 FP32。这个底层硬件层面其实指的就是 Tensor Core,所以 GPU 上有 Tensor Core 是使用混合精度训练加速的必要条件。
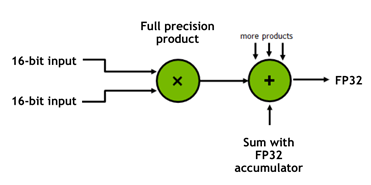
图 1
Tensor Core 直译为张量核心,其物理含义是 NVIDIA GPU 上一块特殊的区域(如图 2 中大块深绿色部分所示),与其地位类似的有普通的 CUDA Core(浅绿色和小块深绿色部分)以及最新的 RT Core(Ray Tracing,光追核心,浅黄色部分)。CUDA Core 一般包含多个数据类型,每个数据类型包含多个小核心,比如图中的 INT32 Core 和 FP32 Core 就各有 4×16 个,在计算专用卡上还可能会包含 FP64 Core(比如 V100 和 A100 显卡),而 Tensor Core 在架构图和接口上则没有具体的区分,可以视作 GPU 上一块较为独立的计算单元(虽然实际内部有一定的区分)。
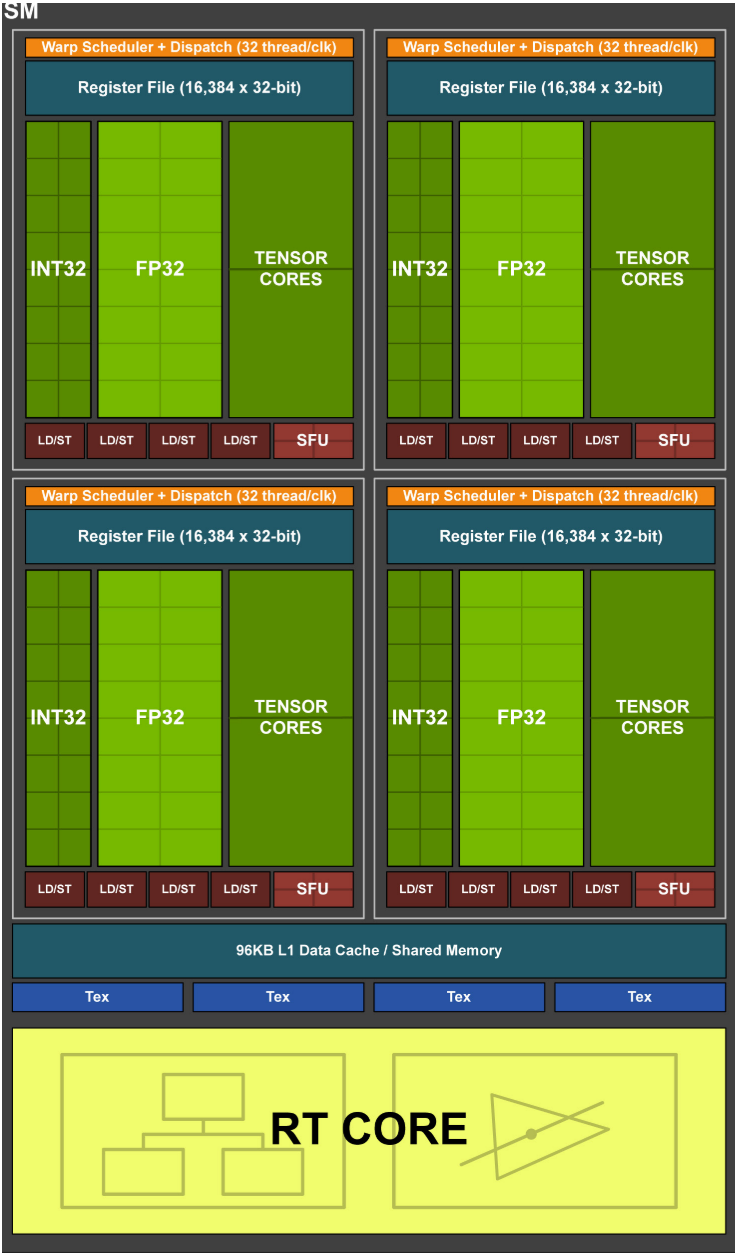
图 2:Turing 架构 2080Ti 显卡的 SM 图 1
而在逻辑(数学)含义上,相比于 FP32 Core 一次只能对两个数字进行计算(如图 3 中两张图的左侧部分),Tensor Core 能一次对两个 4×4 的 FP16 Tensor 进行矩阵乘计算并累加到另一个 4×4 的 Tensor 上,即 D = A * B + C(如图 3 中两张图的右侧部分),这也是其取名为 Tensor Core 的原因。通过硬件上的特殊设计,Tensor Core 理论上可以实现 8 倍于 FP32 Core 的计算吞吐量(Volta 和 Turing 架构),并且没有明显的占用面积和功耗增加。混合精度也是利用 Tensor Core 的这一特性,才能够实现训练加速。
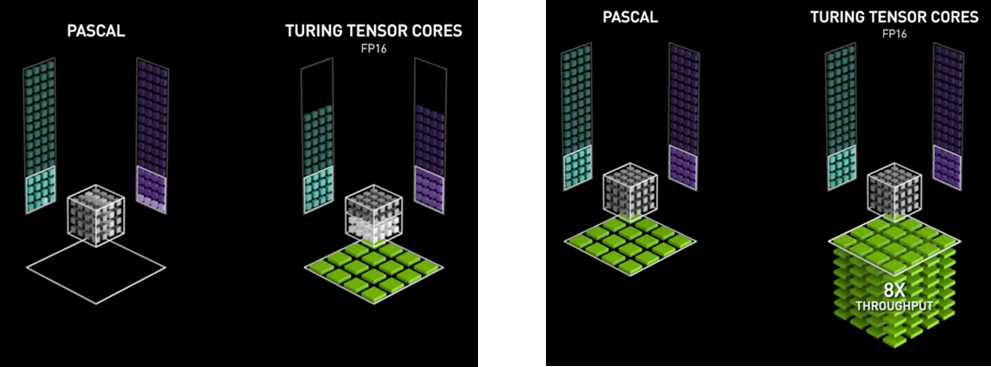
图 3
这里的 8 倍是基于 SM(Streaming Multiprocessor)进行比较的,SM 是 GPU 进行完整计算任务的基本单元,一个 GPU 内一般包含若干 SM(比如 V100 包含 80 个 SM,A100 包含 128 个 SM),而一个 SM 内会包含各种计算核心以及存储资源(图 2 就是一个完整的 SM)。
在 V100 上,一个 SM 包含 8 个 Tensor Core 和 64 个 FP32 Core。一个 Tensor Core 一个时钟周期内能进行 4×4×4=64 次 FMA(Fused-Multiply-Add,乘加计算),总计 64×8/clock,而 FP32 Core 则是 1×64/clock,故而为 8 倍。而在 A100 上,Tensor Core 的单个吞吐能力是上一代的 4 倍,一个时钟周期能进行 256 次 FMA,在总个数减少为 4 个(占用面积更大)的情况下,总吞吐量相比 V100 提升为 2 倍,是 FP32 Core 的 16 倍。
从 CUDA 接口层面理解
前面介绍了 TensorCore 的物理含义和逻辑含义,但是还是有点抽象,所谓 “Talk is cheap. Show me the code.” 接下来就让我们从代码接口层面了解一下 Tensor Core 的含义与作用,从而理解混合精度训练的底层加速原理。
要利用 Tensor Core 进行计算,需要使用 NVIDIA 提供的 CUDA Runtime API。既然在 Volta 架构中引入了 Tensor Core,那必然会有新的 CUDA 接口暴露出来。在 CUDA 9.0 中,引入了新的 WMMA(warp-level matrix multiply and accumulate)API,作用就是使用 Tensor Core 进行矩阵运算,与本文相关的主要是以下三个接口:
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false);
这里的 fragment 可以简单理解为一个矩阵或 Tensor,三个接口的作用是通过 load_matrix_sync 将数据指针 mptr 里的数据加载到 fragment 中,再用 mma_sync 对四个 fragment 进行计算(d = a * b + c),最后通过 store_matrix_sync 将输出 fragment 的数据返回到输出指针 mptr 里。一个最简单的对两个 16×16 矩阵进行乘法并累加的例子如下所示2:
#include <mma.h>
using namespace nvcuda;
__global__ void wmma_ker(half *a, half *b, float *c) {
// Declare the fragments
wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::col_major> a_frag;
wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> b_frag;
wmma::fragment<wmma::accumulator, 16, 16, 16, float> c_frag;
// Initialize the output to zero
wmma::fill_fragment(c_frag, 0.0f);
// Load the inputs
wmma::load_matrix_sync(a_frag, a, 16);
wmma::load_matrix_sync(b_frag, b, 16);
// Perform the matrix multiplication
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
// Store the output
wmma::store_matrix_sync(c, c_frag, 16, wmma::mem_row_major);
}
但是到这里其实累积了一些问题,包括 warp 是什么意思?说好的 Tensor Core 接收 4×4 矩阵进行乘加,到这里为什么变成了 16×16?其实这都涉及到 GPU 进行并行计算的方式。
我们都知道 GPU 有非常多核心,比如一个 SM 里就有 64 个 FP32 Core。在管理这些核心时,为了提升效率,会将其进行分组,若干个核心在行为上进行绑定,执行一样的命令,共同进退,而这样的一个分组就称为一个 warp(与 thread 相对应,都是纺织中概念的延伸 3)。在 CUDA 层面要得到一个多线程同步的结果必须以 warp 为单位,这也是上面三个函数都以"_sync"结尾的原因。
在硬件上其实也可以找到这种分组的迹象,比如我们再看上面 Turing SM 的结构(图 2),可以发现其分为了四个一样的部分(如下图 4),称作 Sub-Core,其中橙色的部分叫作 “Warp Scheduler”,其作用就是给 warp 分配任务。
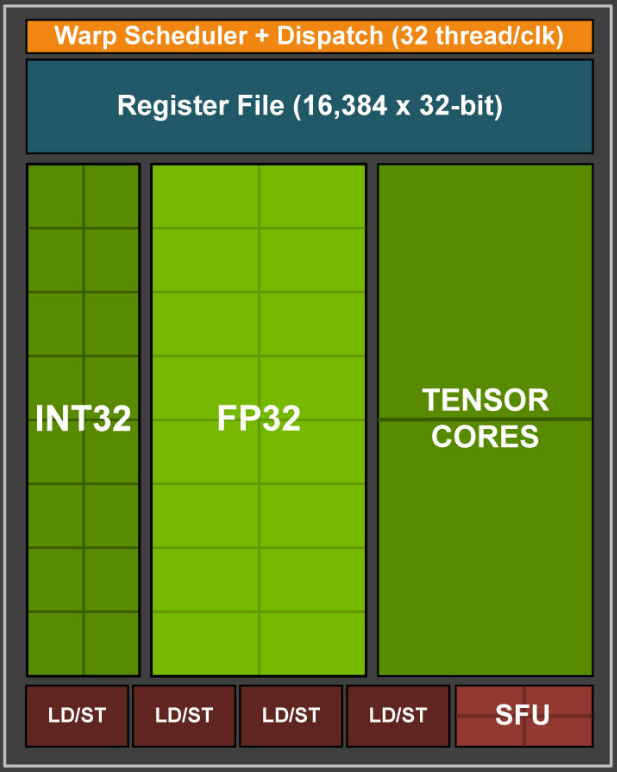
图 4:Turing 架构 SM 的 一个 Sub-Core
而分配任务一个时钟周期只能进行一次,为了尽量让各个部分都能一直运转,这个任务一般需要多个时钟周期执行(类似流水线并行)。在目前的 GPU 设计中,一个 warp scheduler 对应 32 个线程,可以理解为一个任务包含 32 个子任务,而每个 Sub-Core 只有 16 个 FP32 Core,所以需要两个时钟周期才能分配一次。
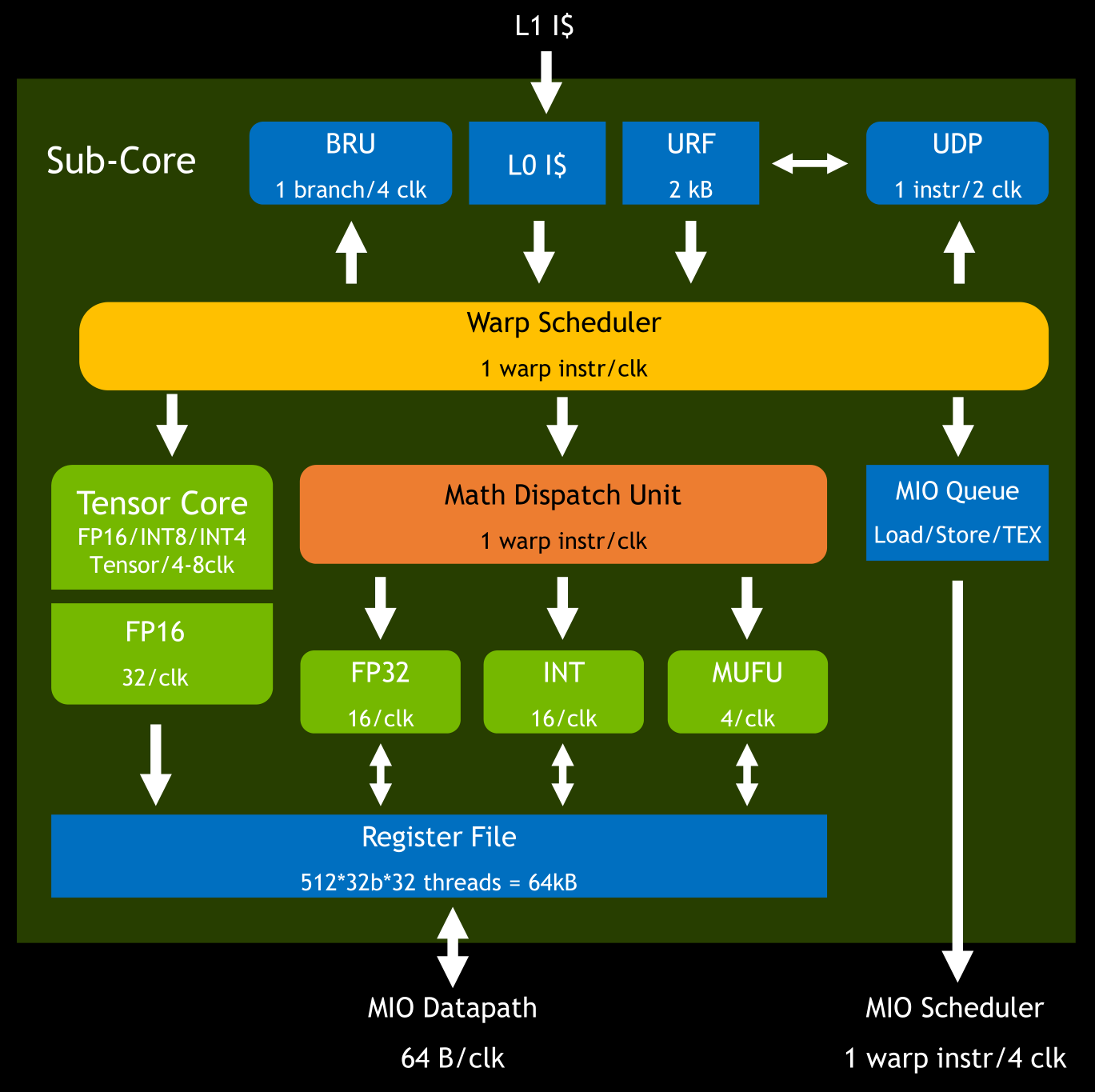
图 5 Turing 架构 Sub-Core 里的指令流程4
对应到 Tensor Core 上算 FP16 的矩阵乘加,如果是 Volta 架构,一次会算 8×4 和 4×8 两个矩阵的乘法和对应矩阵的累加(缩写为 m8n8k4),需要 4 个时钟周期才能分配一次,均摊下来一个时钟周期恰好是两个 4×4 矩阵的乘加,与宣称的 TensorCore 性能一致。而实际上在 CUDA Runtime API 里,为了使指令 overlap 更高,提升并行效率,把这个 m8n8k4 提升为了最少 m16n16k16,这也就是为何 wmma::mma_sync 以 16×16 为最小单元了。
事实上 CUDA 里进行矩阵计算,往往都是把大的矩阵切分成一个个固定大小的分块(tiling)进行计算,这其实也是接口的输入叫 fragment (每个线程的 fragment 负责 tiling 的一部分)而非 Tensor 的一个原因。
总结下来就是 CUDA 通过 wmma 接口以 warp 为单位每 4 个时钟周期向 Tensor Core 提交 m8n8k4 矩阵乘法的运算请求,待其执行完成后把 8×8 的结果进行返回,整个运算的过程都是基于 warp 层面的,即 warp-level。
到这里我们通过 wmma CUDA API 了解了 Tensor Core 的代码含义,以及管中窥豹挖掘了一下硬件底层执行的流程,其中的用语和描述为了方便理解也许不是特别准确,不过相信能帮助大家对 GPU 如何执行并行计算有一个简单的认识。
从框架使用层面进行理解
实际在框架层面一般不会直接基于 CUDA 接口来调用 Tensor Core 进行计算,而是基于 CuDNN 这一现成的 DNN 算子库,一方面是因为 CuDNN 本身隐藏了很多硬件细节,可以保证在不同显卡之间的兼容性(比如无论是否支持 Tensor Core 都可以运行),另一方面 CuDNN 的实现在大部分常见情况下是性能足够的,也就无需重复造轮子。
下面我们以混合精度训练中最常用的卷积操作来介绍一下计算过程,我们先看一下 CuDNN 里的卷积操作 API5:
cudnnStatus_t cudnnConvolutionForward(
cudnnHandle_t handle,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnConvolutionDescriptor_t convDesc,
cudnnConvolutionFwdAlgo_t algo,
void *workSpace,
size_t workSpaceSizeInBytes,
const void *beta,
const cudnnTensorDescriptor_t yDesc,
void *y)
这里面有一些名词需要解释一下:
- cudnnStatus_t,CuDNN 的接口一般采用在参数里包含输出指针(比如这里的 y)进行结果写入的设计,而返回值只包含成功失败的状态信息,即 status。
- cudnnHandle_t,handle 是与设备进行沟通的接口,类似的概念还有 file handle,直译为句柄,任何接口都需要提供一个 cuda device 的 handle。
- cudnnTensorDescriptor_t 和 cudnnFilterDescriptor_t,都属于数据描述符,包含 layout、dtype 等所有数据属性信息,因为数据内容只由一个 void* 指针(比如这里的 x 和 w)提供。
- cudnnConvolutionDescriptor_t,操作描述符,与数据描述符类似,用于描述 Op 本身的一些参数和属性,比如 conv 就包括 pad、stride、dilation 等。
- cudnnConvolutionFwdAlgo_t,直译是前向卷积的算法,因为卷积操作的具体计算方式多种多样,各自有其适合的数据场景,所以需要在这里指定采用什么算法。
- workSpace,相比于上层代码可以随时随地创建数据对象,在设备层,一个计算需要的空间必须事前声明,而 workspace 就是除了输入输出之外,进行这个计算所需的额外“工作空间”,也可以简单理解为空间复杂度。
在看完 API 的参数介绍之后,其实如何使用这个接口进行计算也就自然明了了,我们不准备一步步教你如何用现成的接口填上这些内容,而是想让你思考一下,你觉得这些参数之间的逻辑关系是什么,具体来说,你觉得什么参数能够决定这个卷积操作是运行在 Tensor Core 上的呢?
首先我们结合前面 CUDA Runtime API 的接口进行分析,wmma 接口限制了矩阵的形状都是 16×16,以及输入数据都是 half 半精度类型(累加器 c 可以是 float),那么与数据相关的 x/w/y 的描述符必然是有影响的(数据指针本身没有信息所以不影响),所以我们需要在数据描述符里指明数据类型为半精度,且需要数据的各个维度都是 8 的倍数(之所以不是 16 的倍数是因为内部实现还会做一些处理)。
然后我们分析卷积算子本身,就算数据类型和维度符合要求,也完全可以使用普通的 CUDA Core 进行运算,那么可以推断出必然有控制算子行为的参数,对照上面的列表,不难猜出是操作描述符和算法两个参数。对于算法,我们一般认为是运算的逻辑,而与实际运算的设备无关(比如一个算法在 GPU、CPU 上应该是同样的流程),但是设备会限制能够运行的算法。事实上,对于 NCHW 的二维卷积操作,FFT、GEMM、WINOGRAD 等算法都支持基于 Tensor Core 或 FP32 CUDA Core 的计算,但是有些算法则只能在 CUDA Core 上进行。
所以真正控制是否使用 Tensor Core 的参数就呼之欲出了,就是 Conv 的操作描述符。事实上,除了一般意义上的 param 参数比如 pad、stride、dilation,有一个重要参数 mathType 也包含在操作描述符内,这个参数的默认值是 CUDNN_DEFAULT_MATH,而如果要使用 Tensor Core 进行运算,必须要修改成 CUDNN_TENSOR_OP_MATH,从名字上看也是一个与 Tensor Core 强相关的值。
除此之外,还有一个参数值得一提,我们都知道混合精度训练的重要特性是 FP16 的运算中间结果使用 FP32 存储,直到最后才转成 FP16,从而使得精度不会明显下降,但是这其实不是 Tensor Core 的限制,Tensor Core 完全可以全程 FP16 运算,所以要实现混合精度,也需要我们在操作描述符内进行控制,这个参数就是操作描述符 convDesc 的 dataType 属性,我们需要将其设置成单精度(CUDNN_DATA_FLOAT)而非半精度(CUDNN_DATA_HALF)才能实现保持精度的目的。
最后简单看一下 convDesc 相关的设置代码:
// 创建描述符
checkCudnnErr( cudnnCreateConvolutionDescriptor( &cudnnConvDesc ));
// 设定常见参数,包括 dataType(最后一项)
checkCudnnErr( cudnnSetConvolutionNdDescriptor(
cudnnConvDesc,
convDim,
padA,
convstrideA,
dilationA,
CUDNN_CONVOLUTION,
CUDNN_DATA_FLOAT) );
// 设置 mathType
checkCudnnErr( cudnnSetConvolutionMathType(cudnnConvDesc, CUDNN_TENSOR_OP_MATH) );
至于剩下的 workspace,其实是与前面所有参数都相关的,因为必须知道数据的属性、计算的算法、算子的属性和计算行为等所有实际计算所需的信息,才能得出所需的“工作空间”大小,这里就不过多介绍了。
综上可以看出 NVIDIA 在接口的设计上还是非常老道的,简明合理的参数设计使得我们可以在较高的抽象层次上控制底层硬件的计算逻辑。而通过分析接口设计上的逻辑,我们也对一个算子如何才能利用 Tensor Core 进行混合精度计算有了较为完整的理解。
总结
Tensor Core 作为混合精度训练赖以加速的底层硬件支持,一直在大部分框架用户或者说算法研究员眼中好似“云雾山中人”,了解一些数学上的含义但又不清楚细节。本文则先从物理含义上将其与实际可见的 GPU 芯片进行了关联,再从较底层的 CUDA 接口代码层面如何控制 Tensor Core 做矩阵运算进行了讲解,最后回到框架层面实际开发角度详细介绍了使用卷积算子进行混合精度计算的过程。
通过这些介绍,相信大家都能理解之前熟知的一些 AMP 使用限制是为何存在了,比如为何我的显卡没有加速效果(必须要 Volta 架构及以上),为何要求维度都是 8 的倍数(Tensor Core 里需要矩阵分块),而更进一步的关于硬件如何决定跑 FP16 还是 FP32 的问题,相信经过上面代码层面的讲解也能有所了解。
希望本文能让从未接触过 CUDA 编程的读者能更加深入理解混合精度训练的底层运算原理,也能对 GPU 计算和 CUDA 编程有一些简单的认识。
附:
- GitHub:MegEngine 天元
- 官网:MegEngine-深度学习,简单开发
- 欢迎加入 MegEngine 技术交流 QQ 群:1029741705
参考
- [2]warp matrix functions - Programming Guide :: CUDA Toolkit Documentation (nvidia.com)(wmma CUDA API)
- [4]J. Burgess, “RTX on - The NVIDIA turing GPU,” IEEE Micro, vol. 40, no. 2, pp. 36–44, 2020.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号